

在centos7上用CDH搭建tensorflowonspark
该博客为了记录一下部署雅虎的tensorflowonspark分布式集群的经验,部署的是yarn模式,官网地址为:https://github.com/yahoo/TensorFlowOnSpark/wiki/GetStarted_YARN
简单介绍一下CDH是什么
CDH(Cloudra's Distribution Apache Of Hadoop)是Apache Hadoop和相关项目的最完整,经过测试和最流行的发行版。CDH提供Hadoop的核心要素–可扩展的存储和分布式计算–以及基于Web的用户界面和重要的企业功能。CDH是Apache许可的开源软件,并且是唯一提供统一批处理,交互式SQL和交互式搜索以及基于角色的访问控制的Hadoop解决方案。 一句话概括CDH就是集成多种技术的一个框架。
CDH提供
- 灵活性-存储任何类型的数据并使用各种不同的计算框架进行处理,包括批处理,交互式SQL,自由文本搜索,机器学习和统计计算。
- 集成-在可与广泛的硬件和软件解决方案一起使用的完整Hadoop平台上快速启动并运行。
- 安全性-处理和控制敏感数据。
- 可扩展性-启用广泛的应用程序并进行扩展,并扩展它们以满足您的要求。
- 高可用性-自信地执行关键任务业务任务。
- 兼容性-利用您现有的IT基础架构和投资。
大概的安装过程为,先做一些前期的准备比如配置ssh免密登陆,安装jdk等。然后安装CDH,用CDH部署spark集群,最后安装python,tensorflow和tensorlfowonspark。
一、前期准备
1.1配置静态的ip地址
vim /etc/sysconfig/network-scripts/ifcfg-enp4s0
TYPE="Ethernet" PROXY_METHOD="none" BROWSER_ONLY="no" BOOTPROTO="static" DEFROUTE="yes" IPV4_FAILURE_FATAL="no" IPV6INIT="yes" IPV6_AUTOCONF="yes" IPV6_DEFROUTE="yes" IPV6_FAILURE_FATAL="no" IPV6_ADDR_GEN_MODE="stable-privacy" NAME="enp4s0" UUID="751f3302-7973-4c71-b992-253a15ac4809" DEVICE="enp4s0" ONBOOT="yes" IPADDR=192.168.0.101 NETMASK=255.255.255.0 DNS1=192.168.0.1 GATEWAY=192.168.0.1
1.2 修改主机名
vim /etc/hostname
master
让主机名生效
systemctl restart systemd-hostnamed.service
1.3 配置hosts
vim /etc/hosts
192.168.0.101 master 192.168.0.102 slave1 192.168.0.103 slave2
1.4 编写分发脚本
在/home/jianyuan/bin目录下建一个xsync文件,编写入以下代码:
#!/bin/bash
#1
pcount=$#
if((pcount==0));then
echo no args;
exit;
fi
#2
p1=$1
fname=`basename $p1`
echo fname=$fname
#3
pdir=`cd -P $(dirname $p1);pwd`
echo pdir=$pdir
#4
user=`whoami`
#5
for((host=1;host<3;host++));do
echo -----------------slave$host-------------------------
rsync -rvl $pdir/$fname $user@slave$host:$pdir
done
1.5 安装jdk
1.安装jdk:
在oracle官网上下载jdk(最后市1.8以上),然后安装jdk(在linux上安装就是解压缩,一般在官网上下载的都是.tar后缀的文件),最后配置/etc/profile
下载jdk链接https://www.oracle.com/cn/java/technologies/javase/javase-jdk8-downloads.html
安装jdk:tar -zxvf jdk-8u281-linux-x64.tar.gz -C /opt/module
配置/etc/profile
添加jdk的安装路径到profile文件最后,如下:
#JAVA_HOME export JAVA_HOME=/opt/module/jkd1.8.0_281 export PATH=$PATH:$JAVA_HOME/bin
最后source /etc/profile
1.6 配置ssh免密登陆(每台都要配)
在当前用户的家目录下生成密钥对
ssh-keygen -t rsa(再按三次回车)
拷贝公钥到其他主机
ssh-copy-id slave1
ssh-copy-id slave2
ssh-copy-id master
1.7 配置集群时间同步
(1)时间服务器的配置(master)
安装ntp
yum install ntp
a.检查ntp是否安装
rpm -qa | grep ntp
(结果)
ntp-4.2.6p5-10.e16.centos.x86_64
fontpackages-filesystem-1.41-1.1.e16.noarch
ntpdate-4.2.6p5-10.e16.centos.x86_64
b.修改ntp配置文件
vim /etc/ntp.conf
修改一(授权192.168.100.0-192.168.100.255网段上的所有机器可以从这台机器上查询和同步时间)
#restrict 192.168.1.0 mask 255.255.255.0 nomodify notrap 为
restrict 192.168.100.0 mask 255.255.255.0 nomodify notrap

修改二(集群在局域网中,不使用其他互联网上的时间)
server0.centospool.ntp.org iburst
server1.centospool.ntp.org iburst
server2.centospool.ntp.org iburst
server3.centospool.ntp.org iburst为
#server0.centospool.ntp.org iburst
#server1.centospool.ntp.org iburst
#server2.centospool.ntp.org iburst
#server3.centospool.ntp.org iburst

添加三(当该节点丢失网络连接,依然可以采用本地时间作为时间服务器为机器的其他节点提供时间同步)
server 127.127.1.0
fudge 127.127.1.0 stratum 10
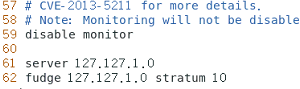
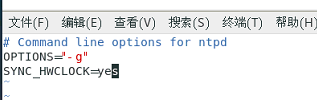
c.修改/etc/sysconfig/ntpd文件
让硬件时间与系统时间一起同步
SYNC_HWCLOCK=yes
效果如图:
d.重启ntpd服务
systemctl restart ntpd
f.设置ntpd服务开机启动
systemctl enable ntpd

(2)其他机器的配置
在其他机器配置10分钟与时间服务器同步一次
crontab -e
编写定时任务如下:
*/10 * * * * /usr/sbin/ntpdate master

1.8 关闭SELINUX(所有节点)
vim /etc/selinux/config

1.9 优化虚拟内存(所有节点)
[root@master opt]# echo 'vm.swappiness = 0' > /etc/sysctl.d/swappiness.conf [root@master opt]# sysctl -p [root@master opt]#
1.10 禁用大叶内存(所有节点)
[root@master opt]# echo never > /sys/kernel/mm/transparent_hugepage/defrag [root@master opt]# echo never > /sys/kernel/mm/transparent_hugepage/enabled [root@master opt]# echo "echo never > /sys/kernel/mm/transparent_hugepage/enabled" >> /etc/rc.local [root@master opt]# echo "echo never > /sys/kernel/mm/transparent_hugepage/defrag" >> /etc/rc.local [root@master opt]# chmod u+x /etc/rc.local
1.11 关闭防火墙(所有节点)
[root@master opt]# systemctl stop firewalld [root@master opt]# systemctl disable firewalld Removed symlink /etc/systemd/system/multi-user.target.wants/firewalld.service. Removed symlink /etc/systemd/system/dbus-org.fedoraproject.FirewallD1.service.
1.12 mysql部署(在master部署)
a、安装mysql
wget -i -c http://dev.mysql.com/get/mysql57-community-release-el7-10.noarch.rpm yum -y install mysql57-community-release-el7-10.noarch.rpm
yum -y install mysql-community-server
b、启动mysql
[root@master FUZHI]# systemctl start mysqld.service [root@master FUZHI]# systemctl status mysqld.service
c、修改密码
grep "password" /var/log/mysqld.log

mysql -uroot -p 然后输入我们之前获取到的密码&1sJr8otpe1O ALTER USER 'root'@'localhost' IDENTIFIED BY 'Admin@123';
flush privileges;
d、修改mysql的默认编码
vi /etc/my.cnf character_set_server=utf8 init_connect='SET NAMES utf8'
e、配置root用户的远程访问
[root@master FUZHI]# mysql -uroot -pXinxi@123 mysql: [Warning] Using a password on the command line interface can be insecure. Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 3 Server version: 5.7.36 MySQL Community Server (GPL) Copyright (c) 2000, 2021, Oracle and/or its affiliates. Oracle is a registered trademark of Oracle Corporation and/or its affiliates. Other names may be trademarks of their respective owners. Type 'help;' or '\h' for help. Type '\c' to clear the current input statement. mysql> grant all privileges on *.* to 'root' @'%' identified by 'Xinxi@123'; Query OK, 0 rows affected, 1 warning (0.00 sec) mysql> flush privileges; Query OK, 0 rows affected (0.00 sec)
f、创建CDH所需要的库
mysql> CREATE DATABASE scm DEFAULT CHARACTER SET utf8 DEFAULT COLLATE utf8_general_ci; Query OK, 1 row affected (0.00 sec) mysql> CREATE DATABASE amon DEFAULT CHARACTER SET utf8 DEFAULT COLLATE utf8_general_ci; Query OK, 1 row affected (0.00 sec) mysql> CREATE DATABASE hue DEFAULT CHARACTER SET utf8 DEFAULT COLLATE utf8_general_ci; Query OK, 1 row affected (0.00 sec) mysql> CREATE DATABASE hive DEFAULT CHARACTER SET utf8 DEFAULT COLLATE utf8_general_ci; Query OK, 1 row affected (0.00 sec) mysql> CREATE DATABASE sentry DEFAULT CHARACTER SET utf8 DEFAULT COLLATE utf8_general_ci; Query OK, 1 row affected (0.00 sec) mysql> CREATE DATABASE oozie DEFAULT CHARACTER SET utf8 DEFAULT COLLATE utf8_general_ci; Query OK, 1 row affected (0.00 sec)
g、放置mysql驱动
mv mysql-connector-java-5.1.27-bin.jar /usr/share/java/mysql-connector-java.jar
xsync /usr/share/java
二、安装CDH
a、unzip 安装
yum install unzip -y
b、cm准备
[root@master FUZHI]# unzip cm6.2.1.zip [root@master FUZHI]# xsync cm6.2.1
c、parcels准备
[root@master FUZHI]# unzip parcels.zip [root@master FUZHI]# cd parcels [root@master FUZHI]# mkdir -p /opt/cloudera/parcel-repo/ [root@master FUZHI]# cp ./* /opt/cloudera/parcel-repo/ [root@master FUZHI]# cd /opt/cloudera/parcel-repo/ [root@master FUZHI]# mv CDH-6.2.1-1.cdh6.2.1.p0.1580995-el7.parcel.sha1 CDH-6.2.1-1.cdh6.2.1.p0.1580995-el7.parcel.sha
d、CDH安装
1)主节点
cd /opt/software/cm6.2.1/RPMS/x86_64 yum install cloudera-manager-daemons-6.2.1-1426065.el7.x86_64.rpm -y yum install cloudera-manager-agent-6.2.1-1426065.el7.x86_64.rpm -y yum install cloudera-manager-server-6.2.1-1426065.el7.x86_64.rpm -y
2)其他节点
cd /opt/software/cm6.2.1/RPMS/x86_64
yum install cloudera-manager-daemons-6.2.1-1426065.el7.x86_64.rpm -y yum install cloudera-manager-agent-6.2.1-1426065.el7.x86_64.rpm -y
e、配置server节点
[root@master x86_64]# vim /etc/cloudera-scm-agent/config.ini
# Hostname of the CM server.
server_host=master

f、配置数据库
/opt/cloudera/cm/schema/scm_prepare_database.sh mysql scm root Xinxi@123
g、启动CM
[root@master cloudera]# systemctl start cloudera-scm-agent
[root@slave1 ~]# systemctl start cloudera-scm-agent
[root@slave2 ~]# systemctl start cloudera-scm-agent
[root@master cloudera]# systemctl start cloudera-scm-server
此时观察我们的日志tail -f /var/log/cloudera-scm-server/cloudera-scm-server.log,看到Started Jetty server.就好了
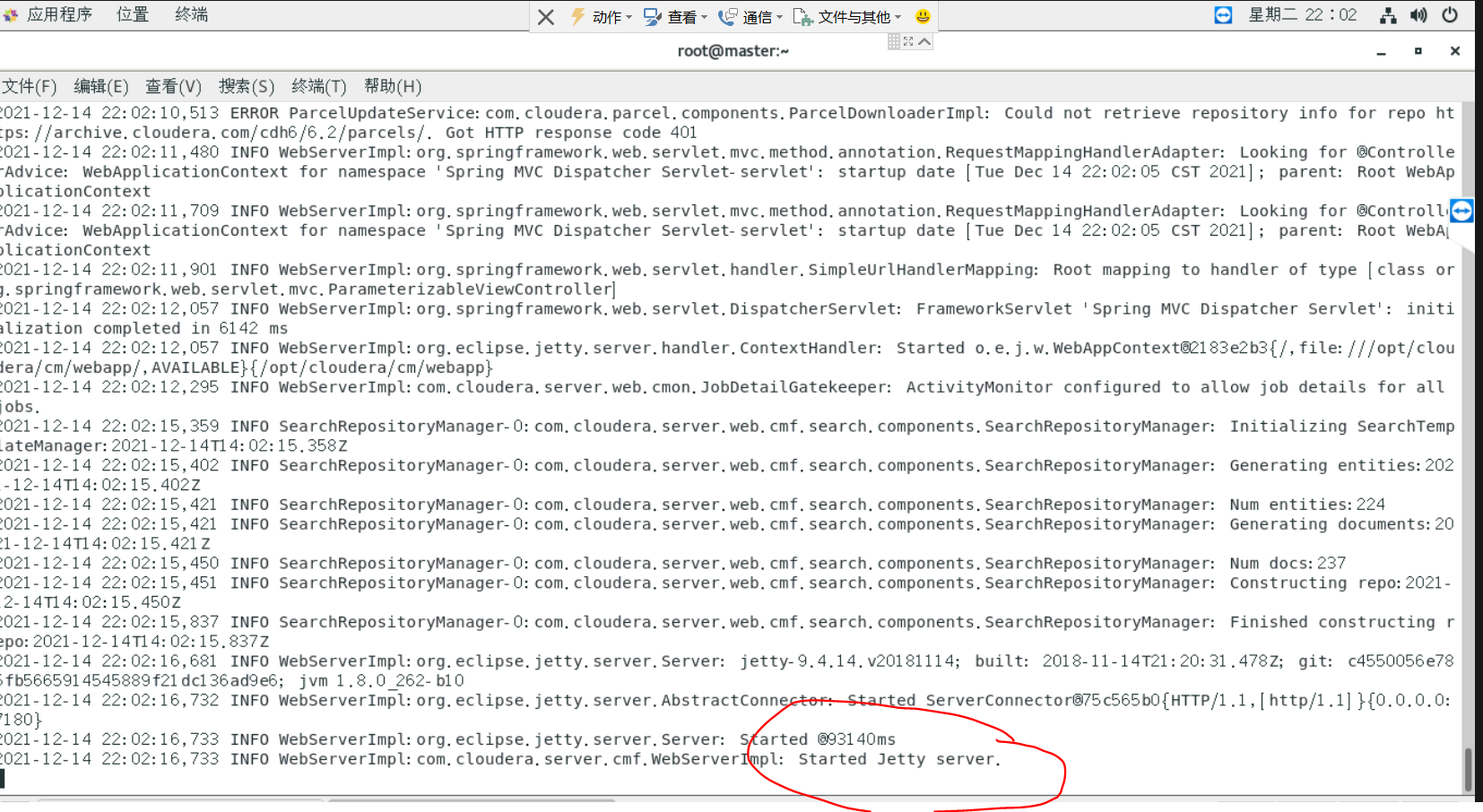
三、安装组件
浏览器输入http://master:7180/cmf/login
账号:admin
密码:admin
a、集群配置
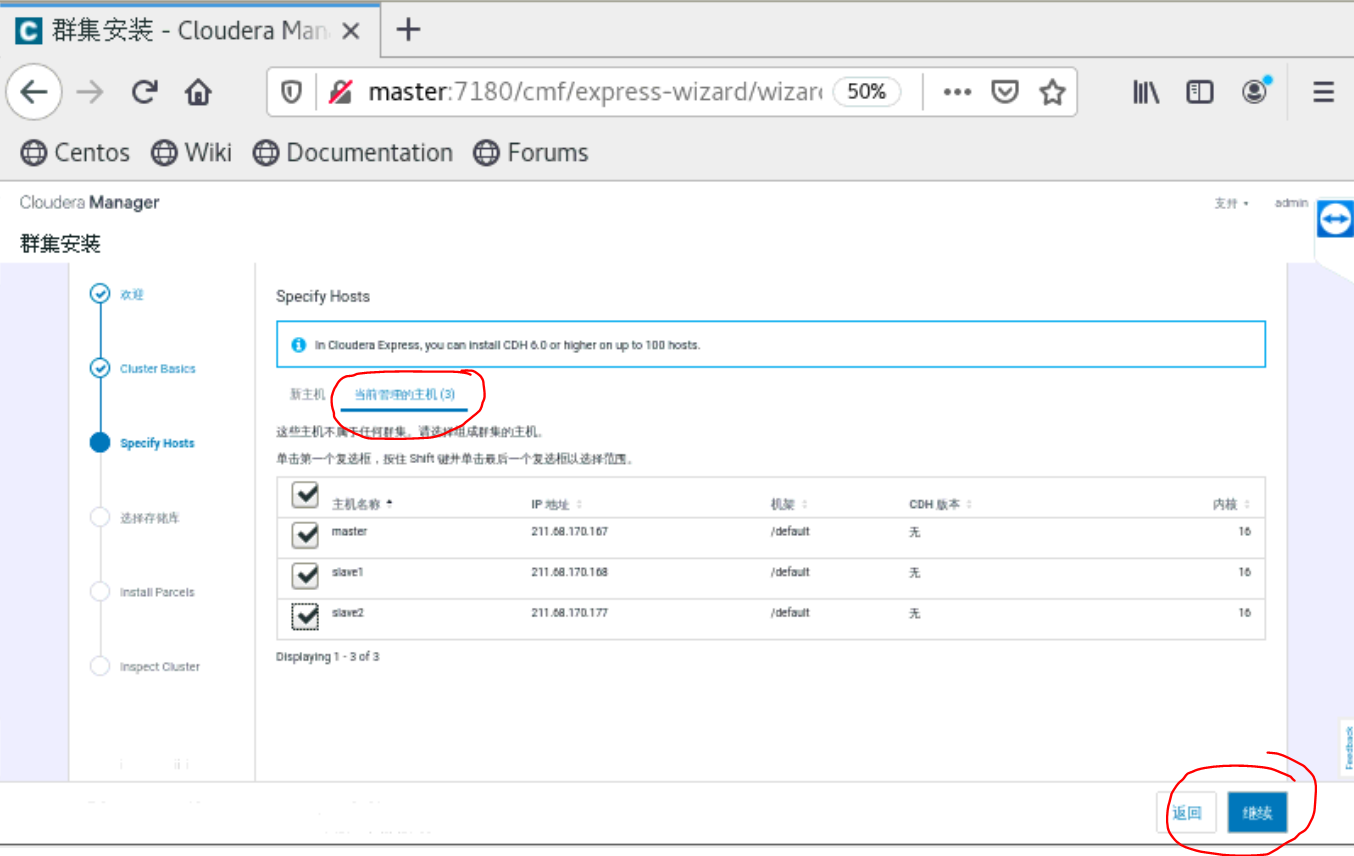
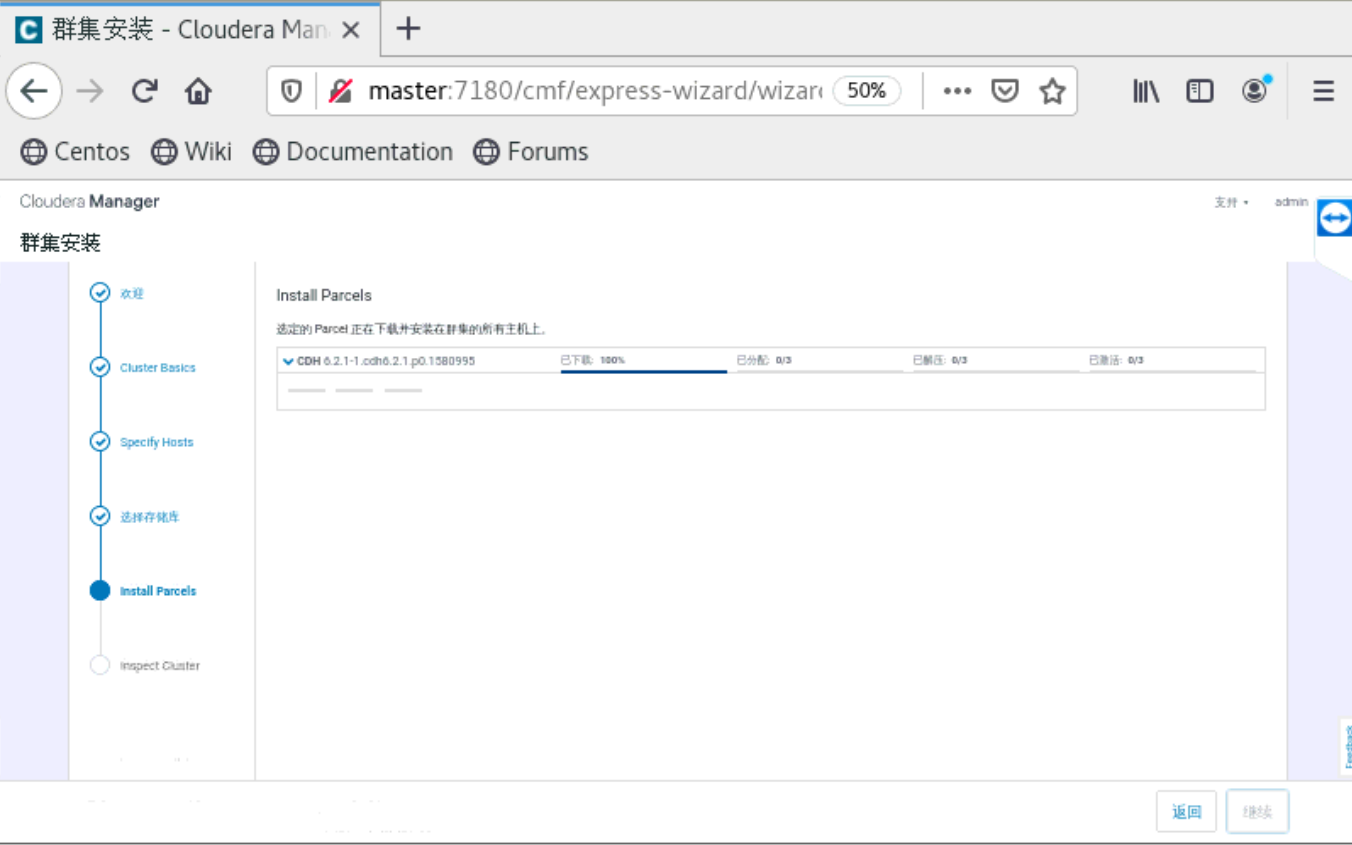
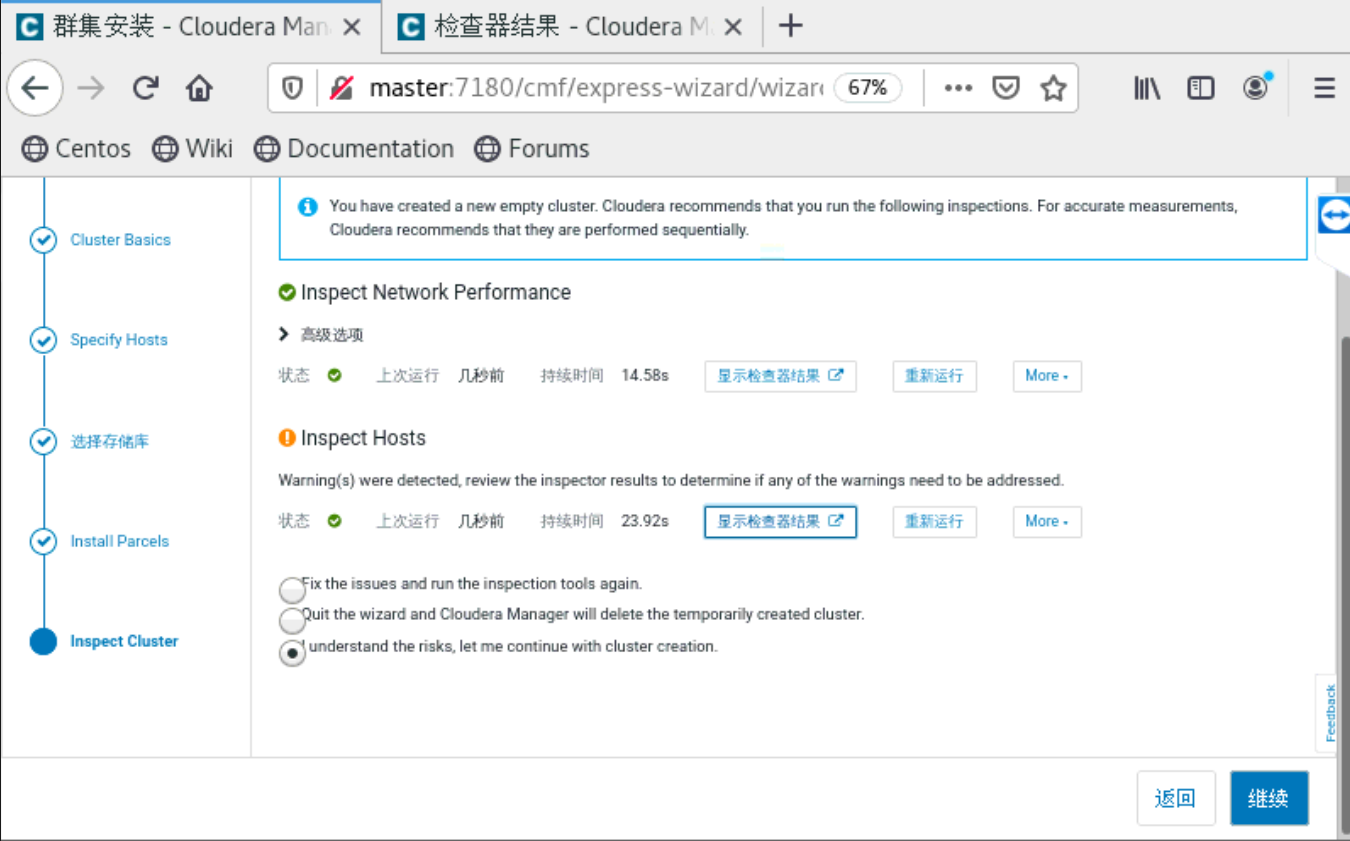
到了这一步的时候,要你所有的主机都是当前管理的主机,如果不是的话,就是你的cloudera-manager-agent没有安装好。就无法安装Parcels。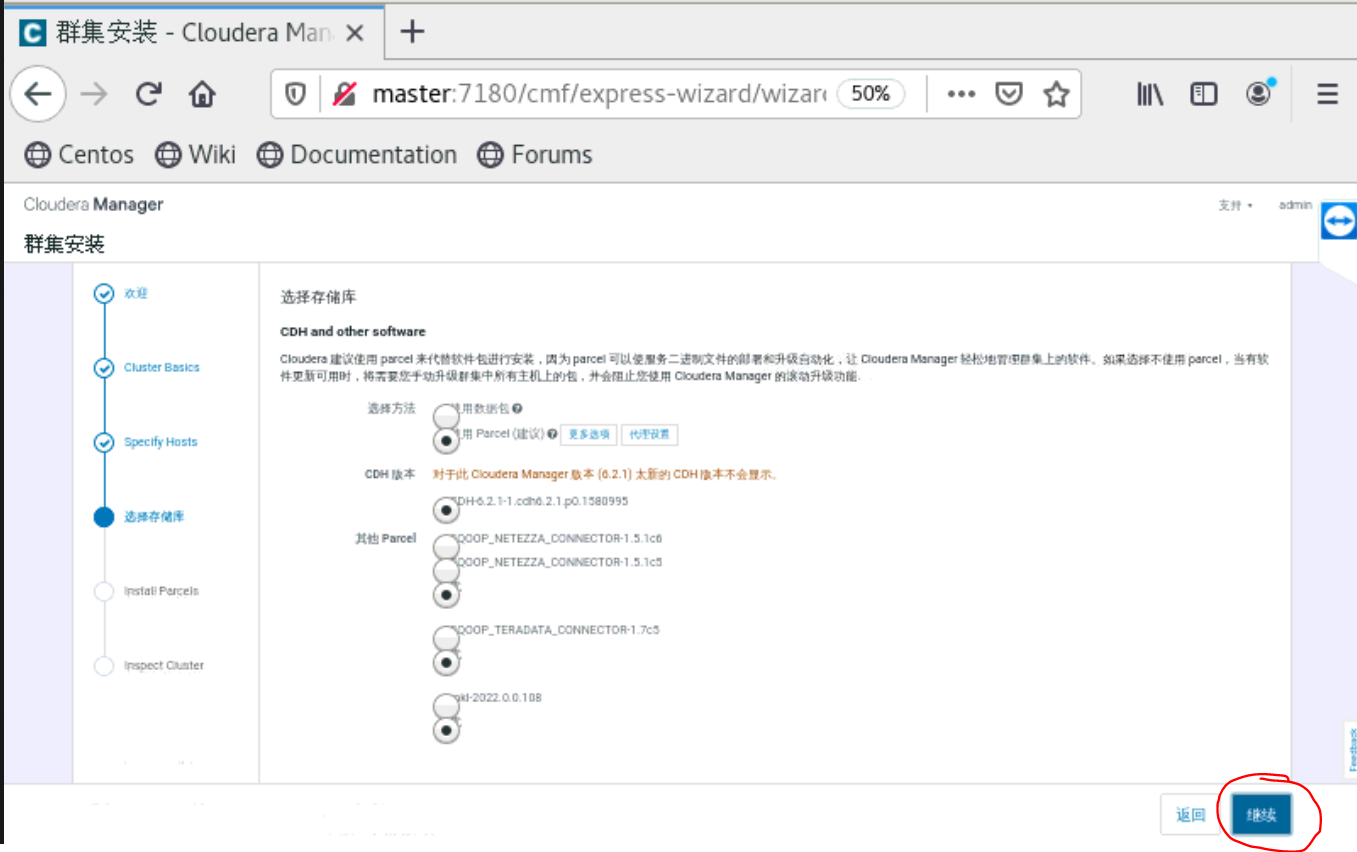
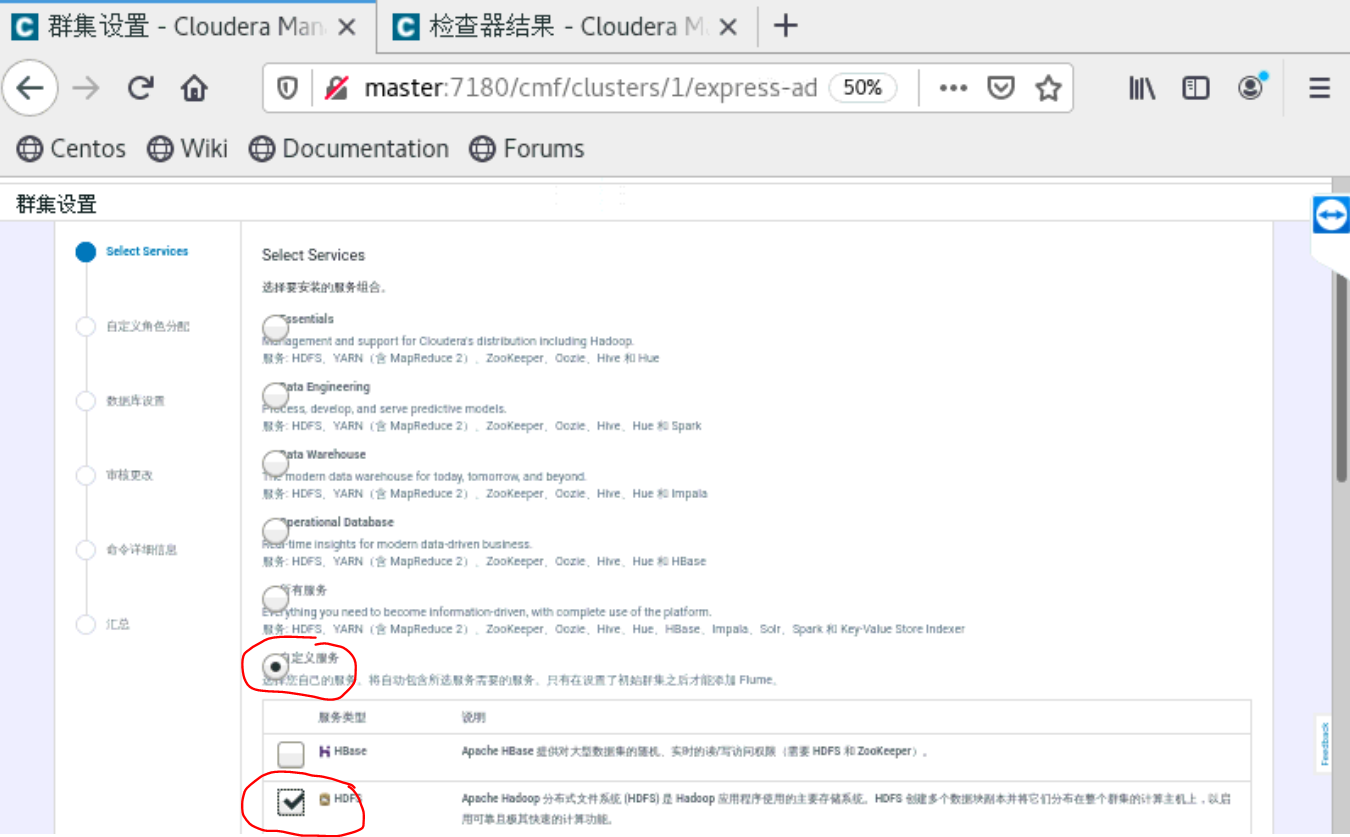
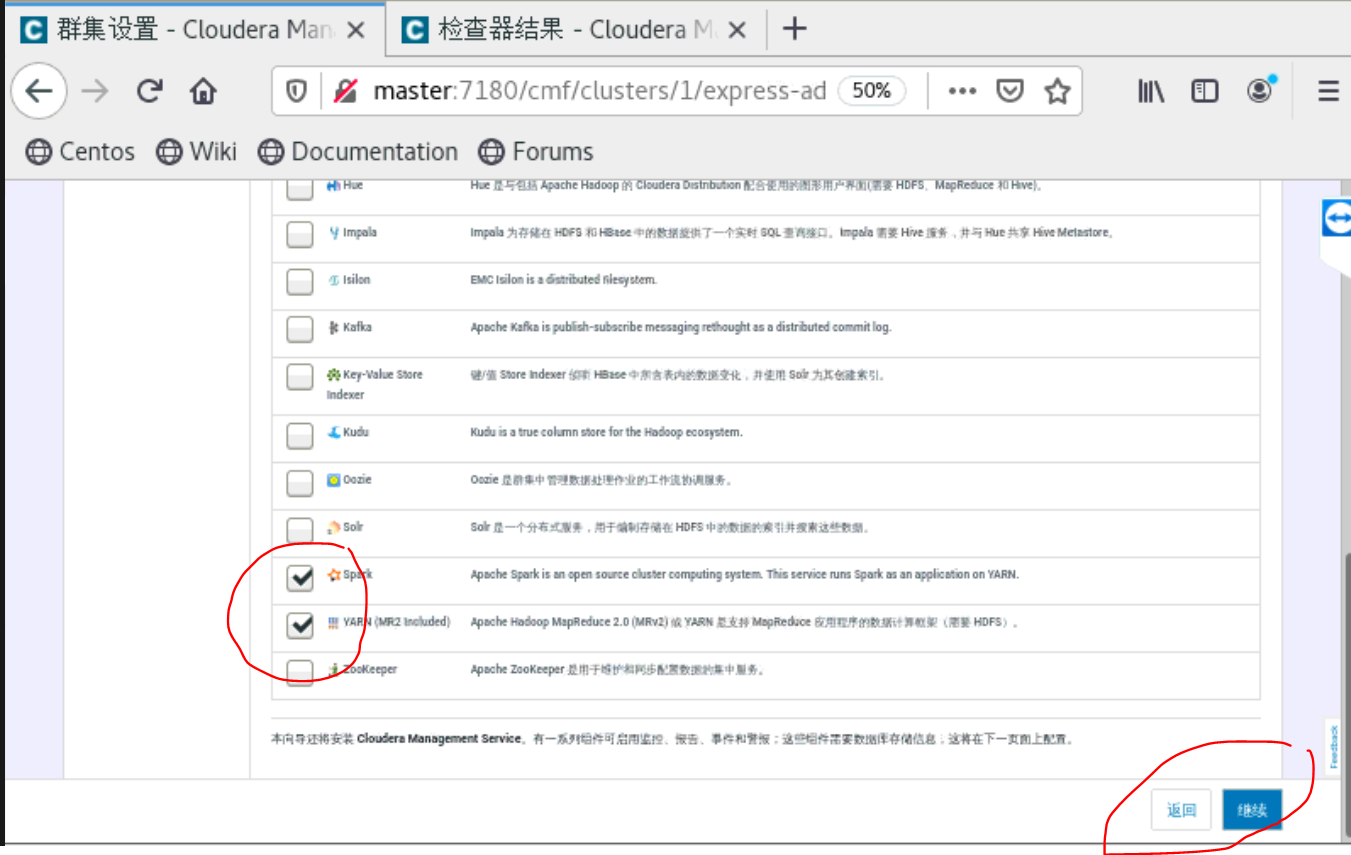
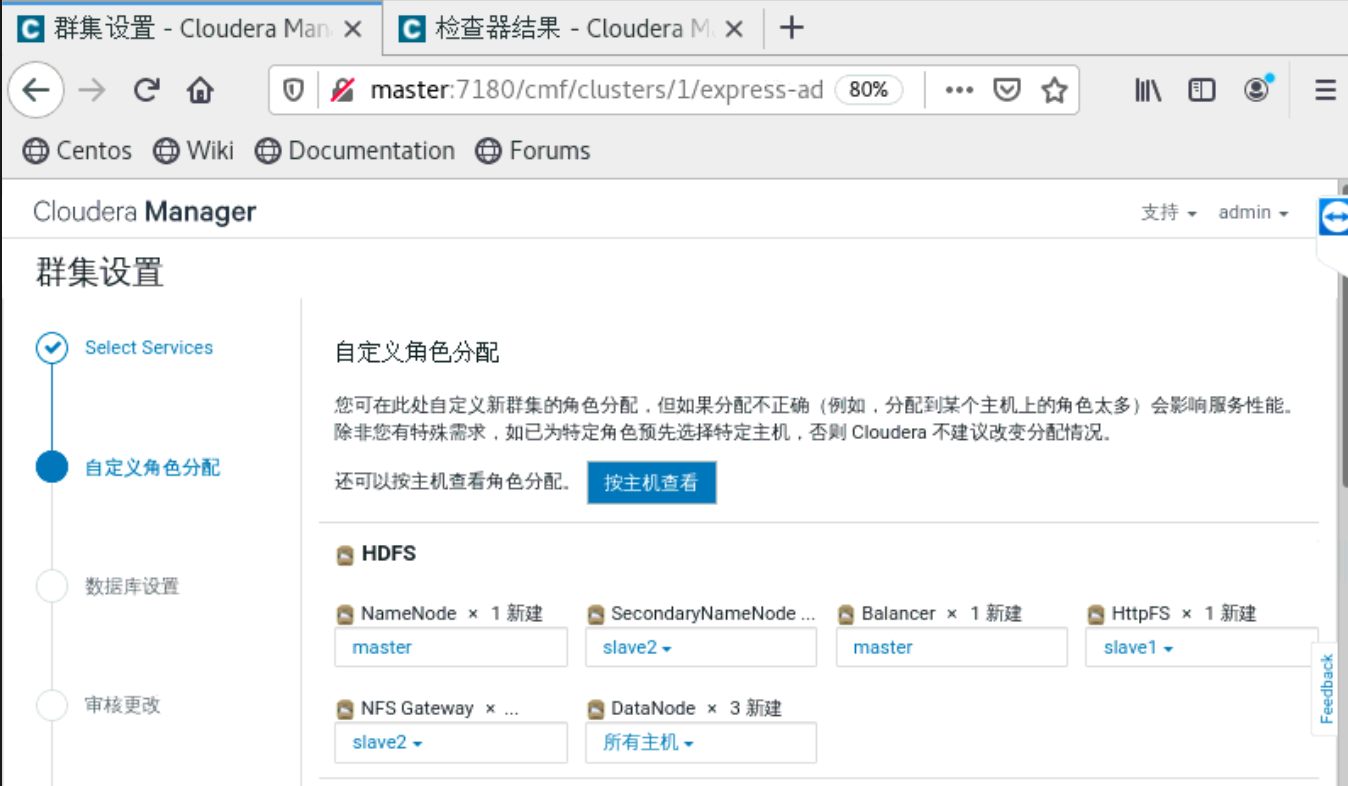
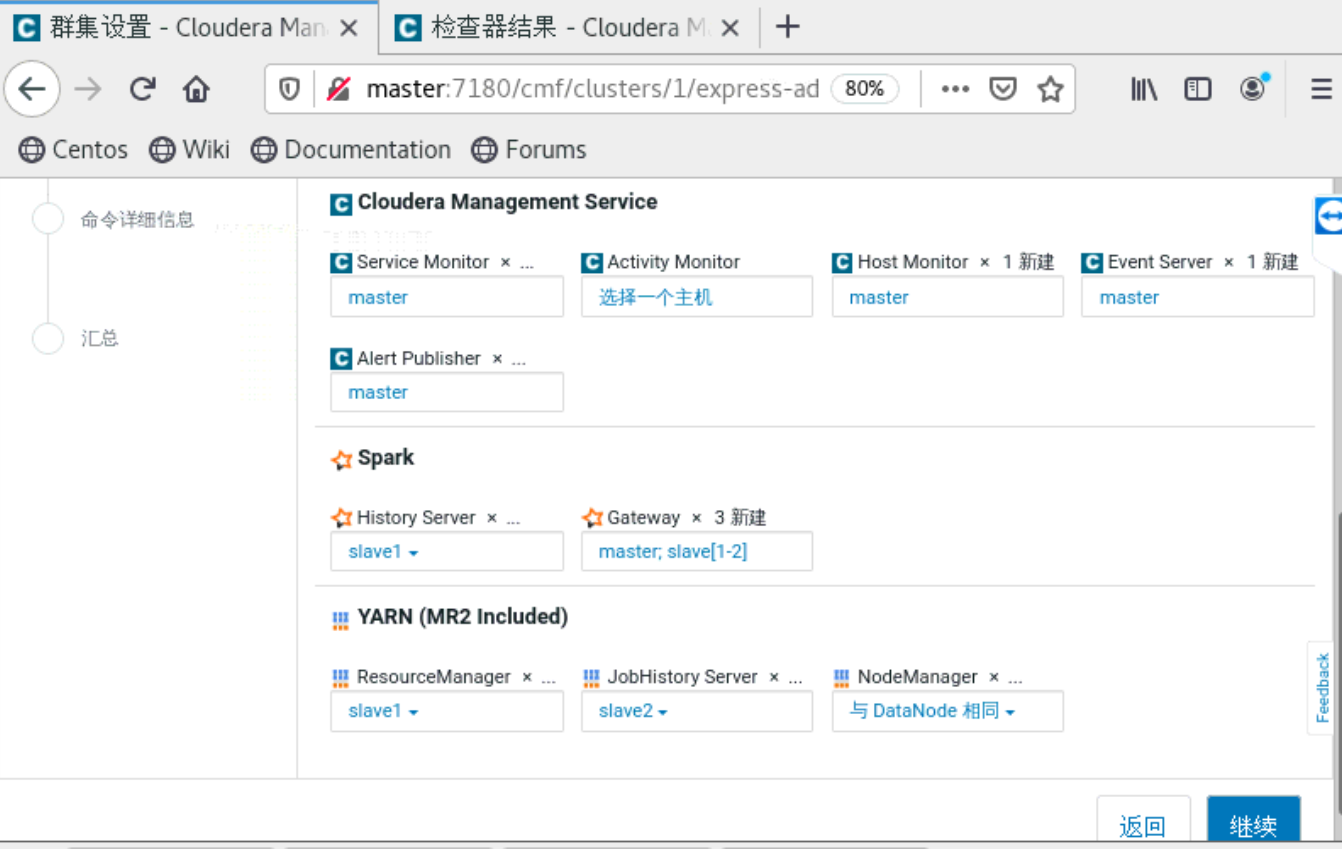
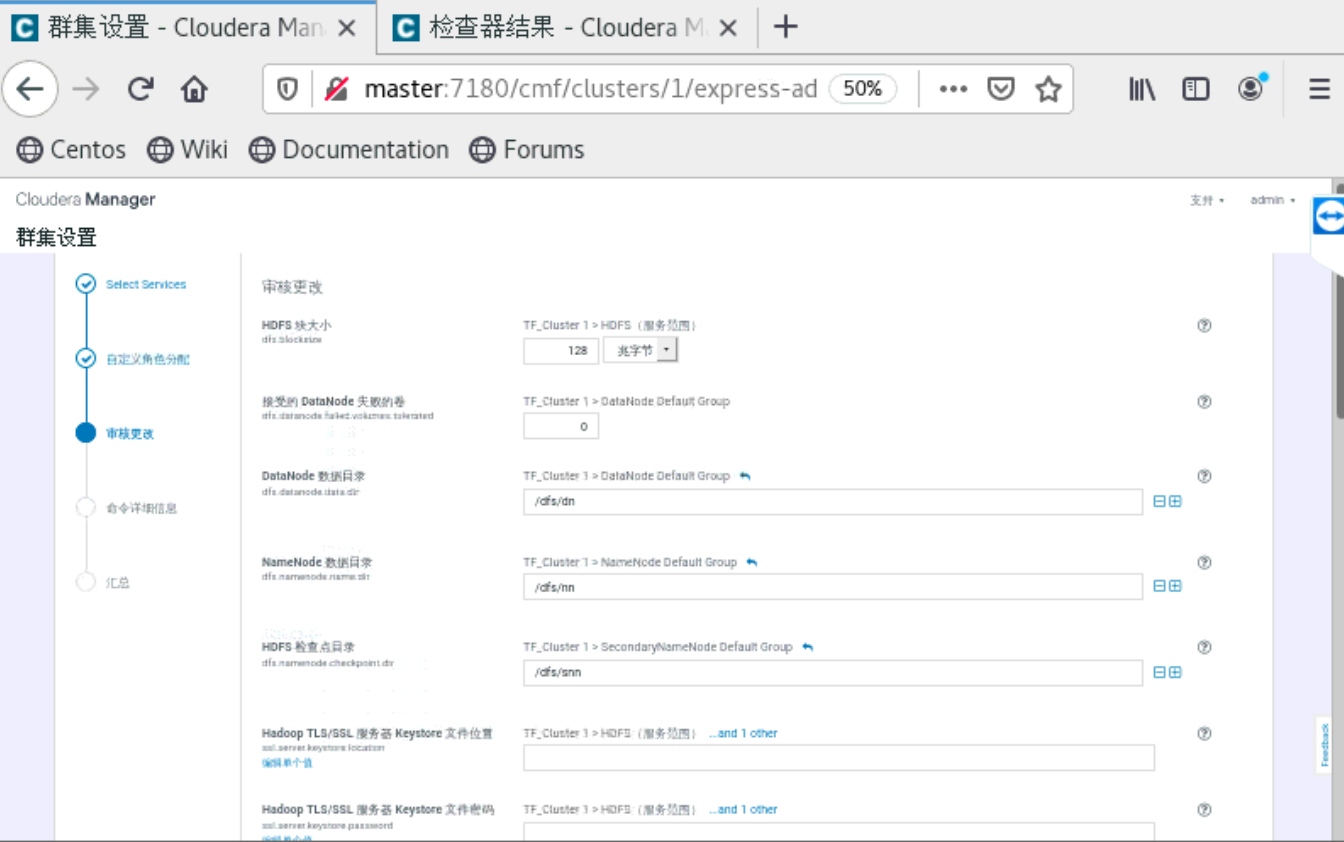
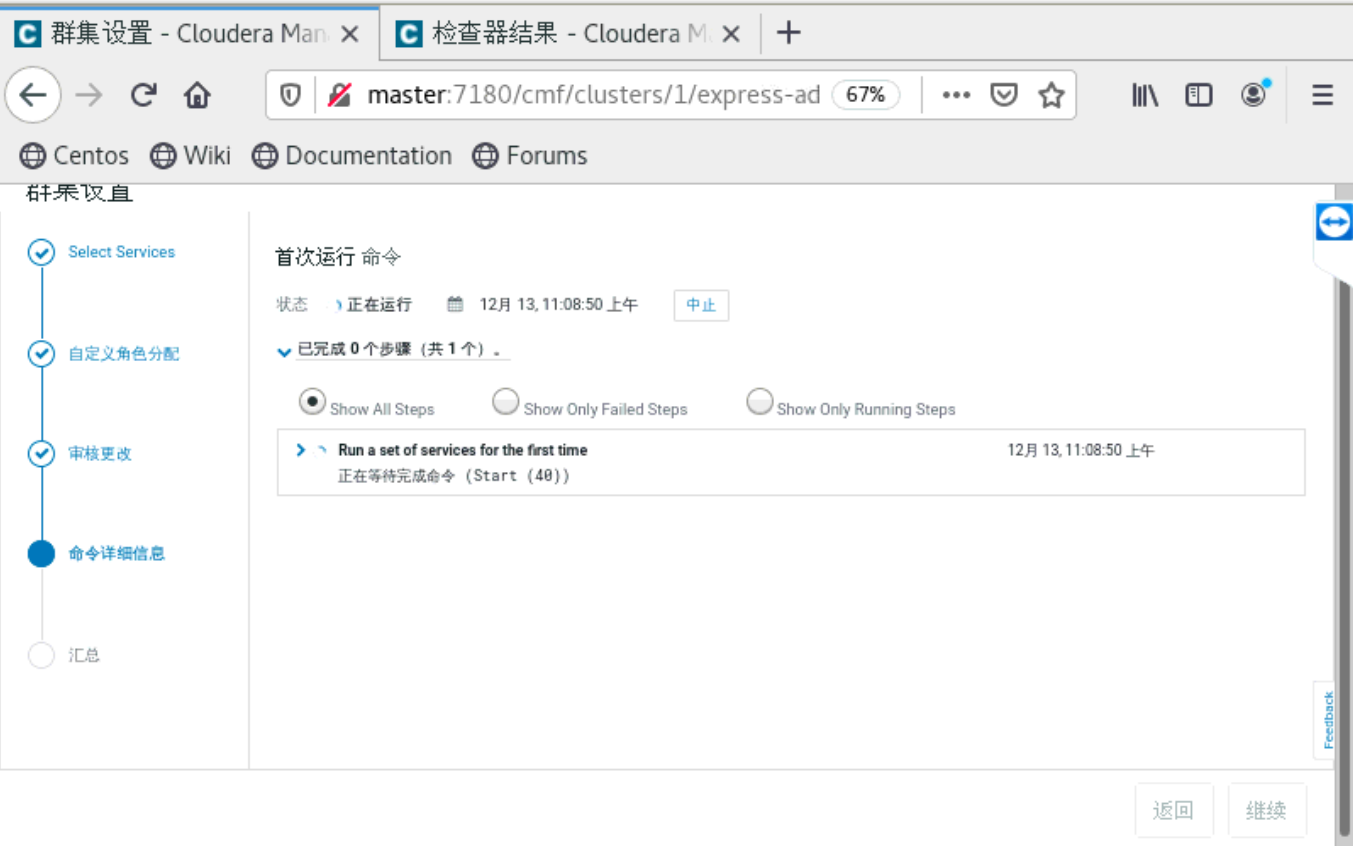
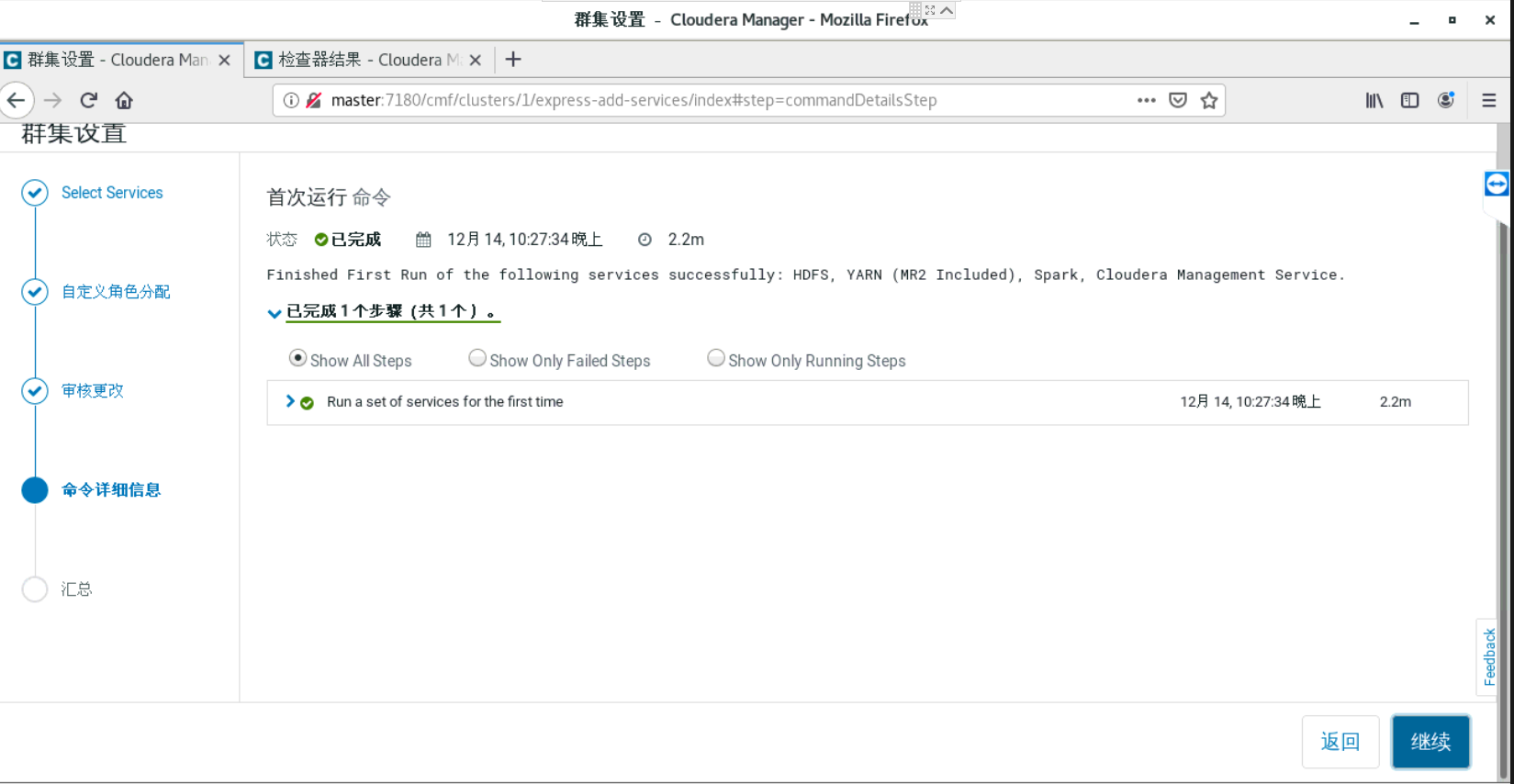
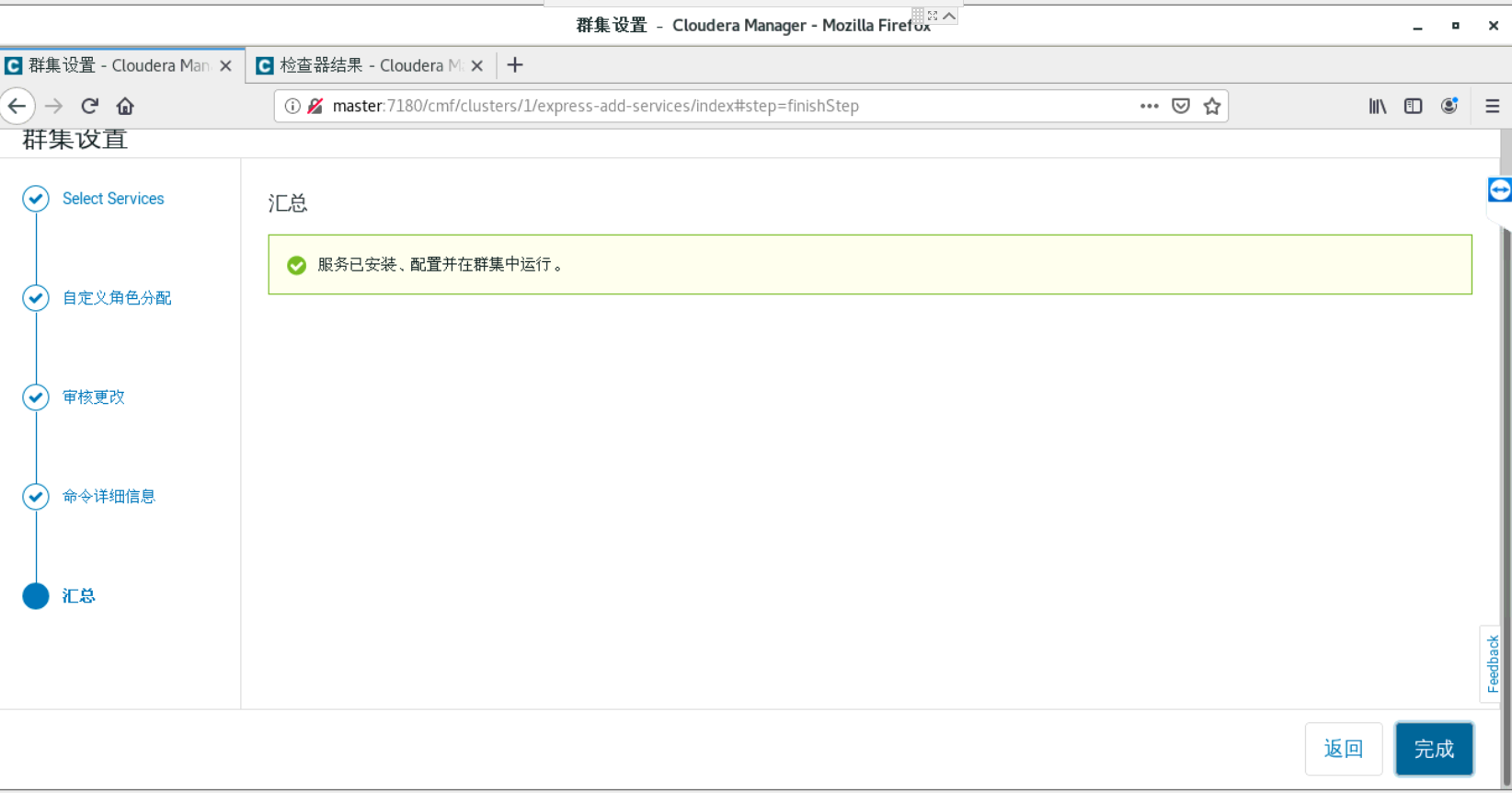
四、安装python,tensorflow和tensorflowonspark等包
在安装这些包之前,为先给出这些的版本号,python版本是3.7.6,tensorflow版本为2.0.0,tensorflowonspark的版本号为2.2.4
Package Version ------------------------ --------- absl-py 1.0.0 astor 0.8.1 astunparse 1.6.3 attrs 21.2.0 cachetools 4.2.4 certifi 2021.10.8 charset-normalizer 2.0.7 dill 0.3.4 future 0.18.2 gast 0.2.2 google-auth 1.35.0 google-auth-oauthlib 0.4.6 google-pasta 0.2.0 googleapis-common-protos 1.53.0 grpcio 1.42.0 h5py 2.10.0 idna 3.3 importlib-metadata 4.8.2 importlib-resources 5.4.0 Keras-Applications 1.0.8 Keras-Preprocessing 1.1.0 Markdown 3.3.6 mrjob 0.7.4 numpy 1.18.5 oauthlib 3.1.1 opt-einsum 3.3.0 packaging 21.3 pip 19.2.3 promise 2.3 protobuf 3.19.1 py4j 0.10.9.2 pyasn1 0.4.8 pyasn1-modules 0.2.8 pydoop 2.0.0 PyHDFS 0.3.1 pyparsing 3.0.6 pyspark 3.2.0 PyYAML 6.0 requests 2.26.0 requests-oauthlib 1.3.0 rsa 4.7.2 scipy 1.4.1 setuptools 41.2.0 simplejson 3.17.6 six 1.16.0 tensorboard 2.0.2 tensorboard-data-server 0.6.1 tensorboard-plugin-wit 1.8.0 tensorflow 2.0.0 tensorflow-datasets 3.0.0 tensorflow-estimator 2.0.1 tensorflow-metadata 1.4.0 tensorflowonspark 2.2.4 termcolor 1.1.0 tqdm 4.62.3 typing-extensions 4.0.0 urllib3 1.26.7 Werkzeug 2.0.2 wheel 0.37.0 wrapt 1.13.3 zipp 3.6.0
需要注意的是,tensorflow-datasets的版本不能太高,太高的话需要tensorflow的版本大于2.1.0,而我安装tensorflow2.1.0以上的版本会报
pkg_resources.DistributionNotFound: The 'tensorflow' distribution was not found and is required by the application(不知道为什么),我现在安装的版本就不会有这个问题,所以我把tensorflow-datasets的版本改为3.0.0
安装python3.7.6
mkdir -r /opt/module/python3 cd /opt/software/Python-3.7.6 yum install openssl-devel zlib-devel gcc gcc-c++ boost-devel python-devel libffi-devel bzip2-devel bzip2 ncurses openssl
yum install openssl-static xz lzma xz-devel sqlite sqlite-devel gdbm gdbm-devel tk tk-devel ./configure CPPFLAGS='-I/opt/zlib/include' LDFLAGS='-L/opt/zlib/lib' --prefix=/opt/module/python3 make make install
ln -s /opt/module/python3/bin/python3 /usr/bin/python3
ln -s /opt/module/python3/bin/pip3 /usr/bin/pip3
#####打包python
#进入python的安装目录,执行以下命令
zip -r Python.zip *
## copy this Python distribution into HDFS
#官网的命令:hadoop fs -put ${PYTHON_ROOT}/Python.zip,实际的命令为:
hadoop fs -put /opt/module/python3/Python.zip /user/root
####打包tensorflowonspark成tfspark.zip
#进入从github上下载下来的TensorFlowOnSpark
cd /opt/software/TensorFlowOnSpark zip -r tfspark.zip tensorflowonspark
为 TFRecords 安装和编译 Hadoop InputFormat/OutputFormat
1) 下载ecosystem
$ git clone https://github.com/tensorflow/ecosystem.git
2) 下载protoc 3.1.0
注意,一定是3..,之前用的2.5.0,发现在编译生成时会出现版本错误。
protoc3.1.0下载地址
此处protobuffer安装注意下载release版本,不然在make时会出现花式错误。
$ tar -zxf ~/Downloads/protobuf-cpp-3.1.0.tar.gz -C ~/workspace/ #将protoc3.1.0解压至workspace中
$ cd protobuf-3.1.0 #进入protobuf目录下准备进行编译
$ ./configure #默认路径是/usr/local/lib
$ make
此处虚拟机中安装报错关键词virtual memory exhausted cannot allocate memory,解决方案:free -m查看内存使用情况,确实占用过多的情况下,可尝试重启解决,我的是这样解决的。若解决不了需自行增加虚拟机内存。
$ make check
$ sudo make install
make install之后总觉得哪里不对劲,之后protoc -version
发现如下错误protoc: error while loading shared libraries: libprotoc.so.11: cannot open shared object file: No such file or directory
这是因为protobuf的默认路径是/usr/local/lib,而/usr/local/lib不在ubuntu体系默认的LD_LIBRARY_PATH 里,所以就找不到该lib。在环境变量中修改即可。
$ sudo vim ~/.bashrc
增加如下内容:
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/lib
$ source ~/.bashrc
3) 下载maven
Apache Maven,这是一个软件(特别是Java软件)项目管理及自动构建工具,由Apache软件基金会所提供。
a、确保已经安装好jdkb、到maven官网下载apache-maven-3.3.9-bin.tar.gzc、解压缩到~/workspace中
$ tar -zxf ~/Downloads/apache-maven-3.3.9-bin.tar.gz -C ~/workspace
d、修改环境变量$ sudo vim ~/.bashrc
在末尾添加
export M2_HOME=/[maven安装目录]/apache-maven-3.3.9
export PATH=$M2_HOME/bin:$PATH
$ source ~/.bashrc #使环境变量生效
e、检测是否安装成功
$ mvn -v
出现如下结果则表示成功:
Apache Maven 3.3.9 (bb52d8502b132ec0a5a3f4c09453c07478323dc5; 2015-11-11T00:41:47+08:00)Maven home: /home/ubuntu/workspace/mavenJava version: 1.7.0_79, vendor: Oracle CorporationJava home: /home/ubuntu/workspace/jdk1.7.0_79/jreDefault locale: en_US, platform encoding: UTF-8OS name: "linux", version: "4.2.0-42-generic", arch: "amd64", family: "unix"
4) 生成tensorflow-hadoop-1.0-SNAPSHOT.jar
一定要注意你的路径,官网给出如下protoc --proto_path=$TF_SRC_ROOT --java_out=src/main/java/ $TF_SRC_ROOT/tensorflow/core/example/{example,feature}.proto
--proto_path是你下载的tensorflow的路径,--java_out是ecosystem下的/hadoop/src/main/java。以下是我的路径。
a.$ protoc --proto_path=/home/ubuntu/workspace/spark/python/tensorflow --java_out=/home/ubuntu/workspace/spark/python/ecosystem/hadoop/src/main/java/ /home/ubuntu/workspace/spark/python/tensorflow/tensorflow/core/example/{example,feature}.proto
b.编译
请cd 到你的[ecosystem路径]/hadoop下执行
$ mvn clean package
这样就生成了 tensorflow-hadoop-1.0-SNAPSHOT.jar,位于[ecosystem路径]/hadoop/target下。
5) 将 tensorflow-hadoop-1.0-SNAPSHOT.jar放到集群上
hadoop fs -put [ecpsystem路径]/hadoop/target/tensorflow-hadoop-1.0-SNAPSHOT.jar
安装protobuf
mkdir /opt/module/protobuf #创建安装目录 cd /opt/software/protobuf-3.18.0 #进入解压的文件夹 ./configure --prefix=/opt/module/protobuf make make install ####### add protobuf lib path ######## #(动态库搜索路径) 程序加载运行期间查找动态链接库时指定除了系统默认路径之外的其他路径 export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/opt/module/protobuf/lib/ #(静态库搜索路径) 程序编译期间查找动态链接库时指定查找共享库的路径 export LIBRARY_PATH=$LIBRARY_PATH:/opt/module/protobuf/lib/ #执行程序搜索路径 export PATH=$PATH:/opt/module/protobuf/bin/ #c程序头文件搜索路径 export C_INCLUDE_PATH=$C_INCLUDE_PATH:/opt/module/protobuf/include/ #c++程序头文件搜索路径 export CPLUS_INCLUDE_PATH=$CPLUS_INCLUDE_PATH:/opt/module/protobuf/include/ #pkg-config 路径 export PKG_CONFIG_PATH=/opt/module/protobuf/lib/pkgconfig/ ################################### protoc --version #测试安装是否成功
安装tensorflow和tensorflowonspark相关的包
pip3 install --index-url https://pypi.douban.com/simple tensorflow==2.0.0 tensorflow_datasets==3.0.0 pip3 install --index-url https://pypi.douban.com/simple tensorflowonspark==2.2.4 pip3 install --index-url https://pypi.douban.com/simple pydoop pyspark PyHDFS py4j==0.10.9.2 mrjob h5py
测试是否安装好:
python3 import tensorflow as tf from tensorflowonspark import TFCluster
如果没有错误信息应该就就是安装好了
参考资料:
https://blog.csdn.net/weixin_43704599/article/details/106364916
https://www.cnblogs.com/yangyuxia/p/14663505.html
https://www.cnblogs.com/shun7man/p/12326282.html
https://github.com/yahoo/TensorFlowOnSpark/wiki/GetStarted_YARN
https://www.jianshu.com/p/98da344dbf22

 浙公网安备 33010602011771号
浙公网安备 33010602011771号