
GO指南之练习答案
GO指南之练习答案
练习:循环与函数
为了练习函数与循环,我们来实现一个平方根函数:给定一个数 x,我们需要找到一个数 z 使得 z² 尽可能地接近 x。
计算机通常使用循环来计算 x 的平方根。从某个猜测的值 z 开始,我们可以根据 z² 与 x 的近似度来改进 z,产生一个更好的猜测:
z -= (z*z - x) / (2*z)
重复调整的过程,猜测的结果会越来越精确,得到的答案也会尽可能接近实际的平方根。
请在提供的 func Sqrt 中实现它。无论输入是什么,可以先猜测 z 为 1。 首先,重复计算 10 次并连续打印每次的 z 值。观察对于不同的 x 值(1、2、3 ...), 你得到的答案是如何逼近结果的,以及猜测改进的速度有多快。
提示:用类型转换或浮点数语法来声明并初始化一个浮点数值:
z := 1.0
z := float64(1)
然后,修改循环条件,使得当值停止改变(或改变非常小)的时候退出循环。 观察迭代次数大于还是小于 10。尝试改变 z 的初始猜测,如 x 或 x/2。 你的函数结果与标准库中的 math.Sqrt 有多接近?
( 注: 如果你对该算法的细节感兴趣,上面的 z² − x 是 z² 到它所要到达的值(即 x) 的距离,除数 2z 为 z² 的导数,我们通过 z² 的变化速度来改变 z 的调整量。 这种通用方法叫做牛顿法, 它对很多函数,特别是平方根而言非常有效。)
答案:
package main
import (
"fmt"
"math"
)
func Sqrt(x float64) float64 {
z := 1.0
tmp := 0.0
for {
z = z - (z*z -x) / (2*z)
fmt.Println(z)
if math.Abs(z-tmp) < 0.0000000001 {
break
} else {
tmp = z
}
}
return z
}
func main() {
Sqrt(4)
}
/* 运行结果:
2.5
2.05
2.000609756097561
2.0000000929222947
2.000000000000002
2
*/
练习:切片
实现 Pic。它应当返回一个长度为 dy 的切片,其中每个元素是一个长度为 dx,元素类型为 uint8 的切片。当你运行此程序时,它会将每个整数解释为灰度值 (好吧,其实是蓝度值)并显示它所对应的图像。
图像的解析式由你来定。几个有趣的函数包括 (x+y)/2、x*y、x^y、x*log(y) 和 x%(y+1)。
(提示:需要使用循环来分配 [][]uint8 中的每个 []uint8。)
(请使用 uint8(intValue) 在类型之间转换;你可能会用到 math 包中的函数。)
答案:
package main
import "golang.org/x/tour/pic"
//import "math"
func Pic(dx, dy int) [][]uint8 {
img := make([][]uint8, dy)
for i := range img {
img[i] = make([]uint8, dx)
for j := range img[i] {
img[i][j] = uint8((i + j) / 2) // 此处可替换成其他函数
}
}
return img
}
func main() {
pic.Show(Pic)
}
练习:映射
实现 WordCount。它应当返回一个映射,其中包含字符串 s 中每个“单词”的个数。 函数 wc.Test 会为此函数执行一系列测试用例,并输出成功还是失败。
你会发现 strings.Fields 很有用。
答案:
package main
import (
"golang.org/x/tour/wc"
"strings"
)
func WordCount(s string) map[string]int {
p := strings.Fields(s)
var m map[string]int // 声明
m = make(map[string]int) // 初始化
for _,v :=range p{
m[v] += 1
}
return m
}
func main() {
wc.Test(WordCount)
}
/* 运行结果:
PASS
f("I am learning Go!") =
map[string]int{"Go!":1, "I":1, "am":1, "learning":1}
PASS
f("The quick brown fox jumped over the lazy dog.") =
map[string]int{"The":1, "brown":1, "dog.":1, "fox":1, "jumped":1, "lazy":1, "over":1, "quick":1, "the":1}
PASS
f("I ate a donut. Then I ate another donut.") =
map[string]int{"I":2, "Then":1, "a":1, "another":1, "ate":2, "donut.":2}
PASS
f("A man a plan a canal panama.") =
map[string]int{"A":1, "a":2, "canal":1, "man":1, "panama.":1, "plan":1}
*/
练习:斐波纳契闭包
让我们用函数做些好玩的。
实现一个 fibonacci 函数,它返回一个函数(闭包),该闭包返回一个斐波纳契数列 (0, 1, 1, 2, 3, 5, ...)。
答案:
package main
import "fmt"
func fibonacci() func() int {
f1, f2 := 0, 1
return func() int {
f := f1
f1, f2 = f2, f1 + f2
return f
}
}
func main() {
f := fibonacci()
for i := 0; i < 10; i++ {
fmt.Printf("%v, ",f()) //原:fmt.Println(f())
}
}
/* 运行结果:
0, 1, 1, 2, 3, 5, 8, 13, 21, 34,
*/
练习:Stringer
通过让 IPAddr 类型实现 fmt.Stringer 来打印点号分隔的地址。
例如,IPAddr{1, 2, 3, 4} 应当打印为 "1.2.3.4"。
答案:
package main
import "fmt"
type IPAddr [4]byte
// TODO: 为 IPAddr 添加一个 "String() string" 方法。
func (i IPAddr) String() string{
return fmt.Sprintf("%v.%v.%v.%v",i[0],i[1],i[2],i[3])
}
func main() {
hosts := map[string]IPAddr{
"loopback": {127, 0, 0, 1},
"googleDNS": {8, 8, 8, 8},
}
for name, ip := range hosts {
fmt.Printf("%v: %v\n", name, ip)
}
}
/* 运行结果:
loopback: 127.0.0.1
googleDNS: 8.8.8.8
*/
练习:错误
从之前的练习中复制 Sqrt 函数,修改它使其返回 error 值。
Sqrt 接受到一个负数时,应当返回一个非 nil 的错误值。复数同样也不被支持。
创建一个新的类型
type ErrNegativeSqrt float64
并为其实现
func (e ErrNegativeSqrt) Error() string
方法使其拥有 error 值,通过 ErrNegativeSqrt(-2).Error() 调用该方法应返回 "cannot Sqrt negative number: -2"。
注意: 在 Error 方法内调用 fmt.Sprint(e) 会让程序陷入死循环。可以通过先转换 e 来避免这个问题:fmt.Sprint(float64(e))。这是为什么呢?
修改 Sqrt 函数,使其接受一个负数时,返回 ErrNegativeSqrt 值。
答案:
package main
import (
"fmt"
)
type ErrNegativeSqrt float64
func (e ErrNegativeSqrt) Error() string {
return fmt.Sprintf("cannot Sqrt negative number: %v", float64(e))
}
func Sqrt(x float64) (float64, error) {
if x < 0 {
return 0, ErrNegativeSqrt(x)
} else {
z := x / 2
for i := 0; i < 10 && z*z-x != 0; i++ {
z -= (z*z - x) / (2 * z)
}
return z, nil
}
}
func main() {
fmt.Println(Sqrt(2))
fmt.Println(Sqrt(-2))
}
/* 运行结果:
1.414213562373095 <nil>
0 cannot Sqrt negative number: -2
*/
练习:Reader
实现一个 Reader 类型,它产生一个 ASCII 字符 'A' 的无限流。
答案:
package main
import "golang.org/x/tour/reader"
type MyReader struct{}
// TODO: 给 MyReader 添加一个 Read([]byte) (int, error) 方法
func (a MyReader) Read(b []byte) (int, error) {
b[0] = 'A'
return 1, nil
}
func main() {
reader.Validate(MyReader{})
}
Go 指南上一页说过:
Read用数据填充给定的字节切片并返回填充的字节数和错误值。在遇到数据流的结尾时,它会返回一个io.EOF错误。
那我们填充了一个 A 就返回 1,无限流转换一下就是不返回 io.EOF,我们返回一个 nil 就行了!
练习:rot13Reader
有种常见的模式是一个 io.Reader 包装另一个 io.Reader,然后通过某种方式修改其数据流。
例如,gzip.NewReader 函数接受一个 io.Reader(已压缩的数据流)并返回一个同样实现了 io.Reader 的 *gzip.Reader(解压后的数据流)。
编写一个实现了 io.Reader 并从另一个 io.Reader 中读取数据的 rot13Reader,通过应用 rot13 代换密码对数据流进行修改。
rot13Reader 类型已经提供。实现 Read 方法以满足 io.Reader。
答案:
package main
import (
"io"
"os"
"strings"
)
type rot13Reader struct {
r io.Reader
}
func rot13(b []byte) []byte {
for i, _ := range b {
switch {
case (b[i] >= 'A' && b[i] <= 'M') || (b[i] >= 'a' && b[i] <= 'm'):
b[i] += 13
case (b[i] >= 'N' && b[i] <= 'Z') || (b[i] >= 'n' && b[i] <= 'z'):
b[i] -= 13
}
}
return b
}
func (a rot13Reader) Read(b []byte) (int, error) {
i, e := a.r.Read(b)
b = rot13(b)
return i, e
}
func main() {
s := strings.NewReader("Lbh penpxrq gur pbqr!")
r := rot13Reader{s}
io.Copy(os.Stdout, &r)
}
/* 运行结果:
You cracked the code!
*/
练习:图像
还记得之前编写的图片生成器 吗?我们再来编写另外一个,不过这次它将会返回一个 image.Image 的实现而非一个数据切片。
定义你自己的 Image 类型,实现必要的方法并调用 pic.ShowImage。
Bounds 应当返回一个 image.Rectangle ,例如 image.Rect(0, 0, w, h)。
ColorModel 应当返回 color.RGBAModel。
At 应当返回一个颜色。上一个图片生成器的值 v 对应于此次的 color.RGBA{v, v, 255, 255}。
答案:
package main
import (
"golang.org/x/tour/pic"
"image"
"image/color"
)
type Image struct { //新建一个Image结构体
w, h int
}
func (i Image) Bounds() image.Rectangle { //实现Image包中生成图片边界的方法
return image.Rect(0, 0, i.w, i.h)
}
func (i Image) ColorModel() color.Model { //实现Image包中颜色模式的方法
return color.RGBAModel
}
func (i Image) At(x, y int) color.Color { //实现Image包中生成图像某个点的方法
return color.RGBA{uint8(x), uint8(y), uint8(255), uint8(255)}
}
func main() {
m := Image{255, 255}
pic.ShowImage(m)
}
练习:等价二叉查找树
不同二叉树的叶节点上可以保存相同的值序列。例如,以下两个二叉树都保存了序列 `1,1,2,3,5,8,13`。
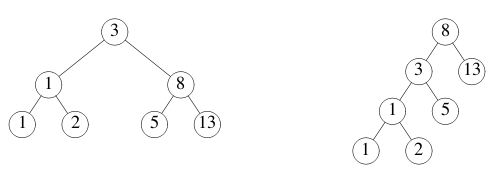
在大多数语言中,检查两个二叉树是否保存了相同序列的函数都相当复杂。 我们将使用 Go 的并发和信道来编写一个简单的解法。
本例使用了 tree 包,它定义了类型:
type Tree struct {
Left *Tree
Value int
Right *Tree
}
1. 实现 Walk 函数。
2. 测试 Walk 函数。
函数 tree.New(k) 用于构造一个随机结构的已排序二叉查找树,它保存了值 k, 2k, 3k, ..., 10k。
创建一个新的信道 ch 并且对其进行步进:
go Walk(tree.New(1), ch)
然后从信道中读取并打印 10 个值。应当是数字 1, 2, 3, ..., 10.
3. 用 Walk 实现 Same 函数来检测 t1 和 t2 是否存储了相同的值。
4. 测试 Same 函数。
Same(tree.New(1), tree.New(1)) 应当返回 true,而 Same(tree.New(1), tree.New(2)) 应当返回 false。
Tree 的文档可在这里找到。
思路一(用go):
- 准备两个信道
- 两棵树分别同时写入自己的信道,写入一个数据后立刻读出数据 (为使该步骤顺利进行,需要将两个
Walk加上go) - 对比读出的数据,一旦数据不同 return false
为什么选择没有缓冲的信道?
- 防止出现ch1在读出第1个数据,ch2已经在读出第2个数据的情况,那样会误判为数据不一样return false
package main
import (
"fmt"
"golang.org/x/tour/tree"
)
// Walk 步进 tree t 将所有的值从 tree 发送到 channel ch。
func Walk(t *tree.Tree, ch chan int) {
// 输出左边;
if nil != t.Left {
Walk(t.Left, ch)
}
// 输出中间;
ch <- t.Value
// 输出右边
if nil != t.Right {
Walk(t.Right, ch)
}
}
// Same 判断 t1 和 t2 是否包含相同的值。
func Same(t1, t2 *tree.Tree) bool {
ch1 := make(chan int)
ch2 := make(chan int)
go Walk(t1, ch1)
go Walk(t2, ch2)
//close(ch1)
//close(ch2)
for i := 0; i < 10; i++ {
x := <-ch1
y := <-ch2
fmt.Println(x, y)
if x != y {
return false
}
}
return true
}
func main() {
flag := Same(tree.New(1), tree.New(1))
fmt.Println(flag)
}
/* 运行结果:
1 1
2 2
3 3
4 4
5 5
6 6
7 7
8 8
9 9
10 10
true
*/
思路二(不使用go)
先把所有的数据全部分别写入自己的信道,之后再依次读取,进行对比
func Same(t1, t2 *tree.Tree) bool {
ch1 := make(chan int, 10)
ch2 := make(chan int, 10)
Walk(t1, ch1)
Walk(t2, ch2)
close(ch1)
close(ch2)
i := 0
for x := range ch1 { // 循环次数
y := <-ch2
fmt.Println(x, y)
if x != y {
return false
}
i++
}
return true
}
练习:Web 爬虫
在这个练习中,我们将会使用 Go 的并发特性来并行化一个 Web 爬虫。
修改 Crawl 函数来并行地抓取 URL,并且保证不重复。
提示: 你可以用一个 map 来缓存已经获取的 URL,但是要注意 map 本身并不是并发安全的!
答案:
借鉴利用队列实现广度优先算法的思路,把第一个url当做根节点,根节点下面的url当做孩子节点,队列当做管道。
- 把第一个url作为根节点,查询[showCrawl()函数]
- 将对应孩子节点集合加入管道。
- 遍历这个孩子节点集合
- 重复2~3步骤
- 直到管道中没有元素
-
为什么要使用
map来存储url而不用数组?虽然只需要存储一个数据
url,但是map可以通过_, ok := map[url]来判断url是否存在,而数组判断某个数据是否存在相对麻烦。 -
管道如何设置"当管道为空时" 停止读取?
设置一个
flag int用于记录管道中还有多少个元素,每次取元素之前判断flag是否为0 -
关于管道记录数
flag ,为什么不判断直接 ++ 呢?万一这个url下面没有任何链接呢,那么就可以不用将 []string写入管道?- 首先,把每个查询后的
url页面下属的url集合放入管道中,要把管道内元素个数++ - 不用判断更加方便
- 如果没有任何链接,
Fetch()会返回一个nil的[]string数组,并且将nil数组加入到管道中 - 在
Crawl()中执行for _, url := range urls时,这个for循环不会执行。正因为这一条,我们可以每次执行查询命令都直接将nil的[]string加入管道,统一管理。注意,在for…range 空数组时,只是不会有任何输出,但不会报错。
- 首先,把每个查询后的
package main
import (
"fmt"
)
type Fetcher interface {
// Fetch 返回 URL 的 body 内容,并且将在这个页面上找到的 URL 放到一个 slice 中。
Fetch(url string) (body string, urls []string, err error)
}
// 存储已经找到url及其body
var store = make(map[string]string)
// 查询页面,并将页面下的url放到管道中
func showCrawl(url string, Urls chan []string, fetcher Fetcher) {
// 1. 搜索url并存储
// 2. 将本页面下属的url写入管道
body, urls, err := fetcher.Fetch(url)
if err != nil {
fmt.Println(err)
} else {
// 显示并存入字典中
fmt.Printf("found: %s %q\n", url, body)
// flag++
}
store[url] = body // 查询过,但是页面没有内容
Urls <- urls
}
// Crawl 使用 fetcher 从某个 URL 开始递归的爬取页面,直到达到最大深度。
func Crawl(url string, depth int, fetcher Fetcher) {
// TODO: 并行的抓取 URL。
// TODO: 不重复抓取页面。
// 下面并没有实现上面两种情况:
// 初始化工作
if depth < 1 {
return
}
Urls := make(chan []string, 10) //需要有缓存的管道:广度优先遍历需要一层层存储
go showCrawl(url, Urls, fetcher) // 用于开篇第一次的查询
flag := 1 // 用于探测管道中还有多少组数据(一个页面的全部下属url为一组)
// 2. 根据要求的深度(depth)查询 : 向下查询多少层
for i := depth; i > 0; i-- {
// 广度优先查询下属url:不一定是广度优先,只要管道里有,就读取
// fmt.Print("dfff")
if flag > 0 {
urls := <-Urls // urls == []string
fmt.Printf("i:%d, flag:%d urls:%s\n", i, flag, urls)
flag-- // 读走一个集合
for _, url := range urls { // 一个页面下的url集合
fmt.Printf("接收到的url:%s\n", url)
if _, ok := store[url]; !ok { // 判断是否查询过
go showCrawl(url, Urls, fetcher)
flag++ //把每个查询后的url页面下属的url集合放入管道中,要把管道内元素个数++
//为什么不判断直接++呢?万一这个url下面没有任何链接呢?
//1. 不用判断更加方便 2. 如果没有任何链接,Feth()会返回一个nil数组,并且将nil数组加入到管道中
// 在Crawl()中执行 for _, url := range urls时,这个for循环不会执行
}
}
}
}
}
func main() {
// flag := 1
Crawl("https://golang.org/", 6, fetcher)
}
// fakeFetcher 是返回若干结果的 Fetcher。
type fakeFetcher map[string]*fakeResult
type fakeResult struct {
body string
urls []string
}
func (f fakeFetcher) Fetch(url string) (string, []string, error) {
if res, ok := f[url]; ok {
return res.body, res.urls, nil
}
return "", nil, fmt.Errorf("not found: %s", url)
}
// fetcher 是填充后的 fakeFetcher。
var fetcher = fakeFetcher{
"https://golang.org/": &fakeResult{
"The Go Programming Language",
[]string{
"https://golang.org/pkg/",
"https://golang.org/cmd/",
},
},
"https://golang.org/pkg/": &fakeResult{
"Packages",
[]string{
"https://golang.org/",
"https://golang.org/cmd/",
"https://golang.org/pkg/fmt/",
"https://golang.org/pkg/os/",
},
},
"https://golang.org/pkg/fmt/": &fakeResult{
"Package fmt",
[]string{
"https://golang.org/",
"https://golang.org/pkg/",
},
},
"https://golang.org/pkg/os/": &fakeResult{
"Package os",
[]string{
"https://golang.org/",
"https://golang.org/pkg/",
},
},
}
/* 运行结果:
found: https://golang.org/ "The Go Programming Language"
i:6, flag:1 urls:[https://golang.org/pkg/ https://golang.org/cmd/]
接收到的url:https://golang.org/pkg/
接收到的url:https://golang.org/cmd/
not found: https://golang.org/cmd/
i:5, flag:2 urls:[]
found: https://golang.org/pkg/ "Packages"
i:4, flag:1 urls:[https://golang.org/ https://golang.org/cmd/ https://golang.org/pkg/fmt/ https://golang.org/pkg/os/]
接收到的url:https://golang.org/
接收到的url:https://golang.org/cmd/
接收到的url:https://golang.org/pkg/fmt/
接收到的url:https://golang.org/pkg/os/
found: https://golang.org/pkg/os/ "Package os"
i:3, flag:2 urls:[https://golang.org/ https://golang.org/pkg/]
接收到的url:https://golang.org/
接收到的url:https://golang.org/pkg/
found: https://golang.org/pkg/fmt/ "Package fmt"
i:2, flag:1 urls:[https://golang.org/ https://golang.org/pkg/]
接收到的url:https://golang.org/
接收到的url:https://golang.org/pkg/
*/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号