

完整教程:【DINOv3教程1-图像分割】使用DINOv3+逻辑回归器进行图像前景分割【附源码】
《博主简介》
小伙伴们好,我是阿旭。
专注于计算机视觉领域,包括目标检测、图像分类、图像分割和目标跟踪等项目开发,提供模型对比实验、答疑辅导等。
《------往期经典推荐------》
二、机器学习实战专栏【链接】,已更新31期,欢迎关注,持续更新中~~
三、深度学习【Pytorch】专栏【链接】
四、【Stable Diffusion绘画系列】专栏【链接】
五、YOLOv8改进专栏【链接】,持续更新中~~
六、YOLO性能对比专栏【链接】,持续更新中~
《------正文------》
目录
引言
DINOv3是Meta于2025年8月推出的第三代自监督视觉基础模型,其核心优势在于:首次证明了自监督学习模型能在图像分类、目标检测、语义分割等超过60项视觉任务上全面超越弱监督和专业模型
,并且仅需单一冻结的骨干网络无需微调即可实现多任务高性能,极大提升了推理效率和部署灵活性。
本文将详细介绍如何使用最新的DINOv3模型搭配逻辑回归器进行图像前景分割,包含完整步骤与代码说明,基本流程如下:
- 特征学习:利用DINOv3预训练模型提取图像patch的高级特征
- 数据准备:将图像和mask对齐,准备训练数据
- 模型训练:使用逻辑回归将特征映射到前景/背景标签
- 模型验证:通过交叉验证选择最佳参数
- 应用部署:保存模型并用于新图像的前景分割
这种方法的优势在于利用了DINOv3强大的自监督学习能力,无需大量标注数据就能获得高质量的视觉特征表示。
1. 导入必要的库和模块
import io
import os
import pickle
import tarfile
import urllib
from PIL import Image
import numpy as np
import matplotlib.pyplot as plt
from scipy import signal
from sklearn.metrics import precision_recall_curve
from sklearn.metrics import average_precision_score
from sklearn.linear_model import LogisticRegression
import torch
import torchvision.transforms.functional as TF
from tqdm import tqdm
from transformers import AutoModel这些库分别用于:
- 文件操作和数据处理(io, os, pickle等)
- 图像处理(PIL, torchvision)
- 数值计算和科学计算(numpy, scipy)
- 机器学习(sklearn)
- 深度学习(torch)
- 进度显示(tqdm)
- 模型加载(transformers)
2. 加载DINOv3预训练模型
model = AutoModel.from_pretrained(
r'D:\7studying\DinoV3_Study\dinov3-main\PreModels\dinov3-vits16-pretrain-lvd1689m',
local_files_only=True
)加载本地的DINOv3预训练视觉Transformer模型,该模型已经学习了丰富的视觉特征表示。这里加载的是dinov3-vits16-pretrain-lvd1689m模型。
3. 数据加载和预处理
def load_images_from_path(base_path):
images = []
for name in os.listdir(base_path):
image_path = os.path.join(base_path, name)
image = Image.open(image_path)
images.append(image)
return images
images = load_images_from_path(r'D:\7studying\DinoV3_Study\dinov3-main\datasets\data1\images')
labels = load_images_from_path(r'D:\7studying\DinoV3_Study\dinov3-main\datasets\data1\masks')加载图像和对应的mask标签数据,用于训练前景分割模型。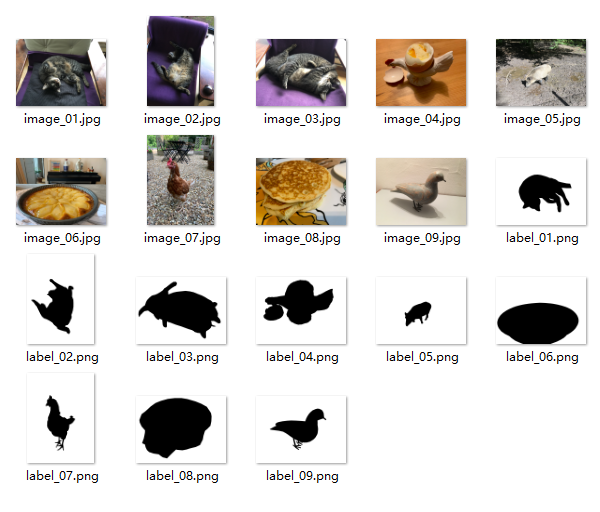
4. 数据可视化
# 显示第一张图像及其mask、前景和背景
data_to_show = [image, mask, foreground, background]
data_labels = ["Image", "Mask", "Foreground", "Background"]
plt.figure(figsize=(16, 4), dpi=300)
for i in range(len(data_to_show)):
plt.subplot(1, len(data_to_show), i + 1)
plt.imshow(data_to_show[i])
plt.axis('off')
plt.title(data_labels[i], fontsize=12)可视化展示原始图像、mask标签、前景和背景,帮助理解数据。
5. 图像预处理函数
def resize_transform(mask_image, image_size=768, patch_size=16):
w, h = mask_image.size
h_patches = int(image_size / patch_size)
w_patches = int((w * image_size) / (h * patch_size))
target_size = (h_patches * patch_size, w_patches * patch_size)
resized_image = TF.resize(mask_image, target_size)
tensor_image = TF.to_tensor(resized_image)
return tensor_image, (h_patches, w_patches)将图像调整为适合ViT模型处理的尺寸,确保图像尺寸能被patch大小(16)整除。

6. 特征提取和训练数据准备
with torch.inference_mode():
for i in tqdm(range(n_images), desc="Processing images"):
# 1. 加载mask并量化
mask_i = labels[i].split()[-1]
mask_i_resized, (h_patches, w_patches) = resize_transform(mask_i)
with torch.no_grad():
mask_i_quantized = patch_quant_filter(mask_i_resized).squeeze().view(-1).detach().cpu()
# 2. 加载并预处理图像
image_i = images[i].convert('RGB')
image_i_resized,_ = resize_transform(image_i)
image_i_resized = TF.normalize(image_i_resized, mean=IMAGENET_MEAN, std=IMAGENET_STD)
image_i_resized = image_i_resized.unsqueeze(0)
# 3. 使用DINOv3提取特征
outputs = model(image_i_resized)
patch_features = outputs.last_hidden_state[:, 1:, :] # 去掉cls token
# 4. 确保特征和标签数量一致
if actual_patches > expected_patches:
patch_features = patch_features[:, :expected_patches, :]这是整个流程的核心部分:
- Mask处理:将mask图像量化为patch级别的标签
- 图像预处理:调整图像大小并进行标准化
- 特征提取:使用DINOv3模型提取每个patch的特征表示
- 数据对齐:确保特征向量和标签数量一致
7. 数据过滤和准备
# keeping only the patches that have clear positive or negative label
idx = (ys < 0.01) | (ys > 0.99)
xs = xs[idx]
ys = ys[idx]
image_index = image_index[idx]只保留标签非常明确(接近0或1)的patch,过滤掉模糊的中间值,提高训练质量。
8. 模型训练和验证
# 使用留一法交叉验证寻找最佳参数
cs = np.logspace(-7, 0, 8)
scores = np.zeros((n_images, len(cs)))
for i in range(n_images):
# 留一法:用除第i张图像外的所有图像训练,用第i张图像验证
train_selection = image_index != float(i)
fold_x = xs[train_selection].numpy()
fold_y = (ys[train_selection] > 0).long().numpy()
val_x = xs[~train_selection].numpy()
val_y = (ys[~train_selection] > 0).long().numpy()
for j, c in enumerate(cs):
# 训练逻辑回归分类器
clf = LogisticRegression(random_state=0, C=c, max_iter=10000).fit(fold_x, fold_y)
output = clf.predict_proba(val_x)
precision, recall, thresholds = precision_recall_curve(val_y, output[:, 1])
s = average_precision_score(val_y, output[:, 1])
scores[i, j] = s使用留一法交叉验证训练逻辑回归器,寻找最佳的正则化参数C。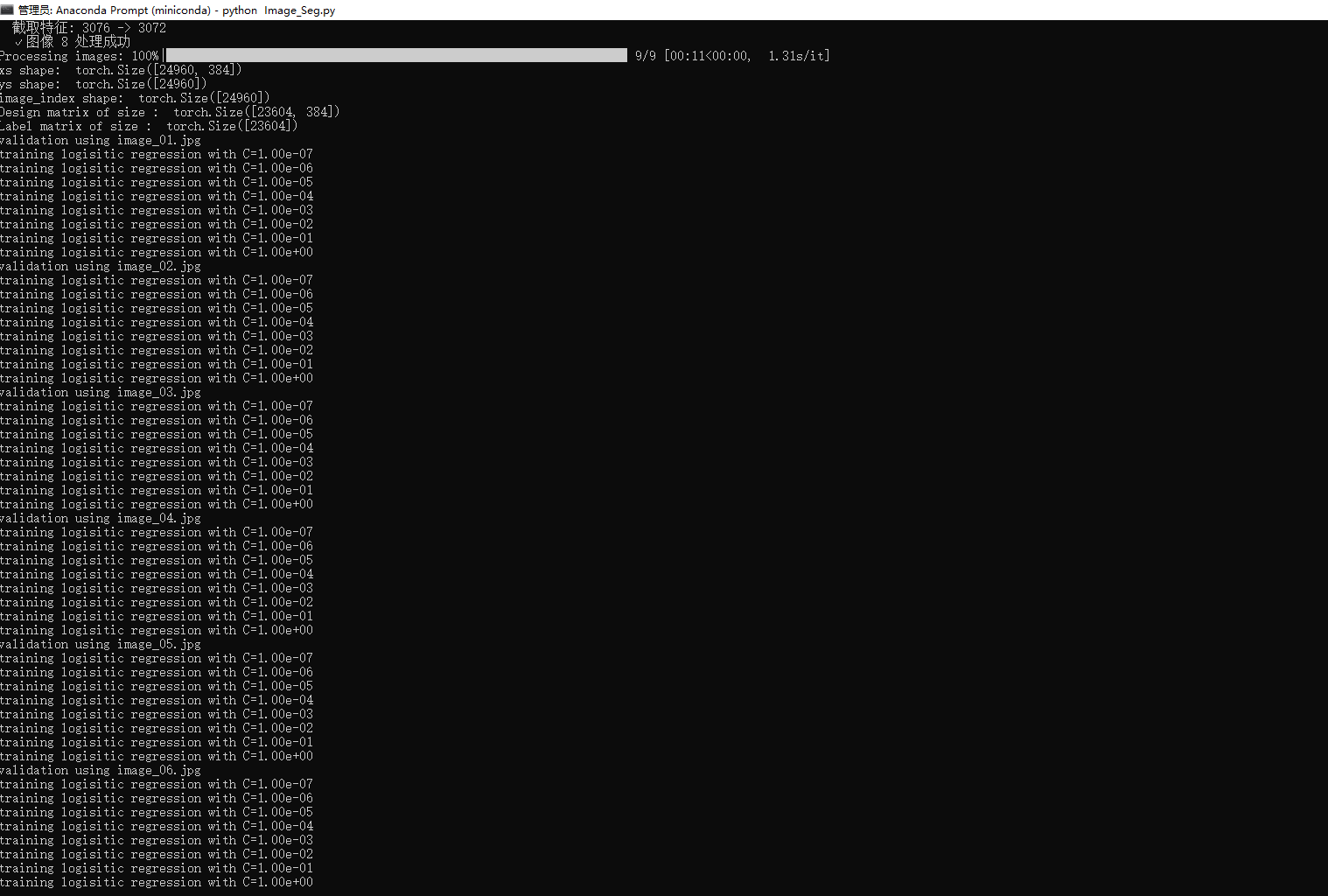
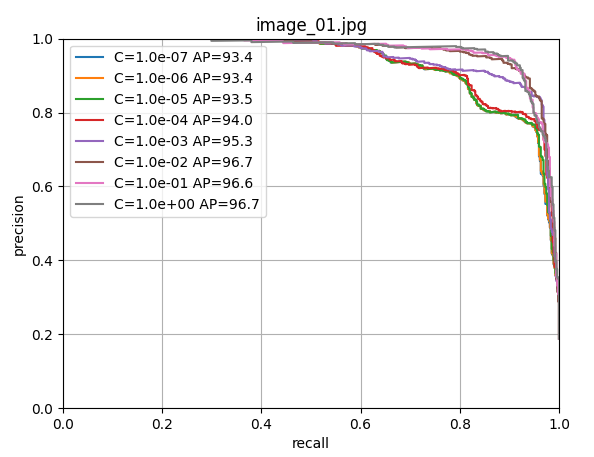
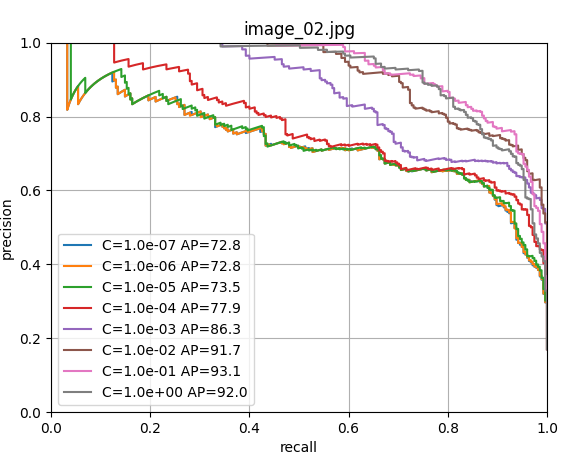
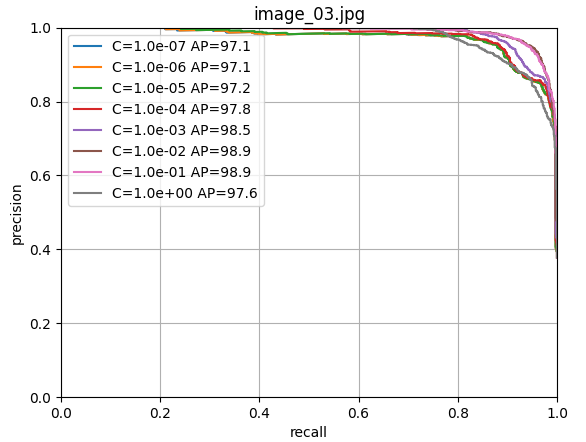
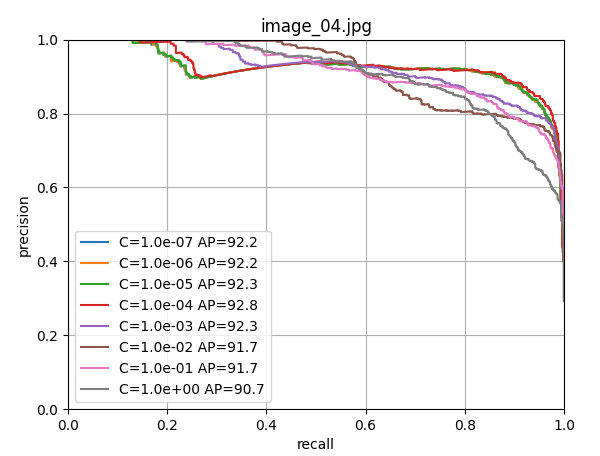
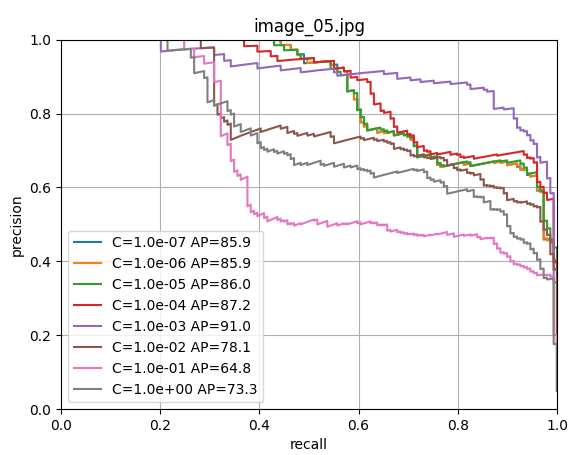
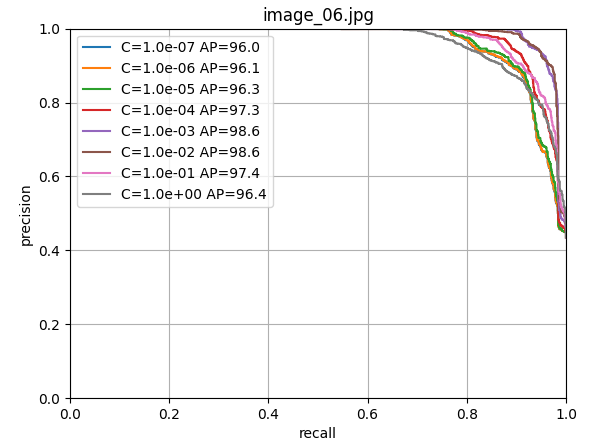
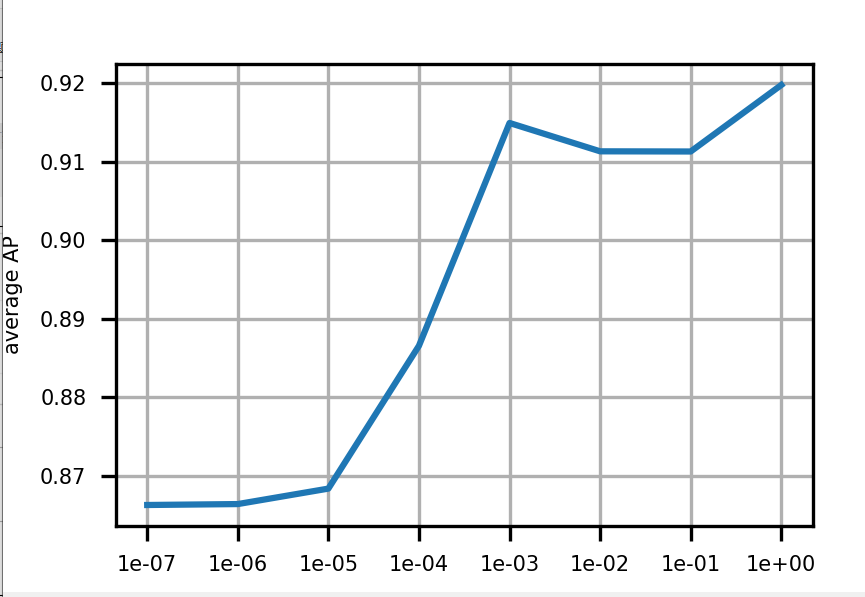
9. 最终模型训练和保存
由上图可以看出c=1.0时,模型性能最佳,这里直接取c=1.0,进行LogisticRegression回归器的模型训练;
# 使用最佳参数训练最终模型
clf = LogisticRegression(random_state=0, C=1.0, max_iter=100000, verbose=2).fit(xs.numpy(), (ys > 0).long().numpy())
# 保存模型
with open(model_path, "wb") as f:
pickle.dump(clf, f)使用所有数据训练最终的前景分割分类器,并将其保存到磁盘。
10. 测试和可视化
# 对测试图像进行预测
with torch.inference_mode():
outputs = model(test_image_normalized.unsqueeze(0))
patch_features = outputs.last_hidden_state[:, 1:, :]
x = patch_features.squeeze().detach().cpu()
# 使用训练好的分类器预测前景概率
fg_score = clf.predict_proba(x)[:, 1].reshape(h_patches, w_patches)
fg_score_mf = torch.from_numpy(signal.medfilt2d(fg_score, kernel_size=3))
# 可视化结果
plt.figure(figsize=(9, 3), dpi=300)
plt.subplot(1, 3, 1)
plt.imshow(test_image_resized.permute(1, 2, 0))
plt.title('input image')
plt.subplot(1, 3, 2)
plt.imshow(fg_score)
plt.title('foreground score')
plt.subplot(1, 3, 3)
plt.imshow(fg_score_mf)
plt.title('+ median filter')对新图像进行前景分割预测,并可视化结果,包括原始图像、前景得分图和经过中值滤波平滑的结果。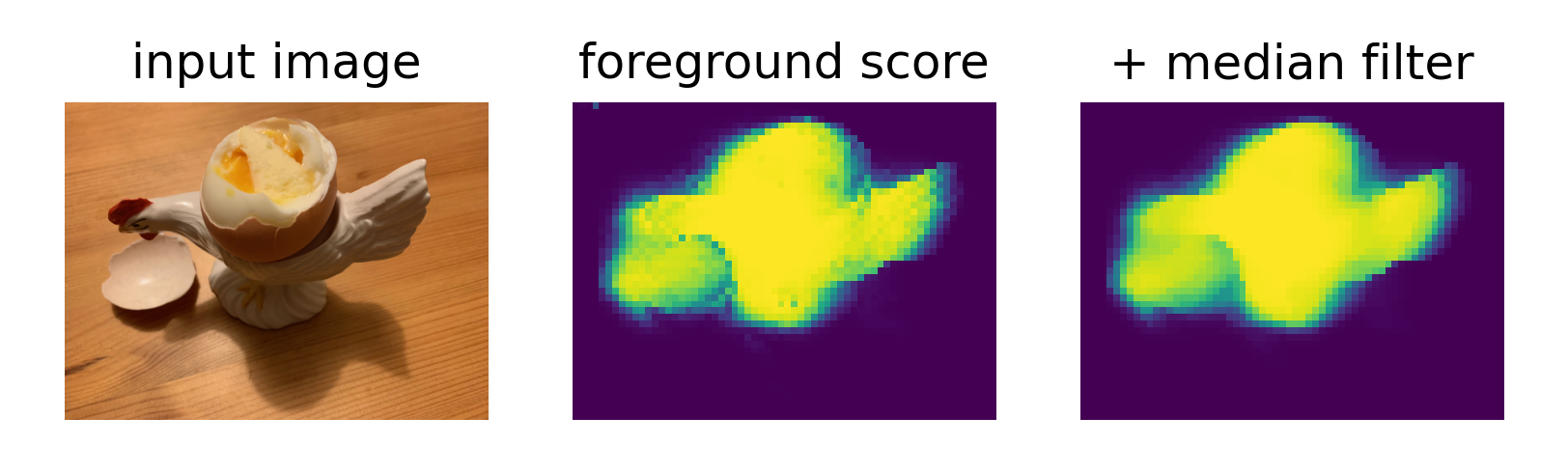
总结
这种方法的优势在于利用了DINOv3强大的自监督学习能力,无需大量标注数据就能获得高质量的视觉特征表示。如果感觉不错的小伙伴,感谢你们的点赞关注。后续还会出一些其他的使用案例~

好了,这篇文章就介绍到这里,喜欢的小伙伴感谢给点个赞和关注,更多精彩内容持续更新~~
关于本篇文章大家有任何建议或意见,欢迎在评论区留言交流!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号