
论文翻译——2017_Residual drum sound estimation for RPCA singing voice extraction
Mikami S, Kawamura A, Iiguni Y. Residual drum sound estimation for RPCA singing voice extraction[C]//2017 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC). IEEE, 2017: 442-446.
题目:RPCA歌唱音提取中的鼓声残余估计
作者:Mikami S, Kawamura A, Iiguni Y.
摘要:本文提出了一种从由歌声和鼓声组成的音乐声音中提取歌唱声音的有效方法。该方法基于鲁棒主成分分析(RPCA),它是一种将给定矩阵分离为稀疏矩阵和低秩矩阵的技术。RPCA将音乐声音的谱图作为给定矩阵,将提取的歌唱声音谱图作为稀疏谱图。我们通过去除稀疏谱图中残余的鼓声来提高RPCA方法的性能。剩余鼓声被估计为在稀疏谱图中反复出现的谱分量。从稀疏谱图中去除估计的鼓声残留谱图,得到改进的歌喉谱图。仿真结果表明,与传统的RPCA歌唱语音提取方法相比,该方法能提高GNSDR 10dB。
1 介绍
从包含演唱声音和伴奏声音的音乐声音中提取歌唱声音是一个有趣的话题,因为它有各种各样的应用,如歌词识别[1],[2],歌手识别[3],音乐润色[4],[5],主动音乐收听[6],等等。传统的歌音提取方法都是利用音乐信号的谱图来表示音乐信号在时频域的谱功率。
有些方法侧重于伴奏音的时间/光谱连续性和唱腔[7]、[8]的稀疏性。该方法在每个时频库中评估音乐谱图与时间或频率的连续性。Tachibana等人基于谐波/打击音[7]的各向同性特性,提出了利用谐波/打击音分离(HPSS)进行歌唱声音提取。Fitzgerald等人沿时间和频率方向对谱图应用不同的中值滤波器来评估连续性[8]。这两种方法都假设谐波声音在几个分析帧中是稳定的,而敲击声音在频域中广泛分布。
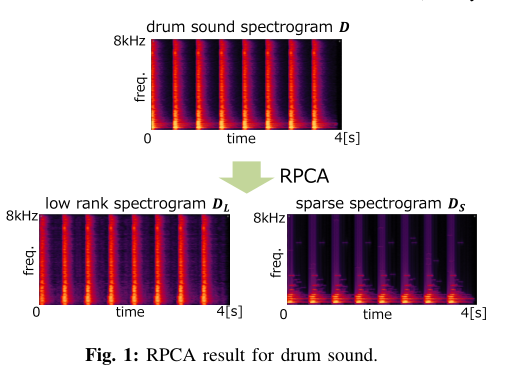
另一种方法是利用伴奏音的重复,这种方法本身不依赖于谱的连续性。采用非负矩阵分解(non - negative matrix factorization, NMF)将观测到的声谱图表示为基矩阵和激活矩阵[9],将观测到的声谱图分解为多个唱腔分量和伴奏分量。在使用NMF时,很难确定合适的基数和选择属于唱腔的基。另一方面,还采用鲁棒主成分分析(RPCA)进行歌唱声音提取,RPCA可以直接将声谱图分离为两个声谱图,即歌唱声谱图和伴奏声谱图。RPCA是一种将低秩矩阵和稀疏矩阵的和相互分离的技术[10]。在伴奏谱反复出现且伴唱谱稀疏的假设下,RPCA可以从观测到的伴唱和伴唱谱[11]组成的谱图中提取出伴唱谱图作为稀疏矩阵。这里将重复伴随谱分离为低秩矩阵。Ikemiya等人提出了一种RPCA与F0估计相结合的方法,可以同时提取歌唱声音及其音高[12]。不幸的是,伴随谱在反复出现时往往变得稀疏。例如,鼓声的衰减部分就具有这样的特征,它们被分离为唱歌的声音频谱。
我们专注于一种基于rpca的方法,它不依赖于伴奏声音的连续性或基的数量。本研究的目的是去除残余鼓声从估计的歌唱声谱图由RPCA。我们提出了一种基于鼓声频谱重复的鼓声残差估计方法。我们对重复的残余鼓声谱进行了采集,并对采集到的鼓声谱取中值,估计出具有代表性的鼓声谱。把有代表性的频谱放在每个鼓声位置,我们得到一个剩余鼓声谱图。最后,从RPCA稀疏谱图中减去剩余鼓声谱图,得到改进的歌声谱图。仿真结果表明,与传统的RPCA歌唱声音提取方法相比,该方法能够提高歌唱声音提取的性能。
设x(n)为时刻n(0≤n < N)的分段加窗音乐信号,式为
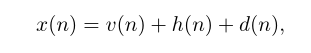
其中v(n)、h(n)、d(n)分别为歌声、和声伴奏声和鼓声。对(1)进行短时傅里叶变换(STFT),我们有
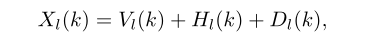
其中l和k分别表示帧索引(0≤l < L)和频率索引(0≤k < N)。我们定义(N/2 + 1) × L矩阵X为
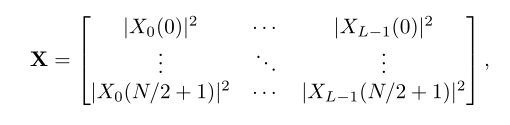
其中|·|为绝对值。当用亮度表示X的元素时,X常被称为光谱图。我们另外定义(N/2 + 1) × L矩阵V, H, D,使每个(L, k)元素分别表示为|Vl(k)|2, |Hl(k)|2, |Dl(k)|2。定义∠X为相谱图的矩阵,其每个元素为exp (j∠Xl(k)),其中j =√−1,∠{·}为相谱。假设X = V + H + D,当V是稀疏矩阵,H和D都是低秩矩阵时,RPCA从X[11]中提取V是有用的。
RPCA满足以下条件[10]。
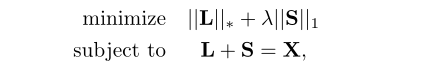
其中L和S分别表示低秩矩阵和稀疏矩阵。||·|| * 表示核范数,||·||1表示L1范数。在文献[10]中,当X∈RI×J时,建议λ = 1/√max(I, J), λ为控制s稀疏性的非负值。为了解决优化问题(4),在文献[13]中提出了一种不精确版本的增广拉格朗日乘子(ALM)算法。RPCA得到的矩阵S与估计的歌唱声谱图相对应。
3 剩余鼓声的估计
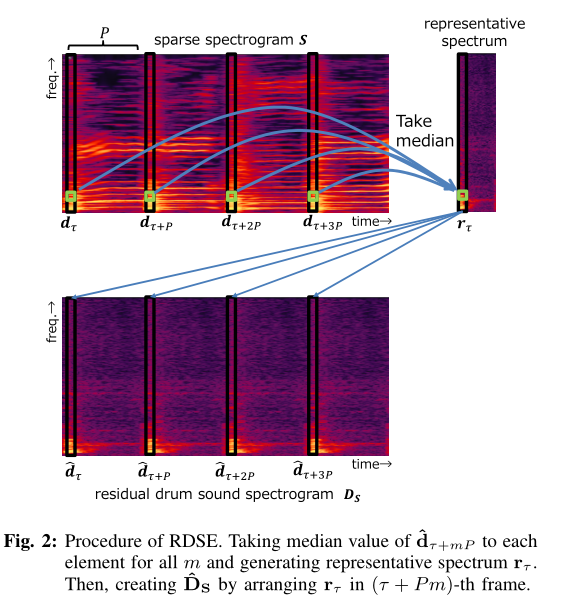
我们假设
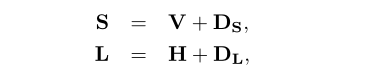
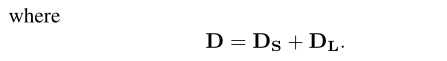
我们称DS为剩余鼓声谱图。
我们用列向量表示S和DS
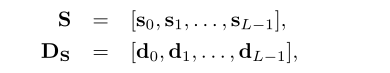
其中sl和dl(0≤l < L)分别为(N/2 + 1) × 1向量。我们假设鼓声反复出现处理区域内的相同间隔即L帧。这意味着
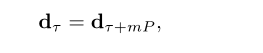
其中,P表示对应于单个间隔的帧数,τ (I≤τ < I + J)表示支持处理区域中第一个鼓声的帧索引。其中I为第一个鼓声的第一帧索引,J为单个鼓声持续时间对应的帧数。非负整数m必须满足
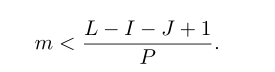
由于V的列是稀疏的和变化的,我们估计代表性的鼓声频谱为中值频谱给出
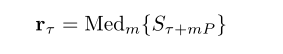
其中Med{·}是一个取向量元素中值的运算符。
我们使用rτ来获得估计的剩余鼓声谱图,给出为
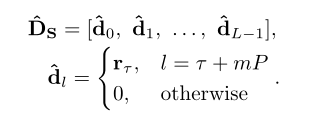
我们将从(13)到(15)的过程称为RDSE。估计的歌唱声谱图ˆV如下:
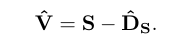
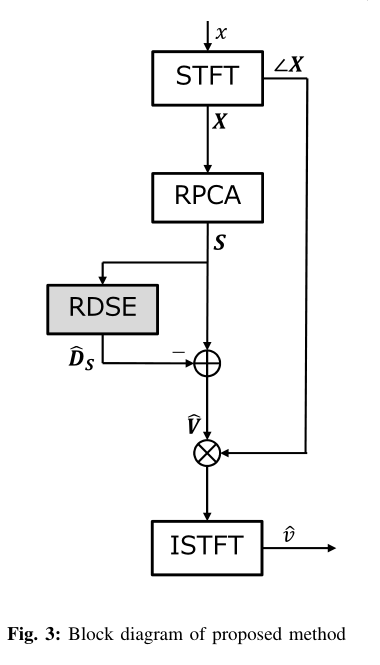
所提出方法的框图如图3所示。其中x表示待处理的整个音乐信号。信号x通过窗口函数被分割成L帧,其中单个帧的分割信号提供了X的单个列。当RPCA应用于X时,我们将S作为预先估计的歌唱声谱图。将RDSE应用于S给出了剩余鼓声谱图作为ˆDS。通过从S中减去ˆDS,我们得到了一个改进的歌唱声谱图ˆV。对得到的矩阵ˆV与∠X的乘积的每一列进行逆stft运算,得到时域上估计的歌声谱图ˆv。
4 仿真
我们进行了歌唱语音提取仿真,验证了所提方法的能力。
A 数据集和条件
我们使用了50个来自MIR-1K数据集[14]的中国流行歌曲女声和男声。在这里,歌声的持续时间为4 ~ 13秒,采样率为16kHz。大多数歌手都是业余的,没有受过专业的音乐训练。此外,我们使用5种鼓的声音,如小军鼓,低音鼓,高汤姆,封闭高帽钹,和碰撞钹从乐器数据库RWC音乐数据库[15]。我们每8192个样本在歌声中加入鼓声,N = 1024中每16帧添加一次,观察到的信号产生的信噪比为6dB。我们已经准备了500个片段的观测信号。
为了计算X,我们使用了N=1024的汉宁窗口,帧移位为N/2。如文献[11]、[10]所建议的,我们将λ=1/√max(N/2+1,L)。我们假设鼓声的位置在以下模拟中是已知的。
B 评价标准
作为评估标准,我们使用信噪比(SNR)和光谱距离(SD),如
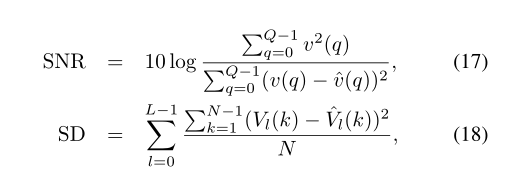
式中,v(q)表示时间q处的干净歌唱声音,ˆVl(k)是ˆv(q)的STFT。此外,我们使用了全局归一化源失真比(GNSDR),如[12]、[11]所示
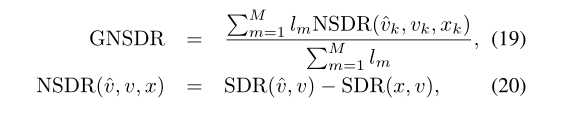
其中m为夹数(1≤m≤m), lm为第m个夹的长度。SDR按给定计算

其中, ˆv(q) = v(q)+einterf(q)+enoise(q)+eartif(q), einterf(q), enoise(q)和eartif(q)表示分离信号中不需要的干扰源、干扰噪声和伪影的干扰。SNR和GNSDR在数值越大时分离性能越好,SD在数值越小时分离性能越好。
C 仿真结果与讨论
模拟结果如表I所示,其中av.和s.d.分别为结果的平均值和标准差。我们对信噪比和SD的平均值进行了Welch 's t检验,在信噪比下,所有鼓声和SD下的大鼓、小军鼓和高鼓在5%的显著性水平上存在显著性差异。在GNSDR中,与传统的RPCA方法相比,该方法对低音鼓、小军鼓和高鼓的值分别提高了10.95dB、8.96dB和10.60dB。闭式高帽钹和碰撞钹分别为2.46dB和3.49dB,未观察到前三种敲击的较大增加。
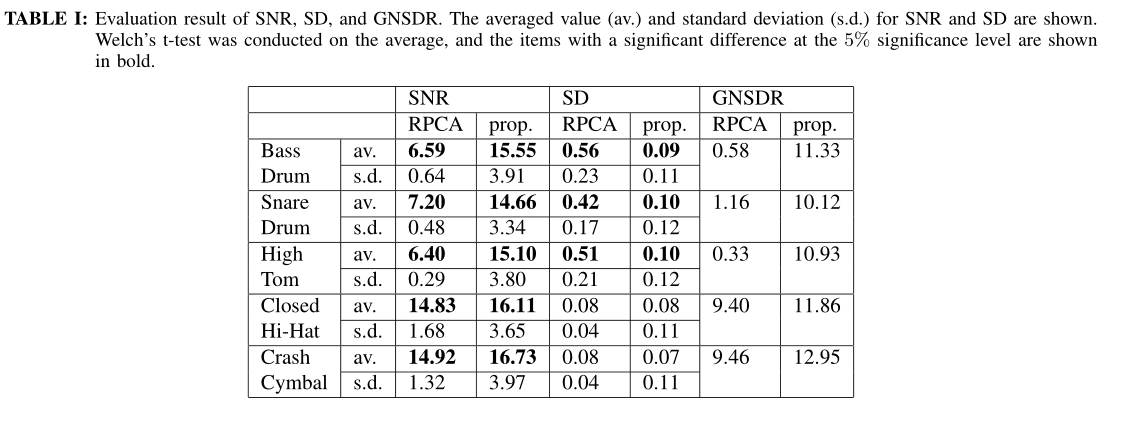
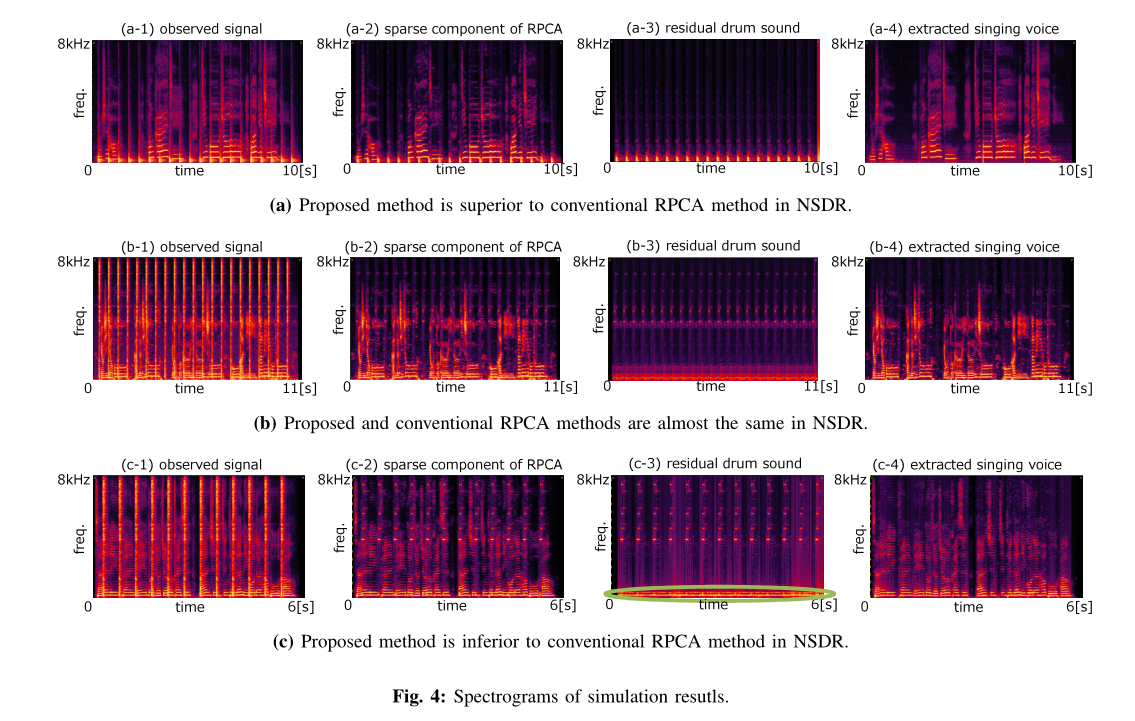
图4 (a)显示了NSDR中提出的方法优于常规RPCA方法时的模拟结果谱图。在这个例子中,低音鼓声被添加到片段“amy 1 01”中。传统RPCA提取的歌唱声音NSDR为0.90dB,而本文方法提取的歌唱声音NSDR为18.34dB。在(a-2)中,低音鼓的低频分量不能被RPCA去除。低音鼓是一种膜鸣乐器,它通过振动拉伸的薄膜与身体产生共鸣来发声。谐振频率由鼓体的形状或大小决定,功率集中在谐振频带内。这意味着膜音器的衰减声谱图稀疏,用RPCA将其分离为歌唱声谱。所提出的方法可以适当地估计剩余鼓声,如图4 (a-3)所示。(a-2)减去(a-3),只提取出歌声,如图(a-4)所示。小军鼓和高鼓也是膜鸣乐器,其评价价值也有所提高。
图4 (b)显示了在NSDR中,当提出的方法和传统方法给出几乎相同的性能时的谱图。在这个例子中,封闭的hi-hat钹声音被添加到片段“abjones 1 01”。RPCA歌声提取结果如(b-2)所示,所提方法的结果如(b-4)所示。两个nsdr都在12.08dB左右。由于高帽钹频谱的功率从高频段均匀分布到低频段,所以在RPCA中,大部分的高帽声音被分离为低阶。如(b-2)所示,RPCA稀疏矩阵只包含少量残余hi-hat钹。当鼓声不稀疏时,RDSE方法效果较差。
图4 (c)显示了一个提取实例的光谱图,在该提取实例中,所提方法优于NSDR中传统的RPCA方法。观察到的信号是通过将闭合的高帽钹加到夹“bobon 101”上获得的。传统的RPCA歌唱语音提取结果(c-2)给出了7.16dB的NSDR,提出的方法(c-4)给出了3.36dB的NSDR。剪辑“bobon 01”有一个唱歌的声音,在剪辑期间音高不断存在。当从这样的信号中选择一个代表性频谱时,该代表性频谱包括唱歌的声音成分。因此,歌唱的声音成分被包含在剩余的鼓谱中,如图4 (c-3)所示的圆圈所示。它导致了语音质量的下降,而剩余的鼓声被有效地去除。
5 结论
提出了一种基于RPCA的歌声提取方法。我们开发了RDSE方法,从RPCA估计的歌唱声音频谱中去除残留的鼓声。在残鼓声谱重复出现的假设下,取残鼓声谱候选值的中位数,得到具有代表性的残鼓声谱。从RPCA唱腔频谱中减去代表性频谱,得到改进的唱腔信号。仿真结果表明,与传统的RPCA方法相比,该方法的GNSDR提高了10dB。注意,本文假定鼓声的位置是已知的。在实际情况下,我们要检测鼓声的位置。同时,我们打算将该方法与其他基于NMF或深度神经网络的方法进行比较。
REFERENCE
[1] M. Suzuki, T. Hosoya, A. Ito, and S. Makino, “Music information retrievalfrom a singing voice using lyrics and melody information,” in EURASIPJ. Adv. Signal Process., Article ID: 038727, 2007.
[2] A Mesaris and T. Virtanen, “Automatic recognition of lyrics in singing,”n EURASIP J. Audio, Speech, Music Process., Article ID: 546047, 2010
[3] H.Fujihara, T. Kitahara, M. Goto, K. Komatani, and T. Ogata, “Singeridentification based on accompaniment sound reduction and reliable frameselection,” in Proc. ISMIR, pp.329-336, 2005.
[4] K. Yoshii, M. Goto, H. G. Okuno, ”INTER:D: A drum sound equalizerfor controlling volume and timbre of drums,” in Proc. Eur. WorkshopIntegration of Knowledge Semantics Digital Media Technol., pp.205-212,2005
[5] Y. Ikemiya, K. Itoyama, H. G. Okuno, “ Transcribing vocal expressionfrom polyphonic music, ”in Proc. ICASSP , pp.3127-3131, 2014.
[6] M. Goto, “Active music listening interfaces based on signal processing,”in Proc. Int. Conf. Acoust., Speech, and Signal Process., pp.1441-1444,2007.
[7] H. Tachibana, N. Ono, and S. Sagayama, “Singing voice enhancement inmonaural music signals based on two-stage harmonic/percussive soundseparation on multiple resolution spectrograms,” in IEEE Trans. Audio,Speech, Lang. Process, vol.22, no.1, pp.228-237, 2014.
[8] D. Fitzgerald and M. Gainza, “Single channel vocal separation using me-dian filtering and factorisation techniques,” in ISAST Trans. on Electronicand Signal Processing, vol.4, no.1, pp.62-73, 2010.
[9] A. Chanrungutai and C.A. Ratanamahan, “Singing voice separation inmono-channel music using non-negative matrix factorization,” in Proc.Int. Conf. Adv. Technol. Commun., pp.243-246, 2008.
[10] Emmanuel J. Cand‘es, Xiaodong Li, Yi Ma, and John Wright,“ Robustprincipal component analysis?,”in J. ACM, vol. 58, no.11, pp.1-37, Jun.,2011.
[11] P . S. Huang, S. D. Chen, P . Smaragdis, and M. H. Johnson,“ Singing-voice separation from monaural recordings using robust principal compo-nent analysis, ”in Proc. Int. Conf. Acoust., Speech, and Signal Process.,
pp. 57-60, 2012
[12] Y . Ikemiya, “Singing voice separation and vocal F0 estimation basedon mutual combination of robust principal component analysis andsubharmonic summation,” in IEEE/ACM Trans. on Audio, Speech, andLanguage. Process., vol.24, no.11, pp.2084-2095, 2016.
[13] Y . M. Z. Lin, M. Chen, “The augmented Lagrange multiplier methodfor exact recovery of corrupted low-rank matrices,” in MathematicalProgramming, 2009.
[14] MIR-1K Dataset https://sites.google.com/site/unvoicedsoundseparation/mir-1k
[15] M. Goto, “ Development of the RWC music database, ” in Proc. Int.Congr. Acoustics, pp. I-553-I-556, 2004.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号