
day28 正则的练习
作业题目
答题要求
- 可以参考老师的正则,理解题意后,自己再写出1种及以上的正则方案
1.看懂老师写的正则,参考,思路的提供
2.自己再去写出另一种正则,即使你就是多了一个字符
练习题
测试数据:
I am teacher yuchao.
I teach linux,python.
testtttsss000123566666
I like video,games,girls
#I like girls.
$my blog is http://yuchaoit.cn/
#my site is https://www.cnblogs.com/pyyu
My qq num is 877348180.
my phone num is 15210888008.
-
^查找以什么开头的行找出以
I开头的行
grep -n '^I' test.txt
'^字符'

-
$查找以什么结尾的行
找出以u结尾的行
结尾字符$
grep -n 'u$' test.txt

找出以.结尾的行
为了最大程度的降低,字符的特殊含义,别用双引号,否则你要考虑加很多的转义符
grep '\.$' -n t1.log
grep -n '\.$' test.txt

-
^$ 查找和排除空行
-
^ $ ^$ 提取出空白行,没有内容的行,连空格都没有的
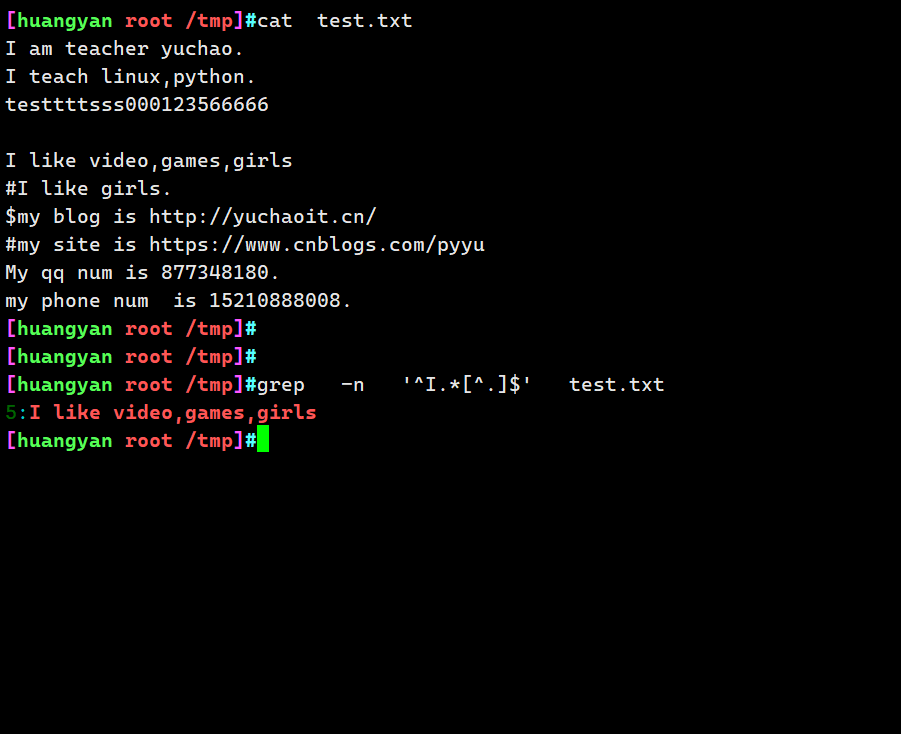
找出以I开头,s结尾的行
grep -n '^I.*s$' test.txt
Is
Ias
Iaaaaaaaaaaaas
IbS
I qs

找出空白行
# 匹配空行的正则
grep -n '^$' test.txt
# grep -v结果取反
grep -nv '.' test.txt

排除空行,提取有益的信息行
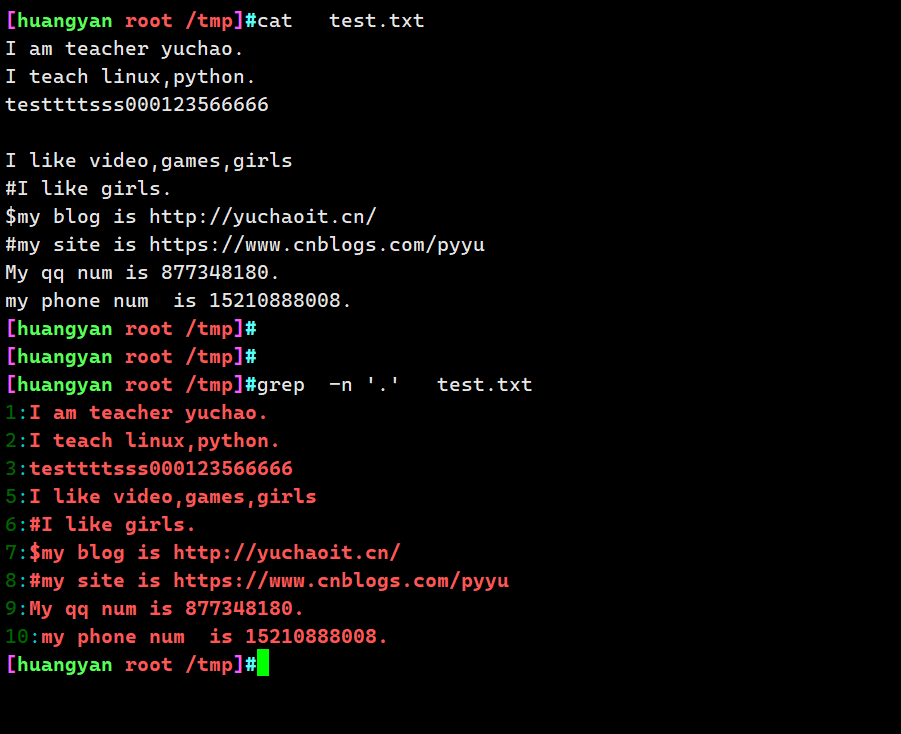
grep -n '.' test.txt
grep -n -v '^$' test.txt


4..任意一个字符 不会匹配空行 、可以匹配空格,注意这里的点是正则符、而不是普通的点
grep -n '.' test.txt
5.\转义特殊字符
找出以$开头的行
grep -n '^\$' test.txt
#暂时武略这种写法
grep -n "^\\s" test.txt

-
[ ]匹配字符
匹配小写字母
grep -n '[a-z]' test.txt
grep -n '[[:lower:]]' test.txt

找出以.或s结尾的行
grep -E '\.$|s$' t1.log
egrep '\.$|s$'
grep -E '(\.|s)$' t1.log
grep -E '[.s]$' t1.log
grep -E '[\.s]$' t1.log
grep -n '[.s]$' test.txt

找出以I开头,且结尾不是.的行
grep -E '^I.*[^\.]$' t1.log
grep -n '^I.*[^.]$' test.txt
7) -i 忽略大小写匹配
grep -i '^i' test.txt

扩展正则练习题
准备测试数据
I am teacher yuchao.
I teach linux,python.
testtttsss000123566666
I like video,games,girls
#I like girls.
$my blog is http://www.yuchaoit.cn
#my site is https://www.cnblogs.com/pyyu
My qq num is 877348180.
my phone num is 15210888008.
1){}匹配手机号
往复杂了思考
中国电信号段133、153、173、177、180、181、189、191、193、199
中国联通号段130、131、132、155、156、166、175、176、185、186、166
中国移动号段134(0-8)、135、136、137、138、139、147、150、151、152、157、158、159、172、178、182、183、184、187、188、198
手机号码的规则如下:
第一位: 1
第二位: 3~9
第三到第十一位只要是数字就行
[242-yuchao-class01 root ~]#grep -E '1[3-9][0-9]{9}' t2.log -o
15210888008
grep 参数
-E 扩展正则
-o 只显示结果
-w 匹配单词(单词表示出现了分割符如,hello,i am super mam.)
grep -Enow '[0-9]{11}' test.txt

匹配QQ号
grep -Enow '[0-9]{9}' test.txt

2)查找出所有单词中出现字母连续的行,比如: www,http重复,可以采用分组,向后引用的特性匹配
找出至少有2个连续的相同字母,且只能找出至少2次连续的字母
向后引用,提取
这个写法是,括号内的数据,必然要再出现一次
这个写法是,只找出2个字母
grep -E '([a-zA-Z])\1' t2.log
ww
wwwwww
分组、向后引用、+号 组合用法
grep -E '([a-zA-Z])\1+' t2.log
只想提取三个连续一样的字母
两种写法
grep -E '([a-zA-Z])\1{2}' t2.log
grep -E '([a-zA-Z])\1\1' t2.log
括号分组,向后引用,语法还未理解

3)只查找出同一个字母连续3次的行,比如www
grep -En '([a-z])\1{2}' test.txt

4)提取网址www.xxx.com ,提取网站的主机名,域名
grep -Eno '([a-z])\1{2,}\.[a-z0-9]{1,}\..*' test.txt
grep -Eno '([a-z])\1{2,}\.[a-z0-9]{1,}\.[a-z0-9]{1,}' test.txt
# 参考写法
[242-yuchao-class01 root ~]#grep -E 'www\..*\.(cn|com)' -o t2.log
www.yuchaoit.cn
www.cnblogs.com
[242-yuchao-class01 root ~]#grep -E 'www\..*\.c(n|om)' -o t2.log
www.yuchaoit.cn
www.cnblogs.com

5)提取完整的链接地址https://www.xxx.com
grep -E 'http[s]?://([a-zA-Z0-9])\1{2}\.[a-zA-Z0-9]{1,}\.[a-zA-Z0-9]{1,}[/]?[a-zA-Z0-9]{0,}' test.txt
grep -E 'h.*://(.*).(.*).(.*)[/]?.*' test.txt
grep -E 'h.*://.*[/]?.*' test.txt
# 提取https://www.xxx.com/xxxxxxxxxxxxxx
[242-yuchao-class01 root ~]#grep -E 'http[s]?://www\..*\..*' -o t2.log
http://www.yuchaoit.cn
https://www.cnblogs.com/pyyu
[242-yuchao-class01 root ~]#grep -E 'http[s]?://www\..*\.(cn|com).*' -o t2.log
http://www.yuchaoit.cn
https://www.cnblogs.com/pyyu

工作常见需求
1)排除配置文件的注释、空行
grep -Ev '^#|^$' test.txt
grep -v '^#' test.txt | grep '.'
grep -v '^#' chaoge.txt | grep -v '^$'
2)查找某进程是否存在,过滤grep临时进程
ps -ef |grep ssh |grep -v 'grep'

3)查看sda磁盘的使用率
df -h |grep sda |grep -oE '[0-9]+%'

4)查看根分区的磁盘使用率
df -h|grep '/$' |grep -oE '[0-9]+%'

5)取出网卡ip地址
思路:找到命令中的ip相关,过滤出ip,显示指定ip
ifconfig命令
ifconfig ens33 |grep 'netmask' | grep -Eo '[0-9]{1,3}.[0-9]{1,3}.[0-9]{1,3}.[0-9]{1,3}' | head -1
ip addr show命令
ip addr show ens33 | grep 'ens33$' | grep -Eo '[0-9]{1,3}.[0-9]{1,3}.[0-9]{1,3}.[0-9]{1,3}' | head -1

6)统计出系统中,所有禁止登录,的用户,且只显示用户名
思路:过滤出/etc/passwd 中的nologin项 ,使用grep的-o参数只显示过滤出的用户名
grep 'nologin' /etc/passwd |grep -Eo '^[a-z0-9A-Z]+'

7)找出由root创建的用户
root
useradd创建普通用户
uid 从1000开始
思路:root创建的用户从UID从1000开始,过滤出UID超过1000的用户
grep -E '\b[0-9]{4,}\b' /etc/passwd


 浙公网安备 33010602011771号
浙公网安备 33010602011771号