
Java线程池总结
一、线程池
线程池适合处理的任务:执行时间短、工作内容较为单一。
合理使用线程池带来的好处:
1)降低资源消耗:重复利用已创建的线程降低线程创建和销毁造成的开销
2)提高响应速度:当任务到达时,任务可以不用等待线程创建就能立即执行
3)提高线程的可管理性:可以统一对线程进行分配、调优和监控
4)提供更多强大的功能:线程池具备可拓展性,允许开发人员向其中增加更多的功能。比如延时定时线程池SchedulerThreadPoolExecutor,允许任务延期执行或定期执行
线程池使应用能更加充分利用CPU、内存、网络、IO等系统资源。线程的创建需要开辟虚拟机栈、本地方法栈、程序计数器等线程私有的内存空间。
在线程销毁时需要回收这些系统资源。因此频繁的创建和销毁线程会浪费大量的系统资源,增加并发编程风险。另外,在服务器负载过大的时候,如何让新的线程等待或者友好地拒绝服务?这些都是线程本身无法解决的。所以需要通过线程池协调多个线程,并实现类似主次线程隔离、定时执行、周期执行等任务。线程池的作用包括:
1):利用线程池管理并复用线程、控制最大并发数等
2):实现任务线程队列缓存策略和拒绝机制
3):实现某些与时间相关的功能,如定时执行、周期执行
4):隔离线程环境。通过配置两个或多个线程池,将一台服务器上较慢的服务和其他服务隔离开,避免各服务线程相互影响。
ThreadPoolExecutor
UML类图:
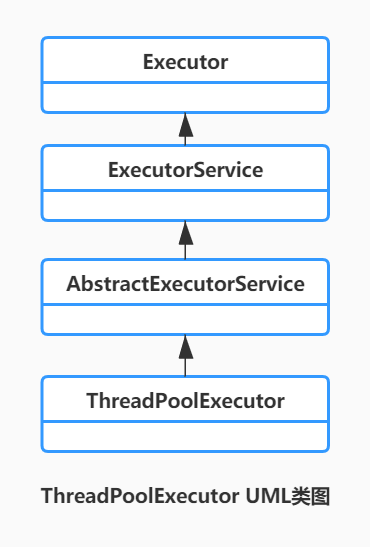
ThreadPoolExecutor实现的顶层接口是Executor,顶层接口Executor提供了一种思想:将任务提交和任务执行进行解耦。用户无需关注如何创建线程,如何调度线程执行任务,用户只需提供Runnable对象,将任务的运行逻辑提交到执行器(Executor)中,由Executor框架完成线程的调配和任务的执行部分。
ExecutorService接口增加了一些能力:
(1)扩充执行任务的能力,补充可以为一个或一批异步任务生成Future的方法;
(2)提供了管控线程池的方法,比如停止线程池的运行。
AbstractExecutorService则是上层的抽象类,将执行任务的流程串联了起来,保证下层的实现只需关注一个执行任务的方法即可。
最下层的实现类ThreadPoolExecutor实现最复杂的运行部分,ThreadPoolExecutor将会一方面维护自身的生命周期,另一方面同时管理线程和任务,使两者良好的结合从而执行并行任务。
主要参数:
1)corePoolSize 线程池核心线程的大小
2)maximumPoolSize 线程池最大线程的大小
3)keepAliveTime 空闲线程的存活时间
4)BlockingQueue 用来暂时保存任务的工作队列
5)RejectedExecutionHandler 线程池已经关闭或者饱和(达到了最大线程数且工作队列已满),executor()方法将调用Handler
参数详细说明:
1、corePoolSize 表示常驻核心线程数,如果大于0,则即使执行完任务,线程也不会被销毁(allowCoreThreadTimeOut为false)。因此这个值的设置非常关键,设置过小会导致线程频繁地创建和销毁,设置过大会造成浪费资源
2、maximumPoolSize 表示线程池能够容纳的最大线程数。必须大于或者等于1。
3、keepAliveTime 表示线程池中的线程空闲时间,当空闲时间达到keepAliveTime值时,线程会被销毁,避免浪费内存和句柄资源。在默认情况下,当线程池中的线程数大于corePoolSize时,keepAliveTime才起作用,达到空闲时间的线程会被销毁,直到只剩下corePoolSize个线程为止。但是当ThreadPoolExecutor的allowCoreThreadTimeOut设置为true时(默认false),核心线程超时后也会被回收。(一般设置60s)
4、TimeUnit 表示时间单位,keepAliveTime的时间单位通常是TimeUnit.SECONDS
5、BlockingQueue 表示缓存队列。
6、threadFactory 表示线程工厂。它用来生产一组相同任务的线程。线程池的命名是通过给threadFactory增加组名前缀来实现的。在用jstack分析时,就可以知道线程任务是由哪个线程工厂产生的。
7、handler 表示执行拒绝策略的对象。当超过workQueue的缓存上限的时候,就可以通过该策略处理请求,这是一种简单的限流保护。
JDK提供了4种拒绝策略:
AbortPolicy:中止策略,线程池会抛出异常并中止执行此任务;
CallerRunsPolicy:把任务交给添加此任务的(main)线程来执行;
DiscardPolicy:忽略此任务,忽略最新的一个任务;
DiscardOldestPolicy:忽略最早的任务,最先加入队列的任务。
默认的拒绝策略为 AbortPolicy 中止策略
private static final RejectedExecutionHandler defaultHandler =
new AbortPolicy();使用JDK提供的拒绝策略:
public static final ThreadPoolExecutor THREAD_POOL = new ThreadPoolExecutor(
5,
10,
60,
TimeUnit.SECONDS,
new LinkedBlockingQueue<>(10000),
new CustomThreadFactory("custom"),
new ThreadPoolExecutor.AbortPolicy()
);
我们还可以通过new RejectedExecutionHandler() 来重写rejectedExecution 方法来实现自定义拒绝策略,如:
public static final ThreadPoolExecutor THREAD_POOL = new ThreadPoolExecutor(
5,
10,
60,
TimeUnit.SECONDS,
new LinkedBlockingQueue<>(10000),
new CustomThreadFactory("custom"),
new RejectedExecutionHandler() {
@Override
public void rejectedExecution(Runnable r, ThreadPoolExecutor executor) {
// 打印日志
LOGGER.error("Task:{},rejected from:{}", r.toString(), executor.toString());
// 提交任务的线程直接执行被拒绝的任务,JVM不会另起线程执行!!!
r.run();
}
}
); 友好的拒绝策略可以是如下三种:
1):保存到数据库进行削峰填谷。在空闲时再取出来执行
2):转向某个提示页面
3):打印日志
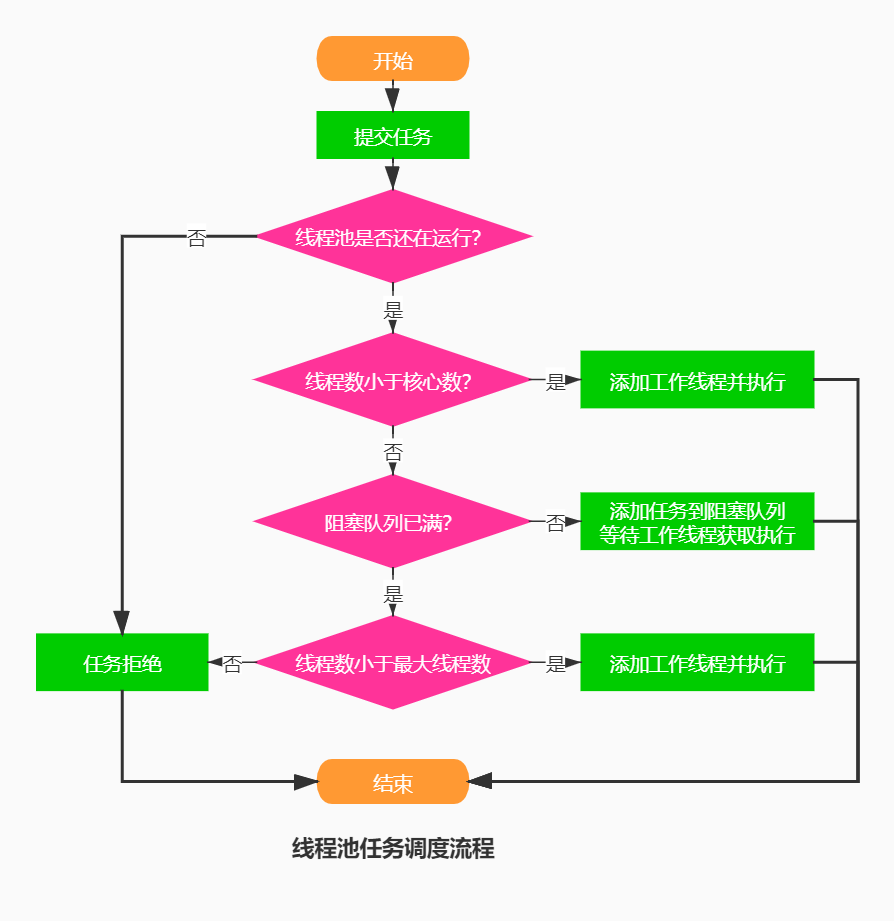
线程池处理任务规则及流程说明:
首先,所有的任务都是由execute方法完成的,这部分完成的工作是:检查现在线程池的运行状态、运行线程数、运行策略,决定接下来的执行流程,是直接申请线程执行,或是缓冲到队列中执行,亦或是直接拒绝该任务。
其执行过程如下:
1、首先检测线程池运行状态,如果不是RUNNING,则直接拒绝,线程池要保证在RUNNING的状态下执行任务。
2、如果workerCount < corePoolSize,则创建并启动一个线程来执行新提交的任务。
3、如果workerCount >= corePoolSize,且线程池内的阻塞队列未满,则将任务添加到该阻塞队列中。
注意:此处在成功加入到队列后,还会重新检查一下是否应该添加一个线程(因为在上次检查之后可能已有线程死掉了),或者在进入这个方法之后线程池关闭了。因此,需要重新检查线程池中线程的状态,并在必要时回滚排队,并创建一个线程执行当前任务。
4、如果workerCount >= corePoolSize && workerCount < maximumPoolSize,且线程池内的阻塞队列已满,则创建并启动一个线程来执行新提交的任务。
5、如果workerCount >= maximumPoolSize,并且线程池内的阻塞队列已满, 则根据拒绝策略来处理该任务, 默认的处理方式是直接抛异常。
6、线程池中存活的线程执行完当前任务后,会在循环中反复从BlockingQueue<Runnable>队列中获取任务来执行
总结使用线程池需要注意以下几点:
1、合理设置各类参数,应根据实际业务场景来设置合理的工作线程数
2、线程资源必须通过线程池提供,不允许在应用中自行显式创建线程
3、创建线程或线程池请指定有意义的线程名称,方便出错时回溯
4、线程池不允许使用Executors,而是通过ThreadPoolExecutor的方式来创建,这样的处理方式能更加明确线程池的运行规则,规避资源耗尽的风险。
另外,线程池中的线程数量不是越多越好,具体的数量需要评估每个任务的处理时间,以及当前计算机的处理器能力和数量。使用的线程过少,无法发挥处理器的性能;使用的线程过多,将会增加上下文切换的开销,反而起到相反的作用。
合理配置线程池
要想合理地配置线程池,就必须首先分析任务特征,可以从下面几个角度:
1)任务的性质:CPU密集型任务(处理任务不需要依赖外部 I/O),IO密集型任务(计算占比少,磁盘IO,网络IO占比多)或混合型任务
2)任务的优先级:高、中、低
3)任务的执行时间:长、中、短
4)任务的依赖性:是否依赖其他系统资源,如数据库连接,接口调用等
策略:
性质不同的任务(CPU密集型、IO密集型、速度优先、吞吐量优先)可以用不同规模的线程池分开处理,这样可以更好确定线程数量。
若CPU的核心数为N:【获取CPU核心数:Runtime.getRuntime().availableProcessors() 】
1)CPU密集型任务应配置尽可能少的线程,如配置核心数为 N+1 个线程的线程池。
2)由于IO密集型的任务并不是一直都在执行任务,存在读写阻塞等待,因此应配置较多的线程,如核心数 2*N 个,最大线程数 25*N 个
3)混合型的任务,如果可以拆分,将其拆分为一个CPU密集型任务和一个IO密集型任务,只要这两个任务执行的时间相差不是太大,那么分解后执行的吞吐量将高于串行执行的吞吐量。如果这两个任务执行的时间相差太大,则没必要进行分解。
4)优先级不同的任务可以使用优先级队列 PriorityBlockingQueue来处理,它可以让优先级高的任务先执行。
5)依赖数据库连接池的任务,因为线程提交SQL后需要等待数据库返回结果,等待的时间越长,则CPU空闲时间就越长,那么线程数应该设置得越大,这样才能更好地利用CPU。
6)建议使用有界队列,并可以根据需要设置大一点。基于链表的LinkedBlockingQueue比基于数组的ArrayBlockingQueue吞吐量高,因为增删多,需要内存大。
有界队列能增加系统的稳定性和预警能力,可以根据需要设置大一点,比如几千。有时会遇到任务执行缓慢的时候,为了避免任务被拒绝,可以适当将队列设置大一些。
7)大量的耗时任务执行的时候,并不需要瞬时的完成,而是关注如何使用有限的资源,尽可能在单位时间内处理更多的任务,也就是吞吐量优先。这个时候应该设置较大队列去缓冲并发任务,调整合适的核心线程数,避免过多引发 线程上下文切换频繁导致的资源消耗(会降低处理任务的速度,降低吞吐量)
参数动态化
ThreadPoolExecutor 提供了API供ThreadPoolExecutor的实例来动态设置线程池的参数。
以setCorePoolSize为例,在运行期线程池使用方调用此方法设置corePoolSize之后,线程池会直接覆盖原来的corePoolSize值,并且基于当前值和原始值的比较结果采取不同的处理策略。对于当前值小于当前工作线程数的情况,说明有多余的worker线程,此时会向当前idle的worker线程发起中断请求以实现回收,多余的worker在下次idle的时候也会被回收;对于当前值大于原始值且当前队列中有待执行任务,则线程池会创建新的worker线程来执行队列任务。
结合ZooKeeper分布式配置中心,利用Zookeeper watch机制,注册节点监听,节点变动自动拉取节点配置判断线程池参数是否变化,若变化,则修改线程池参数,实现即时修改,即时生效。
线程池的监控
如果系统中大量使用线程池,则有必要对线程池进行监控,方便出现问题时,根据线程池的使用状况快速定位问题。可以通过线程池提供的方法获取线程池的信息:
getPoolSize():获取当前线程池中线程的数量
getActiveCount():获取大致的活动的线程数(正在执行任务的线程)
getLargestPoolSize():获取largestPoolSize属性,线程池里曾经创建过的最大线程数量。通过这个数据可以知道线程池是否满过。
getTaskCount():返回已经计划执行的任务的大致总和
getCompletedTaskCount():返回已完成执行的任务的大致总数,小于或等于 getTaskCount()
也可通过直接调用 toString()方法获取大部分信息,当前线程池中线程的数量,活动的即正在执行任务的线程数量,队列大小,已经执行完的任务等。输出结果:
java.util.concurrent.ThreadPoolExecutor@379aea30[Running, pool size = 50, active threads = 50, queued tasks = 300, completed tasks = 1987247]
创建线程池例子,拒绝策略为打印日志并由提交任务的线程自己执行被拒绝的任务(提交任务的线程同步执行):
/**
* 创建一个用于发送邮件的线程池,核心线程数为1,最大线程数为5,线程空闲时间为60s,拒绝策略为打印日志并直接执行被拒绝的任务
*/
private static final ThreadPoolExecutor EXECUTOR = new ThreadPoolExecutor(1, 5, 60, TimeUnit.SECONDS, new LinkedBlockingQueue<Runnable>(50), new CustomThreadFactory("redeemSendMail"), new RejectedExecutionHandler() {
@Override
public void rejectedExecution(Runnable r, ThreadPoolExecutor executor) {
// 打印日志
LOGGER.error("Task:{},rejected from:{}", r.toString(), executor.toString());
// 提交任务的线程直接同步执行被拒绝的任务,JVM不会另起线程执行!!!
r.run();
}
});线程工厂:
/** * 创建线程的工厂,指定有意义的线程组名称,方便回溯 * * @author yangyongjie */ public class CustomThreadFactory implements ThreadFactory { /** * 线程池中的线程名称前缀 */ private String namePrefix; /** * 用于线程的名称递增排序 */ private AtomicInteger atomicInteger = new AtomicInteger(1); public CustomThreadFactory(String whatFeaturOfGroup) { this.namePrefix = "From CustomThreadFactory-" + whatFeaturOfGroup + "-worker-"; } @Override public Thread newThread(Runnable r) { String name = namePrefix + atomicInteger.getAndIncrement(); return new Thread(r, name); } }
线上监听通知修改线程池参数:
// 设置线程池核心线程数
THREAD_POOL.setCorePoolSize(6);
// 设置最大线程数
THREAD_POOL.setMaximumPoolSize(12);
线程池预热
TODO
应用
不同场景下,线程池的参数设置策略不同。
场景1:快速响应请求
追求的是响应速度,所以应该不设置队列去缓冲并发任务,调高corePoolSize和maxPoolSize去尽可能创造多的线程快速执行任务。
场景2:快速处理批量任务
任务量大,不需要瞬时完成,尽可能快执行完成即可。因此关注点在如何使用有限的资源,尽可能在单位时间内处理更多的任务,也就是吞吐量优先的问题。
所以应设置队列去缓冲并发任务,调整合适的corePoolSize去设置处理任务的线程数。在这里,设置的线程数过多可能还会引发线程上下文切换频繁的问题,也会降低处理任务的速度,降低吞吐量。
线程池应用场景
后台批量任务
异步处理
分布式计算
补充:怎么理解Runnable?
Runnable不是线程,是线程可执行的任务。
run()方法内是具体执行的任务,使用Runnable进行封装,使线程可直接执行。
END

 浙公网安备 33010602011771号
浙公网安备 33010602011771号