python 编码
windows中国中一般使用GBK
其中ASCII码在存储是占一个字符,但只能支持英文
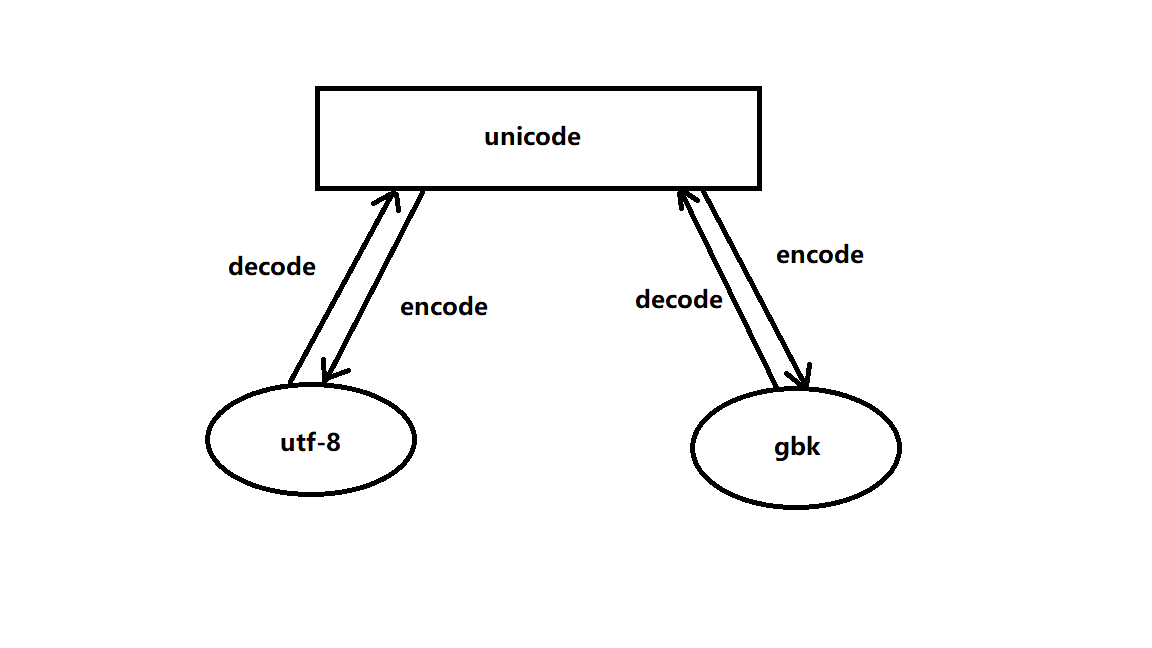
unicode支持中文和英文,但是在存储英文是需要占用2个字符,因此为了解决中文的问题,拓展出了utf-8(中文3个字符,英文1个字符)
python3默认使用的是unicode编码
python2默认使用ASCII编码
python2.7 和python3+ 有很大的区别:
其中python2编码encode后只改变字符串的编码,python3编码encode后不只是改变字符的编码,字符的格式也会改变,会变成byte格式
python2:
1 [yangdong@hd04 ~]$ cat test.py 2 #-*- coding:utf-8 -*- #生命当前文本使用utf-8的编码格式 3 import sys 4 print (sys.getdefaultencoding()) #获取当前环境默认编码格式 5 s = "你好" 6 s_to_unicode=s.decode("utf-8") 7 print(s_to_unicode,type(s_to_unicode)) 8 s_to_gbk = s.decode("utf-8").encode("gbk") 9 print(s_to_gbk) 10 [yangdong@hd04 ~]$ python test.py 11 ascii 12 (u'\u4f60\u597d', <type 'unicode'>) 13 ţº
python3:
1 #-*-coding:utf-8-*- 2 import sys 3 print(sys.getdefaultencoding()) 4 5 s = "你好" 6 s_to_gbk=s.encode("gbk") 7 print(s_to_gbk,type(s_to_gbk)) 8 9 10 11 运行结果: 12 utf-8 13 b'\xc4\xe3\xba\xc3' <class 'bytes'>
由上可以看出当python3更改字符的编码是,输出的结果不再是字符串了,而是bytes类型
任何格式的编码在相互变换时,只需要围绕这unicode进行转换就可以。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号