service与kube-proxy
在Kubernetes集群中,每个Node运行一个kube-proxy进程,负责监视对Service对象、Endpoints对象的添加和移除。
启动时通过--proxy-mode参数指定代理模式:
-
userspace代理模式
对每个Service,它会在本地Node上打开一个随机的代理端口。
它会配置iptables规则,捕获到达该Service的ClusterIP:Port的请求,并重定向到该代理端口。任何连接到该代理端口的请求,都会被代理到某个backend Pods上
默认通过round-robin(轮询调度)算法来选择backend Pod,也会基于基于SessionAffinity。
-
iptables代理模式
对每个Service,它会配置iptables规则,从而捕获到达该Service的ClusterIP:Port的请求,并重定向到某个backend Pods上。 对每个Endpoints对象,它也会配置iptables规则,选择一个backend组合。
流量实际由linux netfilter处理,无需在用户空间和内核空间之间切换,减少了系统开销。
默认随机选择backend。如果所选的第一个Pod没有响应,与userspace模式不同,kube-proxy将检测到连接失败并自动使用其它Pod重试。
kube-proxy对iptables的链进行了扩充,自定义了如下自定义链:
# 对于未能匹配到跳转规则的traffi设置mark 0x8000,有此标记的数据包会在filter表drop掉 KUBE-MARK-DROP - [0:0] # 对于符合条件的包设置mark 0x4000, 有此标记的数据包会在KUBE-POSTROUTING链中统一做MASQUERADE KUBE-MARK-MASQ - [0:0] # 针对通过nodeport访问的包做的操作 KUBE-NODEPORTS - [0:0] KUBE-POSTROUTING - [0:0] # 操作跳转规则的主要链 KUBE-SERVICES - [0:0]
为默认的prerouting、output和postrouting链增加规则,使得数据包可以跳转至自定义链
-A PREROUTING -m comment --comment "kubernetes service portals" -j KUBE-SERVICES -A OUTPUT -m comment --comment "kubernetes service portals" -j KUBE-SERVICES -A POSTROUTING -m comment --comment "kubernetes postrouting rules" -j KUBE-POSTROUTING
如果service类型为nodePort,从KUBE-SERVICE链->KUBE-NODEPORTS链->KUBE-SVC-***链:
-A KUBE-SERVICES -m comment --comment "kubernetes service nodeports; NOTE: this must be the last rule in this chain" -m addrtype --dst-type LOCAL -j KUBE-NODEPORTS -A KUBE-NODEPORTS -p tcp -m comment --comment "default/es1:http" -m tcp --dport 32135 -j KUBE-MARK-MASQ -A KUBE-NODEPORTS -p tcp -m comment --comment "default/es1:http" -m tcp --dport 32135 -j KUBE-SVC-LAS23QA33HXV7KBL
转跳过程如图:
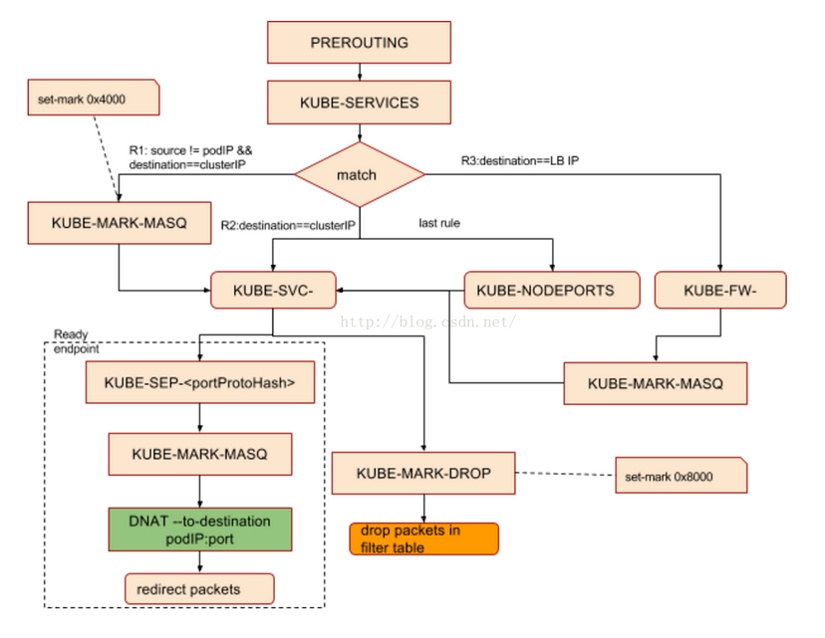
例如:要从服务地址service vip的80端口转发到后端两副本10.244.1.10、10.244.2.10的80端口
-A KUBE-SERVICES -d 10.11.97.177/32 -p tcp -m comment --comment "default/my-service: cluster IP" -m tcp --dport 80 -j KUBE-SVC-BEPXDJBUHFCSYIC3 # 50%的概率轮询后端pod -A KUBE-SVC-BEPXDJBUHFCSYIC3 -m comment --comment “default/my-service:” -m statistic --mode random --probability 0.50000000000 -j KUBE-SEP-U4UWLP4OR3LOJBXU -A KUBE-SVC-BEPXDJBUHFCSYIC3 -m comment --comment "default/my-service:" -j KUBE-SEP-QHRWSLKOO5YUPI7O -A KUBE-SEP-U4UWLP4OR3LOJBXU -s 10.244.1.10/32 -m comment --comment "default/my-service:" -j KUBE-MARK-MASQ -A KUBE-SEP-U4UWLP4OR3LOJBXU -p tcp -m comment --comment "default/my-service:" -m tcp -j DNAT --to-destination 10.244.1.10:80 -A KUBE-SEP-QHRWSLKOO5YUPI7O -s 10.244.2.10/32 -m comment --comment "default/my-service:" -j KUBE-MARK-MASQ -A KUBE-SEP-QHRWSLKOO5YUPI7O -p tcp -m comment --comment "default/my-service:" -m tcp -j DNAT --to-destination 10.244.2.10:80
缺点:添加规则不是增量的,而是先把当前所有规则都拷贝出来,再做修改然后再把修改后的规则保存回去。更新一条规则时会把iptables锁住。在服务数量达到一定量级的时候,性能基本不可接受。
-
IPVS代理模式
调用netlink接口创建IPVS规则, 并定期更新。由于改用了哈希表作为基础数据结构,并且在内核空间中工作。 因此,重定向的延迟更短、同步代理规则时具有更好的性能、支持更高的网络流量吞吐。
需要操作系统的IPVS内核模块可用,如果未检测到将退回到iptables代理模式
访问Service时,IPVS将流量重定向到某个backend Pods上。IPVS提供了更多选项来平衡后端Pod的流量,包括:
rr:round-robin
lc:least connection(smallest number of open connections)
dh:destination hashing
sh:source hashing
sed:shortest expected delay
nq:never queue
kubernetes服务发现架构:

为Pod创建Service
指定对象可以是Deployment、Pod、Statefulset等,表示根据其标签选择器创建一个名为Service的代理组件:
kubectl expose {$sourceType} {$ObjectName} --port=80 --target-port=8000
指定对象也可以在yaml文件中:
kubectl expose -f nginx-controller.yaml --port=80 --target-port=8000
创建出的Service中,定义了若干服务发现的协议以及端口。
在Service创建之后,会在集群里面创建一个虚拟的IP地址以及若干端口。
Service通过selector选择有某个label的Pod,会把它选择的Pod的IP地址+targetPort都挂载到后端。
通过kubectl describe该service可以看到Endpoints:描述了通过声明的selector选择了哪些Pod和对应的targetPort
Name: acct-b-cashweb-starter Namespace: acct Labels: app=acct-b-cashweb-starter wayne-app=acct-b wayne-ns=acct Annotations: <none> Selector: app=acct-b-cashweb-starter Type: ClusterIP IP: 10.20.114.38 Port: acct-b-cashweb-starter-19999 19999/TCP TargetPort: 19999/TCP Endpoints: 182.20.12.104:19999,182.20.86.207:19999 Session Affinity: None Events: <none>
如果没有定义selector,就不会自动创建相应的Endpoint对象,只能手动添加Endpoint对象,将服务手动映射到运行该服务的网络地址和端口:
apiVersion: v1
kind: Endpoints
metadata:
name: acct-b-cashweb-starter
namespace: acct
subsets:
- addresses:
- ip: 182.20.12.104
nodeName: 132.252.41.65
targetRef:
kind: Pod
name: acct-b-cashweb-starter-5db54685cb-5f66x
namespace: acct
- ip: 182.20.86.207
nodeName: 132.252.41.80
targetRef:
kind: Pod
name: acct-b-cashweb-starter-5db54685cb-dk5sj
namespace: acct
ports:
- name: acct-b-cashweb-starter-19999
port: 19999
protocol: TCP
Service的.spec.sessionAffinity配置会话保持,可以是None或ClientIP。
会话保持时通过.spec.sessionAffinityConfig.clientIP.timeoutSeconds配置保持时间
通过Service的.spec.type字段指定Service的类型,包括:
(1)ClusterIP(默认)
仅对集群内的其他应用暴露此服务。
在集群里,所有的Pod和Node都可以通过ClusterIP+端口去访问到这个Service,从而负载均衡的路由到后端Pod的targetPort上
IPVS模式下可以直接ping这个IP地址;iptables下则不能。
为了知道Service的变化、目前有哪些Service及它们的vip、Service的增加减少,要有一个组件来时刻监控记录Service和vip之间的映射关系,称为DNS解析记录。在集群内通过DNS访问该Service时,会返回ClusterIP。访问ClusterIP时会转到某个backend Pods,从而达到负载均衡的效果。
可以在多个namespace中创建同名的Service。解决这个问题,就用到DNS地址的扩展形式{service_name}.{namespace}:{port}
此前常用skyDNS和kubedns,目前常用CoreDNS,它采用更模块化、可扩展的框架构建。
Service创建的时候也可以指定clusterIP:None,k8s就不会给这个Headless Service分配虚拟IP地址,它也不通过kube-proxy做反向代理和负载均衡。

此时对应的每一个Endpoints,即每一个Pod,都会有对应的DNS域名,这样Pod之间就可以互相访问。直接通过ServiceName用DNS的方式会解析到所有后端Pod的IP地址,由客户端自己选择一个。返回的记录列表会随着Pod的生命周期变化。
此时从集群外访问服务的唯一方式就是通过kubectl工具开启调试主机到Kubernetes API的代理:
$ kubectl proxy --port=8080
使用地址http://localhost:8080/api/v1/proxy/namespaces/<NAMESPACE>/services/<SERVICE-NAME>:<PORT-NAME>/来访问服务。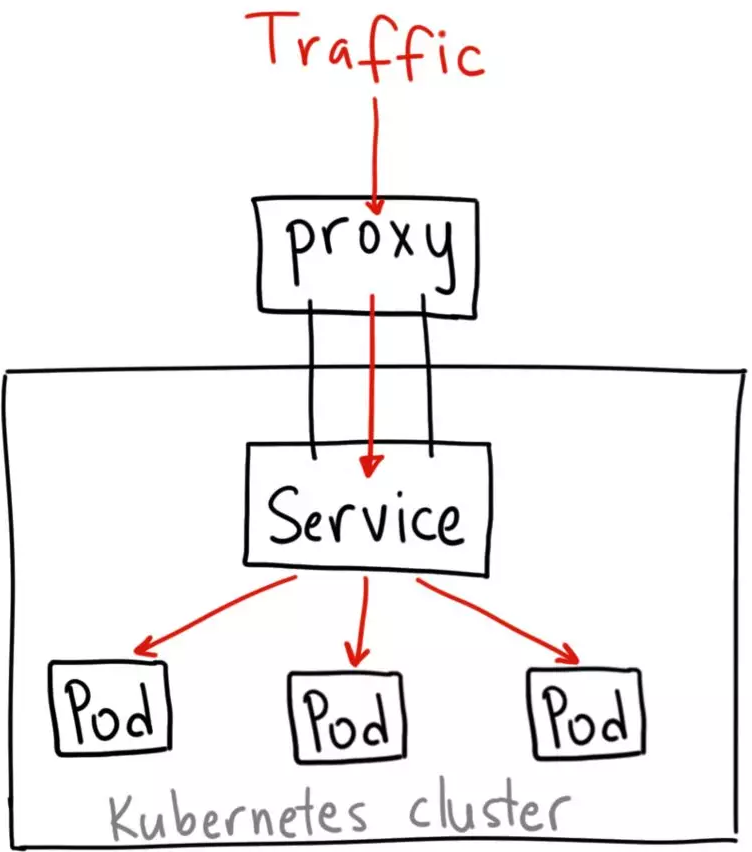
若特别指定Service的clusterIP为None,则Service成为Headless Service。 通过DNS访问该service时,会直接返回该Service对应的所有backend Pods的地址。
(2)NodePort
需要为Service指定一个或多个NodePort端口,端口需要在apiserver启动参数--service-node-port-range指定的范围内,默认只能使用30000–32767的端口
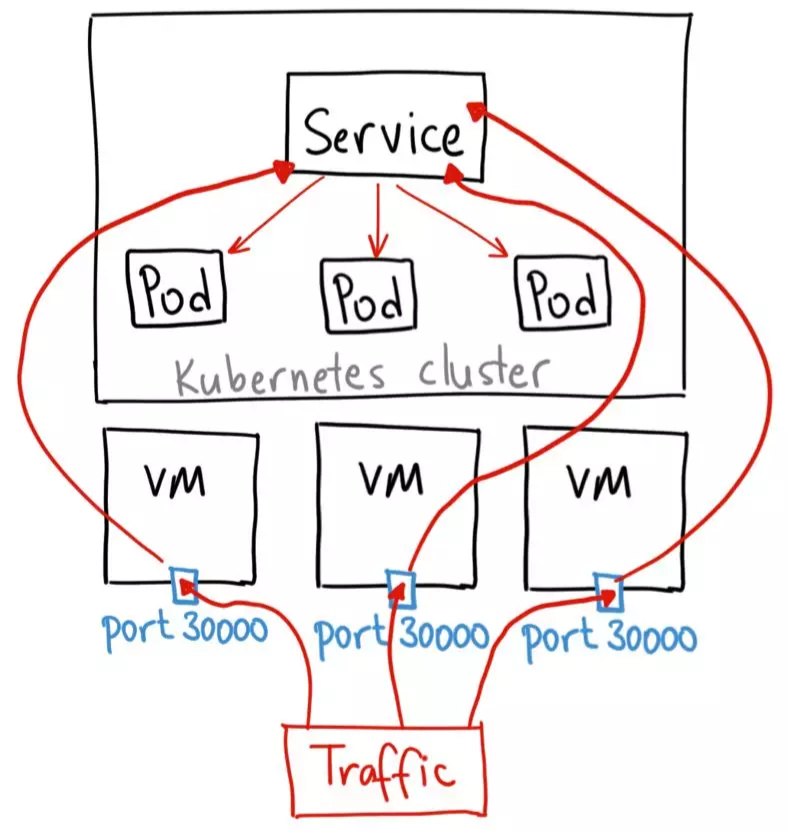
NodePort服务会自动创建ClusterIP服务。发往NodePort的流量,也会经过kube-proxy配置的规则,转换成发往ClusterIP的流量,紧接着转换成发送到后端具体的Pod的IP地址。
(3)ExternalName
不需要指定selector去选择哪些Pod提供服务,只需要在.spec.externalName指定一个其它域名即可
访问此Service时,会使用DNS CNAME机制把自己CNAME到指定的该域名上(可以是集群内域名,也可以是外部真实域名)
(4)LoadBalancer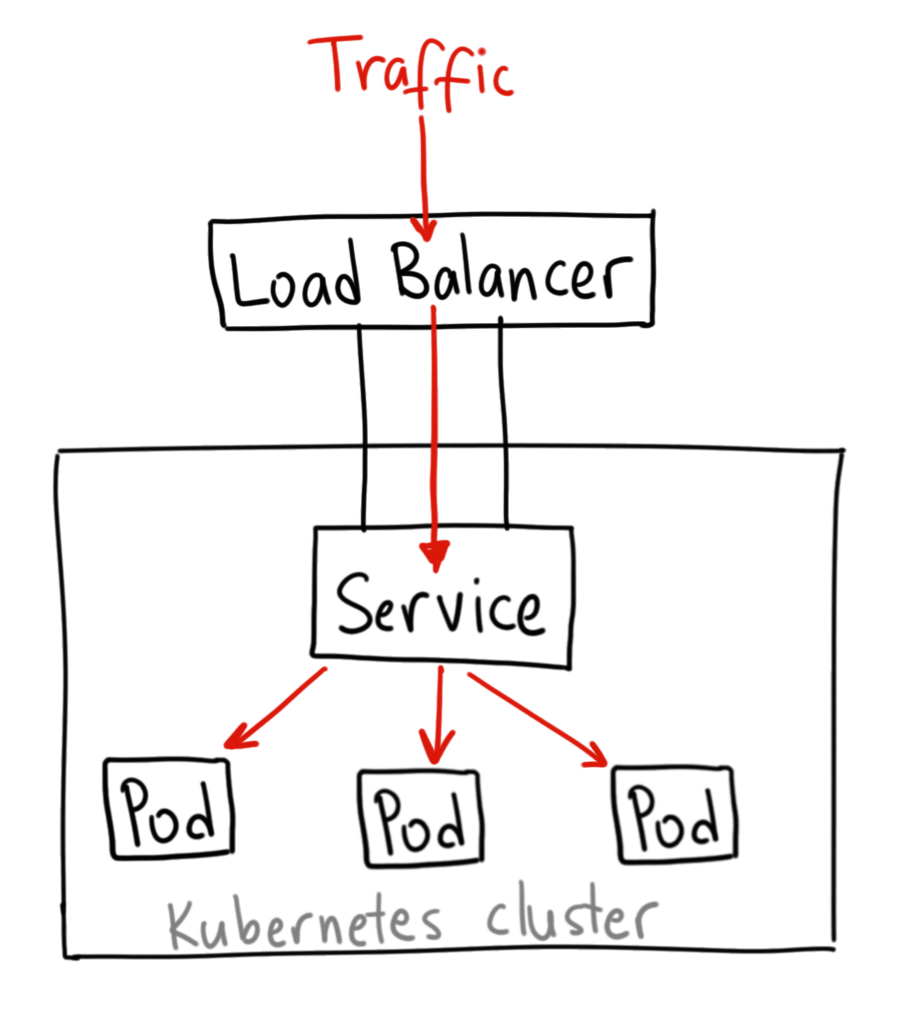
由外部的云服务商提供负载均衡,来自外部负载均衡器的流量将直接打到backend Pod上
但Spec中可以设置哪些字段、外部负载均衡器是如何工作的,这要依赖于云提供商
例如,某些云提供商允许设置loadBalancerIP,将根据用户设置的loadBalancerIP创建负载均衡器。 如果没有设置loadBalancerIP(或者云提供商不支持),将会给负载均衡器指派一个临时IP。
关于被提供的负载均衡器的信息,将会通过Service的.status.loadBalancer字段被发布出去:
status:
loadBalancer:
ingress:
- ip: 146.148.47.155
通过环境变量访问后端Pod
在集群内,除了通过Service名/ClusterIP+port访问服务,其实还可以通过环境变量访问
在同一个namespace里的Pod启动时,K8s会把Service的一些IP地址、端口,以及一些简单的配置,通过环境变量的方式放到Pod里。
容器启动之后,通过读取系统的环境变量读取到namespace里面其他service配置的地址或者端口号。
例如,一个名为redis-master的Service暴露了TCP端口6379,同时给它分配了Cluster IP地址10.0.0.11,在这个Service之后创建的Pod会生成如下环境变量:
REDIS_MASTER_SERVICE_HOST=10.0.0.11 REDIS_MASTER_SERVICE_PORT=6379 REDIS_MASTER_PORT=tcp://10.0.0.11:6379 REDIS_MASTER_PORT_6379_TCP=tcp://10.0.0.11:6379 REDIS_MASTER_PORT_6379_TCP_PROTO=tcp REDIS_MASTER_PORT_6379_TCP_PORT=6379 REDIS_MASTER_PORT_6379_TCP_ADDR=10.0.0.11

 浙公网安备 33010602011771号
浙公网安备 33010602011771号