
ES原理:Lucene-倒排索引实现原理探秘
参考:
倒排索引理论
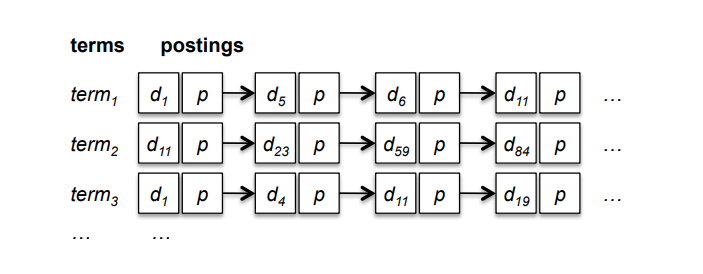
索引,索引词表。倒排索引并不需要扫描整个文档集,而是对文档进行预处理,识别出文档集中每个词。
倒排表,倒排表中的每一个条目也可以包含词在文档中的位置信息(如词位置、句子、段落),这样的结构有利于实现邻近搜索。词频和权重信息,用于文档的相关性计算。
倒排索引由两部分组成,所有独立的词列表称为索引,词对应的一系列表统称为倒排表。 —— 来自《信息检索》
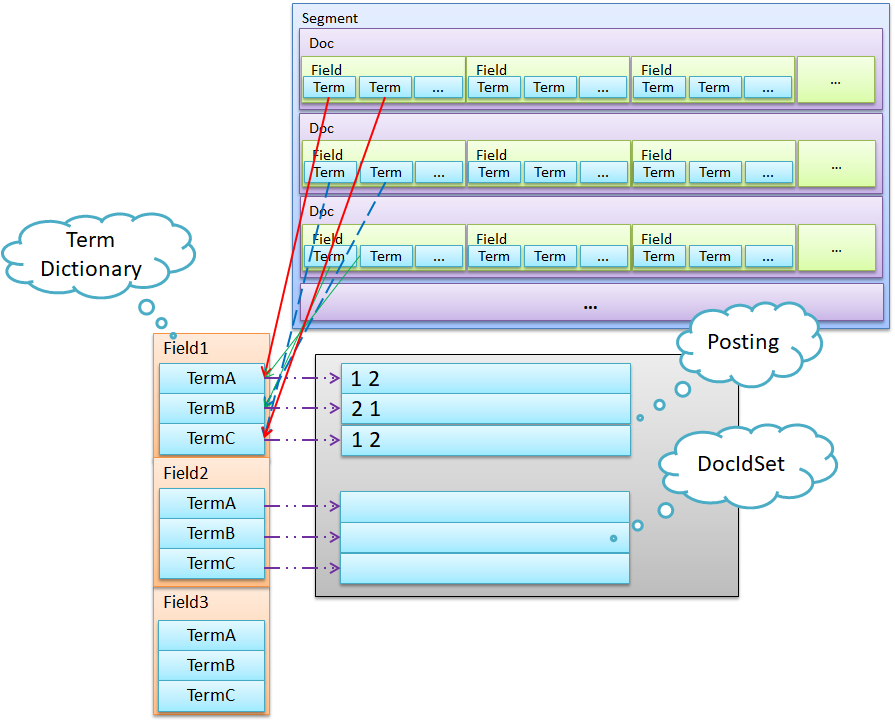
如图,整个倒排索引分两部分,左边是Term Dictionary(索引表,可简称为Dictionary),是由一系列的Terms组成的;右边为Postings List(倒排表),由所有的Term对应的Postings组成。
首先,有必要解释一下,每个Segment中的每个字段(Field)都有这么一个独立的结构。
其次,它是不可改写的,即不能添加或更改。至于为何选择不可改写的设计,简单说有两个方面:一是更新对磁盘来说不够友好;另一方面是写性能的影响,可能会引发各种并发问题。
我们可以用一个HashMap来简单描述这个结构:Map<String, List<Integer>>,这个Map的Key的即是Term,那它的Value即是Postings。
所以它的Key的集合即是Dictionary了,这与上图的描述太贴切了。
由于HashMap的Key查找还是用了HashTable,所以它还解决Dictionary的快速查找的问题,一切显得太美好了。这可以说是一个hello world版的倒排索引实现了。
Lucene的实现
全文搜索引擎通常是需要存储大量的文本,Postings可能会占据大量的存储空间,同样Dictionary也可能是非常大的,因此上面说的基于HashMap的实现方式几乎是不可行的。
在海量数据背景下,倒排索引的实现都极其复杂,因为它直接关系到存储成本以及搜索性能。为此,Lucene引入了多种巧妙的数据结构和算法。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号