BUAA_2022_OO_Unit1总结
2022_OO第一单元总结
一、基于度量的程序结构分析
各项指标解释
Method
- Cogc : 认知复杂度,其目的是显式地度量可理解性,随着每个控制结构的使用而增加,而且嵌套控制结构越多,认知复杂度就越高。
- ev(G) : 本质复杂度,是一种图论度量方法控制流的结构不良程度的方法。
- iv(G) : 设计复杂度,与方法控制流与对其他方法的调用之间如何相互关联有关。
- v(G) : 圈复杂度,是对通过每个方法的不同执行路径数量的度量,也可以被认为是完全执行方法控制流所需的最小测试数。
Class
- OCavg : 每个类中所有非抽象方法的平均圈复杂度(继承的方法不计算在内)。
- OCmax : 每个类中非抽象方法的最大圈复杂度(继承的方法不计算在内)。
- WMC : 每个类中方法的总圈复杂度.
第一次作业
1. 代码度量分析
| Method | CogC | ev(G) | iv(G) | v(G) |
|---|---|---|---|---|
| Lexer.Lexer(String) | 0 | 1 | 1 | 1 |
| Lexer.getDigit() | 2 | 1 | 3 | 3 |
| Lexer.next() | 7 | 2 | 7 | 9 |
| Lexer.peek() | 0 | 1 | 1 | 1 |
| MainClass.main(String[]) | 0 | 1 | 1 | 1 |
| Parser.Parser(Lexer) | 0 | 1 | 1 | 1 |
| Parser.parseExpr() | 10 | 1 | 9 | 9 |
| Parser.parseFactor(Term) | 17 | 1 | 9 | 9 |
| Parser.parseTerm() | 3 | 1 | 4 | 4 |
| expr.Expr.Expr() | 0 | 1 | 1 | 1 |
| expr.Expr.addTerm(Oper) | 0 | 1 | 1 | 1 |
| expr.Expr.culculate() | 1 | 1 | 2 | 2 |
| expr.Expr.getMap() | 0 | 1 | 1 | 1 |
| expr.Expr.getpos() | 0 | 1 | 1 | 1 |
| expr.Expr.outPut() | 11 | 5 | 7 | 7 |
| expr.Expr.plus(Oper, Oper) | 15 | 1 | 7 | 7 |
| expr.Expr.printEach(BigInteger, HashMap<BigInteger, BigInteger>) | 10 | 1 | 7 | 7 |
| expr.Expr.setMap(HashMap<BigInteger, BigInteger>) | 0 | 1 | 1 | 1 |
| expr.Expr.switchpos() | 0 | 1 | 1 | 1 |
| expr.Factor.Factor(String, String) | 0 | 1 | 1 | 1 |
| expr.Factor.culculate() | 0 | 1 | 1 | 1 |
| expr.Factor.getMap() | 0 | 1 | 1 | 1 |
| expr.Factor.getpos() | 0 | 1 | 1 | 1 |
| expr.Factor.setMap(HashMap<BigInteger, BigInteger>) | 0 | 1 | 1 | 1 |
| expr.Factor.switchpos() | 0 | 1 | 1 | 1 |
| expr.Term.Term() | 0 | 1 | 1 | 1 |
| expr.Term.addFactor(Oper) | 0 | 1 | 1 | 1 |
| expr.Term.culculate() | 1 | 1 | 2 | 2 |
| expr.Term.getMap() | 0 | 1 | 1 | 1 |
| expr.Term.getpos() | 0 | 1 | 1 | 1 |
| expr.Term.mult(Oper, Oper) | 10 | 1 | 5 | 5 |
| expr.Term.setMap(HashMap<BigInteger, BigInteger>) | 0 | 1 | 1 | 1 |
| expr.Term.switchpos() | 0 | 1 | 1 | 1 |
| Class | OCavg | OCmax | WMC |
|---|---|---|---|
| Lexer | 2.5 | 6 | 10 |
| MainClass | 1 | 1 | 1 |
| Parser | 5.5 | 9 | 22 |
| expr.Expr | 2.8 | 7 | 28 |
| expr.Factor | 1 | 1 | 6 |
| expr.Term | 1.62 | 5 | 13 |
第一次作业未涉及三角函数以及表达式嵌套等,架构较为简单,只实现最基本的功能,因此我的架构较为简单,每个类的功能也比较清楚,大部分代码的耦合度都比较低。但由于没有把输出单独放到一个类中,导致Expr类功能复杂,耦合较高,显得较为臃肿。
本设计与其他同学相比,复杂度还是比较高,体现出了对面向对象编程思想的不熟练。另外类的使用不清晰,使代码显得十分不规范,同时也给自己的debug造成了许多麻烦。
2. UML类图
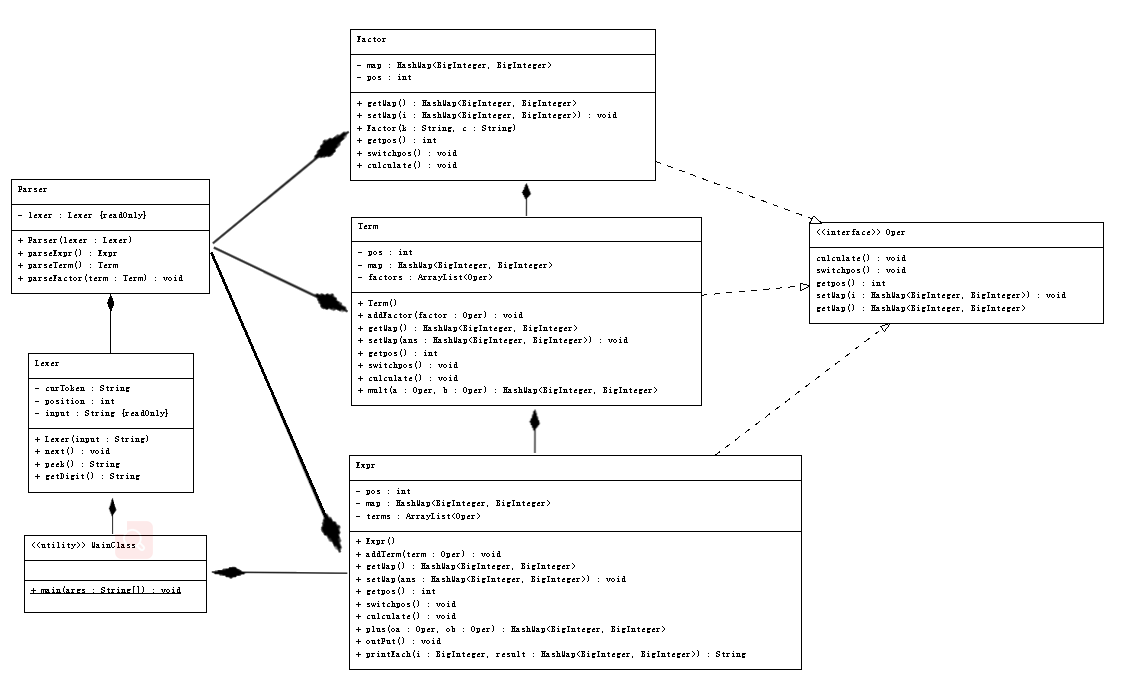
第一次作业借鉴了第一次上机时给出的基本结构。读入表达式后,由Lexer进行词法分析,从头读取有意义的字符串,如"122","x","**"等结构,并输入到Parser中进行句法分析。表达式一共分为三层,Expr为表达式,Term为项,Factor为最基本的因子,表达式用"+"、"-"号分成一个个项,项用"*"分成一个个因子,递归下降,层次分明。因为三个类都有共同的计算方法,而且考虑到将来可能会有互相嵌套的情况,于是定义了一个Oper接口,既方便运算,也能让三个类的形式较为统一。
读入并存储完成后,将每个因子都用Hashmap形式表示,key值存放指数,value值存放系数,依次使用乘法、加法计算出每个因子、项以及表达式的值,并进行合并同类项,最终合并为表示总表达式化简结果Hashmap,再通过OutPut函数输出即可完成去括号。
3.优缺点分析
优点:个人认为本次作业中类的设计还是比较清晰的,使用了递归下降的策略,也让代码更加易读,降低了表达式处理的复杂度。
缺点:主要缺点在于类的处理,刚开始构建时出现了一些没有必要的类,后来又把两个不相干的类合并到了一起,显得臃肿难看;另外,用递归处理字符串还是比较有难度,代码稍有缺点,就会在递归过程中被放大n倍,对代码优化的要求也比较高。
第二次作业
1. 代码度量分析
| Method | CogC | ev(G) | iv(G) | v(G) |
|---|---|---|---|---|
| Lexer.Lexer(String) | 0 | 1 | 1 | 1 |
| Lexer.getDigit() | 2 | 1 | 3 | 3 |
| Lexer.next() | 15 | 4 | 20 | 22 |
| Lexer.peek() | 0 | 1 | 1 | 1 |
| MainClass.main(String[]) | 1 | 1 | 2 | 2 |
| Parser.Parser(Lexer) | 0 | 1 | 1 | 1 |
| Parser.parseExpr() | 10 | 1 | 9 | 9 |
| Parser.parseFactor(Term) | 31 | 1 | 20 | 20 |
| Parser.parseTerm() | 3 | 1 | 4 | 4 |
| Parser.parserFunc() | 4 | 1 | 5 | 5 |
| Parser.parserSum() | 7 | 1 | 8 | 8 |
| expr.Expr.Expr() | 0 | 1 | 1 | 1 |
| expr.Expr.addTerm(Oper) | 0 | 1 | 1 | 1 |
| expr.Expr.apply(HashMap<String, Oper>) | 1 | 1 | 2 | 2 |
| expr.Expr.clone() | 2 | 1 | 3 | 3 |
| expr.Expr.culculate() | 1 | 1 | 2 | 2 |
| expr.Expr.getMap() | 0 | 1 | 1 | 1 |
| expr.Expr.getType() | 0 | 1 | 1 | 1 |
| expr.Expr.getpos() | 0 | 1 | 1 | 1 |
| expr.Expr.outPut(int) | 45 | 5 | 19 | 19 |
| expr.Expr.plus(Oper, Oper) | 15 | 1 | 7 | 7 |
| expr.Expr.printEach(Mark, int) | 13 | 4 | 8 | 8 |
| expr.Expr.switchpos() | 1 | 1 | 2 | 2 |
| expr.Factor.Factor(String, String, String) | 0 | 1 | 1 | 1 |
| expr.Factor.apply(HashMap<String, Oper>) | 0 | 1 | 1 | 1 |
| expr.Factor.clone() | 1 | 1 | 2 | 2 |
| expr.Factor.culculate() | 0 | 1 | 1 | 1 |
| expr.Factor.getMap() | 0 | 1 | 1 | 1 |
| expr.Factor.getType() | 0 | 1 | 1 | 1 |
| expr.Factor.getpos() | 0 | 1 | 1 | 1 |
| expr.Factor.setMap(HashMap<Mark, BigInteger>) | 0 | 1 | 1 | 1 |
| expr.Factor.switchpos() | 0 | 1 | 1 | 1 |
| expr.Func.addFormalPara(String) | 0 | 1 | 1 | 1 |
| expr.Func.apply(ArrayList |
1 | 1 | 2 | 2 |
| expr.Func.paraNumber() | 0 | 1 | 1 | 1 |
| expr.Func.setExpr(Expr) | 0 | 1 | 1 | 1 |
| expr.Funcs.addFuncs(String, Func) | 0 | 1 | 1 | 1 |
| expr.Funcs.getFuncs(String) | 0 | 1 | 1 | 1 |
| expr.Mark.addMark(String, BigInteger) | 2 | 1 | 2 | 2 |
| expr.Mark.culhashmark() | 1 | 1 | 2 | 2 |
| expr.Mark.equals(Object) | 3 | 3 | 2 | 3 |
| expr.Mark.getMark() | 0 | 1 | 1 | 1 |
| expr.Mark.hashCode() | 0 | 1 | 1 | 1 |
| expr.Mark.setMark(HashMap<String, BigInteger>) | 0 | 1 | 1 | 1 |
| expr.SinCos.SinCos(Expr, boolean) | 0 | 1 | 1 | 1 |
| expr.SinCos.apply(HashMap<String, Oper>) | 0 | 1 | 1 | 1 |
| expr.SinCos.clone() | 1 | 1 | 2 | 2 |
| expr.SinCos.culculate() | 15 | 1 | 6 | 7 |
| expr.SinCos.getMap() | 0 | 1 | 1 | 1 |
| expr.SinCos.getType() | 0 | 1 | 1 | 1 |
| expr.SinCos.getpos() | 0 | 1 | 1 | 1 |
| expr.SinCos.switchpos() | 0 | 1 | 1 | 1 |
| expr.Term.Term() | 0 | 1 | 1 | 1 |
| expr.Term.addFactor(Oper) | 0 | 1 | 1 | 1 |
| expr.Term.apply(HashMap<String, Oper>) | 5 | 1 | 5 | 5 |
| expr.Term.clone() | 2 | 1 | 3 | 3 |
| expr.Term.culculate() | 1 | 1 | 2 | 2 |
| expr.Term.getMap() | 0 | 1 | 1 | 1 |
| expr.Term.getType() | 0 | 1 | 1 | 1 |
| expr.Term.getpos() | 0 | 1 | 1 | 1 |
| expr.Term.mult(Oper, Oper) | 21 | 1 | 8 | 8 |
| expr.Term.switchpos() | 0 | 1 | 1 | 1 |
| Class | OCavg | OCmax | WMC |
|---|---|---|---|
| Lexer | 3.5 | 10 | 14 |
| MainClass | 2 | 2 | 2 |
| Parser | 6.33 | 14 | 38 |
| expr.Expr | 3.83 | 19 | 46 |
| expr.Factor | 1.11 | 2 | 10 |
| expr.Func | 1.25 | 2 | 5 |
| expr.Funcs | 1 | 1 | 2 |
| expr.Mark | 1.67 | 3 | 10 |
| expr.SinCos | 1.88 | 7 | 15 |
| expr.Term | 2.4 | 8 | 24 |
第二次作业内容扩展较多,有三角函数、自定义函数以及sum函数等等,原有的架构已经无法计算和化简含有sin、cos和函数的表达式了,所以在第一次基础上做了重构,改变了hashmap的存储形式,使程序的功能更加完善。
因为计算部分重构较困难,类的处理也不是很成熟,输入和输出部分还是在原来的基础上修修补补,导致第二次还是有不少臃肿的函数,虽然勉强过了checkstyle测试,但还是有不少的地方飘红。
2.UML类图
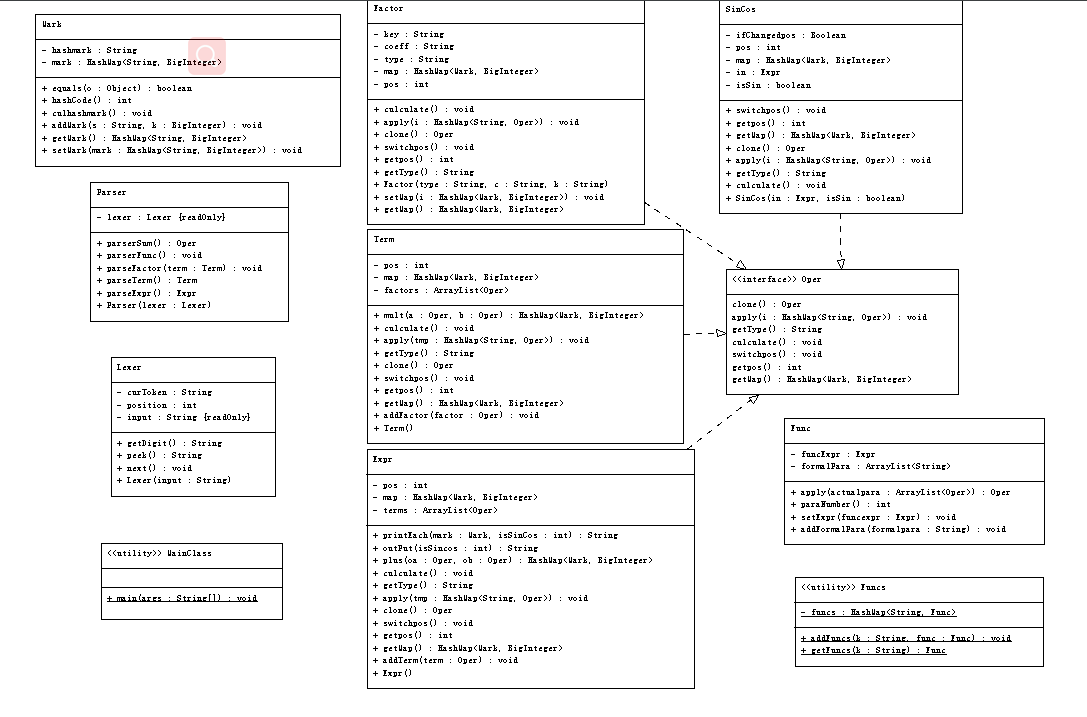
本次作业中,我依旧按照表达式展开的规则进行建模,分为表达式、项和因子三级,仍旧使用了哈希表计算和合并同类项。哈希表中value值依旧存储系数,但key值使用了新建的mark类,这个类用一个hashmap存储了项的类型以及指数。Mark类中定义了一个哈希表hashmap<String, BigInteger>,key值存储了项的类型,value值存储了项的指数,这样就能完整地表示一个因子的全部特征。
对于自定义函数,难点主要在表达式克隆和参数替换这两方面。对于克隆,因为存储函数表达式时采用了递归下降,所以我采取的方法是递归克隆:如果类型是表达式或项,那么就遍历克隆他们的子项;如果类型是因子,就返回一个新生成的完全一样的因子,这样就能保证原表达式不变。对于参数替换,仍然采用递归的方式,将形参和实参一一对应进行替换,再将替换后的表达式代入计算,就完成了函数的计算。
3.优缺点分析
优点:在第一次作业的基础上改良了因子的哈希表表达方式,方便比较、计算和合并同类项,并为下次作业留下了大量的空间,每个类的设计也都较为清楚。
缺点:这次作业还是有不少偷懒的地方,比如Lexer类中各种判断直接堆在一起,导致长度爆炸,可读性也很烂;Parser类和OutPut方法也是修修补补,加了大量的特判情况,复杂度剧增,我认为这些仍然有优化的余地,比如用一些子函数实现重复较多的功能等等。
第三次作业
1.代码度量分析
| Method | CogC | ev(G) | iv(G) | v(G) |
|---|---|---|---|---|
| Lexer.Lexer(String) | 0 | 1 | 1 | 1 |
| Lexer.getDigit() | 2 | 1 | 3 | 3 |
| Lexer.next() | 15 | 4 | 20 | 22 |
| Lexer.peek() | 0 | 1 | 1 | 1 |
| MainClass.main(String[]) | 1 | 1 | 2 | 2 |
| Parser.Parser(Lexer) | 0 | 1 | 1 | 1 |
| Parser.ifplus(String) | 2 | 2 | 1 | 2 |
| Parser.parseExpr() | 7 | 1 | 6 | 6 |
| Parser.parseFactor(Term) | 34 | 1 | 18 | 18 |
| Parser.parseTerm() | 3 | 1 | 4 | 4 |
| Parser.parserFunc() | 10 | 5 | 9 | 10 |
| Parser.parserSinCos() | 2 | 1 | 3 | 3 |
| Parser.parserSum() | 15 | 1 | 13 | 13 |
| expr.Expr.Expr() | 0 | 1 | 1 | 1 |
| expr.Expr.addTerm(Oper) | 0 | 1 | 1 | 1 |
| expr.Expr.apply(HashMap<String, Oper>) | 4 | 1 | 3 | 3 |
| expr.Expr.clone() | 6 | 2 | 4 | 4 |
| expr.Expr.culculate() | 4 | 1 | 3 | 3 |
| expr.Expr.getMap() | 0 | 1 | 1 | 1 |
| expr.Expr.getType() | 0 | 1 | 1 | 1 |
| expr.Expr.getpos() | 0 | 1 | 1 | 1 |
| expr.Expr.outPut(int) | 43 | 6 | 18 | 19 |
| expr.Expr.plus(Oper, Oper) | 16 | 1 | 7 | 7 |
| expr.Expr.printEach(Mark, int) | 13 | 4 | 8 | 8 |
| expr.Expr.switchpos() | 4 | 2 | 3 | 3 |
| expr.Factor.Factor(String, String, String) | 0 | 1 | 1 | 1 |
| expr.Factor.apply(HashMap<String, Oper>) | 0 | 1 | 1 | 1 |
| expr.Factor.clone() | 1 | 1 | 2 | 2 |
| expr.Factor.culculate() | 0 | 1 | 1 | 1 |
| expr.Factor.getMap() | 0 | 1 | 1 | 1 |
| expr.Factor.getType() | 0 | 1 | 1 | 1 |
| expr.Factor.getpos() | 0 | 1 | 1 | 1 |
| expr.Factor.setMap(HashMap<Mark, BigInteger>) | 0 | 1 | 1 | 1 |
| expr.Factor.switchpos() | 0 | 1 | 1 | 1 |
| expr.Func.addFormalPara(String) | 0 | 1 | 1 | 1 |
| expr.Func.apply(HashMap<String, Oper>) | 0 | 1 | 1 | 1 |
| expr.Func.applyEach(ArrayList |
1 | 1 | 2 | 2 |
| expr.Func.applyFunc(ArrayList |
0 | 1 | 1 | 1 |
| expr.Func.clone() | 0 | 1 | 1 | 1 |
| expr.Func.culculate() | 0 | 1 | 1 | 1 |
| expr.Func.getMap() | 0 | 1 | 1 | 1 |
| expr.Func.getName(String) | 0 | 1 | 1 | 1 |
| expr.Func.getType() | 0 | 1 | 1 | 1 |
| expr.Func.getpos() | 0 | 1 | 1 | 1 |
| expr.Func.paraNumber() | 0 | 1 | 1 | 1 |
| expr.Func.setExpr(Expr) | 0 | 1 | 1 | 1 |
| expr.Func.switchpos() | 0 | 1 | 1 | 1 |
| expr.Funcs.addFuncs(String, Func) | 2 | 1 | 2 | 2 |
| expr.Funcs.getFuncs(String) | 2 | 2 | 2 | 2 |
| expr.Mark.addMark(String, BigInteger) | 2 | 1 | 2 | 2 |
| expr.Mark.apply(HashMap<String, Oper>) | 0 | 1 | 1 | 1 |
| expr.Mark.clone() | 0 | 1 | 1 | 1 |
| expr.Mark.culHashmark() | 4 | 1 | 3 | 3 |
| expr.Mark.culculate() | 0 | 1 | 1 | 1 |
| expr.Mark.equals(Object) | 3 | 3 | 2 | 3 |
| expr.Mark.getMap() | 0 | 1 | 1 | 1 |
| expr.Mark.getMark() | 0 | 1 | 1 | 1 |
| expr.Mark.getType() | 0 | 1 | 1 | 1 |
| expr.Mark.getpos() | 0 | 1 | 1 | 1 |
| expr.Mark.hashCode() | 0 | 1 | 1 | 1 |
| expr.Mark.setMark(HashMap<String, BigInteger>) | 0 | 1 | 1 | 1 |
| expr.Mark.switchpos() | 0 | 1 | 1 | 1 |
| expr.Num.getMap() | 0 | 1 | 1 | 1 |
| expr.Num.getpos() | 0 | 1 | 1 | 1 |
| expr.Num.switchpos() | 0 | 1 | 1 | 1 |
| expr.Num.toString() | 0 | 1 | 1 | 1 |
| expr.SinCos.SinCos(Expr, boolean) | 0 | 1 | 1 | 1 |
| expr.SinCos.apply(HashMap<String, Oper>) | 0 | 1 | 1 | 1 |
| expr.SinCos.clone() | 1 | 1 | 2 | 2 |
| expr.SinCos.culculate() | 43 | 8 | 12 | 15 |
| expr.SinCos.getMap() | 0 | 1 | 1 | 1 |
| expr.SinCos.getType() | 0 | 1 | 1 | 1 |
| expr.SinCos.getpos() | 0 | 1 | 1 | 1 |
| expr.SinCos.switchpos() | 0 | 1 | 1 | 1 |
| expr.Term.Term() | 0 | 1 | 1 | 1 |
| expr.Term.addFactor(Oper) | 0 | 1 | 1 | 1 |
| expr.Term.apply(HashMap<String, Oper>) | 7 | 1 | 4 | 4 |
| expr.Term.clone() | 6 | 2 | 4 | 4 |
| expr.Term.culculate() | 4 | 1 | 3 | 3 |
| expr.Term.getMap() | 0 | 1 | 1 | 1 |
| expr.Term.getType() | 0 | 1 | 1 | 1 |
| expr.Term.getpos() | 0 | 1 | 1 | 1 |
| expr.Term.mult(Oper, Oper) | 18 | 1 | 7 | 7 |
| expr.Term.switchpos() | 0 | 1 | 1 | 1 |
| Class | OCavg | OCmax | WMC |
|---|---|---|---|
| Lexer | 3.5 | 10 | 14 |
| MainClass | 2 | 2 | 2 |
| Parser | 6.88 | 16 | 55 |
| expr.Expr | 4.08 | 18 | 49 |
| expr.Factor | 1.11 | 2 | 10 |
| expr.Func | 1.08 | 2 | 14 |
| expr.Funcs | 2 | 2 | 4 |
| expr.Mark | 1.38 | 3 | 18 |
| expr.SinCos | 2.88 | 15 | 23 |
| expr.Term | 2.4 | 7 | 24 |
第三次作业新增了三角函数以及自定义函数的括号嵌套,由于第二次架构比较完善,第三次作业就是第二次的改良版本,对parser和OutPut的一些功能进行了修补。大部分类聚合度都比较高,但从度量中可以看出,有几个类已经变得十分复杂,与其他类的耦合变得很高。
2.UML类图
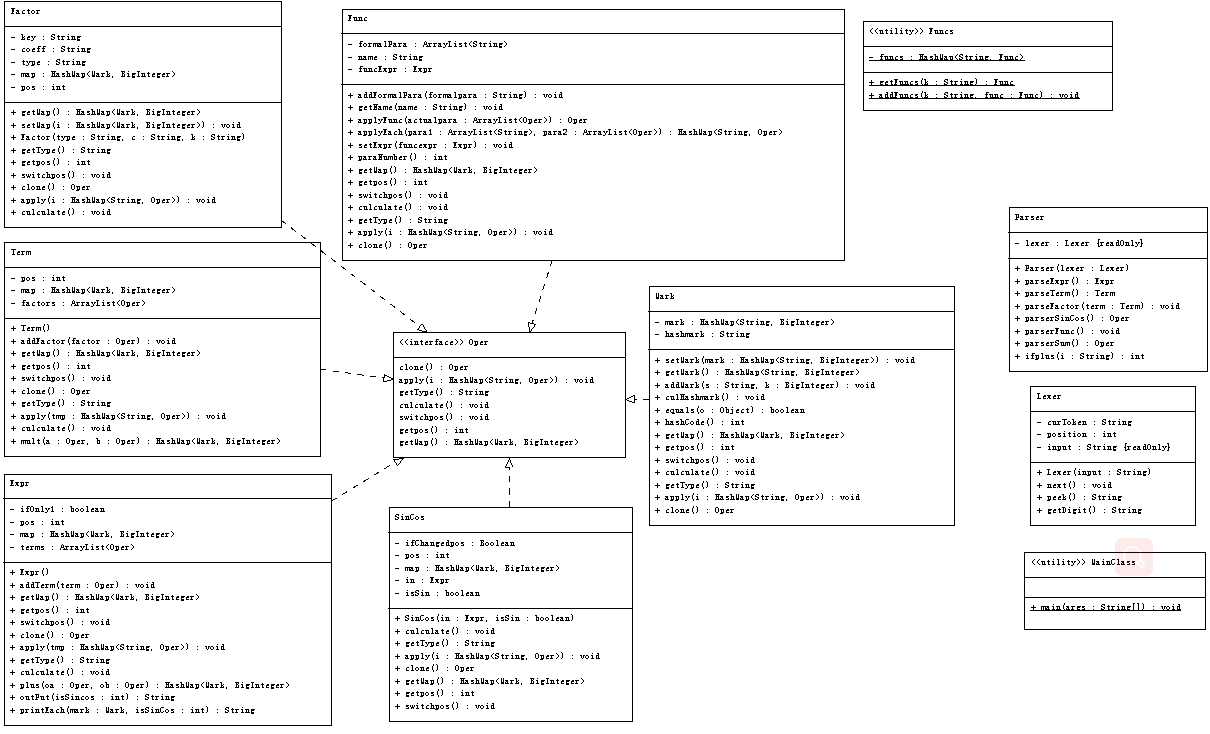
由于在第二次作业中,我把所有的括号内项全部当作表达式进行操作,所以自然支持各种数据类型的嵌套,第三次只是增加了一些优化,如三角函数括号内的表达式优化,符号优化等等。
3.优缺点分析
优点:架构比较完善,理论上可以支持任意层数的嵌套,递归的结构也使每一部分维护比较方便,debug时在相应函数段设置几个断点就能定位出错误。
缺点:互测前进行的测试发现,运算时间会随着嵌套层数指数增加,实际上四五层左右的嵌套就可能超过10秒,性能优化方面还是有缺陷;另外还是老生常谈的类使用问题,还是有为了省事,把不相干的函数堆到同一个类中的操作。
二、bug分析
第一次作业:
强测没有出现bug,优化也拿到了满分;互测时被hack了一次,是关于去空格的bug。由于我一开始的设计是遇到空格时直接跳过,并读取下一个字符,没有判断此时读取的位置是否已经大于等于最后一个字符。此时如果表达式最后有空格,读取就会溢出,造成报错的bug。
第二次作业:
强测错了两个点,互测时同一个bug被hack了一轮,一共查出了三个bug:
- 第一个是误把sin和cos括号内的x**2化简成了x*x,导致输出不符合规范。其实就是指导书看得不仔细,化简一刀切,结果出了bug。
- 第二个是sum函数中起始数和终止数的符号问题,起始数输入完成后忘记把符号flag重置为0,导致终止数和起始数符号始终相同,导致了一些莫名其妙的情况。
- 第三个是sin函数符号的化简问题,由于符号处理不完善,乘方时没有改变所有项的符号,导致了sin(-x)**2化成-sin(x)**2的情况。
第三次作业:
强测没有出错,但由于优化不完善丢了一些性能分;互测时没有被hack,反倒找到了同房间不少的bug,主要有以下几类:
- 大数bug,相信大部分互测的同学都尝试过爆int(逃),也确实有一些同学没有考虑大数的计算,使用了int或long存储数据,造成了bug。
- 零次幂bug,这部分bug第一次作业应该就修过了,但是遇到sin和cos函数,自定义和sum函数参数替换,以及层层嵌套关系后,有时零次幂又会输出奇怪的结果。
- sum函数bug,sum函数相对于自定义函数较为简单,可能这方面同学们考虑的也不够完善,比如起始数和终止数的大小和符号问题,有的同学输入负号就会报错,有的同学起始数大于终止数仍会输出;还有就是sum函数中i的替换问题,不少同学没有考虑i的乘法的情况,导致报错或输出错误。
三、Hack策略分析
我一般只是手动输入一些数据,比如简单的0,1,零次幂等等,还有一些边界数据,个人认为只要对自己的程序做了充分测试,找到薄弱点,比如i**0,sum(i,2,-4,x)等等,再进行测试即可,效率虽然不高,但是有时候确实会有一些收获(当然大佬可以手打评测机)
四、收获总结
在第一单元的作业中,我初步认识到了面向对象编程的基本思想和方法,认识到了一个良好的架构对程序迭代开发的重要性,代码风格检查也让我改正了许多从未意识到的坏习惯。下面是我在第一单元的主要收获:
- 一定要仔细阅读指导书,理解透彻输入和输出形式,以及程序设计的目的,包括一些可行的方法、可能会踩的坑,指导书中也会有提示。
- 写程序之前要先把整体架构做好,先想清楚各个问题怎么解决,把各个类、函数的关系搞清楚,切忌像我一开始一样,漫无目的,写一步算一步,结果做了很多的无用功。
- 牢记“高内聚,低耦合”的原则,要分类的时候果断去分,需要写在一起的函数也不要强行拆开,时刻考量复杂度
- 提交前一定要对自己的程序做充分的测试,如各种常见数据,以及边界数据等等,不至于在自己能测出的bug上浪费提交次数。
五、心得体会
首先要感谢我身边的同学(大佬)们,由于个人是降转,开学前几天才来到计算机学院,pre尽力只做了前两个,结果第一周就开幕雷击,在和他们讨论的过程中我才有了思路,能一步步把程序写下来也离不开他们的帮助和指导。
另外,我充分感觉到了面向对象这门课对个人代码能力的要求,有时候作业发下来了却完全没思路,只能和同学讨论,求教大佬,写一步看一步,无比痛苦,不得不说前两周真的是我进入北航以来最黑暗的两周,被无力感深深包裹,眼看着周围同学都写完了,而我还在摸索思路。好不容易走出第一单元,无论结果是好是坏,我也要吸取教训,笨鸟先行,先做好第二单元的预习,靠自己攻克以后的难关。
(PS:老师和助教真的特别好,在我困难的时候提供了非常多的帮助,所以有问题就赶快去问吧 :3)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号