

包含汉字的字符串截取,及相关
前言:
在含有汉字的字符串中,如何有效截取(根据提供字节数)。例如:针对输入的字符串,根据所提供字节数,截取前一部分。如果截止字符为字母,则保留。如果为汉字的前一字节,则向前退一字节取。ex:"我是ABB" 6,结果为"我是AB";"我是ABB么" 8,结果为"我是ABB"。
因为并没有指定语言(C、C#)。我们假设只有汉字和字母构成。
- 如果用C的话,这将是一道常规题(除了对汉字的处理以外)。
- 如果用C#的话,我想的做法如下:
// Description: 演示字符串中包含汉字的截取
// CopyRight: http://www.cnblogs.com/yangmingming
// Notes: 采用调用函数形式完成
namespace StringCutDemo
{
class Program
{
static void Main(string[] args)
{
string str1 = "我是ABC";
string str2 = "我是ABC么";
string getStr1 = GetString(str1, 4);
string getStr2 = GetString(str2, 6);
Console.WriteLine("get the str1 and str2 is {0},{1}",getStr1 ,getStr2 );
}
public static string GetString(string str, int count)
{
if (!(str[count - 1] >= 'a' && str[count - 1] <= 'z' || str[count - 1] >= 'A' && str[count - 1] <= 'Z'))
return str.Substring(0, count - 1);
else
return str.Substring(0, count );
}
}
}
// CopyRight: http://www.cnblogs.com/yangmingming
// Notes: 采用调用函数形式完成
namespace StringCutDemo
{
class Program
{
static void Main(string[] args)
{
string str1 = "我是ABC";
string str2 = "我是ABC么";
string getStr1 = GetString(str1, 4);
string getStr2 = GetString(str2, 6);
Console.WriteLine("get the str1 and str2 is {0},{1}",getStr1 ,getStr2 );
}
public static string GetString(string str, int count)
{
if (!(str[count - 1] >= 'a' && str[count - 1] <= 'z' || str[count - 1] >= 'A' && str[count - 1] <= 'Z'))
return str.Substring(0, count - 1);
else
return str.Substring(0, count );
}
}
}
然而输出结果,确是:
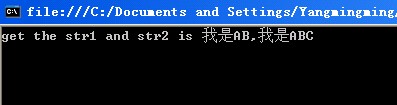
可见,在C#中,传统意义上的ASCII字符由所占一个字节,在这里都已“升级”为2个字节,同汉字拥有一样的字节数。所以这里的用C#的截取方法,将是不正确的!因为Substring(startIndex,count)中的count不是字节数,而是所需获取的元素个数(包含汉字、字母等)了。
所以这题的有效做法,还是用C实现,这样可以实现字母的ASCII码实现,即只占有1个字节。(这里略)
附:C#中不同编码的字节数
同样采用上例,当采用不同编码时,所显示的字节数是不同的。见代码:
// Description: 演示字符串中包含汉字的截取,不同编码的字节数
// CopyRight: http://www.cnblogs.com/yangmingming
// Notes: 采用两种编码方式完成
namespace StringCutDemo
{
class Program
{
static void Main(string[] args)
{
string str1 = "我是ABC";
string str2 = "我是ABC么";
//第一种编码方式:
int str1Count = Encoding.Default.GetByteCount(str1);
int str2Count = Encoding.Default.GetByteCount(str2);
//第二种编码方式:
int str1UnicodeCount = Encoding.Unicode.GetByteCount(str1);
int str2UnicodeCount = Encoding.Unicode.GetByteCount(str2);
Console.WriteLine("The Byte Count of str1 and str2 is {0},{1}",str1Count ,str2Count );
Console.WriteLine("The Byte by Unicoding of str1 and str2 is {0},{1}", str1UnicodeCount, str2UnicodeCount);
}
// CopyRight: http://www.cnblogs.com/yangmingming
// Notes: 采用两种编码方式完成
namespace StringCutDemo
{
class Program
{
static void Main(string[] args)
{
string str1 = "我是ABC";
string str2 = "我是ABC么";
//第一种编码方式:
int str1Count = Encoding.Default.GetByteCount(str1);
int str2Count = Encoding.Default.GetByteCount(str2);
//第二种编码方式:
int str1UnicodeCount = Encoding.Unicode.GetByteCount(str1);
int str2UnicodeCount = Encoding.Unicode.GetByteCount(str2);
Console.WriteLine("The Byte Count of str1 and str2 is {0},{1}",str1Count ,str2Count );
Console.WriteLine("The Byte by Unicoding of str1 and str2 is {0},{1}", str1UnicodeCount, str2UnicodeCount);
}
调试结果如图:
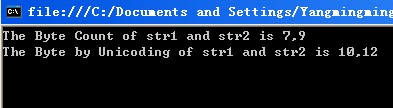
可见,虽然原先的ASCII的单字节在C#中存储为2个字节,但是由于其第二个字节为0,所以当采用不同编码时,所计算的字符串的字节数是不同的。第一种情况,将其字节计为1,第二种计为2。
综述之,由含有汉字的字符串的截取,所延伸至字符编码的相关问题。虽然关于编码,接触甚少,然此次遂完成一窥的效果,呵呵~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号