①.kubernetes pod
一.Pod是什么
二.Pod管理方式
三.Pod运行应用
四.Pod运行应用对应字段
五.Pod重启策略
六.Pod生命周期流程
七.Init Container
八. Pod Hook
九.Pod检测探针
十.startupProbe
十一.livenessProbe
十二.readinessProbe
十三.Pod资源限制
十四.资源限制单位换算
十五. CPU资源限制实践
十六. 内存资源限制
十七. Pod服务质量Qos
-
17.1 什么是QOS
-
17.2 QOS类别
-
17.3 创建Guaranteed的Pod
-
17.4 创建Burstable的pod
-
17.5 创建BestEffort的Pod
-
17.6 创建多容器Pod
十八. Downward API
-
18.1 什么是Downward API
-
18.2 可注入的元数据信息
-
18.3 环境变量方式注入元数据
-
18.4 存储卷方式注入元数据
-
18.5 为注册服务注入Pod名称
-
18.6 为Tomcat注入堆内存相知
==============================================================================================================================
一.Pod是什么
pod在k8s里能够运行的最小的逻辑端元 一个pod代表集群运行的一个进程!
1个pod里面可以运行单个或者多个容器 他们共享 Network(网络)、PID(进程)、IPC(进程间通讯)、HostName(主机名称)、Volume(卷)。
Pod中的容器共享IP HostName IPC 他们可以通过localhost 互相发现 他们之间可以通过IPC通讯
Pod中的容器也有访问共享volume的权限 这些volume也会被定义成Pod的一部分被挂载到pod的容器中应用成文件系统
可以把Pod理解成豌豆荚 容器为豆粒

一个pod里运行多个容器 又叫边车(SideCar)模式
边车模式可以很好的保证原有业务不变的情况,通便边车模式添加新的容器来匹配现在的环境,例如日志手机 IAAS平台环境收集
二.Pod管理方式
2.1自助式Pod
在kubernetes中,我们部署POD的时候,基本上都是使用控制器管理,如果不使用控制器,也可以直接定义一个Pod资源,那么就是Pod自己去控制自己,这样的Pod称为自主式Pod!
- 如果
Pod被删除,那就是真的被删除,不会重新运行新的Pod - 如果
Pod所在的节点需要维护,那么节点会先执行驱逐,如果是自主式Pod,驱逐后不会被重建。 - 如果
Pod期望部署多个副本,这个也能实现,但如果想持续维护副本数量,则需要认为参与,过于繁琐。
1.创建一个自主式Pod
cat nginx-pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: nginx-pod
spec:
containers:
- name: nginx-container
image: nginx:1.16
ports:
- containerPort: 80
2.测试删除Pod,验证是否能被彻底删除
kubectl delete pod nginx-pod
3.测试节点故障,当Pod所运行的节点故障,那么改Pod会被删除,不会重新运行起来
kubectl drain node01 --ignore-daemonsets --force #驱逐
kubectl uncordon node01
2.2 控制器Pod
kubernetes通过controller控制器来创建管理Pod实例。Controller可以创建和管理多个Pod,提供副本副本管理、滚动升级和集群级别的自愈呢能力。
Pod的标签能匹配Controller控制器的标签,当运行Pod的节点发生故障时,控制器会把Pod调度到其他节点,Pod被删除,控制器会根据清单上Pod的数量来运行,Controller控制器能控制pod的副本(水平扩展)、滚动升级、故障自愈。
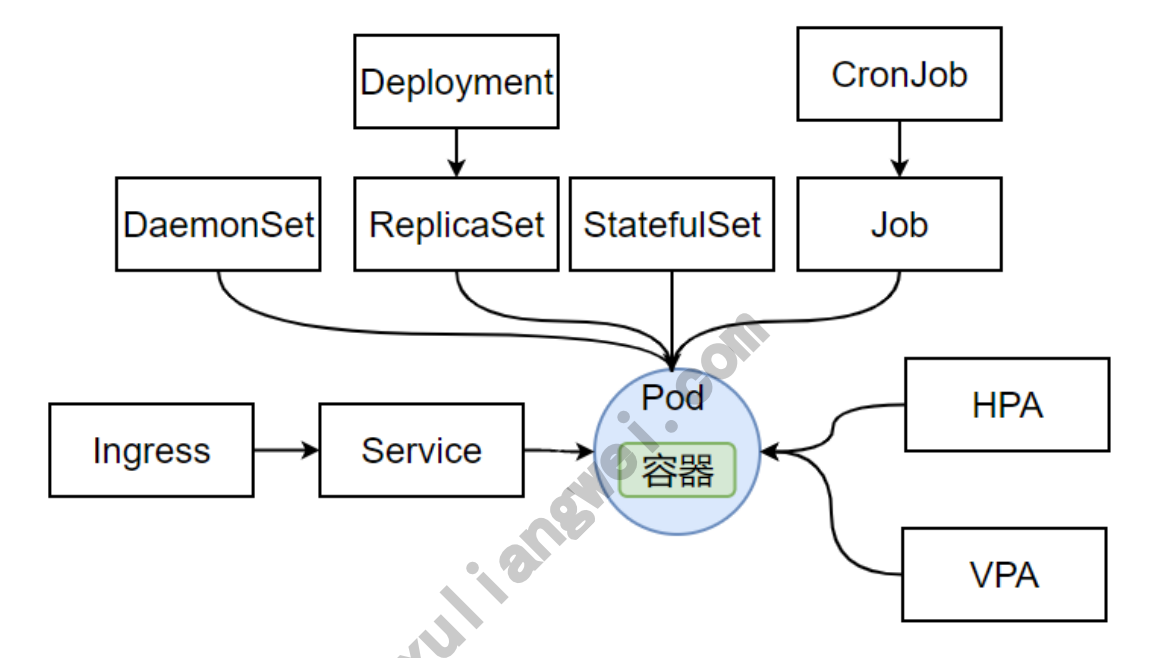
1.创建控制器管理的Pod
cat nginx-dp.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-dp
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx-container
image: nginx:1.16
2.测试删除Pod,会发现Pod被删除后,立即又启动一个相同的Pod实例。
#查看
[root@k8s-240 pod]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-dp-776b5f86cc-5t46z 1/1 Running 0 22s 10.244.232.223 flyfish81 <none> <none>
nginx-dp-776b5f86cc-kd8s7 1/1 Running 0 22s 10.244.157.160 flyfish83 <none> <none>
nginx-dp-776b5f86cc-ngnvw 1/1 Running 0 22s 10.244.149.155 flyfish82 <none> <none>
#删除Pod
[root@k8s-240 pod]# kubectl delete pod nginx-dp-776b5f86cc-5t46z
pod "nginx-dp-776b5f86cc-5t46z" deleted
#验证
[root@k8s-240 pod]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-dp-776b5f86cc-4xj5b 1/1 Running 0 7s 10.244.232.224 flyfish81 <none> <none>
nginx-dp-776b5f86cc-kd8s7 1/1 Running 0 37s 10.244.157.160 flyfish83 <none> <none>
nginx-dp-776b5f86cc-ngnvw 1/1 Running 0 37s 10.244.149.155 flyfish82 <none> <none>
三.Pod运行应用
3.1 创建应用
cat nginx-pod.yaml
apiVersion: apps/v1
kind: Pod
metadata:
name: nginx-pod
spec:
containers:
- name: nginx-container
image: nginx:1.16
3.2 Pod运行阶段
Pod创建后,起始为 Pending 阶段,如果其中至少又一个主要容器正常启动,则进入Running,之后的状态取决于Pod中是否有容器运行失败或被管理员停止运行,从而会进入 Succeeded 或者 Failed 阶段。

- Pending: Pod 已被 Kubernetes 系统接受,但有一个或者多个容器尚未创建亦未运行。此阶段包括等待 Pod 被调度的时间和通过网络下载镜像的时间。
- Running: Pod已经绑定至某个节点,同时Pod中所有的容器都已创建。至少有一个容器在运行,或处于启动、重启状态。
- Succeeded: Pod中的所有容器都已成功终止,并且不会再重启
- Failed: Pod中的所有容器都已终止,并且至少有一个容器是因为失败终止。也就是说,容器以非0状态退出或被系统终止
- Unknown: 因为某些原因无法取得 Pod 的状态。这种情况通常是因为与 Pod 所在主机通信失败。
1.可以通过 kubectl describe pod <pod名称> 查看podStatus 对象中的Status,查看当前Pod所处的阶段
[root@k8s-240 pod]# kubectl describe pod nginx-dp-776b5f86cc-4xj5b
Name: nginx-dp-776b5f86cc-4xj5b
Namespace: default
Priority: 0
Service Account: default
Node: flyfish81/192.168.1.240
Start Time: Wed, 24 May 2023 16:39:23 +0800
Status: Running
#如果某节点死掉或者与集群中其他节点失恋,`Kubernetes`会实施一种策略,将失去节点上运行的`Pod`的`phase`设置为`Failed`
2.在PodStatus对象中还包含了一组Conditions,它主要描述造成当前Status的具体原因。
[root@k8s-240 pod]# kubectl describe pod nginx-dp-776b5f86cc-4xj5b
Conditions:
Type Status
Initialized True #pod中所有的init容器都已成功完成;
Ready True #pod可以对外提供服务,并可以加入对应的负载均衡;
ContainersReady True #pod中的所有容器都处于就绪状态;
PodScheduled True #pod已经成功被调度到莫个节点上;
3.3 容器运行阶段
kubernetes会跟踪Pod中每个容器的状态,就像跟踪Pod阶段一样。Pod中运行的容器状态与Pod阶段是存在关联关系的,所以当Pod出现故障时,讲Pod的阶段状态和Pod中的容器状态结合起来查看,更容易定位具体问题。
一旦调度器讲Pod分配给莫格节点,kubelet就通过容器运行时开始为Pod创建容器。容器的状态有三种:Waiting(等待)、Running(运行中)和Terminated(已终止)。容器状态官方站点
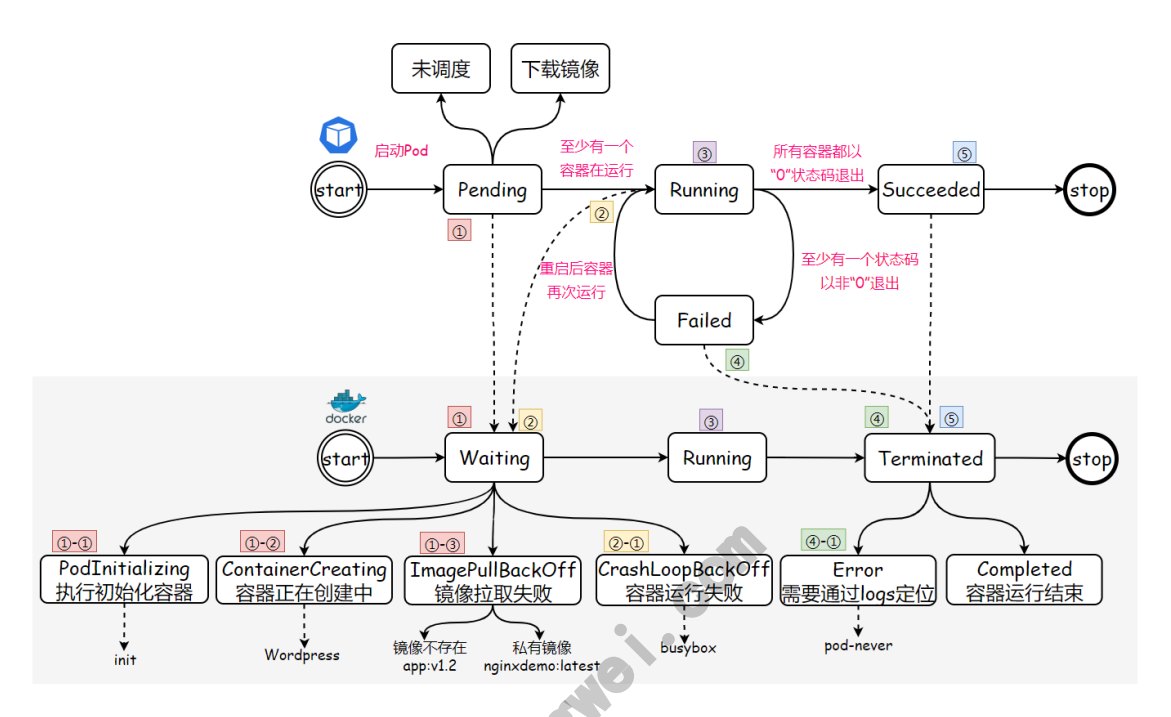
可以通过
kubectl describe pod <pod名称> 查看pod种的容器状态
[root@k8s-240 pod]# kubectl describe pod nginx-dp-776b5f86cc-4xj5b
Containers:
nginx-container:
Container ID: containerd://7410087425f295554a14e42f5cc2927c3f738005dc3381dc0e8536f24b6a4fa9
Image: nginx:1.16
Image ID: docker.io/library/nginx@sha256:d20aa6d1cae56fd17cd458f4807e0de462caf2336f0b70b5eeb69fcaaf30dd9c
Port: <none>
Host Port: <none>
State: Running #当前状态除了Running,还有Waiting Terminated
Started: Wed, 24 May 2023 16:39:26 +0800
Ready: True #容器是否已经就绪
Restart Count: 0 #容器重启的次数
Environment: <none>
四. Pod运行容器对应字段
4.1 容器镜像拉取策略
imagePullPolicy 容器的镜像拉取策略
- IfNotPresent: 本地有镜像则使用本地镜像,本地不存在则拉取镜像。
- Always: 每次都会尝试拉取新镜像
- Never: 永不拉取镜像!如果镜像已经存在本地,
kubelet会尝试启动容器,否则会启动失败。
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-dp
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx-container
image: nginx:1.16
imagePullPolicy: Always #指定镜像的拉取策略 每次pod启动都拉取最新版
没有设置imagePullPolicy字段,容器镜像的标签是latest,imagePullPolicy会自动设置为Always.如果你省略了imagePullPolicy字段,并且没有指定容器镜像的标签,imagePullPolicy会自动设置为Always.如果省略了imagePullPolicy字段,并且tag为非 latest, imagePullPolicy就会自动设置为IfNotPresent.
4.2 容器拉取私有仓库镜像
ImagePullSecrets拉取私有仓库中的镜像
1.创建一个Pod资源,拉取一个私有仓库镜像,在不添加ImagePullSectets时,验证是否正常拉取镜像
apiVersion: v1
kind: Pod
metadata:
name: pod-image-secret
spec:
containers:
- name: pod-image-secret
image: registry.cn-huhehaote.aliyuncs.com/oldxu3957/nginxdemo:latest
imagePullPolicy: Always
2.检查Pod状态,发信啊Pod状态为ErrImagePull,通过describe描述,发现需要docker login 后才能拉取镜像
[root@k8s-240 pod]# kubectl apply -f imagepull.yaml
pod/pod-image-secret created
[root@k8s-240 pod]# kubectl get pod
NAME READY STATUS RESTARTS AGE
pod-image-secret 0/1 ErrImagePull 0 2s
[root@k8s-240 pod]# kubectl describe pod pod-image-secret
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 2m6s default-scheduler Successfully assigned default/pod-image-secret to flyfish83
Normal Pulling 36s (x4 over 2m6s) kubelet Pulling image "registry.cn-huhehaote.aliyuncs.com/oldxu3957/nginxdemo:latest"
Warning Failed 35s (x4 over 2m5s) kubelet Failed to pull image "registry.cn-huhehaote.aliyuncs.com/oldxu3957/nginxdemo:latest": rpc error: code = Unknown desc = failed to pull and unpack image "registry.cn-huhehaote.aliyuncs.com/oldxu3957/nginxdemo:latest": failed to resolve reference "registry.cn-huhehaote.aliyuncs.com/oldxu3957/nginxdemo:latest": pull access denied, repository does not exist or may require authorization: server message: insufficient_scope: authorization failed
Warning Failed 35s (x4 over 2m5s) kubelet Error: ErrImagePull
Warning Failed 23s (x6 over 2m5s) kubelet Error: ImagePullBackOff
Normal BackOff 8s (x7 over 2m5s) kubelet Back-off pulling image "registry.cn-huhehaote.aliyuncs.com/oldxu3957/nginxdemo:latest"
3.创建一个名为aliyun的secret资源,然后配置对应仓库的用户名称及密码
[root@k8s-240 pod]# kubect create secret docker-registry aliyun --docker-username=552408925@qg.com -docker-password=123456 --docker-server registry.cn-huhehaote.aliyuncs .com
4.修改Pod资源清单,添加ImagePullSecrets传入对应的Secrets资源名称
apiVersion: v1
kind: Pod
metadata:
name: pod-image-secret
spec:
imagePullSecrets: #增加imagePullSecrets字段,传入对应资源的名称
- name: aliyun
containers:
- name: pod-image-secret
image: registry.cn-huhehaote.aliyuncs.com/oldxu3957/nginxdemo:latest
imagePullPolicy: Always
4.3 容器环境变量自定义
使用 env 控制容器环境变量
1.准备一个mysql镜像,然后通过env传入对应的登录密码,同事创建一个默认的k8s数据库
apiVersion: v1
kind: Pod
metadata:
name: pod-mysql-env
spec:
containers:
- name: mysql
image: mysql:5.7.37
env:
- name: MYSQL_ROOT_PASSWORD
value: "oldxu3957"
- name: MYSQL_DATABASE
value: "k8s"
2.查看mysql-pod容器详情
[root@k8s-240 pod]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
pod-mysql-env 1/1 Running 0 94s 10.244.149.156 flyfish82 <none> <none>
3.通过本机的 mysql client 尝试连接服务,验证密码是否传入成功数据库是否建立
[root@k8s-240 pod]# mysql -h 10.244.149.156 -uroot -p
MySQL [(none)]> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| k8s |
| mysql |
| performance_schema |
| sys |
+--------------------+
4.4 容器启动命令与参数
- command: 为容器指定启动命令,会覆盖容器启动的默认命令,不指定则默认容器的启动命令
- args: 为命令提供选项或参数
1.准备一个nginx镜像演示command与args的作用
container:
- images; nginx
name: nginx
command:
- /bin/bash #参数
- -C
- "echo $(msg);sleep 600:"
env:
- name : msg
value: "Hello 0ldxu"
4.5 容器自定义端口
ports 用于暴露pod对外访问的端口,如不指定,则无法通过 PodIP + PodPort 访问该应用
- containerPort: 填写Pod对外暴露的端口(0~65535)
- name: 为端口指定一个名称,当服务存在多个端口,可以通过名称区分
- protocol: 指定端口对应的协议,有tcp udp sctp 默认不写为tcp
示例文件
apiVersion: v1
kind: Pod
metadata:
name: redis-port
spec:
containers:
- name: redis-port
image: redis
ports:
- name: port
containerPort: 6379
protocol: TCP
五.Pod重启策略
Pod 的 spec 中包含一个 restartPolicy 字段,用来设置 Pod 中所有容器的重启策略,取值有ALways、0nFailure、Never。默认值是ATways。
ALways: 当容器出现异常退出时,kubelet 会尝试重启该容器已恢复正常状态; (默认策略)Never: 当容器退出时,kubelet 永远不会尝试重启该容器 (适合Job类一次性任务)0nFailure: 当容器异常退出 (且退出状态码非0时) ,kubelet会尝试重启容器 (适合Job类一次性任务)
注意: 通过 kubelet 重新启动的容器,后续如果还出现异常退出,则会以指数增加延迟 (10s,20s,40s...) 来进行容器的重新创建和启动,其最长延迟为 5 分钟。一旦容器执行了 10 分钟并且没有出现问题,kubelet 对该容器的重启计时器进行重置为初始状态
5.1 Always
1.编写Pod的yaml文件
apiVersion: v1
kind: Pod
metadata:
name: pod-always
spec:
restartPolicy: Always
containers:
- name: pod-always
image: nginx
ports:
- containerPort: 80
2.检查Pod的运行状态,可以看到Pod正常运行,RESTARTS(重启次数)字段为0
[root@k8s-240 pod]# kubectl get pod
NAME READY STATUS RESTARTS AGE
pod-always 1/1 Running 0 17m
3.正常停止容器应用,可以看到容器被重启了一次,然后Pod又恢复正常状态了。
[root@k8s-240 pod]# kubectl exec -it pod-always -- /bin/bash -c 'nginx -s quit'
2023/05/25 08:07:31 [notice] 33#33: signal process started
[root@k8s-240 pod]# kubectl get pod
NAME READY STATUS RESTARTS AGE
pod-always 1/1 Running 1 (4s ago) 28m
4.非正常停止容器应用,发现容器又被重启了一下,然后Pod又恢复正常状态了,并且重启次数再次增加1次;
[root@k8s-240 pod]# kubectl exec -it pod-always -- /bin/bash -c 'kill 1'
[root@k8s-240 pod]# kubectl get pod
NAME READY STATUS RESTARTS AGE
pod-always 1/1 Running 2 (55s ago) 53m
重启侧罗Always,在创建单个Pod的情况下,不管Pod中的容器是否正常停止,最终都会恢复。
5.2 Never
1.编写Pod的yaml文件
apiVersion: v1
kind: Pod
metadata:
name: pod-never
spec:
restartPolicy: Never
containers:
- name: pod-never
image: nginx
ports:
- containerPort: 80
2.检查Pod的运行状态,可以看到Pod正常运行,RESTARTS(重启次数)字段为0.
[root@k8s-240 pod]# kubectl exec -it pod-never -- /bin/bash -c 'nginx -s quit'
2023/05/25 08:50:35 [notice] 33#33: signal process started
[root@k8s-240 pod]# kubectl get pod
NAME READY STATUS RESTARTS AGE
pod-always 1/1 Running 2 (18m ago) 71m
pod-never 0/1 Completed 0 29s
5.3 OnFailure
1.编写Pod的yaml文件
apiVersion: v1
kind: Pod
metadata:
name: pod-onfailure
spec:
restartPolicy: OnFailure
containers:
- name: pod-onfailure
image: nginx
ports:
- containerPort: 80
2.检查Pod的运行状态,可以看到Pod正常运行,RESTARTS(重启次数)字段为0.
[root@k8s-240 pod]# kubectl get pod
NAME READY STATUS RESTARTS AGE
pod-onfailure 1/1 Running 0 19s
[root@k8s-240 pod]# kubectl exec -it pod-onfailure -- /bin/bash -c 'kill 1'
error: cannot exec into a container in a completed pod; current phase is Succeeded
[root@k8s-240 pod]# kubectl get pod
NAME READY STATUS RESTARTS AGE
pod-onfailure 0/1 Completed 0 61s #没有成功
6.Pod生命周期
6.1 什么是Pod生命周期
Pod对象从创建开始至终止退出之间的时间称其为生命周期
6.2 生命周期流程
下图展示了一个Pod的完整生命周期过程,其中包含Init Container、Pod Hook、健康检查 三个主要部分,接下来我们就来分别介绍影响Pod生命周期的部分
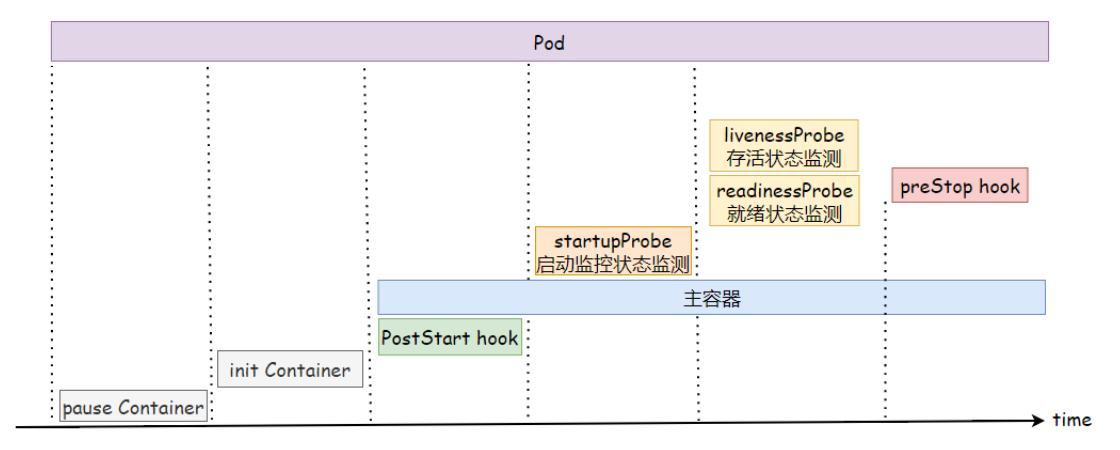
6.3 生命周期总结
当一个Pod对象被创建时,其生命周期的运行步骤如下:
1. 创建pause基础容器:在启动任何其他容器之前,首先创建一个pause容器。该容器用于初始化Pod的环境,并提供共享的名称空间给后续加入的容器使用。
2. 运行初始化容器:按照定义顺序依次运行用户定义的初始化容器。这些初始化容器以串行方式运行,用于完成Pod环境的初始化。如果任何一个初始化容器运行失败,将导致Pod创建失败。根据restartPolicy的策略进行处理,默认为重启。
3. 启动程序容器:在所有初始化容器成功完成后,启动主要的程序容器。如果Pod中有多个容器,它们将并行启动,并各自维护自己的生命周期。同时,主容器上定义的Poststart钩子函数会在容器启动时运行。如果该步骤失败,相关容器将被重启。
4. 运行健康状态监测:在容器启动后,执行容器启动健康状态的监测(startupProbe)。如果检测失败,根据restartPolicy中定义的策略进行处理。如果没有定义策略,默认状态为成功(Success)。
5. 运行存活状态和就绪状态监测:容器在启动成功后,定期进行存活状态监测(Liveness)和就绪状态监测(Readiness)。如果存活状态监测失败,将导致容器重启;而就绪状态监测失败将使容器从负载均衡中被移除。
6. 终止Pod:在终止Pod时,先运行preStop钩子函数。在经过宽限期(terminationGracePeriodSeconds)后,终止容器。宽限期默认为30秒。
以上是Pod对象生命周期的运行步骤。
7.Init Container
7.1 基本概念
Init Container是用来做初始化工作的容器。可以有一个或多个,如果多个按照定义的顺序依次执行,只有所有的执行完后,主容器才启动由于一个Pod里的存储卷是共享的,所以 Init Container 里产生的数据可以被主容器使用到,但它仅仅是在Pod启动时,在主容器启动前执行,做初始化工作,如果 Pod 的 Init 容器失败,Kubernetes 会不断地重启该 Pod,直到 Init 容器成功为止。如果 Pod 对应的restartPolicy 值为 Never,Kubernetes 不会重新启动 Pod。
7.2 应用场景
1、app容器依赖MySQL的数据交互,所以可以启动一个初始化容器检查MySOL服务是否正常,如果正常则启动主容器;
2、在启动主容器之前,使用初始化容器对系统内核参数进行调优.然后共享给主容器使用;
3、获取集群成员节点地址,为主容器生成对应配置信息,这样主容器启动后,可以通过配置信息加入集群环境;
7.3 场景实践
1.编写yaml,使用初始化容器对MySQL端口进行检查,如果存活则运行Pod,否则一直重启尝试
apiVersion: v1
kind: Pod
metadata:
name: init-check-mysql
spec:
initcontainers:
- name: check-mysql
image: oldxu3957/tools
command: ["sh", "-c", "nc -z 10.0.0.206 3306"]
securityContext:
privileged: true #以特权模式运行容器,否则无法修改内核参数
Containers: #主容器
- name: app-mysql
image: nginx
ports:
- containerPort: 80
2.当MySQL服务没有启动完毕,则改Pod会出现初始化失败,然后触发重启
[root@master ~]# kubectl get pod init-systctl-nginx
NAME READYSTATUS RESTARTS AGE
init-check-mysql 0/1 Init:CrashLoopBack0ff(5s ago) 43s
3.安装MySQL服务,确保3306对外监听
yum install mariadb-server
systemctl start mariadb
4.检查Pod,发现已经检查到MySQL运行,所以会启动主容器
[root@master ~] kubectl get pod init-systctl-nginx
NAME READY STATUS RESTARTS AGE
init-check-mysql 1/1] Running 0 103s
场景实践二 优化内核参数
1.编写yaml,使用初始化容器对内核参数进行优化
[root@master pod-init]# cat init-sysctl-nginx.yaml
apiVersion: v1
kind: Pod
metadata:
name: init-sysctl-nginx
spec:
initContainers: #初始化容器,必须运行完就结束,否则后续无法正常运行主容器
- name: set-sysctl
image: alpine:3.13
command: ["sh","-c","sysctl -wnet.core.somaxconn=32769; sysctl -wnet.ipv4.ip_local_port_range='1024 65000"]
securityContext:
privileged: true# 以特权模式运行容器否则无法修改内核参数
containers: #主容器
- name: app-sysctl
image: nginx
ports:
- containerPort: 80
2.运行Pod,检查Pod的内核参数,发现已经优化了(建议使用镜像查看此前的内核参数)
[root@master ~]# kubectl get pod
NAME READY STATUS RESTARTS AGE
init-sysctl-nginx 0/1 Init:0/1 0 4S
[root@master ~]# ubectl exec -it init-systctl-nginx-c "app-sysctl" -- /bin/bash -c "cat/proc/sys/net/core/somaxconn"
32769
八.Pod Hook
容器生命周期钩子(Container Lifecycle Hooks)监听容器生命周期的特定实践,并在事件发生时执行已注册的回调函数。
kubernetes支持 poststart和prestop事件。当一个容器启动后,kubernetes将立即发送poststart事件;在容器被终结之前,kubernetes将发送一个prestop事件。容器可以为每个事件指定一个处理程序。
8.1 两种钩子
postStart: 容器创建后立即执行,由于是异步执行,它无法保证一定在容器之前运行。如果失败,容器会被杀死,并根据RestartPolicy决定是否重启。
preStop: 容器终止前执行。用于:释放占用的资源,清理注册过的信息,优雅的关闭进程。在其完成之前会阻塞删除容器的操作,默认等待时间为30s,可以通过terminationGracePeriodSecpnds宽限时间。
8.2 钩子示例
postStart示例:
#通过postStart设定端口重定向,将请求本机的8080调度到本机的80端口
lifecycle:
postStart:
exec:
command:
- "/bin/bash"
- "-c"
- "iptables -t nat -A PREROUTING -p tcp --dport 8080 -j REDIRECT --to-ports 80"
preStop
# runner主要用来编译打包提高CI效率。启动后悔注册到gitlab上,后续不需要可以删除Pod,然后清理注册信息
#通过preStop清理runner注册信息
lifecycle:
preStop:
exec:
command:
- /bin/bash
- -c
- /usr/bin/gitlab-runner unregister -n $RUNNER_NAME
8.3 场景实践
postStart 命令在容器的 /usr/share/nginx/html/index.html自定义一段内容 preStop负载优雅的终止nginx服务。
terminationGracePeriodSecpnds: 宽限期,如果超过宽限期pod还没终止,则会由SIGKILL强制关闭信号介入。
apiVersion: v1
kind: Pod
metadata:
name: Tifecycle-nginx
spec:
containers:
- name: Tifecycle-demo-container
image: nginx
lifecycle:
postStart:
exec:
command:
- "/bin/sh"
- "-c"
- "echo 'Hello from the postStart handler' > /usr/share/nginx/html/index.html"
preStop:
exec:
command:
- "/bin/sh"
- "-c"
- "nginx -s stop"
场景实践二
postStart命令负责将默认页面,拷贝至/usr/local/tomcat/webapps preStop负责给容器发送 SIGERM信号,从而优雅的终止tomcat服务。
terminationGracePeriodSecpnds: 宽限期,如果超过宽限期pod还没终止,则会有SIGKILL强制关闭信号介入。
apiVersion: v1
kind: Pod
metadata:
name: Tifecycle-tomcat-hook
labels:
web: tomcat
spec:
terminationGracePeriodSeconds: 120
containers:
- name: tomcat
image: tomcat
ports:
- containerPort: 8080
lifecycle:
postStart:
exec:
command:
- "/bin/bash"
- "-c"
- "cp -rf /usr/local/tomcat/webapps.dist/* /usr/local/tomcat/webapps"
preStop:
exec:
command:
- "/bin/bash"
- "-c"
- "sleep 10; /usr/local/tomcat/bin/shutdown.sh"
九.Pod检测探针
9.1 为何需要探针
当容器进程运行时如果出现了异常退出,Kubernetes则会认为容器发生故障,会尝试进行重启解决该问题。但有不少情况是发生了故障,但进程并没有退出。比如访问Web服务器时出现了500的内错误,可能是系统超载,也可能是资源死锁,但nginx进程并没有异常退出,在这种情况下重启容器可能是最佳的方法。那如何来实现这个检测呢;
Kubernetes 使用探针 (probe) 的方式来保障容器正常运行,实现零宕机;它通过 kubelet 定期对容器进行健康检查 (exec、tcp.http) ,当探针检测到容器状态异常时,会通过重启策略来进行重启或重建完成修复。修复后继续进行探针检测,已确保容器稳定运行。
9.2 探针探测类型
针对运行中的容器,kubelet 可以选择以下三种探针来探测容器的状态
- startupProbe 启动探针
用于检测容器中的应用是否已经正常启动。如果使用了启动探针,则所有其他探针都会被禁用,需要等待启动探针检测成功之后才可以执行。如果启动探针探测失败,则 kubelet 会将容器杀死,而容器依其重启策略 进行重启。如果容器没有提供启动探测,则默认状态为Success。 - LivenessProbe 存活探针
用于检测容器是否存活,如果存活探测检测失败,kubeLet会杀死容器,然后根据容器重启策略,决定是否重启该容器。如果容器不提供存活探针,则默认状态为Success。 - readinessProbe 就绪探针
指容器是否准备好接收网络请求,如果就绪探测失败,则将容器设定为未就绪状态,然后将其从负载均衡列表中移除,这样就不会有请求会调度到该Pod上;如果容器不提供就绪态探针,则默认状态为Success.
9.3 探针检查机制
使用探针来检查容器有如下集中方式
- exec : 在容器内执行指定命令。如果命令退出时返回码为 则认为诊断成功。
- httpGet: 对指定的IP、端口,执行HTTP请求。如果响应的状态码大于等于200且小于400,则诊断被认为是成功的。
- tcpSocket: 对容器的 IP 地址上的指定端口执行 TCP 检查。如果端口打开,则诊断被认为是成功的。
每次探测都将获得以下三种结果之一 - Success (成功) : 容器通过了诊断Success
- Failure (失败) :容器未通过诊断,可能会触发重启操作
- Unknown (未知) : 诊断失败,因此不会采取任何行动.
9.4 探针配置格式
apiVersion: v1
kind: Pod
metadata :
name : probe
spec :
containers:
- name :
image:
livenessProbe:
exec:
httpGet:
tcpSocket:
initialDelaySeconds:
timeoutseconds:
PeriodSeconds:
successThreshold:
failureThreshold:
十.startupProbe
10.1 exec
apiVersion: v1
kind: Pod
metadata:
name: pod-startup-exec
spec:
containers:
- name: pod-startup-exec
image: oldxu3957/demoapp:v1.8
ports:
- containerPort: 80
startupProbe:
exec:
command:
- "/bin/sh"
- "-c"
- "ps aux | grep demo.py"
initialDelaySeconds: 10 #容器启动多久后开始探测,默认0
periodSeconds: 10 #探测频率,10s探测一次
timeoutSeconds: 10 #探测超时时间
successThreshold: 1 #成功多少次则为成功,默认1次
failureThreshold: 3 #失败多少次则为失败,默认3次
PS 第一次探测失败多久会重启
initialDelaySeconds + (periodSeconds +timeoutSeconds) * faiureThreshold
PS 程序启动完成后: 此时不需要计入initiaLDelaySeconds.
(periodSeconds + timeoutSeconds) * failureThreshold
10.2 httpGet
apiVersion: v1
kind: Pod
metadata:
name: pod-startup-http
spec:
containers:
- name: pod-startup-http
image: oldxu3957/demoapp:v1.0
ports:
- containerPort: 80
startupProbe:
httpGet:
path: /
port: 80
initialDelaySeconds: 10 #容器启动多久后开始探测,默认0
periodSeconds: 10 #探测频率,10s探测一次
timeoutSeconds: 10 #探测超时时长
successThreshold: 1 #成功多少次则为成功,默认1次
failureThreshold: 3 #失败多少次则为失败默认3次
10.3 tcpSocket
apiVersion: v1
kind: Pod
metadata:
name: pod-startup-tcp
spec:
containers:
- name: pod-startup-tcp
image: oldxu3957/demoapp:v1.0
ports:
- containerPort: 80
startupProbe:
tcpSocket:
port: 80
initialDelaySeconds: 10 #启动多久开始探测
periodSeconds: 10 #探测频率 10s一次
timeoutSeconds: 10 #探测超时时长
successThreshold: 1 #成功多少次为成功 默认1次
failureThreshold: 3 #失败多少次为失败 默认3次
十一. livenessProbe
11.1 exec
apiVersion: v1
kind: Pod
metadata:
name: pod-liveness-exec
spec:
containers:
- name: pod-liveness-exec
image: oldxu3957/demoapp:v1.0
ports:
- containerPort: 80
livenessProbe:
exec:
command:
- "/bin/sh"
- "-c"
- '["$(curl -s 127.0.0.1/livez)" = "OK"]'
initialDelaySeconds: 10 #容器启动后多久开始探测,默认0
periodSeconds: 10 #探测时间间隔 10s探测一次
timeoutSeconds: 10 #探测的超时时间
successThreshold: 1 #成功多少次为成功 默认1次
failureThreshold: 3 #失败多少次为失败 默认3次
2、为了测试存活状态监测效果,可以手动将/Livez接口的响应内容修改为任意值。
[root@master ~]# kubectl exec -it pod-liveness-exec- curl -s -X POST -d 'livez=error' http://127.0.0.1/livez
3、会发现容器等待60s之后,会触发重启操作
[root@master ~]# kubectl describe pod pod-liveness-exec
...
Warning Unhealthy 31s (x3 over 51s) kubelet Liveness probe failed:
Normal Killing 31s kubelet Container pod-liveness-exec failed livenessprobe, will be restarted
11.2 httpGet
apiVersion: v1
kind: Pod
metadata:
name: pod-liveness-http
spec:
containers:
- name: pod-liveness-http
image: oldxu3957/demoapp:v1.0
ports:
- containerPort: 80
livenessProbe:
httpGet:
path: '/livez'
port: 80
scheme: HTTP
initialDelaySeconds: 10 #容器启动后多久开始探测,默认0
periodSeconds: 10 #探测时间间隔 10s探测一次
timeoutSeconds: 10 #探测的超时时间
successThreshold: 1 #成功多少次为成功 默认1次
failureThreshold: 3 #失败多少次为失败 默认3次
2、镜像中定义的默认响应是以200状态码响应,存活状态会成功完成为了测试存活状态监测效果,可以手动将/Livez接口的响应内容修改为任意值。
[root@master ~]# kubectl exec -it pod-liveness-http-- curl -s -X POST -d 'livez=error' 127.0.0.1/ivez
3、等待3个监测周期,容器会因健康监测失败而被重启,重启后/ivez响应内容会被重置为ok,后续存活状态监测不会出现错误
[root@master ~]# kubectl describe pod pod-liveness-http
Warning Unhealthy 30s (x6 over 7m30s) kubeletLiveness probe failed: HTTP probe failedwith statuscode: 506
Normal Killing30s (x2 over 7m10s) kubeletContainer pod-liveness-http failed livenessprobe, will be restarted
11.3 tcpSocket
apiVersion: v1
kind: Pod
metadata:
name: pod-liveness-tcp
spec:
containers:
- name: pod-liveness-tcp
image: oldxu3957/demoapp:v1.0
ports:
- containerPort: 80
livenessProbe:
tcpSocket:
port: 80
initialDelaySeconds: 10 #容器启动后多久开始探测,默认0
periodSeconds: 10 #探测时间间隔 10s探测一次
timeoutSeconds: 10 #探测的超时时间
successThreshold: 1 #成功多少次为成功 默认1次
failureThreshold: 3 #失败多少次为失败 默认3次
十二.readinessProbe
指容器是否准备好接收网络请求,如果就绪探测失败,则将容器设定为未就绪状态,然后将其从负载均衡列表中移除,这样就不会有请求会调度到该Pod上;如果容器不提供就绪态探针,则默认状态为Success。
有些程序启动后需要加载配置或数据,甚至有些程序需要运行预热的过程,需要一定的时间。所以需要避免Pod启动成功后立即让其处理客户端请求,而应该让其初始化完成后转为就绪状态,在对外提供服务。此类应用就需要使用readinessProbe探针。
12.1 exec
apiVersion: v1
kind: Pod
metadata:
name: pod-readiness-exec
labels:
app: readiness
spec:
containers:
- name: pod-readiness-exec
image: oldxu3957/demoapp:v1.0
ports:
- containerPort: 80
readinessProbe:
exec:
command:
- "/bin/sh"
- "-c"
- '[ "$(curl -s 127.0.0.1/readyz)" = "OK" ]'
initialDelaySeconds: 10 #容器启动后多久开始探测,默认0
periodSeconds: 10 #探测时间间隔 10s探测一次
timeoutSeconds: 10 #探测的超时时间
successThreshold: 1 #成功多少次为成功 默认1次
failureThreshold: 3 #失败多少次为失败 默认3次
12.2 httpGet
apiVersion: v1
kind: Pod
metadata:
name: pod-readiness-http
labels:
app: readiness
spec:
containers:
- name: pod-readiness-http
image: oldxu3957/demoapp:v1.0
ports:
- containerPort: 80
readinessProbe:
httpGet:
path: '/readyz'
port: 80
scheme: HTTP
initialDelaySeconds: 10 #容器启动后多久开始探测,默认0
periodSeconds: 10 #探测时间间隔 10s探测一次
timeoutSeconds: 10 #探测的超时时间
successThreshold: 1 #成功多少次为成功 默认1次
failureThreshold: 3 #失败多少次为失败 默认3次
2.为了测试就绪状态监测效果,将/readyz修改为非0K
[root@master ~]# kubectl exec -it pod-readiness-http -- curl -s -X POST -d 'readyz=error' http://127.0.0.1/readyz
3.由于pod未就绪,所以会将该节点从Service负载均衡中准为未就绪状态 (需要事先创建好负载均衡,否则难以观察效果)
[root@master ~]# kubectl get pod pod-readiness-http
NAME READY STATUS RESTARTS AGE
pod-readiness-http 0/1 Running 0 6m
[root@master ~]# kubectl describe endpoints pod-readiness-exec
Name: pod-readiness-exec
Subsets:
Addresses: <none>
NotReadyAddresses: 192.168.3.38
12.3 tcpSocket
apiVersion: v1
kind: Pod
metadata:
name: pod-readiness-tcp
labels:
app: readiness
spec:
containers:
- name: pod-readiness-tcp
image: oldxu3957/demoapp:v1.0
ports:
- containerPort: 80
readinessProbe:
tcpSocket:
port: 80
initialDelaySeconds: 10 #容器启动后多久开始探测,默认0
periodSeconds: 10 #探测时间间隔 10s探测一次
timeoutSeconds: 10 #探测的超时时间
successThreshold: 1 #成功多少次为成功 默认1次
failureThreshold: 3 #失败多少次为失败 默认3次
十三.Pod资源限制
13.1 什么是资源限制
在kubernetes集群中,某Pod发生异常,不断的使用系统资源。会对kubernetes中所有Pod稳定性产生影响,所以需对运行的Pod进行资源限制。
13.2 如何实现资源限制
kubernetes 通过 requests 和 limits 字段阿里实现对pod的资源进行限制
- requests:启动Pod时申请分配的资源大小;(Pod在调度的时候requests比较重要)
- limits: 限制Pod运行时最大可用的资源大小;(Pod在运行时limits比较重要)
spec.containers[].resources .request.cpu
spec.containers[].resources.request.memory
spec.containers[].resources.limits.cpu
spec.containers[].resources.limits.memory
13.3 资源限制的目的与意义
CPU: 为集群中运行的容器配置CPU请求和限制,可以有效利用集群上可用的CPU资源。
-
设置Pod CPU请求 设定在较低的数值,可以使Pod更有机会被调度。
-
设置CPU limit大于CPU request,可以完成如下两件事:
* 当Pod碰到一些突发负载时,它可以合理利用可用的CPU资源 * 当Pod在突发流量期间,可使用的CPU被限制为合理的数值,从而可以避免影响其他Pod的正常运行
Memory: 为集群中运行的容器配置内存请求和限制,可以有效利用集群节点上可用的内存资源。
-
通过将POD的内存请求设定在脚底的数值,可以使Pod更有机会被调度。
-
通过让内存限制大于内存请求,可以完成如下两件事:
- 当Pod碰到一些突发负载时,可以更好的利用其主机上的可用内存。
- 当Pod在突发负载期间可使用的内存被限制为合理的数值,从而可以避免影响其他的Pod的运行。
十四.资源限制单位换算
14.1 CPU限制单位
1核CPU等于1000毫核,当定义容器为0.5时,所能用到的CPU资源时1核心CPU的一半,对于 CPU 资源单位,表达式 .1 等价于表达式100m,可以看作 1 millicpu.
1 核心 = 100 millicpu(1 Core = 1000m)
0.5 核 = 50日 millicpu(0.5 Core = 500m)
举例:当我们有1个物理CPU,16核心,如果某个Pod最多使用一半的核心数,则表达式可以写入如下两种:
- limits.cpu: 8
- Timits.cpu: 8000m 计算公式: (160*.5=8000m)
注意: Kubernetes不允许设置精度小于 1m 的CPU资源。因此当CPU 单位小于1时,只能使用毫核来表示。
例如: 期望使用1个CPU的0.5%,应该写 5m 而不是 .5
14.2 内存限制单位
内存的基本单位是字节数(Bytes),也可以加上国际单位,十进制的E、P、T、G、M,K、m,或二进制的 Ei、Pi、Ti、Gi、Mi、Ki.
1MB = 1000 KB = 100000 Bytes
1Mi = 1024 KB = 1048576 bytes
十五.CPU资源限制实践
metrics-server
15.1 设置容器的CPU请求和限制
1.创建一个具有一个容器的Pod。容器将请求0.5个CPU,最多限制使用1个CPU
apiVersion: v1
kind: Pod
metadata:
name: cpu-demo
spec:
containers:
- name: cpu-demo-ctr
image: vish/stress
args: #容器启动命令,容器尝试使用2核CPU
- "-cpus"
- "2"
resources:
requests: #显示启动Pod时最多申请0.5核的CPU
cpu: "500m"
limits: #限制运行中的Pod最多使用1核CPU
cpu: "1000m"
2.查看Pod详细信息,输出显示Pod中的一个容器的CPU请求为500 milli CPU,并且 CPU限制为1个CPU.
[root@master ~]# kubectl get pod cpu-demo -o yaml
resources:
Limits:
cpu:"1"
requests:
cpu: 500m
3.检查资源限制情况,容器配置为尝试使用2个CPU,但是容器只被允许最大使用1个CPU,所以容器的CPU用量受到限制。
[root@master ~]# kubectl apply -f https://linux.oldxu .net/metrics-server.yaml
[root@master ~]# kubectl top pod cpu-demo
NAME CPU(cores) MEMORY(bytes)
cpu-demo 913m 0Mi
15.2 设置超过节点的CPU请求
1.创建一个 Pod,设置该Pod中容器的请求为100核,这个值会大于集群中的任何一个节点。
apiVersion: V1
kind: Pod
metadata:
name: cpu-demo-2
spec:
containers:
- name: cpu-demo-ctr-2
image: vish/stress
args:
- -cpus
- "2"
resources:
requests:
cpu: "100"
limits:
cpu:"100"
2.查看该Pod的状态,输出显示Pod状态为 pending.也就是说 Pod未被调度到任何节点上运行。
[root@master pod-request]# kubectl get pod
NAME READY STATUS RESTARTS AGE
cpu-demo-2 0/1 Pending 0 3s
3.查看该Pod的详细信息及事件,输出显示由于节点上的CPU资源不足,无法调度容器
[rootmaster ~]# kubectl describe pod cpu-demo-2
Events:
Type Reason Age From Message
-----------------------------------------------
Warning FailedScheduling 49s (x2 over 116s)default-scheduler /3 nodes are available: 1node(s) had taint {node-role .kubernetes .io/master:}, that the pod didn't tolerate, 2 Insufficient cpu.
4.删除Pod
[root@master ~]# kubectl delete pod cpu-demo-2
pod "cpu-demo-2" deleted
15.3 如果不指定CPU的limits
如果没有为容器指定 CPU 限制,那么容器在可以使用的 CPU 资源是没有上限。因而可以使用所在节点上所有的可用 CPU 资源,这样可能会造成某一个Pod占用了大量的CPU时间,可能会影响其他的Pod正常运行从而造成业务的不稳定性。
这个也不用担心,在Kubernetes中,可以通过 LimitRange 自动为容器设定,所使用的CPU资源和内存资源最大最小值。
十六. 内存资源限制实践
16.1 设置容器的内存请求和限制
1.创建一个拥有一个容器的Pod。容器将会请求100MiB内存,并且内存会被限制在200MiB 以内
apiVersion: v1
kind: Pod
metadata:
name: memory- demo
spec:
containers:
- name: memory-demo-ctr
image: polinux/stress
command: ["stress"]
args: ["--vm","1","--vm-bytes","150M","--vm-hang”,"1”] # 告知容器尝试分配 150 MB 内存
resources:
requests:
memory: "100Mi'
limits:
memory: "200Mi"
2.检查Pod,结果显示该Pod中容器的内存请求为 100MiB,内存限制为 200MiB
[root@master ~]# kubectl get pod memory-demo -o yaml
resources :
limits:
memory: 200Mi
requests:
memory: 100Mi
3.获取该Pod的指标数据: 输出结果显示Pod正在只用的内存为150MiB.这大于Pod请求的100MiB,但又在Pod限制的200MiB之内。
[root@master ~]# kubectl top pod memory-demo
NAME CPU(cores) MEMORY(bytes)
mmemory-demo 46m 150Mi
4.删除pod
[root@master ~]# kubectl delete pod memory-demo
pod "memory-demo" deleted
16.2 运行超过容器内存限制的应用
当节点拥有足够的可用内存时,容器可以使用其请求的内存。但是,容器不允许使用超过其限制的内存。如果容器分配的内存超过其限制,该容器会成为被终止的候选容器。如果容器继续消耗超出其限制的内存,则终止容器。如果终止的容器可以被重启,则 kubelet 会重新启动它。
1.创建一个 Pod,其拥有一个容器,该容器的内存请求为 100MiB,内存限制为 200MiB,尝试分配超出其限制的内存。
[root@master ~]# cat memory-request-limit-2.yaml
apiVersion: v1
kind: Pod
metadata:
name: memory- demo-2
spec:
containers:
- name: memory-demo-2-ctr
image: polinux/stress
command: ["stress"]# 容器会尝试分配 250 MiB 内存,这远高于 100 MiB 的限制。
args: ["--vm","1","--vm-bytes","250M","-- vm-hang","1” ] # 模拟1个进程产生250M内存
resources:
requests:
memory:"100Mi"
limits:
memory: "200Mi"
2.查看Pod,此时,容器可能正在运行或被杀死。重复前面的命令,直到容器被杀掉:
[root@master ~]# kubectl get pod
NAME READY STATUS RESTARTS AGE
memory-demo-2 0/1 00MKilled 0 13s
3.查看容器更详细的信息,其输出结果为,内存溢出 (00M) ,容器已被杀掉:
[root@master ~]# kubectl get pod memory-demo-2 -o yaml
lastState:
terminated:
containerID:docker://43d2278dacdac6cea191c6c04f2147025128ce45c961ab0c2d366840dobc5e40
exitCode: 1
finishedAt: "2022-04-11T15:45:17Z
reason: 00MKilTed
startedAt: "2022-04-11T15:45:17Z"
4.删除Pod
[root@master ~]# kubectl delete pod memory-demo-2
pod "memory-demo-2" deleted
16.3 超过节点的内存分配
Pod 的调度基于请求。只有当节点拥有足够满足 Pod 内存请求的内存时,才会将 Pod 调度至节点上运行。
1.创建一个 Pod,其拥有一个请求 1000GiB 内存的容器,这应该超过了集群中任何一台节点所拥有的内存。
[root@master pod-request]# cat memory-request-limit-3.yaml
apiVersion: V1
kind: Pod
metadata:
name: memory- demo-3
spec:
containers:
- name: memory-demo-3-ctr
image: polinux/stress
command: ["stress"]
args: ["--vm","1","--vm-bytes","25M","--vm-hang","1”] # 告知容器尝试分配 25 MiB 内存
resources:
requests:
memory: "100Gi"
limits:
memory:"200Gi"
2.查看 Pod 状态,发现处于 PENDING 状态。 这意味着,该 Pod 没有被调度至任何节点上运行
[root@master ~]# kubectl get pod
NAME READY STATUS RESTARTS AGE
memory-demo-3 0/1 Pending 0 46s
3.查看Pod详情,输出结果显示,由于节点内存不足,该容器无法被调度:
[root@master ~]# kubectl describe pod memory-demo-3
Events:
Type Reason Age From
Message
------------------------------------------------
WarningFailedScheduling 78s default-scheduler0/3 nodes are available: 1 node(s) had taint inoderole.kubernetes .io/master: ], that the pod didn'ttolerate,2 Insufficient memory.
iang
4.删除Pod
[root@master ~]# kubectl delete pod memory-demo-3
pod "memory-demo-3" deleted
16.4 如果没有指定内存限制
如果没有为容器指定内存限制,容器可无限制地使用其所在节点的所有可用内存,进而可能导致该节点调用 00M KiLLer。 此外,如果发生 00MKi飞,没有配置资源限制的容器将被杀掉的可行性更大。
不用担心,在Kubernetes中,可以通过[LimitRange]自动为其容器设定,所使用的内存资源最大最小值。
十七. Pod服务质量QoS
17.1 设么是QoS
QoS (Quality of Service) ,可译为 "服务质量等级",或者译作"服务质量保证",是作用在 Pod 上的一个配置,当 Kubernetes 创建一个 Pod 时,它就会给这个 Pod 分配一个 QoS 等级。
在Kubernetes的环境中,Kubernetes允许节点的Pod过载使用资源这意味着节点无法同时满足所有Pod以过载的方式运行。因此在内存资源紧缺的情况下,Kubernetes需要借助Pod对象的服务质量和优先级等完成判定,进而挑选对应的Pod杀死。Kubernetes根据pod的Requests和Limits属性,把Pod对象归类为三类 BestEffort、BurStable、Guaranteed
17.2 QoS类别
- Guaranteed: Pod对象为每个容器都设置了CPU资源需求和资源限制,且两者的值相同;还同时为每个容器设置了内存需求与内存限制,并且两者的值相同。这类Pod对象具有最高级别服务质量。
- Burstable: 至少有一个容器设置了CPU或内存资源Requests属性,但不满足Guaranteed,这类Pod具有中级服务质量。
- BestEffort:没有为任何容器设置Requests和Limits属性,这类Pod对象服务质量是最低级别。
当 Kubernetes 集群内存资源紧缺,优先杀死BestEffort类别的容器,因为系统不为该类资源提供任何服务保证,但此类资源最大的好处就是能够尽可能的使用资源
如果系统中没有BestEffort类别的容器,接下来就轮到Burstable类别的容器,如果有多个Burstable类别的容器,就看谁的内存资源占用多,就优先干掉谁。比如A容器申请1G内存资源,实际使用了95%,而B容器申请了2G内存资源,实际使用了80%,但任然会优先干掉A容器,虽然A容器的用量少,但与自身的Requests值相比,它的占比要大于B容器.
对于Guaranteed类别的容器拥有最高优先级,它们不会被杀死,除非其内存资源需求超限,或者00M时没有其他更低优先级的Pod对象存在,才会干掉Guaranteed类容器。
17.3 创建Guaranteed的Pod
对于 QoS 类为 Guaranteed 的 Pod:
- Pod 中的每个容器都必须指定内存请求和内存限制,且Pod中每个容器内存请求必须等于内存限制。
- Pod 中的每个容器都必须指定CPU请求和CPU限制,且Pod中每个容器CPU请求必须等于CPU限制。
1.创建一个Pod,容器设置了内存请求和内存限制,值都是200MiB。容器设置了CPU请求和CPU限制,值都是70 milLiCPU
[root@master ~]# cat pod-gos-guaranteed.yaml
apiVersion: V1
kind: Pod
metadata:
name: pod-qos-guarantee
spec:
containers:
- name: qos-demo
image: nginx
resources:
requests:
cpu:"700m"
memory: "200Mi"
limits:
cpu: "700m"
memory: "200Mi"
2.查看Pod详情
spec:
containers:
Limits:
cpu: 700m
memory: 200Mi
Requests:
cpu: 700m
memory: 200Mi
status:
qosClass: Guaranteed
17.4 创建Burstable的Pod
如果满足下面条件,将会指定 Pod 的 QoS 类为 Burstable。
- Pod 不符合 Guaranteed QoS 类的标准。
- Pod 中至少一个容器指定了,内存或 CPU 的请求或限制
1.创建一个Pod,容器设置了内存请求 100 MiB,以及内存限制 200MiB。
[root@master ~]# cat pod-qos-burstable.yaml
apiVersion: V1
kind: Pod
metadata:
name: pod-gos-burstable
spec:
containers:
- name: qos-demo
image: nginx
resources:
requests:
memory: "100Mi"
limits:
memory: "200Mi"
2.查看Pod详情
spec :
containers:
Limits:
memory: 200Mi
Requests:
memory : 100Mi
status:
qosClass: Burstable
17.5 创建BestEffort的Pod
对于 QoS 类为 BestEffort 的 Pod,Pod 中的容器必须没有设置内存和 CPU 限制或请求。
1.创建一个Pod,容器没有设置内存和 CPU 限制或请求
[root@master tmp]# cat pod-qos-besteffort.yaml
apiVersion: 1
kind: Pod
metadata:
name: pod-qos-besteffort
spec:
containers:
- name: qos-demo
image: nginx
2.查看 Pod 详情
spec:
containers:
...
resources: {}
...
status:
qosClass: BestEffort
17.6 创建多容器Pod
1.创建一个Pod,一个容器指定了内存请求 200 MiB。 另外一个容器没有指定任何请求和限制。此 Pod 满足 Burstable QoS 类的标准但它不满足 Guaranteed QoS 类标准,因为它的一个容器设有内存请求。
[root@master ~]# cat pod-qos-mutil.yaml
apiVersion: V1
kind: Pod
metadata:
name: pod-qos-mutil
spec:
containers:
- name: gos-demo
image: nginx
resources :
requests:
memory: "100Mi"
- name: qos-demo2
image: redis
2.查看Pod
spec :
containers:
name: qos-demo
resources :
Requests:
memory: 100Mi
......
name: qos-demo2
resources: {}
....
status:
qosClass:Burstable
十八. Downward API
18.1 什么是DownwardAPI
DownwardAPI可以让容器获取Pod的相关元数据信息,比如Pod名称Pod的IP,Pod的资源限制等,获取后通过env、volume的方式将相关的环境信息注入到容器中,从而让容器通过这些信息,来设定容器的运行特性。
- 例如: Nginx进程根据节点的CPU核心数量自动设定要启动的worker进程数。
- 例如: JVM虚拟根据Pod的内存资源限制,来设定对应容器的堆内存大小。
- 例如: 获取Pod名称,以Pod名称注册到某个服务,当Pod结束后调用prestop清理对应名称的注册信息。
18.2 可注入的元数据信息
使用 pod.spec.containers.env.valueFrom.fieldRef 可以注入的字段有:
- metadata.name: Pod对象的名称
- metadata.namespace: Pod对象隶属的名称空间
- metadata.uid: Pod对象的UID
- metadata.Labels['
]: 获取Label指定KEY对应的值 - metadata.annotations['
]: 获取Annotations对应KEY的值 - status.podIP: Pod对象的IP地址
- status.hostIP: 节点IP
- status.nodeName: 节点名称
- spec.serviceAccountName: Pod对象使用的ServiceAccount资源名称
使用
pod.spec.containers.env.valueFrom .resourceFieldRef 可以注入的字段有: - requests.cpu
- requests.memory
- limits.cpu
- limits.memory
18.3环境变量方式注入元数据
1.创建Pod容器,将Pod相关环境变量注入到容器中,比如 (pod名称命名空间、标签、以及cpu、内存的请求和限制)
apiVersion: v1
kind: Pod
metadata:
name: pod-downward
labels:
app: pod-app
spec:
containers:
- name: pod-downward
image: nginx
command: ["/bin/sh", "-c", "env"]
resources:
requests:
cpu: "200m"
memory: "32Mi"
limits:
cpu: "200m"
memory: "64Mi"
env:
- name: THIS_POD_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: THIS_POD_NAMESPACE
valueFrom:
fieldRef:
fieldPath: metadata.namespace
- name: THIS_POD_APP_LABEL
valueFrom:
fieldRef:
fieldPath: metadata.labels['app']
- name: THIS_CPU_LIMITS
valueFrom:
resourceFieldRef:
resource: limits.cpu
- name: THIS_MEMORY_REQUEST
valueFrom:
resourceFieldRef:
resource: requests.memory
#divisor: 1Mi #默认显示为字节,通过divisor调整显示单位为兆
2.通过控制台日志获取注入的环境变量
[root@master tmp]# kubectl Togs pod-downward |grep ^THIS
THIS_CPU_LIMITS=1 # 200毫核,不足1核,则进行取整。
THIS_POD_APP_LABEL=pod-app
THIS_POD_NAME=pod-downward
THIS_MEMORY_REQUEST=32 # 单位为兆,默认字节
THIS_POD_NAMESPACE=default
18.4 存储卷方式注入元数据
apiVersion: v1
kind: Pod
metadata:
name: pod-downward-volumes
labels:
app: pod-app
zone: beijing
role: backend
spec:
containers:
- name: pod-downward
image: nginx
resources:
requests:
cpu: "200m"
memory: "32Mi"
limits:
cpu: "200m"
memory: "54Mi"
volumeMounts: #将环境变量挂载到/etc/podinfo目录中,每注入一条元数据都会产生一个文件
- name: podinfo
mountPath: /etc/podinfo
volumes:
- name: podinfo
downwardAPI:
items:
- path: podname
fieldRef:
fieldPath: metadata.name
- path: podlabels
fieldRef:
fieldPath: metadata.labels
- path: podnamespace
fieldRef:
fieldPath: metadata.namespace
- path: mem_limits
resourceFieldRef:
containerName: pod-downward
resource: limits.memory
#divisor: 1Mi #默认显示为字节,通过divisor调整显示单位为兆
- path: mem_requests
resourceFieldRef:
containerName: pod-downward
resource: requests.memory
#divisor: 1Mi #默认显示为字节,通过divisor调整显示单位为兆
18.4 为注册服务注入Pod名称
使用DownwardAPI实现注册与卸载
apiVersion: apps/v1
kind: Deployment
metadata:
name: pod-mysql-register
spec:
replicas: 10
selector:
matchLabels:
app: tools
template:
metadata:
labels:
app: tools
spec:
containers:
- name: register
image: oldxu3957/tools:latest
imagePullPolicy: IfNotPresent
command:
- "/bin/bash"
- "-c"
- |
mysql -h 10.8.0.286 -u oldxu -p123 -e "create database ${POD_NAME//-/_}"
sleep 9999999
env:
- name: POD_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
lifecycle:
preStop:
exec:
command:
- "/bin/bash"
- "-c"
- "mysql -h 10.8.0.286 -u oldxu -p123 -e 'drop database ${POD_NAME//-/_}'"
18.5 为tomcat注入堆内存限制
默认Tomcat应用会使用Pod所在的物理节点内存,初始堆内存为1/64,最大堆内存为1/4.
[root@master tmp]# cat 11-pod-lifecycle-2.yaml
apiVersion: v1
kind: Pod
metadata:
name: pod-tomcat
spec:
containers:
- name: tomcat-web
image: tomcat:9.0.63
ports:
- containerPort: 8080
env:
- name: JAVA_OPTS
value: -server -Xms${JVM_XMS} -Xmx${JVM_XMX} -XX:+UseConcMarkSweepGC
# downward API
- name: JVM_XMS
valueFrom:
resourceFieldRef:
resource: requests.memory
- mame: JVM_XMX
valueFrom:
resourceFieldRef:
resource: limits.memory
resources:
requests:
memory: "250Mi"
limits:
memory: "500Mi"

 浙公网安备 33010602011771号
浙公网安备 33010602011771号