原于2018年1月在实验室组会上做的分享,今天分享给大家,希望对大家科研有所帮助。

今天给大家分享一下对抗训练(Adversarial Training,AT)。
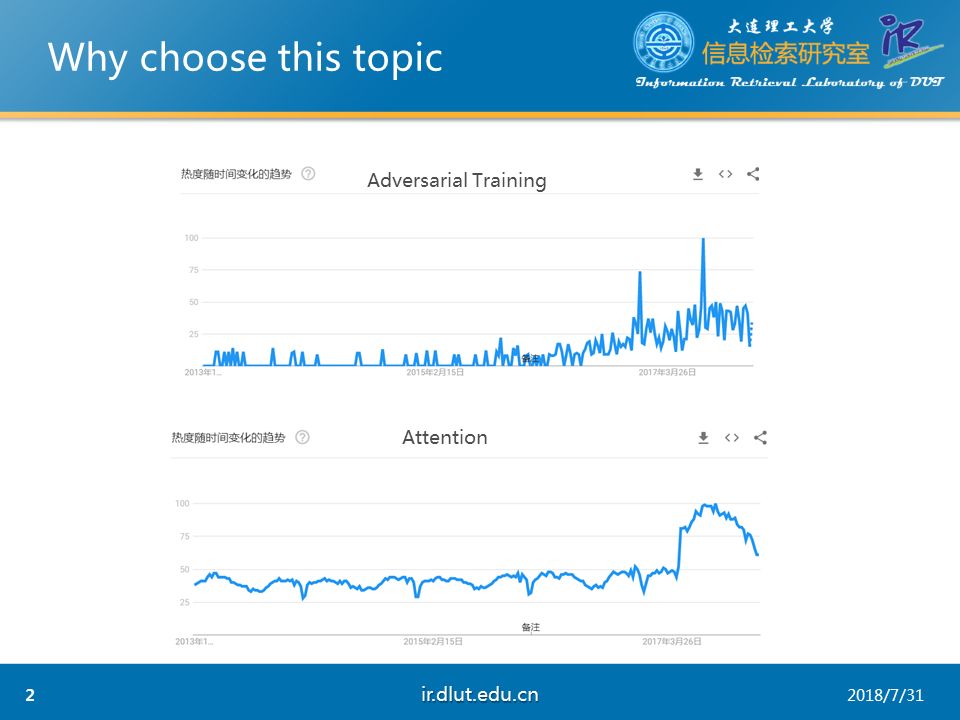
为何要选择这个主题呢?
我们从上图的Attention的搜索热度可以看出,Attention在出现后,不断被人们所重视,基本上现在的顶会论文都离不开Attention。
同样,AT的搜索热度也持续高涨,因此,我们有理由相信AT也能像Attention一样,在学术界大放光彩。
原本的AT,最初是在样本中加入对抗扰动使神经网络失效,当时AT并不广为人知。
但是后来GAN(Generative Adversarial Networks )的出现,使AT受到了大量的关注,并且也被用于各种任务中。
下面,我们通过三篇论文来介绍一下AT能够应用于何种场景,以及能够取得何种效果。
首先,我们来介绍一下《Domain-Adversarial Training of Neutral Networks》

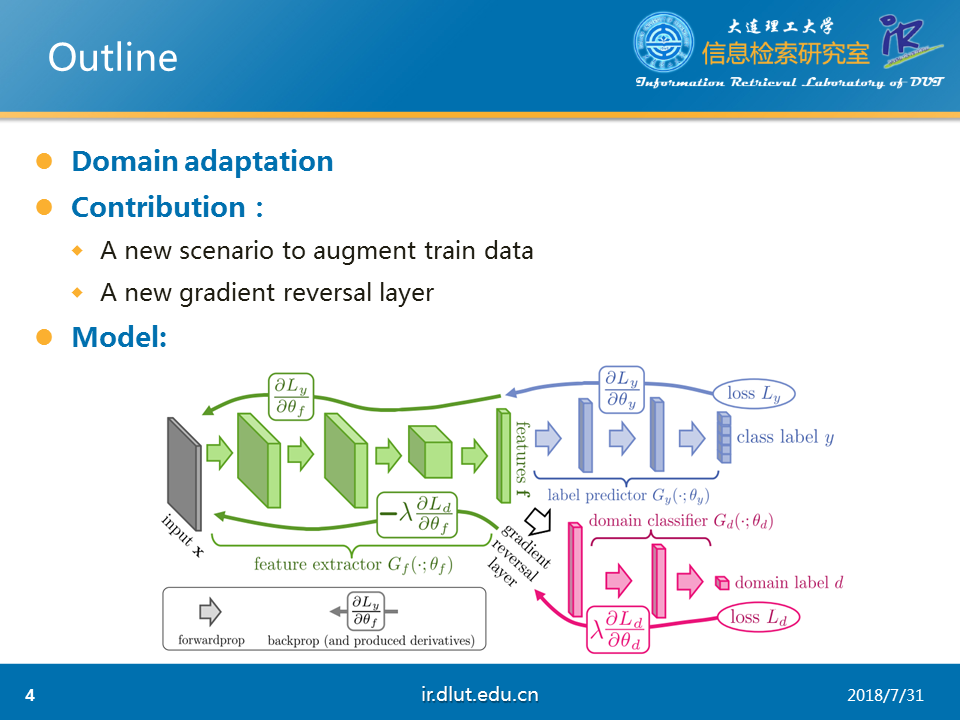
这篇论文的核心任务是领域适配(Domain Adaptation),也是我们常说的迁移学习。主要涉及两个领域,一个目标领域(target domain)和源领域(source domain),通常,源领域的资源、语料较多、比较适合特征建模,但是并不是任务需要的领域,仅仅是相关领域;但是目标领域虽然是任务需要的领域,但是由于资源、语料少,难于建模。因此,通过在源领域学习特征后,迁移到目标领域,即领域适配。
本文的主要贡献是①一种新的扩充训练集的方式②提出了梯度方向层(Gradient Reversal Layer, GRL)
本文的模型包括三个部分,分别为特征抽取器(feature extractor)、标签预测器(label predictor)和领域分类器(domain classifier)。
特征抽取器主要用于抽取两个领域的特征,而标签预测器用于对源领域的样本进行标签预测(目标领域的语料少,这里假设目标语料没有标注数据,所以不需要对目标语料进行预测)。领域分类器借助GRL对样本是来源于目标领域还是源领域进行预测。

本文的理论依据是如果抽取的特征是两个领域中公共的特征(即仅仅使用该特征无法区分该样本是来自目标领域还是源领域),则该特征比较适合领域适配(即可以利用该特征进行迁移学习,且效果较好)。
那么如何评价领域适配的好于坏呢?
领域适配中涉及目标误差(target error)和源误差(source error),领域适配的好坏可以通过目标误差的大小来衡量。而目标误差可以通过源误差+两领域之间的距离来衡量。
源误差通过损失函数很容易衡量,那么,问题的焦点可以转移到两领域的距离如何衡量上。

在论文中,作者指出可以使用领域散度(domain divergence)来衡量两个领域的距离。但是由于计算复杂,作者又引入代理距离(Proxy Distance)来计算。即代理距离可以通过分类器在两领域上的误差来衡量(ε表示分类器在两领域上得到的最小损失)。

源误差可以通过神经网络来衡量,而距离可以通过代理距离来衡量,则整个领域适配的损失函数便是两者的相加。

源领域的误差可以通过最小化标签分类器的误差来达到最小化;在领域分类器上,由于代理距离的衡量需要最小化分类器的损失,因此模型需要最小化领域分类器的误差。同时由于要寻找两个领域公共的特征,也就是特征抽取的特征不能最小化领域分类器的误差,必须要最大化。这样与普通的后向传播有很大的区别。为此,作者提出使用GRL来将领域分类器传给特征分类器的梯度进行反向。这样在最小化领域分类器的误差时,从特征抽取器的角度看是最大化领域分类器,而从领域分类器的角度看,是最小化领域分类器的误差,这样就形成了对抗,这就是本文的对抗的体现。
通过对抗训练,特征抽取器抽取的特征是两领域中公共的特征,那么就可以利用这些公共特征来进行迁移学习。同时由于本模型不需要目标语料的标签,因此可以大幅度的扩充训练语料规模。
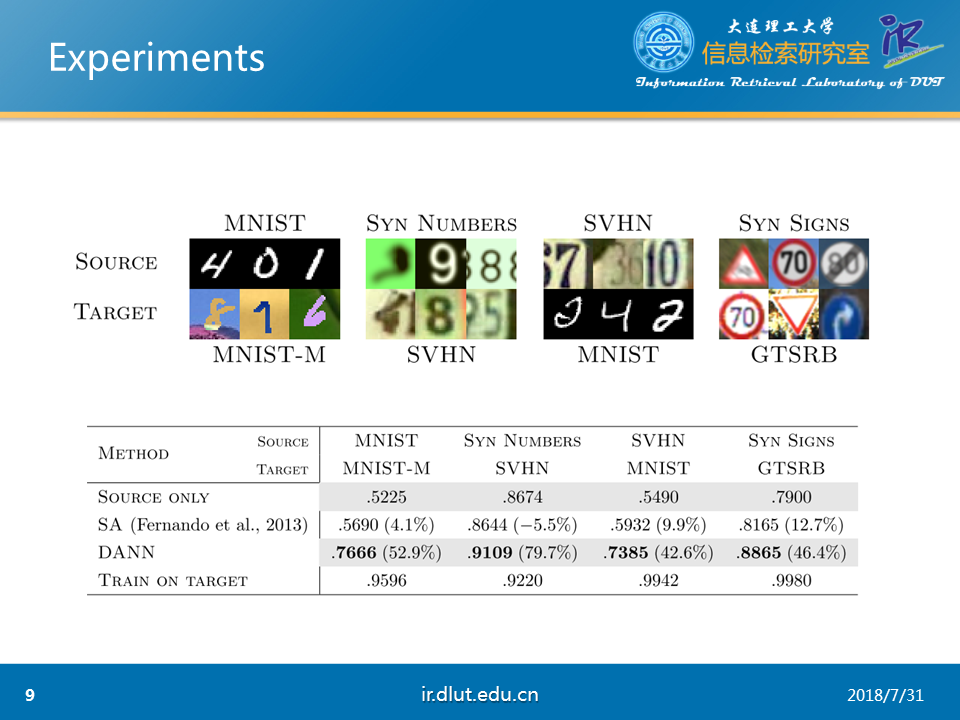
作者在MNIST数据集上对本文模型进行了测试,可以看出文本模型的确有所提升。

AT的另一个应用便是《Adversarial Multi-task Learning for Text classification》,本文可以看成是《Domain-Adversarial Training of Neutral Networks》的一种扩展,基本没有特别大的创新点。
本文主要的任务是多任务学习,也就是某些任务相互关联,而且语料都很少,如果每一任务单独训练一个模型很容易造成过拟合,但是如果将他们一起训练,寻找这些任务中的公共特征,那么模型在这些任务上都有提升。
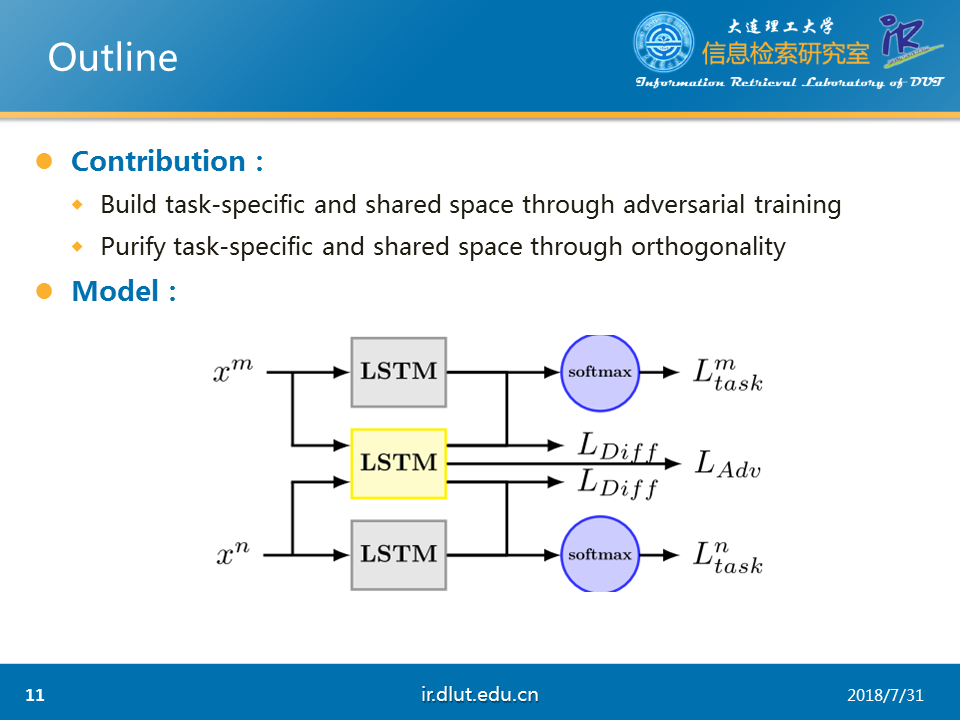
本文的创新点主要有①通过AT来区分特定任务的特征和公共特征②通过正交化来确保两种特征不产生交集。
本文的模型如上所示,每个任务都有一个LSTM来用提取本任务特定的特征,同时所有的任务都公用一个LSTM来提取公共特征。这两者的区分是通过梯度反向层GRL和正交化来实现的
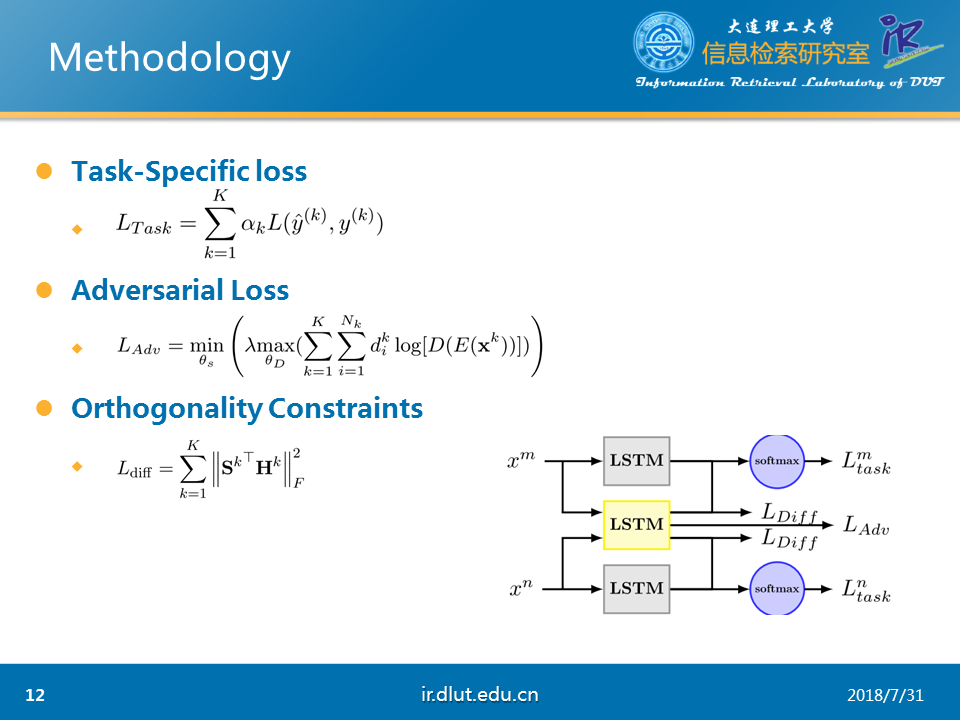
特定任务的损失直接通过softmax来衡量,而对抗训练通过GRL来实现。
正交化直接通过F范数实现。
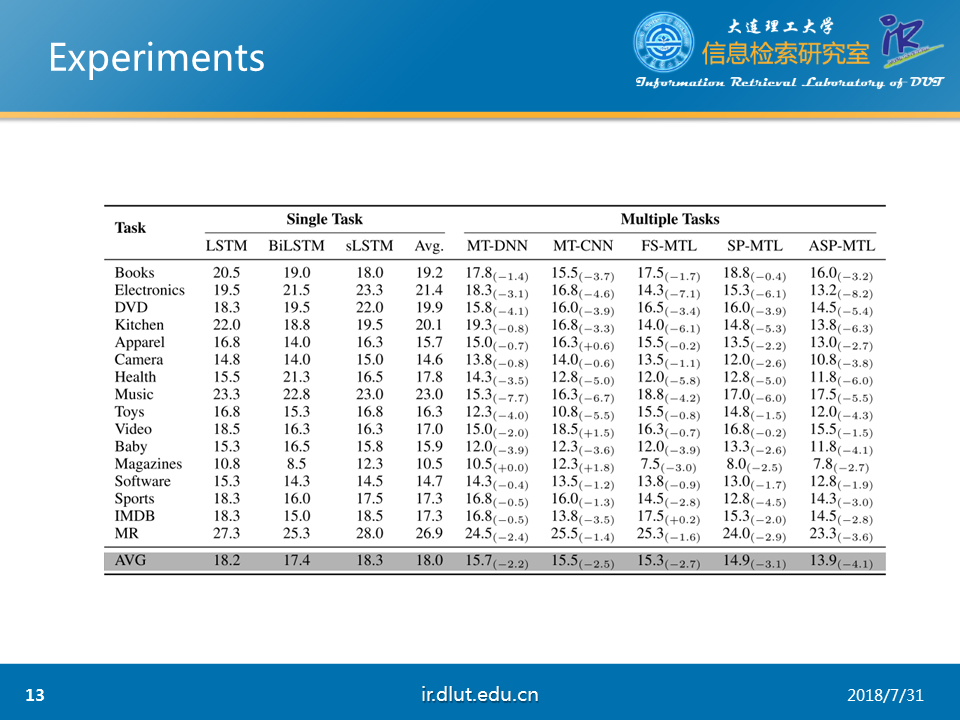
作者通过实验也证明本文模型的有效性。
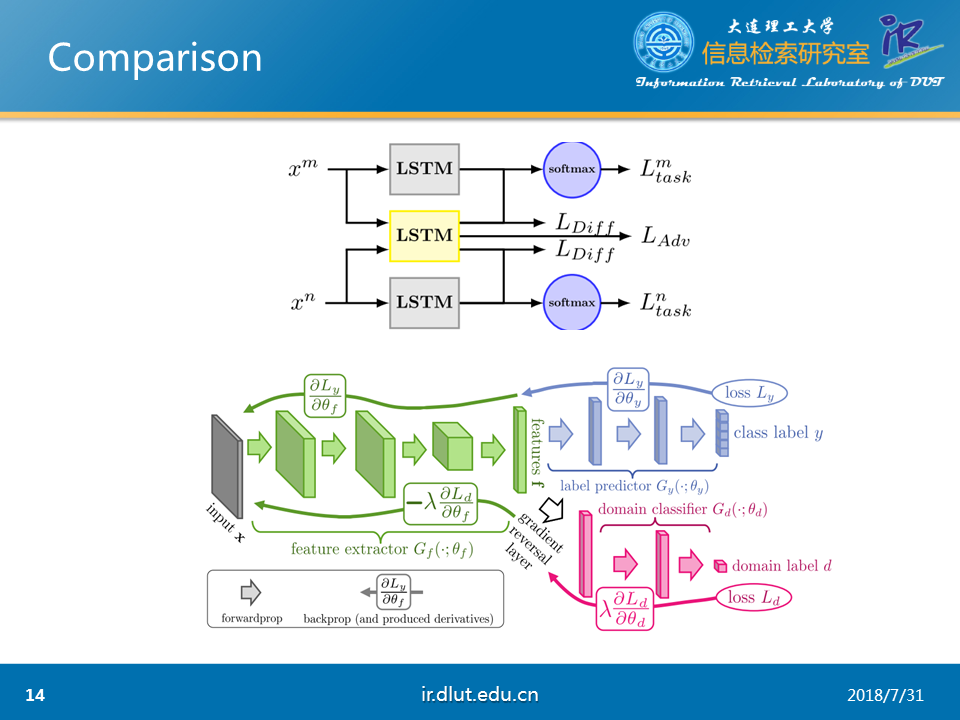
由于《Adversarial Multi-task Learning for Text classification》和《Domain-Adversarial Training of Neutral Networks》相识性,我们可以将这两者进行对比,可以发现本文仅仅是对后者的多类别扩充。
下面,来介绍AT的另一种应用,即《Adversarial Training for Relation Extraction》。

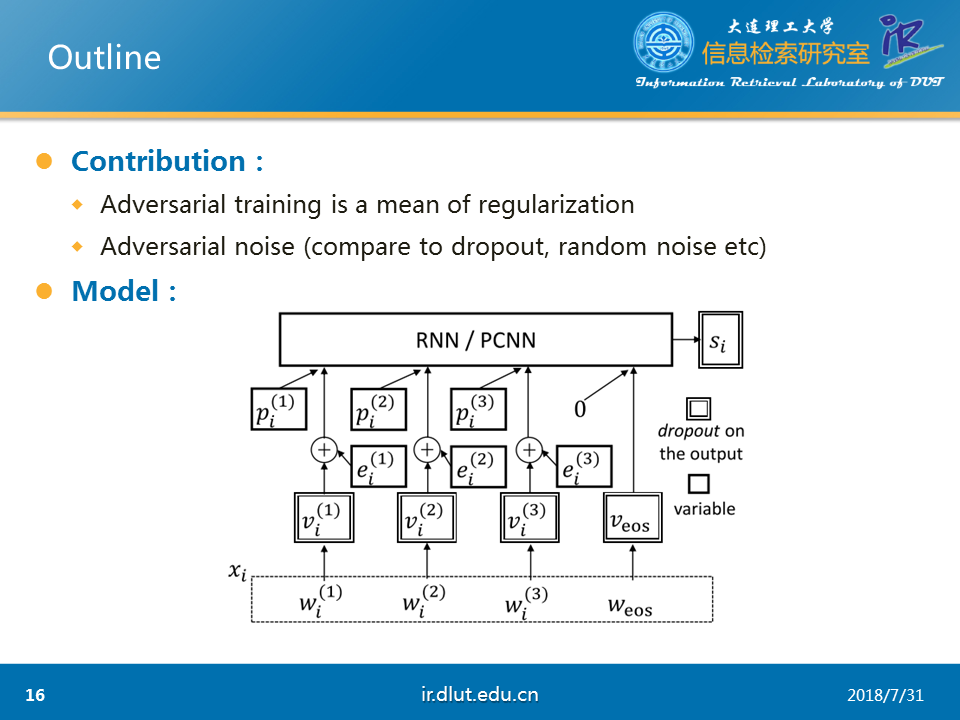
本文的主要贡献在于①将AT视为一种正则化方法②提出对抗噪音,也就是AT正则化的原理。
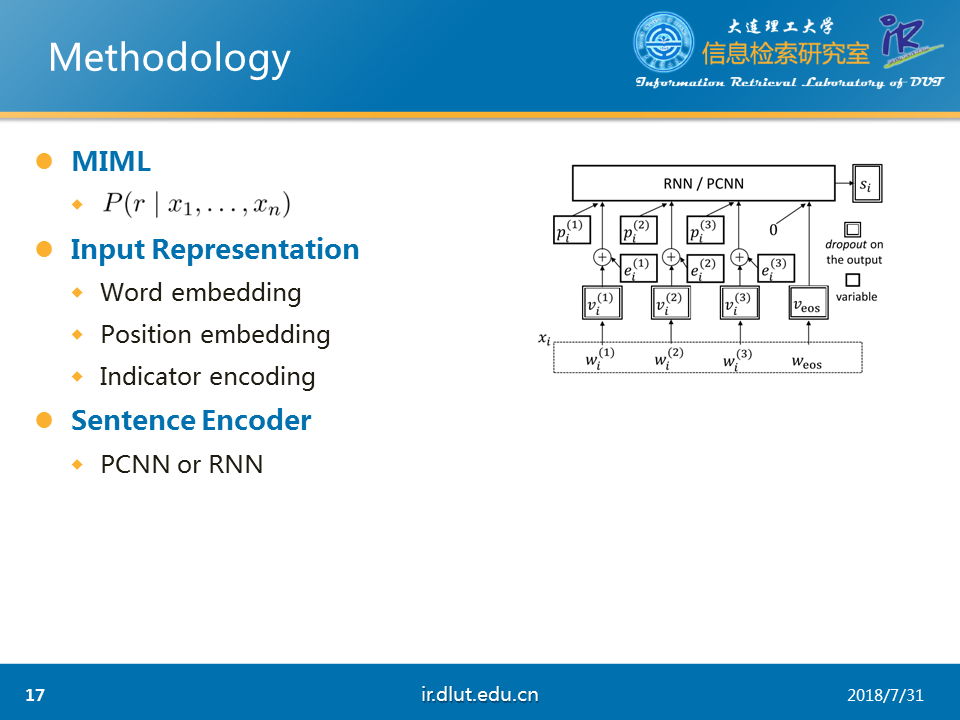
本文的主要任务是多标签学习。在关系抽取中,由于人工标注语料较少,同时目前的知识库较多(如百度百科、维基等)。因此相关研究者提出通过知识库来自动的创建语料,但是由于是自动标注,因而存在偏差,即标签不一定正确。为了解决标签不一定正确的问题,多标签学习便被提出。

本文的模型首先通过RNN或者PCNN抽取特征,然后通过选择注意力(selective attention)来选择当前实体对最有可能的标签,最后通过softma即可得到模型损失。
本文的对抗是通过在输入层也就是词向量层加入对抗扰动(该扰动能够最大化模型损失)来实现。
本文的对抗的作用与在模型中加入高斯噪音有着相似的效果。与随机的高斯噪音不同,本文的对抗噪音是非随机的,能够使模型损失变大的噪音。能够最大化提高模型的泛化性能。
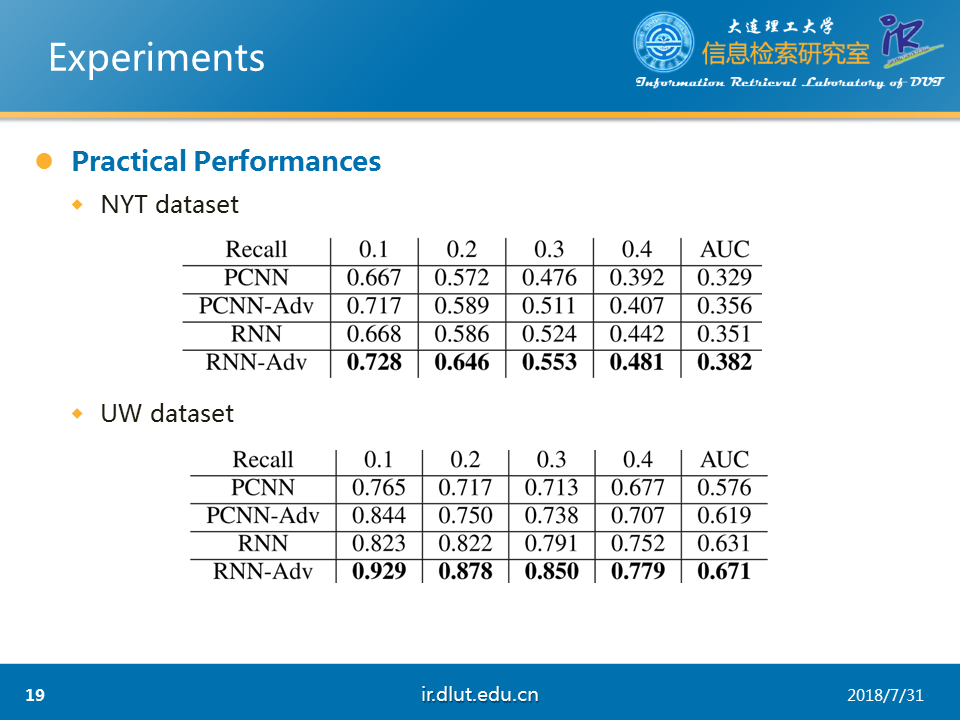
作者在NYT和UW两个数据集上证明了本文方法的有效性。
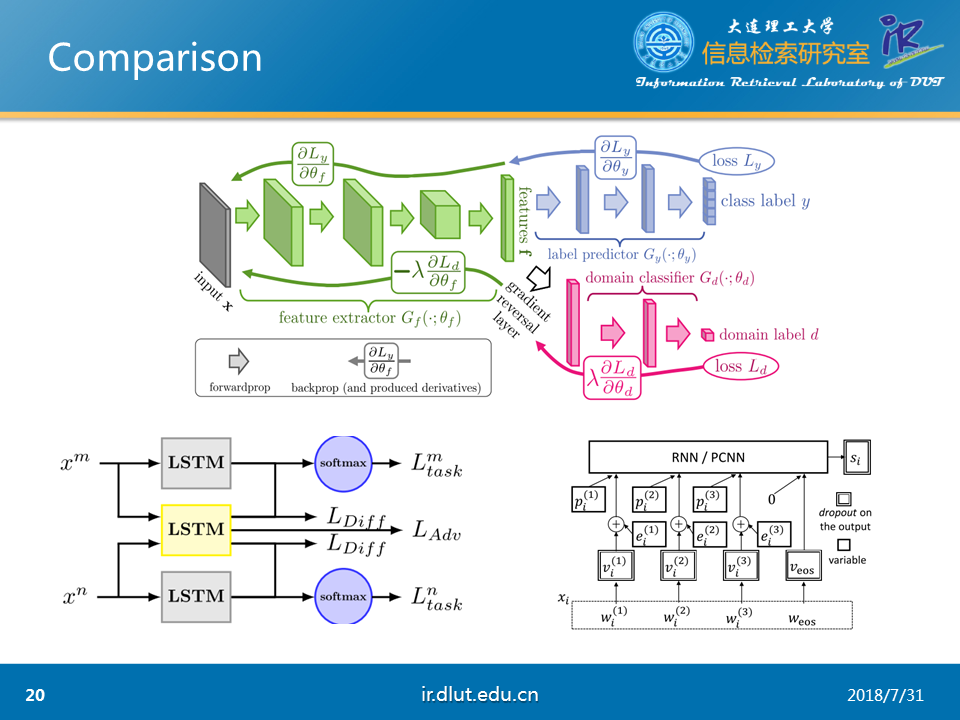
我们可以将这三篇论文进行对比,来对AT进行更加深入的理解。
目前,AT主要是用于提取公共特征上,通过这种方式可以有效地扩大训练集。同时还可以将AT作为一种正则化的方法,来提高模型的泛化性能。
但是,缺点也很明显,现在的AT大多是用于迁移学习、多任务学习,这会涉及两个以上的领域,那么对于特定领域、单任务能够利用AT呢?能否在单任务的关系抽取中利用AT呢?
在单任务中利用AT的挑战主要是无法找到生成器(G)和判别器(D),既然G和D不明确,那么对抗也就无从谈起。
同时对抗的另一个缺点便是需要大量的数据,在图像领域,由于数值的连续性,可以很容易的获得大量数据。但是文本领域中的大量数据却不是很好获得。前两篇论文通过多任务来获得大量数据,而最后一篇论文通过远程监督来获得大量数据(通过知识库来自动标注数据集这一技术被称为远程监督)。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号