
华为昇腾AI服务器部署Triton Inference Server,运行yolov8s目标检测服务化推理 - 指南
在华为昇腾环境上部署Triton Inference Server
1、背景
随着人工智能技术的快速发展,模型推理服务的部署效率与性能优化成为实际应用中的关键挑战。Triton Inference Server作为NVIDIA开源的推理服务框架,以其多框架支持、动态批处理和高并发能力受到广泛关注。昇腾800IA2作为国产AI加速卡,在推理场景下展现出优异的能效比和计算性能。
本文将详细介绍在昇腾800IA2硬件环境上部署Triton Inference Server的完整流程,并以目标检测小模型的服务化推理为实践案例,验证部署方案的可行性和性能表现。通过本实践,读者将了解:
- 昇腾CANN软件栈与Triton Server的兼容性配置
- 针对昇腾硬件的模型转换
- 基于Triton的推理服务部署
本博客不仅适用于目标检测模型,其方法论亦可扩展至其他计算机视觉乃至自然语言处理任务的模型部署,为在国产AI硬件上构建高效推理服务提供参考。
2、环境介绍
硬件:
- Atlas800IA2
- 910B (32GB显存)
- CPU (KUNPENG)
- 内存 (16GB)
软件: - NPU驱动: 25.2.0
- CANN版本:8.2.RC1
- Triton: 2.42.0
3、资源获取
- 集成docker环境获取地址:https://download.csdn.net/download/weixin_50005386/92232598
- 相关模型和源码获取地址:https://download.csdn.net/download/weixin_50005386/92232604
4、创建triton环境
1、使用以下命令创建一个全新的tritonserver+ascend的环境;
docker run -itd -u root \
--net=host \
--ipc=host \
--privileged \
--device=/dev/davinci_manager \
--device=/dev/devmm_svm \
--device=/dev/hisi_hdc \
-v /var/log/npu/:/usr/slog \
-v /usr/local/bin/npu-smi:/usr/local/bin/npu-smi \
-v /usr/local/Ascend/driver:/usr/local/Ascend/driver \
-v /usr/local/sbin:/usr/local/sbin \
-v /home/data:/data \
--name tritonserver \
--entrypoint=/bin/bash \
28961f2d1d8b如图所示:
2、使用docker exec -it -u 0 tritonserver bash进入环境;
3、进入源码的models路径,运行atc.sh,将onnx模型转换成om模型
atc内容:
atc --model=yolov8s.onnx --framework=5 --output=yolov8s --input_format=NCHW --op_select_implmode=high_performance --input_shape='images:1,3,640,640' --log=info --soc_version=Ascend910B4运行完成提示:ATC run success, welcome to the next use.
4、运行python infer.py使用脚本做模型纯推理
运行后在本目录下生成一个output_image.jpg的推理结果图
运行结果:
正在初始化推理会话…
[INFO] acl init success
[INFO] open device 0 success
[INFO] create new context
[INFO] load model yolov8s.om success
[INFO] create model description success
推理会话初始化成功。
正在进行图像预处理…
原始图像尺寸: 1024x683
预处理信息 - 缩放因子: 0.625, 填充: (0, 107)
开始推理…
推理完成。
正在进行后处理…
<class ‘list’>
(8400, 84)
最终检测到 1 个目标。
检测到 dog: 0.945
坐标范围: x1:113, y1:130, x2:917, y2:589
结果图像已保存至: output_image.jpg
[INFO] unload model success, model Id is 1
资源已释放。
[INFO] end to reset device 0
[INFO] end to finalize acl
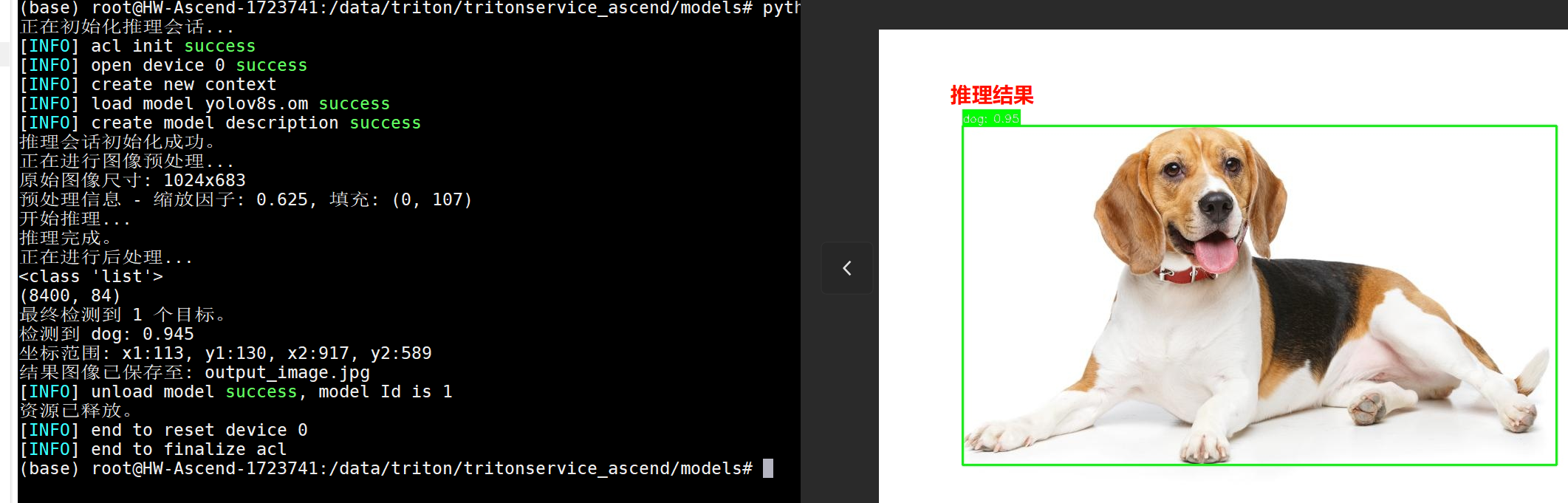
至此说明环境没有问题;
5、triton服务化推理
1、进入源代码主目录下,有一个run_triton_service.sh的脚本,内容如下:
tritonserver --model-repository=./model_repository --log-info=true --log-verbose=1
它主要是使用tritonserver 运行模型仓;我们进入查看./model_repository的目录结构:
model_repository/ # Triton模型仓库根目录
└── yolov8s # 模型目录(模型名称:yolov8s)
├── 1 # 版本目录(版本号:1)
│ ├── model.py # Python模型推理脚本
│ ├── __pycache__/ # Python缓存目录
│ │ └── model.cpython-310.pyc # 编译后的Python字节码
│ └── yolov8s.om # 昇腾离线模型文件(通过ATC转换)
└── config.pbtxt # 模型配置文件- 关键文件说明
- config.pbtxt- 模型配置
name: "yolov8s" # 模型名称
backend: "python" # 使用Python后端
max_batch_size: 1 # 最大批处理大小
input: [
{
name: "images", # 输入名称
data_type: TYPE_FP32, # 数据类型
dims: [3, 640, 640] # 输入维度 [通道, 高, 宽]
}
]
output: [
{
name: "output0", # 输出名称
data_type: TYPE_FP32,
dims: [84, 8400] # 输出维度
}
]- 2. model.py- Python推理脚本import cv2
import numpy as np
from ais_bench.infer.interface import InferSession
from torch.utils.dlpack import to_dlpack, from_dlpack
import triton_python_backend_utils as pb_utils
class TritonPythonModel:
def initialize(self, args):
self.model_path = "./model_repository/yolov8s/1/yolov8s.om"
self.device_id = 0
self.session = InferSession(self.device_id, self.model_path)
def execute(self, requests):
responses = []
for res in requests:
image = from_dlpack(pb_utils.get_input_tensor_by_name(res, 'images').to_dlpack())
image = np.array(image)
outputs = self.session.infer([image], mode="static")
output_tensor = pb_utils.Tensor('output0', outputs[0])
response = pb_utils.InferenceResponse(output_tensors=[output_tensor])
responses.append(response)
return responses
def finalize(self):
print("Inference finalized")- 3. yolov8s.om- 昇腾离线模型
通过ATC工具从ONNX/PyTorch转换而来
针对昇腾硬件优化,包含图编译和算子优化2、启动服务化程序:bash run_triton_service.sh
如图所示,说明运行成功:
I1029 16:37:47.487552 4741 server.cc:676]
±--------±--------±-------+
| Model | Version | Status |
±--------±--------±-------+
| yolov8s | 1 | READY |
±--------±--------±-------+
6、客户端代码运行
进入client目录下,该目录是triton的客户端代码目录;
clienet.py的代码样例:
#!/usr/bin/env python
import argparse
import numpy as np
import sys
import cv2
import tritonclient.grpc as grpcclient
from tritonclient.utils import InferenceServerException
CLASS_NAMES = [
"person", "bicycle", "car", "motorcycle", "airplane", "bus", "train", "truck", "boat", "traffic light",
"fire hydrant", "stop sign", "parking meter", "bench", "bird", "cat", "dog", "horse", "sheep", "cow",
"elephant", "bear", "zebra", "giraffe", "backpack", "umbrella", "handbag", "tie", "suitcase", "frisbee",
"skis", "snowboard", "sports ball", "kite", "baseball bat", "baseball glove", "skateboard", "surfboard",
"tennis racket", "bottle", "wine glass", "cup", "fork", "knife", "spoon", "bowl", "banana", "apple",
"sandwich", "orange", "broccoli", "carrot", "hot dog", "pizza", "donut", "cake", "chair", "couch",
"potted plant", "bed", "dining table", "toilet", "tv", "laptop", "mouse", "remote", "keyboard",
"cell phone", "microwave", "oven", "toaster", "sink", "refrigerator", "book", "clock", "vase", "scissors",
"teddy bear", "hair drier", "toothbrush"
]
CONF_THRESHOLD = 0.25
IOU_THRESHOLD = 0.45
INPUT_NAMES = ["images"]
OUTPUT_NAMES = ["output0"]
def preprocess_image(image_path, input_shape=(640, 640)):
"""
"""
original_image = cv2.imread(image_path)
if original_image is None:
raise ValueError(f"无法读取图像: {image_path}")
original_h, original_w = original_image.shape[:2]
input_h, input_w = input_shape
scale = min(input_h / original_h, input_w / original_w)
new_h, new_w = int(original_h * scale), int(original_w * scale)
resized_image = cv2.resize(original_image, (new_w, new_h))
padded_image = np.full((input_h, input_w, 3), 114, dtype=np.uint8)
dx = (input_w - new_w) // 2
dy = (input_h - new_h) // 2
padded_image[dy:dy+new_h, dx:dx+new_w] = resized_image
normalized_image = padded_image.astype(np.float32) / 255.0
blob = np.transpose(normalized_image, (2, 0, 1))
blob = np.expand_dims(blob, axis=0)
return blob, original_image, (scale, dx, dy)
def postprocess_yolov8(outputs, original_shape, preprocess_info, input_shape=(640, 640), conf_threshold=0.25, iou_threshold=0.45):
"""
修正后的后处理函数:正确的坐标映射
"""
original_h, original_w = original_shape[:2]
input_h, input_w = input_shape
scale, pad_x, pad_y = preprocess_info
prediction = outputs.squeeze(0).transpose(1, 0) # (8400, 84)
boxes = []
scores = []
class_ids = []
for i in range(prediction.shape[0]):
# 模型输出的是基于640×640输入尺寸的绝对坐标(包含填充)
cx, cy, w, h = prediction[i, :4]
classes_scores = prediction[i, 4:]
max_score = np.max(classes_scores)
class_id = np.argmax(classes_scores)
if max_score >= conf_threshold:
# 将中心点坐标转换为边界框坐标
x1 = cx - w / 2
y1 = cy - h / 2
x2 = cx + w / 2
y2 = cy + h / 2
# 关键修正:正确的坐标映射步骤
# 1. 去除填充的影响
x1 = max(0, x1 - pad_x)
y1 = max(0, y1 - pad_y)
x2 = max(0, x2 - pad_x)
y2 = max(0, y2 - pad_y)
# 2. 缩放到原始图像尺寸(除以缩放因子)
x1 = int(x1 / scale)
y1 = int(y1 / scale)
x2 = int(x2 / scale)
y2 = int(y2 / scale)
# 3. 确保坐标在有效范围内
x1 = max(0, min(x1, original_w))
y1 = max(0, min(y1, original_h))
x2 = max(0, min(x2, original_w))
y2 = max(0, min(y2, original_h))
# 只保留有效的检测框
if x2 > x1 and y2 > y1 and (x2 - x1) > 5 and (y2 - y1) > 5:
boxes.append([x1, y1, x2, y2])
scores.append(max_score)
class_ids.append(class_id)
# 应用NMS
if len(boxes) > 0:
boxes = np.array(boxes)
scores = np.array(scores)
class_ids = np.array(class_ids)
indices = cv2.dnn.NMSBoxes(boxes.tolist(), scores.tolist(), conf_threshold, iou_threshold)
if len(indices) > 0:
indices = indices.flatten()
return boxes[indices], scores[indices], class_ids[indices]
return np.array([]), np.array([]), np.array([])
def draw_detections(image, boxes, scores, class_ids):
"""
绘制检测结果
"""
h, w = image.shape[:2]
for i in range(len(boxes)):
box = boxes[i]
score = scores[i]
class_id = class_ids[i]
x1 = int(box[0])
y1 = int(box[1])
x2 = int(box[2])
y2 = int(box[3])
# 确保坐标在有效范围内
x1 = max(0, min(x1, w-1))
y1 = max(0, min(y1, h-1))
x2 = max(0, min(x2, w-1))
y2 = max(0, min(y2, h-1))
color = (0, 255, 0) # 绿色框
cv2.rectangle(image, (x1, y1), (x2, y2), color, 2)
label = f"{CLASS_NAMES[class_id]}: {score:.2f}"
label_size = cv2.getTextSize(label, cv2.FONT_HERSHEY_SIMPLEX, 0.5, 2)[0]
cv2.rectangle(image, (x1, y1 - label_size[1] - 10), (x1 + label_size[0], y1), color, -1)
cv2.putText(image, label, (x1, y1 - 5),
cv2.FONT_HERSHEY_SIMPLEX, 0.5, (255, 255, 255), 1)
print(f"检测到 {CLASS_NAMES[class_id]}: {score:.3f}")
print(f"坐标范围: x1:{x1}, y1:{y1}, x2:{x2}, y2:{y2}")
return image
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--input',
type=str,
help='Input file to load from in image or video mode')
parser.add_argument('-m',
'--model',
type=str,
required=False,
default='yolov8s',
help='Inference model name, default yolov7')
parser.add_argument('--width',
type=int,
required=False,
default=640,
help='Inference model input width, default 640')
parser.add_argument('--height',
type=int,
required=False,
default=640,
help='Inference model input height, default 640')
parser.add_argument('-u',
'--url',
type=str,
required=False,
default='localhost:8001',
help='Inference server URL, default localhost:8001')
parser.add_argument('-o',
'--out',
type=str,
required=False,
default='',
help='Write output into file instead of displaying it')
parser.add_argument('-f',
'--fps',
type=float,
required=False,
default=24.0,
help='Video output fps, default 24.0 FPS')
parser.add_argument('-i',
'--model-info',
action="store_true",
required=False,
default=False,
help='Print model status, configuration and statistics')
parser.add_argument('-v',
'--verbose',
action="store_true",
required=False,
default=False,
help='Enable verbose client output')
parser.add_argument('-t',
'--client-timeout',
type=float,
required=False,
default=None,
help='Client timeout in seconds, default no timeout')
parser.add_argument('-s',
'--ssl',
action="store_true",
required=False,
default=False,
help='Enable SSL encrypted channel to the server')
parser.add_argument('-r',
'--root-certificates',
type=str,
required=False,
default=None,
help='File holding PEM-encoded root certificates, default none')
parser.add_argument('-p',
'--private-key',
type=str,
required=False,
default=None,
help='File holding PEM-encoded private key, default is none')
parser.add_argument('-x',
'--certificate-chain',
type=str,
required=False,
default=None,
help='File holding PEM-encoded certicate chain default is none')
FLAGS = parser.parse_args()
try:
triton_client = grpcclient.InferenceServerClient(
url=FLAGS.url,
verbose=FLAGS.verbose,
ssl=FLAGS.ssl,
root_certificates=FLAGS.root_certificates,
private_key=FLAGS.private_key,
certificate_chain=FLAGS.certificate_chain)
except Exception as e:
print("context creation failed: " + str(e))
sys.exit()
# Health check
if not triton_client.is_server_live():
print("FAILED : is_server_live")
sys.exit(1)
if not triton_client.is_server_ready():
print("FAILED : is_server_ready")
sys.exit(1)
if not triton_client.is_model_ready(FLAGS.model):
print("FAILED : is_model_ready")
sys.exit(1)
if FLAGS.model_info:
# Model metadata
try:
metadata = triton_client.get_model_metadata(FLAGS.model)
print(metadata)
except InferenceServerException as ex:
if "Request for unknown model" not in ex.message():
print("FAILED : get_model_metadata")
print("Got: {}".format(ex.message()))
sys.exit(1)
else:
print("FAILED : get_model_metadata")
sys.exit(1)
# Model configuration
try:
config = triton_client.get_model_config(FLAGS.model)
if not (config.config.name == FLAGS.model):
print("FAILED: get_model_config")
sys.exit(1)
print(config)
except InferenceServerException as ex:
print("FAILED : get_model_config")
print("Got: {}".format(ex.message()))
sys.exit(1)
if True:
if not FLAGS.input:
print("FAILED: no input image")
sys.exit(1)
inputs = []
outputs = []
inputs.append(grpcclient.InferInput(INPUT_NAMES[0], [1, 3, FLAGS.width, FLAGS.height], "FP32"))
outputs.append(grpcclient.InferRequestedOutput(OUTPUT_NAMES[0]))
print("Creating buffer from image file...")
# 图像预处理
print("正在进行图像预处理...")
input_blob, original_image, preprocess_info = preprocess_image(str(FLAGS.input))
original_h, original_w = original_image.shape[:2]
print(f"原始图像尺寸: {original_w}x{original_h}")
print(f"预处理信息 - 缩放因子: {preprocess_info[0]:.3f}, 填充: ({preprocess_info[1]}, {preprocess_info[2]}) input shape:{input_blob.shape}")
# input_image = cv2.imread(str(FLAGS.input))
# input_image = cv2.resize(input_image, (FLAGS.width, FLAGS.height))
# input_image = cv2.cvtColor(input_image, cv2.COLOR_BGR2RGB)
# print("input shape:", input_image.shape)
# input_image = np.transpose(input_image, (2, 0, 1)) # 从(H,W,C)变为(C,H,W)
# input_image = np.expand_dims(input_image, axis=0) # 增加批次维度,变为(1,C,H,W)
# input_image = np.array(input_image, dtype=np.float32)
# print("get input shape:", input_image.shape)
inputs[0].set_data_from_numpy(input_blob)
print("Invoking inference...")
results = triton_client.infer(model_name=FLAGS.model,
inputs=inputs,
outputs=outputs,
client_timeout=FLAGS.client_timeout)
if FLAGS.model_info:
statistics = triton_client.get_inference_statistics(model_name=FLAGS.model)
if len(statistics.model_stats) != 1:
print("FAILED: get_inference_statistics")
sys.exit(1)
print(statistics)
print("Done")
for output in OUTPUT_NAMES:
result = results.as_numpy(output)
print(f"Received result buffer \"{output}\" of size {result.shape}")
print(f"Naive buffer sum: {np.sum(result)}")
det_outputs = results.as_numpy(OUTPUT_NAMES[0])
# 4. 后处理
print("正在进行后处理...")
boxes, scores, class_ids = postprocess_yolov8(det_outputs, (original_h, original_w), preprocess_info)
print(f"最终检测到 {len(boxes)} 个目标。")
# 5. 绘制结果
if len(boxes) > 0:
result_image = draw_detections(original_image.copy(), boxes, scores, class_ids)
# 保存结果图像
cv2.imwrite('out.jpg', result_image)
print(f"结果图像已保存至: out.jpg")
else:
print("未检测到任何目标。")
# 保存原始图像用于调试
cv2.imwrite('out.jpg', original_image)新建一个终端,进入tritonserver容器,使用命令行运行python client.py --input dog.jpg 程序,如下输出结果,并且生成一个out.jpg的结果图。
Creating buffer from image file…
正在进行图像预处理…
原始图像尺寸: 1024x683
预处理信息 - 缩放因子: 0.625, 填充: (0, 107) input shape:(1, 3, 640, 640)
Invoking inference…
Done
Received result buffer “output0” of size (1, 84, 8400)
Naive buffer sum: 6695313.5
正在进行后处理…
最终检测到 1 个目标。
检测到 dog: 0.945
坐标范围: x1:113, y1:130, x2:917, y2:589
结果图像已保存至: out.jpg

至此,我们成功完成了在昇腾环境上基于Triton Inference Server的YOLOv8s服务化推理部署。这一方案具有良好的通用性和可移植性:
方案优势与扩展性
通用性验证
环境兼容性:本方案适用于所有支持OM模型推理的昇腾硬件平台
模型扩展性:部署方法论可平滑迁移至其他视觉任务模型(分类、分割等)
框架无关性:支持PyTorch、TensorFlow等多种训练框架转换的OM模型。适用场景
边缘计算场景的昇腾设备部署
云端推理服务的国产化替代
需要统一服务化接口的多模型管理

 浙公网安备 33010602011771号
浙公网安备 33010602011771号