
论文翻译-----Heartbeat Sound Classification with Visual Domain Deep Neural Networks
题目:基于视觉域深度神经网络的心音分类
摘要:心脏病是人类死亡的最常见原因,导致全世界近三分之一的死亡。及早发现疾病会增加患者的生存机会,有几种方法可以早期发现心脏病的迹象。通过数字听诊器和移动设备应用的心音听诊技术是识别心血管疾病最简单、方便的方法之一。虽然可以使用这些方法以电子方式收集数据,但识别机械心音中的任何问题仍然是一个手动过程,需要专业的临床人员诊断任何异常。因此,研究心血管声音的自动特征提取和分类是必要的。Pascal心音分类挑战数据集在以前的研究中很受欢迎,因为它提供了种类一致的心血管音频。本研究提出将净化和标准化的心音转换为视觉mel尺度的频谱图,然后使用视觉域转移学习方法自动提取心音特征并进行分类。该研究将使用视觉域分类方法,即基于卷积神经网络的架构,即ResNet、MobileNetV2等,作为光谱图的自动特征提取工具。这些在图像领域广为接受的模型被发现可以学习从不同环境中采集的心音的广义特征表示,这些环境具有不同的振幅和噪声水平。由于所选数据集不平衡,使用的模型评估标准为分类准确性、精确性、召回率和AUROC。所提出的方法已在帕斯卡心音的两个数据集上实施,两个数据集的分类准确率均为90%,AUROC均为0.97。
关键词:自动特征提取、心血管声音分类、频谱图、转移学习、音频数据的视觉转换
1.introduction
心脏病可分为不同类型,即动脉阻塞、心脏瓣膜、肌肉问题和节律问题。早期检测对有效治疗心脏病具有重要意义。侵入性和非侵入性诊断方法都可以产生可靠的结果。检测心脏健康的一些主要侵入性方法包括血液测试、冠状动脉造影等。非侵入性方法包括运动负荷测试、心电图、听诊技术、磁共振成像、心率监测、胸部x光等。心音听诊技术是最简单、方便、廉价的,快速了解患者心脏健康的方法,但需要临床专业知识。这项技术是其他心血管健康检查中最古老的,可以追溯到19世纪。心血管系统的机械运动产生信息丰富的声音,其中包含心脏不同部位之间相互作用的细节。任何异常的存在,如噪音、扭曲声,都可能预示着早期的心脏病。
通过使用听诊器、移动应用等简单方便的技术,可以发现几种与心脏相关的不规则现象。心音是一种微弱的信号,由三尖瓣、二尖瓣、主动脉瓣、肺动脉瓣的打开和关闭、心肌收缩和舒张的颤动以及血流冲击产生。心脏产生机械可听声音,即lub和dub(临床上称为S1和S2)。在正常情况下,S1以50-150 Hz的频率延长50-100毫秒,而S2以50-200 Hz的频率延长25-50毫秒。这些声音的出现模式可分为不同类别,即正常、杂音、额外声音、早搏。杂音主要表示疾病,根据响度分为1到6级。额外的声音或额外的收缩类型可能预示着疾病,也可能不预示着疾病。了解心音的类型有助于医生为患者决定行动方案。到目前为止,大多数情况下,这些声音类别的识别仍然是手动的。此外,心音听诊方法的主要缺点之一是背景噪声和外部推断。如果测量是由缺乏经验的临床人员进行的,这可能会导致诊断问题。以前的大多数工作都集中于从音频中手动提取特征,即时间、频率、振幅等。一旦提取出特征,它们将作为输入发送给分类学习确定性或概率算法。然后,生成的模型能够以中等精度和精密度成功预测几类心音。
[8] 通过小波和短时傅里叶变换对心脏音频进行去噪,在重新采样后对音频信号进行去噪。在特征提取步骤中,研究提取了心跳、收缩和舒张的统计特征,即总和、平均值、标准差等,以及S1和S2声音的位置(Lub和Dub)。使用条件逻辑对提取的特征进行分类,并通过精度、F分数、Y-ouden指数和判别能力对结果进行测量,但没有获得良好的准确性。[28]重点研究了基于音频时频和非线性特征提取的正常与杂音心音分类。使用电力线去噪和白噪声去除方法消除噪声。基于时频和非线性熵方法从净化后的信号中提取了五个可分辨特征。然后使用带有高斯径向基核分类器的支持向量机对这两种类型进行分类,准确率达97%。这是不稳定的,因为使用小波分解方法时,不同频率的心音会导致预测误差。[7] 在他们的研究中提出了一种新方法,将自相关特征与扩散图一起用于低维特征提取。SVM对杂音和收缩期外问题心音的敏感性均为38%,低于其他研究。[27]专注于心音分割,然后根据分割的心脏周期创建缩放频谱图。S1和S2声音的分配是基于舒张期大于收缩期的考虑。然后使用短时傅里叶变换创建估计的心脏周期的对数功率谱图。然后利用张量分解从标度谱图中提取鉴别特征。SVM分类器对声音进行了进一步分类,获得了较好的分类精度。[21]通过绘制振幅与时间的曲线图和频谱图,直观地分析了心跳信号,这表明不同类别的心脏音频在视觉上是可以区分的。该研究从去噪数据集中生成50000帧的固定时间长度信号进行分类。研究发现,表现最好的算法是具有正则化的长-短记忆(LSTM)。通过五次交叉验证,准确率约为80%。
在使用环境声音数据集实现视觉图像模型方面已经做了一些工作。最近的研究显示了有希望的结果,同时尝试使用视觉域模型(如CNN、CRNN等)对音频域数据集进行分类[11]对GTZAN数据集进行了分类,该数据集包括10种类型的音乐。[5] 探索了使用不同参数生成的光谱图,以及用于自动标记音乐的几个深度卷积神经网络。该研究的结论是,对于自动音频分类问题,mel谱图比原始谱图具有更好的代表性,当有更多的训练数据可用时,更深的网络可以产生更好的准确度分数。[3] )对光谱图、MFCC(Mel频率倒谱系数)、CRPs(交叉递归图)表示进行了实验,以找出每种类型的有效性,并得出结论,光谱图是最有效的视觉表示,可通过视觉域深度模型(即GoogleNet、ResNet等)进行高精度分类。[16]探讨了时间信息在音频分类中的使用,其中mel谱图被用作卷积递归神经网络(CRNN)的输入。[18] 考虑使用预先训练好的Imagenet模型对GTZAN、ESC-50和UrbanSound8K等知名音频数据集进行分类。可变窗口大小和跳长用于计算三通道Mel谱图,以捕获可变水平的频率和时间信息。实验中使用了随机启动和预先训练的模型。据观察,预先训练的模型优于随机初始化的模型。该研究还表明,前几层预训练模型的权重变化不大,但中间层的权重发生了显著变化,以适应光谱图相关特征。
众所周知,卷积神经网络在处理大量输入训练数据集时效果最好。这有助于网络学习复杂的非线性函数,从而更好地在看不见的数据集上进行泛化,从而提高精度,并有助于避免过度拟合问题。与图像域数据集相比,心音数据库缺乏高质量的训练数据。解决这个问题的简单而有效的方法之一是数据扩充。[22]探讨了环境声音数据集上的几种音频增强技术及其对整体准确度得分的影响。试验的技术包括时间拉伸、音调偏移、动态范围压缩和添加背景噪声。在转换成mel谱图之前,所有这些增强都直接应用于音频。模型显示,无论数据增加在哪里,精确度都提高了16%。对结果的进一步分析发现,尽管增强总体上提高了某些类的每类准确度,但由于一些重叠的特征,它有所降低。因此,这项研究基于这些发现提出了面向未来实验的类扩展。由于生成的光谱图是一种图像表示,因此还可以使用几种图像增强技术来减少过度拟合。一些常见的图像增强技术包括随机旋转、随机裁剪、水平翻转和仿射变换。[9] 引入了一种新的方法,他们称之为CutOut。这项技术随机屏蔽图像中的方形区域以增强图像。将该方法应用于输入数据集提高了相关CNN的性能和鲁棒性。与CutOut类似,[29]探索了另一种方法,即删除图像中的矩形空间。这种方法被称为随机擦除,它被证明是一种有效的方法,可以避免过度拟合,提高基于CNN模型的泛化能力。[15]探索了另一种有效的图像增强方法——样本配对,该方法将一幅图像与从训练数据集中随机选择的另一幅图像合并。将两幅图像的像素随机组合以生成样本图像的方法称为混搭(MixUp),该方法已在[26]中探索过。这里需要注意的一点是,采样配对是混合方法的一种特殊情况,其中像素混合的比率变为1:1。这两种方法都显示了图像域模型在分类精度方面的显著进步。[20] 在谷歌提出了一种称为SpecAugment的谱图增强技术,该技术简单且计算成本低廉。该方法包括时间包装、基于时间和频率掩蔽的增强。时间缠绕是指扭曲频谱图时间序列的X轴(时间)。时间掩蔽是指掩蔽一组连续的时间步,而频率掩蔽是指掩蔽频谱图中的频率通道。该方法已通过ASR(自动语音识别)网络的语音识别问题进行了测试,并通过[19]项任务获得了LibriSpeech 960h和[10]项任务获得了交换机300h的最新结果。研究中指出的一个要点是,时间包装确实有助于提高模型的性能,但不是一个关键因素。它还指出,增强将过拟合问题转化为欠拟合问题,然后通过设计更长的网络或进行更长时间的训练等常用方法来解决。
在过去十年中,人们对图像和视频等视觉域数据进行了大量研究,为特征提取提供了几种最先进的模型。ImageNet挑战要求这些模型在一个巨大的数据集(100多万)上进行训练。这些经过训练的模型能够逐层学习图像数据表示。初始层学习简单的特征,如边缘、边界,而后续层学习更复杂的特征,如物种、背景、环境等。这些知识可以很容易地用作网络权重和偏差,用于任何类似图像的特征提取。文献回顾发现,目前还没有研究过使用视觉方法对心音进行自动特征提取。近实时的自动特征提取程序以及心音分类器对医疗领域和医疗保健行业很有帮助,可以将该方法结合到电子听诊设备中,用于检测心音类别。
本文做出了以下贡献:
成功演示了如何使用视觉域神经网络对心脏音频数据进行高精度分类。本研究中描述的方法可进一步用于其他心血管数据集的训练,并预测高水平类别
通过将精心策划的心音分割成标准化持续时间的多个音频片段,展示培训在规范化、数据可用性和剪切无效信息方面的优势
基于Pascal心音分类挑战数据集进行的训练/测试,比较不同预训练特征提取器(即ResNet152V2、MobileNetV2等)的分类性能
最新的谱图增强方法SpecAugment对语音数据进行了实验,取得了良好的语音识别效果。据我们所知,本研究首次将SPECAMULTED方法用于心血管音频数据。该方法的实现,通过时间包裹和频率掩蔽技术有效地增强了心音频谱图,提高了分类精度。
本文的组织结构如下,第二节介绍了研究方法和数据集细节。本节还重点介绍端到端分类过程的实际实现,包括参数和超参数选择、过程和库的详细信息。研究结果和分析见第三节。第四节和第五节总结了研究,总结了新信息,提出了建议,并提出了该领域的进一步研究建议。
2.研究方法
在不同的领域和用例中,通过人工视觉技术解释音频数据已被广泛接受。这鼓励了利用音频数据集进行视觉域模型实验的想法,之前的一些工作已经显示了该方法的巨大潜力。
2.1数据集详细信息
30]创建的PASCAL心音挑战已从数字听诊器和iMobile应用程序ISethoscope Pro捕获心音数据。这两个数据集中都有长度在1到30秒之间的带标签和不带标签的原始心脏音频文件。尽管未标记的数据集可以按最终模型进行分类,但它不能用于性能度量。因此,未标记的数据集被排除在本研究之外。ISethoscope Pro(称为Dataset-A)应用程序收集的数据分为四类,即正常、杂音、额外心音和伪影。Dataset-A共有124个带标签的WAV格式音频文件和52个未带标签的WAV格式音频文件。由于这些数据是通过移动设备收集的,环境噪声主要是噪声的主要类型。iPhone麦克风要求将其压到直接皮肤上的心脏顶端区域,以44.1 kHz的采样频率捕捉心脏音频。数据集B由数字听诊器从医院收集,分为三类,即正常、杂音和早搏。这有461个标记和195个未标记的WAV格式音频文件。标记的数据集是不平衡的,其中70%的音频文件仅属于正常类别。数字听诊器以4 kHz的采样频率记录心跳音频。该数据集中的大部分噪声可归因于呼吸、肺部声音和电子推理。两个数据集中的实际心脏音频大多在频率标度的较低区域可用,而较高频率区域通常包含噪声信息。数据集描述提到使用195 Hz的低通滤波器来提取与干净心音相关的信息。每个类别中可用的数据集都具有类内相似性和类间差异,这是解决分类问题的理想方法。
帕斯卡心音挑战提出了两个问题。首先,通过分段技术识别lub(S1)和dub(S2)声音的位置。一些音频文件包含S1和S2声音的确切位置,需要借助机器学习技术来学习位置。目前的研究旨在解决第二个挑战,即需要使用适当的标签直接对心音进行分类,而不需要识别lub和dub声音的位置。数据集A和B不包括相同的类别和捕获方法、环境,采样率不同。因此,不建议将这些数据集组合起来用于自动特征提取和分类。数据集A每个类的数据较少,但似乎是平衡的。数据集B有足够的训练数据,但它反映了班级不平衡问题,其中正常组的杂音是正常组的3倍,是早搏组的8倍。这两个数据集的正常类别都表示常规和强健的心音。它将有一个清晰的润滑配音模式和一些周围的噪音。从正常的心音可以看出,舒张期比收缩期长。当人处于休息状态时,每分钟的正常心率在60到100之间。该数据集捕捉了儿童、成人在兴奋和休息状态下的心脏音频模式。杂音是几种心脏疾病的指标之一。根据是否存在其他因素,如慢性咳嗽、胸痛等,可将其确定为并发症。
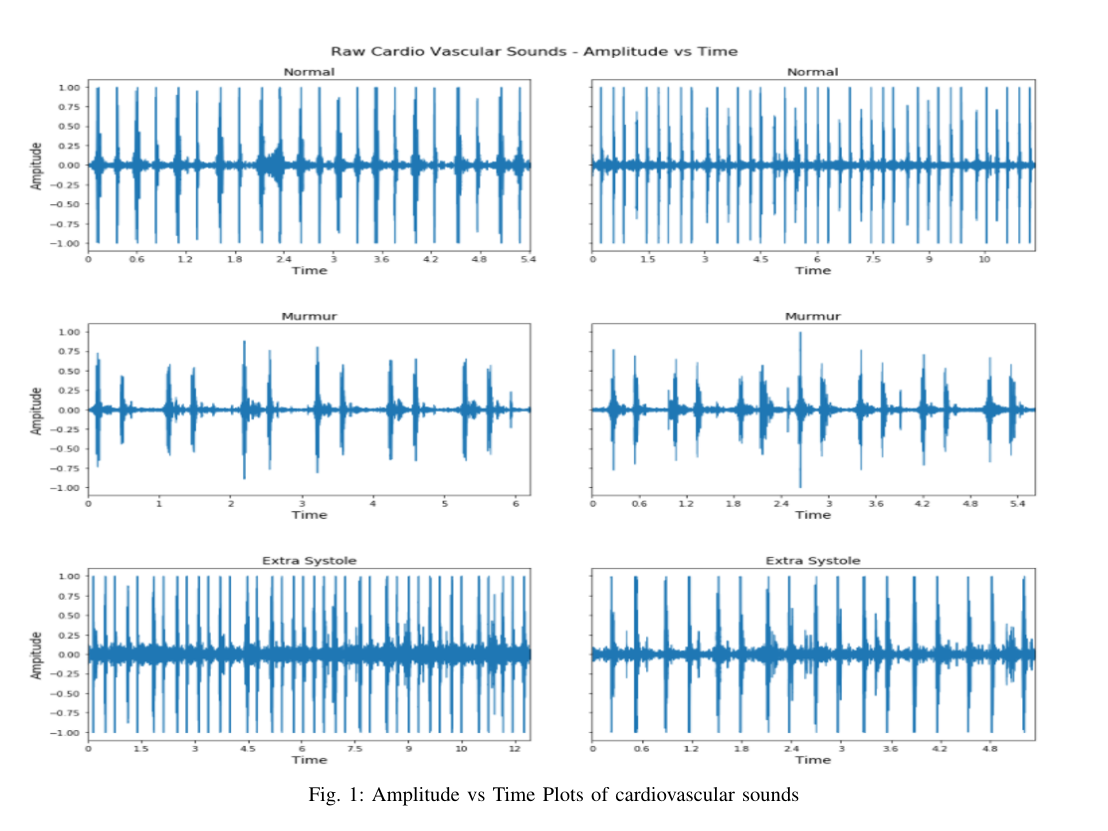
杂音可以是收缩性的,也可以是舒张性的。当心腔之间的血液流动不规则时,就会发生这种情况,这会在收缩期或舒张期产生噪音。杂音出现在S1和S2音之间,在实际心音中很少重叠。分别在S1或S2结尾处出现的规律性增加的lub或dub音可归类为额外心音。听起来像“lub-lub-dub”或“lub-dub-dub”。它有时可能是疾病的指标,但也可能是正常情况。心音的早搏模式包括随机添加或不添加lub或dub音。需要指出的是,与额外心音类别中的常规额外声音不同,额外收缩音是随机添加或删除的。早搏音可能是也可能不是疾病的症状。早搏常见于儿童,有时也可见于成人。数据的视觉分析有助于指出每个类别之间的差异。图1显示了不同心音之间的模式差异。
人造声音不包括任何可听见的心音,只包括背景噪音。由于背景环境不稳定,移动设备可以捕捉到这些声音。大多数情况下,频率大于195 Hz,仅表示噪声信息。这一类别的特征应显示出与任何其他心音类别不同的特征。伪影数据集不能提供很多关于心音的时间信息。
2.2数据预处理
本研究选择的可变长度数据集存在音频噪声、无效信息和班级不平衡。实现去噪的一种常见方法是使用低通滤波器,忽略建议的195 Hz以上的音频,以消除大部分背景噪声。理想情况下,快速傅里叶变换可以应用于信号,以识别噪声相对于原始信号的频率和振幅分量。由于截止频率已经存在,该研究将不会采用复杂的方法,如多级奇异值分解或压缩传感来消除数据集的噪声。低通或高截止滤波器设计用于通过选择的低频范围,同时拒绝更高的范围。一个带有电容器和电阻器的简单低通滤波器通常用于此目的,R是电阻器的值(欧姆),C是电容器,V是输入电压,V是输出电压。
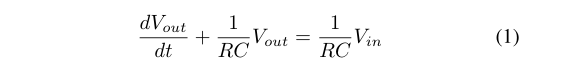
本研究将使用python Scipy信号库以编程方式实现低通滤波器。首先,利用从音频信号中提取的采样率计算奈奎斯特频率。然后用计算出的频率确定归一化截止频率。数字巴特沃斯滤波器被用来计算无限脉冲响应滤波器的分子和分母多项式。然后使用零相位滤波器以及提取的分子、分母多项式和音频信号来计算新的去噪信号。iMobile移动应用程序捕获的数据集A记录了采样频率为44100 Hz的心音。处理如此高采样率的信号需要更多的处理能力、资源和时间,因此该研究将数据集a的采样率降低了10倍。信号的数字重采样在librosa python库的帮助下实现,并在去噪操作之前进行。
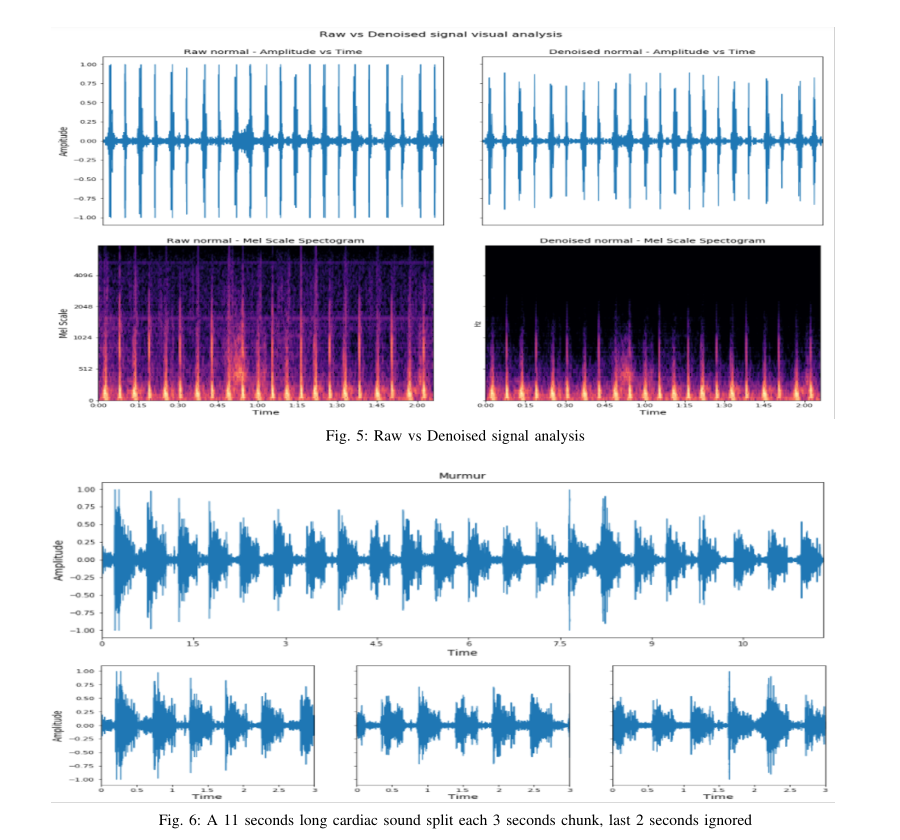
音频长度需要标准化,因为数据集中每个可用音频文件的长度不同。这项研究建议将每条录音分割3秒,以标准化音频长度。如果尾巴上有提醒部件,则丢弃。该策略也有助于消除数据集B中与听诊器相关的断开噪声。使用分割方法时,音频长度小于3秒的记录被忽略。Python库“wave”用于拆分实现,并存储输出文件以供进一步参考。数据集A没有大型心音数据库,这可能会导致泛化问题。因此,重要的是要增加数据,使每个类别不会失去其基本特征。本研究建议使用基于时间和基音偏移的音频增强技术进行初级增强。时间偏移修改音频信号的节奏而不更新音高。音调变换技术有助于心脏音频分类,因为它改变了声音本身的频率成分。使用python librosa库通过将音高向下移动半步来实现音高移动。对数据集的所有类别应用了1个单位的右移时间。
对音高和时移进行了不同的实验,其中一个单位得到了最佳值。两种应用的转换都会产生所有类别的不同数据样本。仅使用数据集A的训练数据实现了增强。数据集B在分割后已经有相当数量的音频文件;因此,音频增强技术没有用它来实现。
2.3转化为图像
有几种方法可以在频谱图表示中转换音频,即傅里叶变换、滤波器组等。一些研究,如[5]、[1]表明,使用mel尺度的频谱图在视觉域模型中表现更好。请注意,本研究将使用短时傅里叶变换方法生成对数/梅尔尺度的光谱图。作为第一步,需要借助方程式2计算短时傅里叶变换。
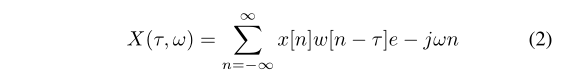
ω是基本正弦的相位,τ是时域信号x中的时间点。计算公式2要求将原始信号划分为重叠帧,然后再乘以窗函数w。两个数据集使用相同长度的快速傅里叶变换窗,其值为200。窗口功能需要应用于由成帧产生的较低频谱干扰。要绘制的STFT的生成震级可称为震级谱图。将其转换为mel频谱图需要将频率扭曲到mel尺度,并将快速傅里叶变换单元合并到mel频率单元。然后,将平方幅度谱图与Mel滤波器组相乘,得到Mel标度功率谱图。最后,利用方程3计算对数功率谱图或mel谱图。
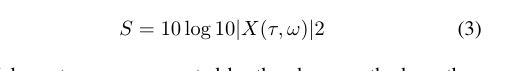
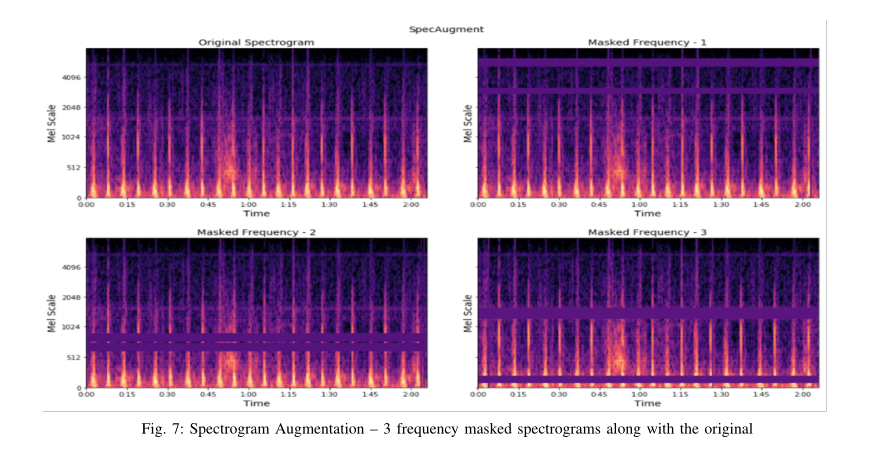
然后,将上述方法生成的Mel光谱图绘制为RGB图像,以可视化频率随时间的变化和振幅的变化,其中8000是Y轴Mel频率标度的最大值。然后,在librosa python库的帮助下,将分贝级mel谱图转换为功率谱图进行可视化。这项研究打算使用光谱图增强技术,以提高培训和验证的数据可用性,这将有助于分类的推广。[20]提出了一种语音-音频谱图增强技术,名为SpecAugment。我们的实验旨在将SpecAugment实现扩展到心音数据集。该技术提供了时间包裹和频率块屏蔽的频谱图。频谱图增强仅直接应用于去噪和标准化原始音频数据集,而不应用于音频增强样本。对于数据集A,每个可用频谱图(包括使用SpecAugment的音频增强数据集)生成一个时间包装图像和两个频率屏蔽图像。数据集B中的每个谱图图像都经过一次时间包裹和一次频率掩蔽变换。本研究使用了一种使用NumPy和SciPy库的specAugment的简化实现[24]。所有增强彩色光谱图图像的像素值都需要在0到1之间进行缩放以进行归一化,然后才能用于深度学习模型。研究所用图像的像素值在255到1之间变化,因此只需将值除以255即可将值缩放到所需范围。然后重新调整标准化图像的大小,以适应模型训练所需的内存和批处理能力。研究发现,根据训练过程中使用的硬件容量,将所有光谱图图像调整为128*128维可以产生最佳效果。然后,对图像的数字版本进行洗牌,以满足IID(独立且相同分布)假设。
2.4数据分割和类平衡
该研究建议列车和测试数据按70:30的比例分割。最佳实践建议使用验证数据集来确保模型性能良好。由于可用数据集的大小已经变小,进一步拆分以进行验证将导致训练数据集不足。用于从训练集中生成更多数据集的增强技术。然后,可以以80:20的比例使用增强数据,其中20%的增强数据将用于验证目的。测试数据集未使用增强技术。
数据集A的杂音和正常样本数量相似,约为伪影类别出现次数的一半。对工件类应用了下采样方法,其中属于该类的数据集的50%被随机消除。该技术平衡了伪影、正常和杂音类。extrahls类仍然存在类不平衡,尽管该方法增加了类的权重值。数据集B显示了类似的趋势,其中62%的数据集属于“正常”类,而最低频率的“额外声音”类仅占数据集的8%。数据集B中的杂音类的频率为30%。为了平衡正常类别和杂音类别,需要移除大量样本,这可能会影响类别的数据分布。由于这种不平衡的类不平衡,任何类的下采样或上采样可能都无法有效工作,因此该技术未应用于数据集B。另一种处理这种不平衡的已知有效技术称为类权重。这种方法确定每门课的权重,并在训练时分配计算值。训练时使用班级权重参数可以改变损失的范围。损失将成为加权平均值,并有助于相应地调整SoftMax结果。每个类的权重计算为类的出现次数除以训练数据集中可用的记录数。综上所述,数据集A既包括下采样,也包括类别加权,以处理类别不平衡,而数据集B仅包括用于此目的的类别加权技术。
2.5评估
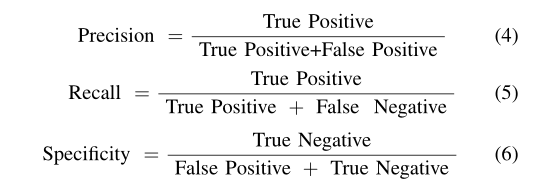
作为一个多类别的分类问题,模型评估的一些合适的度量是分类准确度、精确度、召回率、特异性、AUROC等。精确度和召回率分别关注真实的正面和真实的负面,因此,有助于在不平衡的数据集中产生见解。ROC测量下的面积显示了模型区分不同类别的能力。AUROC分数是在精确度和召回率的帮助下计算出来的,因此也可以作为不平衡数据集的稳健指标。精确性、召回率和特异性的方程分别显示在方程#4、5、6中。
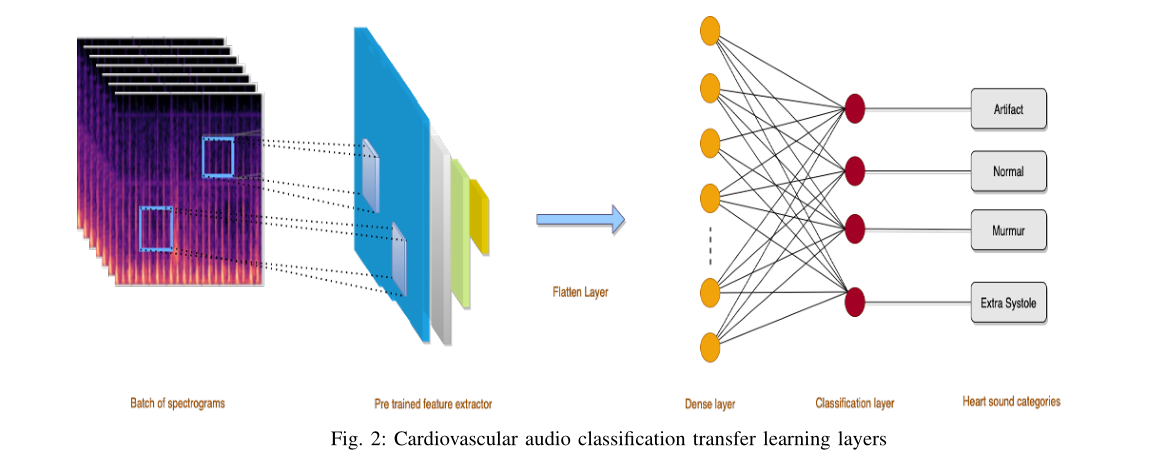
2.6视觉域神经网络
卷积神经网络是一种先进的结构,擅长处理图像和视频等视觉数据。CNN彻底改变了以前被认为非常困难的视觉领域的分类任务。CNN的架构受到动物视觉系统的启发,最近它在分类准确度方面超过了人类。一个常见的CNN架构将由几个卷积块组成,然后迭代地合并层,直到特征图的矩阵大小足够小,可以容纳密集层。特征映射被转换为一个特征向量,然后作为输入发送到稠密层和分类层进行分类。
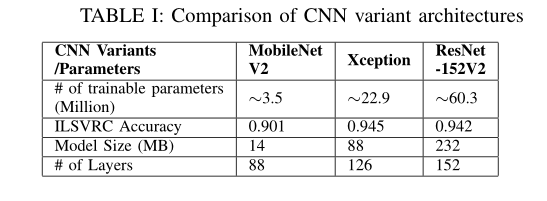
虽然常见的CNN体系结构可以为某些数据集带来良好的性能,但像ImageNet挑战这样的复杂问题需要更复杂的网络设计。据观察,叠加更多的卷积、合并层会在某一点之前产生更好的精度,之后添加更多层会导致信息丢失。[4]中比较了一些基于CNN的高效网络。本文比较了精度、操作次数、网络参数数量、训练和测试时间、功率要求、每个网络参数的精度密度等。结果表明,精度较高的模型需要大量的计算时间,而模型参数量较大。因此,需要在参数数量和精度之间进行权衡。本研究旨在以良好的精度分类心音,但也将考虑模型的实际使用。未来的应用可能包括实时环境中的心音分类器,即移动设备;因此,预测速度将非常重要。因此,研究需要在高精度和少量参数之间找到平衡。[12]提出的ResNet和[23]提出的MobileNetV2似乎是这方面的两个很好的体系结构,具有良好的ImageNet精度分数。ResNet152V2[13]和MobileNetV2分别有6000万和350万个可训练参数。该研究还将包括对这两个数据集的MobileNet[14]、InceptionResNetV2[25]和Exception[6]等网络进行实验。表一捕获了一些CNN变体模型的数据点。
2.7ResNet-152V2
剩余学习网络(ResNet)是CNN的一种变体,它可以有效地进行更深层次的网络学习。ResNet借助剩余学习避免了更深层次网络的消失/爆炸梯度问题。在剩余网络中,当输入和输出维度与堆叠卷积块相同时,可以插入快捷方式或跳过连接。跳过连接将第一个卷积块的输入添加到两层堆栈中下一个卷积块的输出。当输入和输出大小不同时,快捷键可以用零填充输出,或者借助1*1卷积投影以匹配尺寸。这有助于通过身份映射明确地重新构造层,以解决退化问题。快捷连接允许渐变通过自身流动,这有助于缓解渐变消失的问题。ResNet的identity功能确保后续层的学习至少与前一层相同(如果不是更好的话)。ResNet研究还引入了瓶颈块的使用,瓶颈块分别堆叠了1*1、3*3和1*1内核的三个卷积块,而不是更深层次的网络的两层。无参数身份快捷方式在基于瓶颈的ResNet体系结构中表现出更好的性能。152层ResNet使用3层瓶颈取代了ResNet-34的2层块,从而提高了ImageNet挑战的准确性。[13]将ResNet152V2描述为原始ResNet152的预激活整流线性单元(RELU)。
2.8MobileNetV2
MobileNet专注于构建[14]引入的轻量级高效视觉域深度神经网络。它的核心是基于深度可分离卷积的,这使得计算量比标准卷积少9倍,同时只牺牲了少量的精度。宽度和分辨率乘数超参数旨在优化分类器延迟和精度之间的权衡。MobileNetV2由[23]于明年推出,其设计采用了反向残余结构,在薄瓶颈层之间具有快捷连接。MobileNetV2被发现是MobileNetV1的重大升级,并展示了一些近实时视觉分类领域问题的最新结果。MobileNetV2引入了架构中新引入的层间线性瓶颈之间的跳过连接。实验发现,与MobileNetV1相比,MobileNetV2需要一半的操作和30%的参数,同时实现了更好的精度。
2.9迁移学习
迁移学习是从人类学习过程中获得灵感而形成的概念。人类社会通过一代一代地传递知识,然后再增加知识来获取知识。迁移学习是一个概念,在这个概念中,为特定任务构建的一个模型被重新用于不同的任务。人工智能实现的主要挑战之一是高质量标记数据集的可用性。在深度学习领域,考虑到相关数据集的可用性,训练健壮且可伸缩的模型需要大量的图像和文本数据计算资源。常用的迁移学习任务是选择一个适合该任务的预训练模型,完全重用该模型而不进行任何权重更新,并选择通过更新最后几层的权重来调整模型。迁移学习可以被认为是一种节省时间、成本和资源的优化机制。与从头构建的模型相比,转移学习模型的准确性也更高,因为转移学习模型从可用的标记分类数据集中学习了特征表示,并且通常能够更好地概括。这项研究将在跨导学习中进行实验,其中预先训练的模型来自视觉领域,但目标应用领域是心音。
2.10提议的方法
几个预定义的特征提取器在这项研究中试验了不同的分类要求配置。在实验过程中,评估了使用现有模型而不进行任何权重增强、更新最后几层的权重以及调整所有层的权重等方法。
培训过程中使用了所有型号的一些通用配置。所有实验在RGB通道上以128*128的一致输入大小运行。不同的值,如224*224、164*164和100*100也进行了实验,但没有一个比所选维度表现更好。批量大小保持为8,以确保训练过程不会耗尽内存。采用Keras图像数据发生器方法,在训练时提供运行时数据,并确保对每个历元的数据进行洗牌。在本研究中,所有用于转移学习的预定义特征提取程序都忽略了最后一层,以确保学习到的特征映射仅用于心血管音频分类。 在所有优化器配置上,已根据定义的学习速率和时间动态启用学习衰减率。衰减值定义为学习率除以所有实验中本研究的历次次数。所有预定义的功能提取器架构都加载了ImageNet初始化权重。之前计算的班级权重已分配给所有类别,以确保在培训过程中计算加权损失。基于Tensorflow的“Keras”python库用于培训、验证和测试目的。
预先训练的网络提取有意义和详细的特征图,然后用于进一步分类。这些特征图需要首先展平,而不影响批量大小。例如,如果特征地图的尺寸为(64*10*10),其中64是批量大小,输入的形状为10*10,则展平层的输出大小为64*100。展平层的输入和输出大小将根据使用的预训练网络而变化。为了阻止神经网络过度拟合,一些正则化技术可用于神经网络,如L1、L2、DropOut等。本研究在两个完全连接的层之间使用DropOut和batch normalization层,只要训练导致模型过度拟合。并不是所有的实验都包括这些层,并被用作需求基础。辍学值为0.2、0.3、0.35等,在不同的体系结构中进行实验。密集层用于处理扁平层的输入,然后通过激活和计算的权重和偏差对其进行转换。然后,这些转换后的信号被传递到另一个密集的完全连接层,以便在两个数据集的心血管音频之间进行分类。第一个全连接层使用整流线性激活函数或ReLU作为激活函数,第二层使用SoftMax作为激活函数。第一个密集层配置为实验32、64、128、500和1000个神经元。数据集A和B分别有4类和3类心血管音频数据。因此,根据输出类别,数据集A和B的最后一层神经元数量分别为4和3。
在这项研究中进行实验的优化器将是随机梯度下降(SGD)和ADAM。对于SDG优化器,动量值始终被视为0.9。实验中的学习率分别为0.01、0.001和0.0001。评估的年代数在10到40之间。本研究使用分类交叉熵作为损失函数,因为心血管音频分类检测是一个多类分类问题。分类交叉熵损失是区分两个离散概率分布的一个有力指标。随着分布越来越接近,损失也越来越小。从数学上讲,分类交叉熵通过方程7得到解析,其中y是实际标签,p是预测标签。损失函数要求将输出定义为一个热向量,因此需要相应地转换类标签。最后一层的激活函数是一个SoftMax函数,支持分类交叉熵作为损失函数。
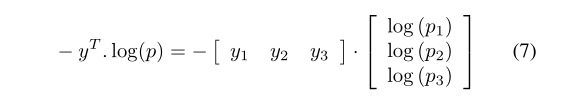
回调可以帮助自动化某些任务,例如根据选定的标准保存最佳模型、根据某些指标的值提前停止培训,或者在没有培训改进的情况下降低学习率。当培训过程注意到已经执行的迭代的验证损失最小时,当前的研究继续使用该模型。python Keras库的reducelRonplation函数有助于等到执行了定义数量的历元,而所选指标没有改善,然后将学习率降低一个已声明的因子。在这项研究中,耐心水平被定义为5个阶段,学习率折减系数为0.2。
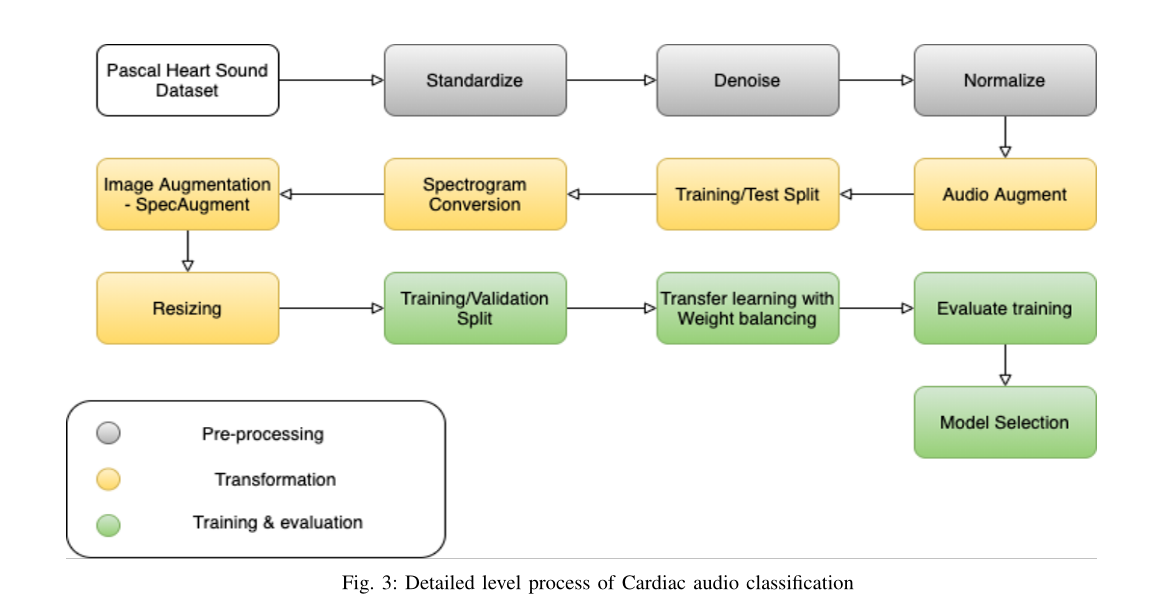
3 结果与分析
分别对数据集A和B进行了实验,并将根据关键性能指标分别进行比较。基于训练、验证和测试性能,将评估不同的预训练视觉域卷积神经网络结构,并在最后几层进行一些更新。为不同心音类别生成的频谱图在视觉上是可分离的。光谱图的上半部分大部分是黑色的,因为在去噪过程中过滤掉了更高的频率范围。还将对结果进行分析,以了解最适合心血管音频分类的模型。
成功实现了音频文件分割机制,例如,如果一条记录的长度为11秒,则将其分割为3个部分,即1-3秒、4-6秒和7-9秒。包括第10秒和第11秒的部分被忽略;图5给出了一个示例。光谱图增强技术有助于增加可用图像的数量,以便更好地训练适用的视觉域神经网络。本研究对不同层进行了批量标准化实验,但没有发现模型性能有任何改善,因此在最终实验中被忽略。大多数模型在最后一个致密层的64个神经元以及结构的其余部分中表现良好,因此本研究选择了相同数量的神经元进行最终实验。

3.1数据集A上的实验结果
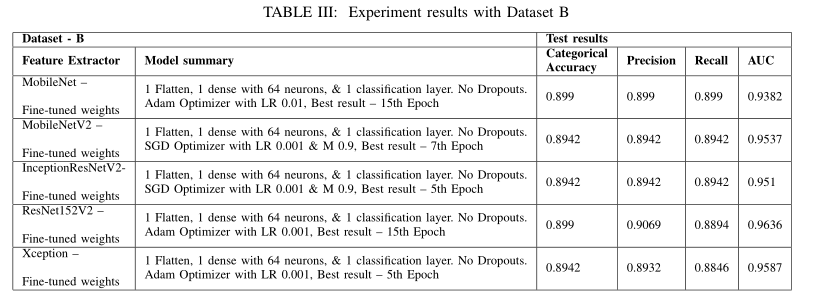
数据集A捕获音频的采样频率为44100 Hz。这样的高采样频率可以捕获准确的音频信息,并产生更大的文件大小。在神经网络训练期间,一批这些数据将直接加载到内存中,以满足分类要求。这导致在训练过程中出现记忆不足问题。对数据集A的所有心血管音频样本进行了10倍的降采样,以减少文件大小和信息分布。使用采样频率为4410 Hz的新生成文件的操作速度更快,并且未观察到内存不一致问题。数据集很小,分割后只包含291个样本,而41%的样本属于工件类别。除音频增强步骤外,它使用前面提到的所有步骤进行预处理。然后使用生成的和增强的光谱图图像对一些样本模型进行训练。预先训练的神经网络,即MobileNet、MobileNetV2、ResNet152V2等,根据更新的类权重进行调整。由于数据较少,训练过程很快,但分类性能并不令人满意。除音频增强外,最高的测试分类准确度值为0.81,准确度为0.84,召回率为0.74。
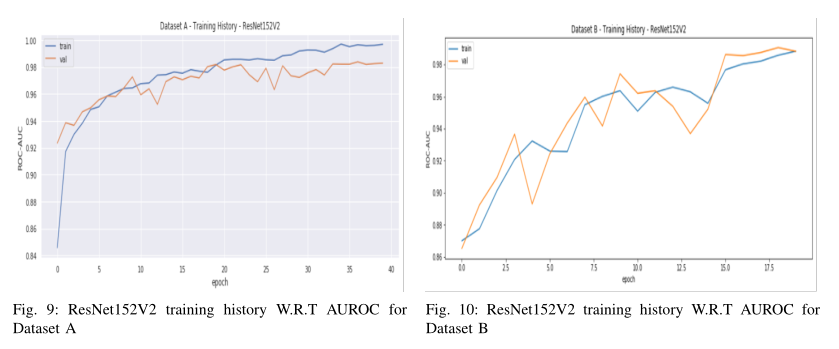
然后用选定的训练数据集实现音频增强技术,该数据集生成2倍的添加音频文件,并带有音调和时间偏移。在音频增强后,训练数据集包含1500个样本,验证集包含500个样本。ResNet152V2是本研究中使用心血管音频测试的最大预训练网络。加入后展平和分类层,使用随机梯度下降优化器对网络进行训练。当学习率和动量值分别设置为0.001和0.9时,该网络实现了最佳关键性能指标。采用0.35的退出值作为正则化步骤,同时将输入从上一个包含64个神经元的密集层传输到最后一个分类层。训练过程一直持续到40个阶段,第35个阶段的成绩最好。测试数据评估显示,测试损失为0.3942,分类准确度为0.9041,准确度为0.9041,召回率为0.9041,AUROC为0.9797。
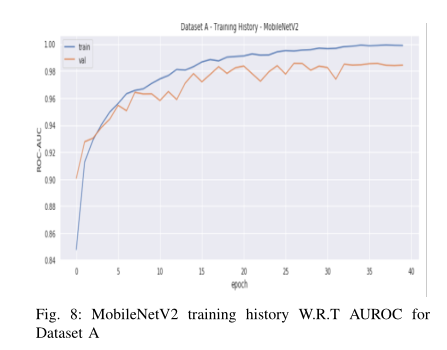
MobileNet网络作为预训练层,然后进行平坦化和两个密集层,也可以获得良好的分类结果。它以0.001的学习率实现了Adam优化器,并为ImageNet预先训练的MobileNet网络重用现有权重。模型培训期间未使用辍学或批量标准化。该实验被配置为15个阶段,但在第12个阶段获得了最佳结果。结果测试指标为测试损失为0。5142,分类准确度为0.8767,精密度为0.8767,召回率为0.8767,AUROC为0.9629。ImageNet预先训练了MobileNet V2网络,以及两个完全连接的层,使用与MobileNet网络类似的设置进行实验。在使用随机梯度下降优化器、0.001倾斜率和0.9动量值执行训练过程的情况下,发现了最精细的模型。作为一个正则化步骤,当输入从上一个包含64个神经元的密集层传递到最后一个分类层时,使用0.3的退出值。当在数据集A的训练过程中未更新现有的预训练权重时,观察到最佳结果。使用所述配置设置了40个历元,并在第33个历元发现了最高结果。测试损失为0.4516,分类准确率为0.8767,精密度为0.8873,召回率为0.863,AUROC为0.9585。由于年代较少,MobileNet所需的培训时间比MobileNet V2少。图8显示了基于MobileNet V2的AUROC评分模型的培训历史。
评估了其他几种预训练网络,即不同设置的InceptionResNetV2、Exception和DenseNet169,结果见表II。实验表明,基于ResNet152V2的模型是数据集A的最佳分类器,具有最高的AUROC、分类准确率、精确度和召回率。基于MobileNet和MobileNet V2的模型也显示了数据集的可靠分类性能指标。这三个模型都没有微调任何预先训练的权重,而是将ImageNet权重重新用于光谱图图像的特征提取。因此,可以得出结论,基于图像域CNN的模型可以从音频域频谱图中提取合适的低层和高层特征,然后可以成功地用于心血管声音分类。有关AUROC分数的基于ResNet152V2的模型的培训历史可在图9中找到。
3.2数据集B上的实验结果
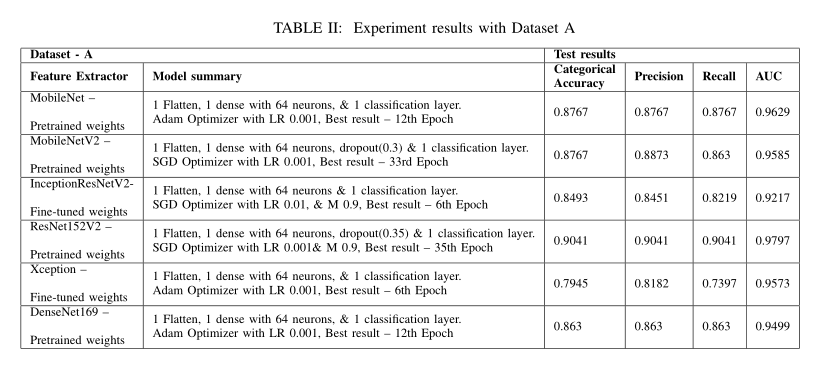
以4000 Hz的采样频率记录数据集B的心血管音。这进一步不需要任何重新采样,因为采样频率已经较低,并且为分类提供了足够的信息。数据集B在最初将每个音频文件分割为3秒钟的数据块后,总共包含758个样本。通过微调预训练网络的权重,对ResNet152V2以及平坦层和分类层进行训练,以获得数据集B的最佳分类度量。使用Adam optimizer(0.001)作为学习率对模型进行训练,并在第15个纪元期间获得最佳结果。增加辍学或批量标准化并没有显示出培训绩效的任何改善。使用看不见的测试数据评估测试结果,导致测试损失为0.3697,分类准确度为0.899,精密度为0.9069,召回率为0.8894,AUROC为0.9636。MobileNetV2嵌入式网络训练过程使用随机梯度下降优化器以及0.001学习率和0.9值执行,以获得定义指标的最佳结果。将其配置为10个历元的训练,在第7个历元发现最佳结果。该模型使用预先训练好的MobileNetV2网络的微调权重,获得了最好的结果。基于MobileNetV2的网络获得的最佳结果是测试损失为0.5691,分类准确率为0.8942,精确度为0.8942,召回率为0.8942,AUROC为0.9537。
其他经过评估的预训练特征提取器包括MobileNet、InceptionResNetV2和Exception以及分类网络。所有进行的实验都得出结论,基于ResNet152V2的模型对数据集B的分类效果最好。使用该模型进行的测试数据评估的AUROC为0.96,分类准确度为0.9069。MobileNetV2和基于异常的网络都可以被视为数据集B的良好分类器,因为它们的AUROC得分为0.95,分类准确率为0.894。当预先训练好的网络的所有层都被适当地微调时,数据集B的所有实验结果都会更好。这可能是因为基于体重的减肥计算,而数据集中的训练过程包含严重的班级不平衡。表3显示了使用数据集B对所有经过预训练的基于视觉域的神经网络进行实验的验证和测试分数。
4 模型评估与讨论
实验结果证明了视觉域神经网络对心血管音频数据集的适用性,主要是因为预先训练的图像域知识能够很好地识别心音频谱图的低层和高层特征。将每个音频文件拆分为多个3秒钟的块有助于保留有用的心血管声音信息,并增加可用于分类的样本数量。频谱图增强技术在心血管音频数据集上的应用也被证明是成功的,它提高了分类精度和AUROC分数。音频增强技术,如时间和基音偏移来增加音频样本的数量,对数据集A的分类结果非常有效。
基于ResNet152V2的特征提取器被发现是两个数据集特征的顶级标识符,对于数据集A和B,分类网络AUROC得分分别为0.9797和0.9636。所有层的ImageNet预训练权重都用于数据集A的分类,而所有层的权重都在数据集A的训练过程中进行了微调数据集B。基于MobileNet的功能提取器系列还展示了识别两个数据集的详细功能的良好能力。由于基于MobileNet的特征提取器体积小,在训练过程中速度非常快,因此可以在移动设备中用于近实时的解释和特征提取。在分类网络AUROC得分分别为0.9585和0.9537的数据集a和B中,发现MobileNet V2在特征识别方面更稳定。与ResNet152V2类似,预训练的图像净重用于所有层,对数据集A的分类没有变化,而在训练数据集B时调整所有层的权重。这种现象可能与数据集之间的类别不平衡程度有关。数据集B的训练过程包括班级权重平衡和权重交叉熵损失计算。这可能就是为什么对所有层进行微调会使使用数据集B进行实验的所有网络的模型性能更好的原因。
大多数其他经过实验的网络也产生了良好的分类指标。i、 e.DenseNet用于数据集A,ExceptionNet用于数据集B。结果证明了将视觉领域知识转化为音频领域数据分类的方法的有效性。ImageNet学习的权重有助于提取所需的心血管音频特定特征,如识别峰值、杂音噪声、额外的声音峰值等,从而获得更好的分类指标得分。该研究实验的方法可以普遍用于心音的训练和分类,具有良好的分类准确性、精确度、AUROC等。
5 结论和建议
基于ResNet152V2的特征提取器具有152层和6030万个参数,使其成为大型ImageNet训练的预训练网络之一。尽管分类准确率和AUROC分数较高,但推断时间也较高。MobileNetV2仅包含350万个参数,使其成为实验性预训练网络中速度最快的特征提取程序之一。使用MobileNet V2提取特征的分类网络也为数据集a和B获得了良好的AUROC,因此它可以用于近实时推理需求的分类。但是,如果分类精度比推理所需的时间更重要,建议使用具有以下分类网络的基于ResNet152V2的特征提取器进行推理。
5.1知识贡献
在以前的研究中,基于领域的特征提取技术已被用于手动识别心血管数据集的适当特征。据我们所知,没有一项研究探索了心血管音频数据集的图像域转移自动特征提取和分类。这项研究成功地证明了如何使用视觉域神经网络作为特征提取器,对心脏音频数据进行高精度分类。本研究中描述的方法可进一步用于其他心血管数据集的训练和预测高水平类别。基于ResNet152V2和MobileNetV2的特征提取器以及以下分类层被发现是Pascal心音分类挑战中提出的心血管数据集的良好分类器。最新的谱图增强方法SpecAugment对语音数据进行了实验,取得了良好的语音识别效果。据我们所知,本研究首次将SPECAMULTED方法用于心血管音频数据。该方法的实现通过时间包裹和频率掩蔽技术有效地增强了心音频谱图,总体上提高了分类精度。
5.2研究局限性
本研究中使用的方法可普遍用于训练和分类任何心音数据集,以对标签进行分类,如正常、杂音、早搏、早搏等。本研究考虑的是,借助mel标度频谱图,心血管音频在视觉上可区分这些类别。现在,如果心音的任何分类在视觉上无法区分,本研究中提出的方法可能不适用。该研究也没有确定S1、S2峰值或杂音的确切位置,以对心音进行分类。研究中讨论的方法可能无助于在给定的心血管音频中识别这些位置。
5.3未来的工作
这项研究提出了一种简单的方法来去除音频文件中的噪声,方法是使用低通滤波器来消除192Hz以上的任何声音。这可能已经消除了一些杂音和心音,也可能存在低频外部噪声与低于阈值频率的心音混合的情况。可以研究一种去噪方法来处理这些复杂的场景,从而产生适合分类的去噪音频。数据集A和B由1到30秒不等的音频长度组成。这项研究选择了3秒作为分割每个音频文件的标准,因为整个心音周期应该在这一时间范围内覆盖。任何长度小于3秒的音频都被丢弃,因为它不包含分类所需的足够信息。作为未来的工作,如果这会影响分类性能,可以增加该持续时间,并使用其他值进行试验。目前的研究使用数据集A实现音频增强技术,并使用两个数据集实现频谱图增强技术。作为未来的建议,可以使用数据集B测试时间和基音偏移等音频增强技术。SpecAugmentation可用于为每个原始谱图生成更多频率屏蔽谱图,以检查它是否有助于提高分类性能。音频增强技术,如时间拉伸和音量增益,可以应用于这两个数据集。未来的另一个建议是将输入图像大小从128*128增加到224*224,以实现更好的特征提取。预处理步骤和训练过程需要在高内存配置的GPU环境中执行,以实现这一点。
参考文献
[1] Adapa, S., (2019) Urban Sound Tagging using Convolutional Neural Networks. In: Proceedings of the Detection and Classification of Acoustic Scenes and Events 2019 Workshop (DCASE2019). [online] New York University, pp.5–9. Available at:https://arxiv.org/pdf/1909.12699.pdf.
[2] Bhoi, A.K., Sherpa, K.S. and Khandelwal, B., (2015) Multidimensional analytical study of heart sounds: A review. International Journal Bioautomation, 193, pp.351–376.
[3] Boddapati, V ., Petef, A., Rasmusson, J. and Lundberg, L., (2017)Classifying environmental sounds using image recognition networks.Procedia Computer Science, [online] 112,pp.2048–2056. Available at:http://dx.doi.org/10.1016/j.procs.2017.08.250.
[4] Canziani, A., Paszke, A. and Culurciello, E., (2016) An Analysis of DeepNeural Network Models for Practical Applications. [online] pp.1–7.Available at: http://arxiv.org/abs/1605.07678
[5] Choi, K., Fazekas, G. and Sandler, M., (2016) Automatic tagging using deep convolutional neural networks. [online] Available at:http://arxiv.org/abs/1606.00298.
[6] Chollet, F., (2017) Xception: Deep Learning with Depthwise SeparableConvolutions. In: 2017 IEEE Conference on Computer Vision andPattern Recognition (CVPR). [online] IEEE,pp.1800–1807. Availableat: http://ieeexplore.ieee.org/document/8099678/.
[7] Deng, S.-W. and Han, J.-Q., (2016) Towards heart sound classificationwithout segmentation via autocorrelation feature and diffusion maps.Future Generation Computer Systems, [online] 60, pp.13–21. Availableat: http://dx.doi.org/10.1016/j.future.2016.01.010.
[8] Deng, Y . and Bentley, P ., (2012) A Robust Heart Sound Segmentation and Classification Algorithm using Wavelet Decompositionand Spectrogram. Extended Abstract in the First PASCAL HeartChallenge Workshop, held after AISTATS. [online] Available at:http://www.peterjbentley.com/heartworkshop/challengepaper3.pdf.
[9] DeVries, T. and Taylor, G.W., (2017) Improved Regularization ofConvolutional Neural Networks with Cutout. arXiv. [online] Availableat: http://arxiv.org/abs/1708.04552.
[10] Godfrey, J.J., Holliman, E.C. and McDaniel, J., (1992) SWITCH-BOARD: telephone speech corpus for research and development. In:[Proceedings] ICASSP-92: 1992 IEEE International Conference onAcoustics, Speech, and Signal Processing. [online] IEEE, pp.517–520vol.1. Available at: http://ieeexplore.ieee.org/document/225858/.
[11] Gwardys, G. and Grzywczak, D., (2014) Deep Image Features inMusic Information Retrieval. International Journal of Electronics andTelecommunications, [online] 604, pp.321–326.
[12] He, K., Zhang, X., Ren, S. and Sun, J., (2016a) Deep residual learningfor image recognition. Proceedings of the IEEE Computer SocietyConference on Computer Vision and Pattern Recognition, 2016-Decem,
pp.770–778.
[13] He, K., Zhang, X., Ren, S. and Sun, J., (2016b) Identity Mappingsin Deep Residual Networks. In: Lecture Notes in Computer Science(including subseries Lecture Notes in Artificial Intelligence and LectureNotes in Bioinformatics). [online] pp.630–645.
[14] Howard, A.G., Zhu, M., Chen, B., Kalenichenko, D., Wang, W., Weyand,T., Andreetto, M. and Adam, H., (2017) MobileNets: Efficient convolu-tional neural networks for mobile vision applications. arXiv.
[15] Inoue, H., (2018) Data Augmentation by Pairing Samplesfor Images Classification. arXiv. [online] Available at:http://arxiv.org/abs/1801.02929.
[16] Nasrullah, Z. and Zhao, Y ., (2019) Music Artist Classification withConvolutional Recurrent Neural Networks. arXiv. [online] Available at:http://arxiv.org/abs/1901.04555.
[17] O’Shea, K. and Nash, R., (2015) An Introduction to Con-volutional Neural Networks. [online] November. Available at:http://arxiv.org/abs/1511.08458.
[18] Palanisamy, K., Singhania, D. and Yao, A., (2020) Rethinking CNN
Models for Audio Classification. [online] November. Available at:
https://arxiv.org/pdf/2007.11154.pdf.
[19] Panayotov, V ., Chen, G., Povey, D. and Khudanpur, S., (2015) Lib-
rispeech: An ASR corpus based on public domain audio books. In:
2015 IEEE International Conference on Acoustics, Speech and Sig-
nal Processing (ICASSP). [online] IEEE, pp.5206–5210. Available at:
http://ieeexplore.ieee.org/document/7178964/.
[20] Park, D.S., Chan, W., Zhang, Y ., Chiu, C.-C., Zoph, B., Cubuk, E.D.
and Le, Q. V ., (2019) SpecAugment: A Simple Data Augmentation
Method for Automatic Speech Recognition. Proceedings of the An-
nual Conference of the International Speech Communication Associ-
ation, INTERSPEECH, [online] 2019-Septe, pp.2613–2617. Available
at: http://arxiv.org/abs/1904.08779.
[21] Raza, A., Mehmood, A., Ullah, S., Ahmad, M., Choi, G.S.
and On, B.-W., (2019) Heartbeat Sound Signal Classification Us-
ing Deep Learning. Sensors, [online] 1921, p.4819. Available at:
https://www.mdpi.com/1424-8220/19/21/4819.
[22] Salamon, J. and Bello, J.P ., (2017) Deep Convolutional Neural Net-
works and Data Augmentation for Environmental Sound Classification.
IEEE Signal Processing Letters, [online] 243, pp.279–283. Available at:
http://ieeexplore.ieee.org/document/7829341/.
[23] Sandler, M., Howard, A., Zhu, M., Zhmoginov, A. and Chen, L.C.,
(2018) MobileNetV2: Inverted Residuals and Linear Bottlenecks. Pro-
ceedings of the IEEE Computer Society Conference on Computer Vision
and Pattern Recognition, pp.4510–4520.
[24] Sun, K.J., (2019) SpecAugment Implementation with SciPy. Available
at: https://github.com/KimJeongSun/SpecAugment numpy scipy [Ac-
cessed 4 Jan. 2021].
[25] Szegedy, C., Ioffe, S., V anhoucke, V . and Alemi, A., (2016) Inception-
v4, Inception-ResNet and the Impact of Residual Connections on
Learning. 31st AAAI Conference on Artificial Intelligence, AAAI 2017,
[online] pp.4278–4284.
[26] Zhang, H., Cisse, M., Dauphin, Y .N. and Lopez-Paz, D., (2017a) mixup:
Beyond Empirical Risk Minimization. arXiv, [online] pp.1–13. Available
at: http://arxiv.org/abs/1710.09412.
[27] Zhang, W., Han, J. and Deng, S., (2017b) Heart sound classifica-
tion based on scaled spectrogram and tensor decomposition. Expert
Systems with Applications, [online] 84, pp.220–231. Available at:
https://linkinghub.elsevier.com/retrieve/pii/S0957417417303305.
[28] Zheng, Y ., Guo, X. and Ding, X., (2015) A novel hybrid energy fraction
and entropy-based approach for systolic heart murmurs identification.
Expert Systems with Applications, [online] 425, pp.2710–2721. Avail-
able at: http://dx.doi.org/10.1016/j.eswa.2014.10.051.
[29] Zhong, Z., Zheng, L., Kang, G., Li, S. and Yang, Y ., (2017) Random
Erasing Data Augmentation. Proceedings of the AAAI Conference on
Artificial Intelligence, [online] 3407, pp.13001–13008. Available at:
https://aaai.org/ojs/index.php/AAAI/article/view/7000.
[30] Bentley P . and Nordehn G. and Coimbra M. and Mannor S,
The PASCAL Classifying Heart Sounds Challenge 2011. Available:
http://www.peterjbentley.com/ heartchallenge/index.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号