
|NO.Z.00048|——————————|BigDataEnd|——|Hadoop&MapReduce.V21|——|Hadoop.v21|MapReduce综合案例.v02|
一、分区排序多目录输出
### --- Mapper
package com.yanqi.mr.comment.step2;
import org.apache.commons.lang3.StringUtils;
import org.apache.hadoop.io.BytesWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
//第一对kv:使用SequenceFileinputformat读取,所以key:Text,Value:BytesWritable(原因是生成sequencefile文件指定就是这种类型)
public class CommentMapper extends Mapper<Text, BytesWritable, CommentBean, NullWritable> {
//key就是文件名
//value:一个文件的完整内容
@Override
protected void map(Text key, BytesWritable value, Context context) throws IOException, InterruptedException {
//且分区每一行
String str = new String(value.getBytes());
String[] lines = str.split("\n");
for (String line : lines) {
CommentBean commentBean = parseStrToCommentBean(line);
if (null != commentBean) {
context.write(commentBean, NullWritable.get());
}
}
}
//切分字符串封装成commentbean对象
public CommentBean parseStrToCommentBean(String line) {
if (StringUtils.isNotBlank(line)) {
//每一行进行切分
String[] fields = line.split("\t");
if (fields.length >= 9) {
return new CommentBean(fields[0], fields[1], fields[2], Integer.parseInt(fields[3]), fields[4], fields[5], fields[6], Integer.parseInt(fields[7]),
fields[8]);
}
{
return null;
}
}
return null;
}
}### --- CommentBean
package com.yanqi.mr.comment.step2;
import org.apache.hadoop.io.WritableComparable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
public class CommentBean implements WritableComparable<CommentBean> {
private String orderId;
private String comment;
private String commentExt;
private int goodsNum;
private String phoneNum;
private String userName;
private String address;
private int commentStatus;
private String commentTime;
@Override
public String toString() {
return orderId+"\t"+comment+"\t"+commentExt+"\t"+goodsNum+"\t"+phoneNum+"\t"+userName+"\t"+address+"\t"+commentStatus+"\t"+commentTime;
}
//无参构造
public CommentBean() {
}
public CommentBean(String orderId, String comment, String commentExt, int goodsNum, String phoneNum, String userName, String address, int commentStatus, String commentTime) {
this.orderId = orderId;
this.comment = comment;
this.commentExt = commentExt;
this.goodsNum = goodsNum;
this.phoneNum = phoneNum;
this.userName = userName;
this.address = address;
this.commentStatus = commentStatus;
this.commentTime = commentTime;
}
public String getOrderId() {
return orderId;
}
public void setOrderId(String orderId) {
this.orderId = orderId;
}
public String getComment() {
return comment;
}
public void setComment(String comment) {
this.comment = comment;
}
public String getCommentExt() {
return commentExt;
}
public void setCommentExt(String commentExt) {
this.commentExt = commentExt;
}
public int getGoodsNum() {
return goodsNum;
}
public void setGoodsNum(int goodsNum) {
this.goodsNum = goodsNum;
}
public String getPhoneNum() {
return phoneNum;
}
public void setPhoneNum(String phoneNum) {
this.phoneNum = phoneNum;
}
public String getUserName() {
return userName;
}
public void setUserName(String userName) {
this.userName = userName;
}
public String getAddress() {
return address;
}
public void setAddress(String address) {
this.address = address;
}
public int getCommentStatus() {
return commentStatus;
}
public void setCommentStatus(int commentStatus) {
this.commentStatus = commentStatus;
}
public String getCommentTime() {
return commentTime;
}
public void setCommentTime(String commentTime) {
this.commentTime = commentTime;
}
//定义排序规则,按照时间降序;0,1,-1
@Override
public int compareTo(CommentBean o) {
return o.getCommentTime().compareTo(this.commentTime);
}
//序列化
@Override
public void write(DataOutput out) throws IOException {
out.writeUTF(orderId);
out.writeUTF(comment);
out.writeUTF(commentExt);
out.writeInt(goodsNum);
out.writeUTF(phoneNum);
out.writeUTF(userName);
out.writeUTF(address);
out.writeInt(commentStatus);
out.writeUTF(commentTime);
}
//反序列化
@Override
public void readFields(DataInput in) throws IOException {
this.orderId = in.readUTF();
this.comment = in.readUTF();
this.commentExt = in.readUTF();
this.goodsNum = in.readInt();
this.phoneNum = in.readUTF();
this.userName = in.readUTF();
this.address = in.readUTF();
this.commentStatus = in.readInt();
this.commentTime = in.readUTF();
}
}### --- 自定义分区器
package com.yanqi.mr.comment.step2;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Partitioner;
public class CommentPartitioner extends Partitioner<CommentBean, NullWritable> {
@Override
public int getPartition(CommentBean commentBean, NullWritable nullWritable, int numPartitions) {
// return (commentBean.getCommentStatus() & Integer.MAX_VALUE) % numPartitions;
return commentBean.getCommentStatus();//0,1,2 -->对应分区编号的
}
}### --- 自定义OutputFormat
### --- CommentOutputFormat
package com.yanqi.mr.comment.step2;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.RecordWriter;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
//最终输出的kv类型
public class CommentOutputFormat extends FileOutputFormat<CommentBean, NullWritable> {
//负责写出数据的对象
@Override
public RecordWriter<CommentBean, NullWritable> getRecordWriter(TaskAttemptContext job) throws IOException, InterruptedException {
Configuration conf = job.getConfiguration();
FileSystem fs = FileSystem.get(conf);
//当前reducetask处理的分区编号来创建文件获取输出流
//获取到在Driver指定的输出路径;0是好评,1是中评,2是差评
String outputDir = conf.get("mapreduce.output.fileoutputformat.outputdir");
FSDataOutputStream goodOut=null;
FSDataOutputStream commonOut=null;
FSDataOutputStream badOut=null;
int id = job.getTaskAttemptID().getTaskID().getId();//当前reducetask处理的分区编号
if(id==0){
//好评数据
goodOut =fs.create(new Path(outputDir + "\\good\\good.log"));
}else if(id ==1){
//中评数据
commonOut = fs.create(new Path(outputDir + "\\common\\common.log"));
}else{
badOut = fs.create(new Path(outputDir + "\\bad\\bad.log"));
}
return new CommentRecorderWrtier(goodOut,commonOut,badOut);
}
}### --- RecordWriter
package com.yanqi.mr.comment.step2;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.RecordWriter;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
import java.io.IOException;
public class CommentRecorderWrtier extends RecordWriter<CommentBean, NullWritable> {
//定义写出数据的流
private FSDataOutputStream goodOut;
private FSDataOutputStream commonOut;
private FSDataOutputStream badOut;
public CommentRecorderWrtier(FSDataOutputStream goodOut, FSDataOutputStream commonOut, FSDataOutputStream badOut) {
this.goodOut = goodOut;
this.commonOut = commonOut;
this.badOut = badOut;
}
//实现把数据根据不同的评论类型输出到不同的目录下
//写出数据的逻辑
@Override
public void write(CommentBean key, NullWritable value) throws IOException, InterruptedException {
int commentStatus = key.getCommentStatus();
String beanStr = key.toString();
if (commentStatus == 0) {
goodOut.write(beanStr.getBytes());
goodOut.write("\n".getBytes());
goodOut.flush();
} else if (commentStatus == 1) {
commonOut.write(beanStr.getBytes());
commonOut.write("\n".getBytes());
commonOut.flush();
} else {
badOut.write(beanStr.getBytes());
badOut.write("\n".getBytes());
badOut.flush();
}
}
//释放资源
@Override
public void close(TaskAttemptContext context) throws IOException, InterruptedException {
IOUtils.closeStream(goodOut);
IOUtils.closeStream(commonOut);
IOUtils.closeStream(badOut);
}
}### --- Reducer
package com.yanqi.mr.comment.step2;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class CommentReducer extends Reducer<CommentBean, NullWritable, CommentBean, NullWritable> {
@Override
protected void reduce(CommentBean key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException {
//遍历values,输出的是key;key:是一个引用地址,底层获取value同时,key的值也发生了变化
for (NullWritable value : values) {
context.write(key, value);
}
}
}### --- Driver
package com.yanqi.mr.comment.step2;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.SequenceFileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class CommentDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "CommentDriver");
job.setJarByClass(CommentDriver.class);
job.setMapperClass(CommentMapper.class);
job.setReducerClass(CommentReducer.class);
job.setMapOutputKeyClass(CommentBean.class);
job.setMapOutputValueClass(NullWritable.class);
job.setOutputKeyClass(CommentBean.class);
job.setOutputValueClass(NullWritable.class);
job.setPartitionerClass(CommentPartitioner.class);
//指定inputformat类型
job.setInputFormatClass(SequenceFileInputFormat.class);
//指定输出outputformat类型
job.setOutputFormatClass(CommentOutputFormat.class);
//指定输入,输出路径
FileInputFormat.setInputPaths(job,
new Path("E:\\merge\\outout"));
FileOutputFormat.setOutputPath(job,
new Path("E:\\merge\\outmulti-out"));
//指定reducetask的数量
job.setNumReduceTasks(3);
boolean b = job.waitForCompletion(true);
if (b) {
System.exit(0);
}
}
}二、编译打印
### --- 编译打印
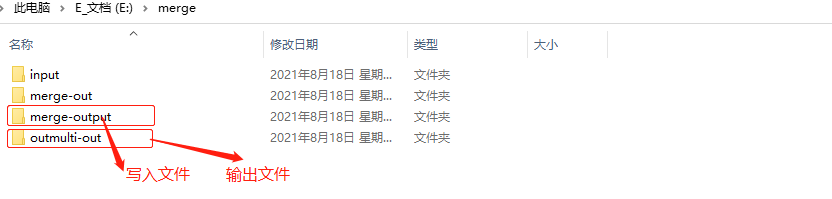
~~~ 输入输出参数
~~~ 打印输出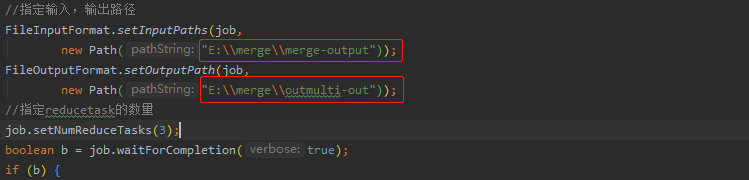
Walter Savage Landor:strove with none,for none was worth my strife.Nature I loved and, next to Nature, Art:I warm'd both hands before the fire of life.It sinks, and I am ready to depart
——W.S.Landor

 浙公网安备 33010602011771号
浙公网安备 33010602011771号