
数据采集与融合技术实验5
作业①:
要求
熟练掌握 Selenium 查找HTML元素、爬取Ajax网页数据、等待HTML元素等内容。
使用Selenium框架爬取京东商城某类商品信息及图片。
候选网站
http://www.jd.com/
关键词
自由选择
输出信息
MySql输出如下
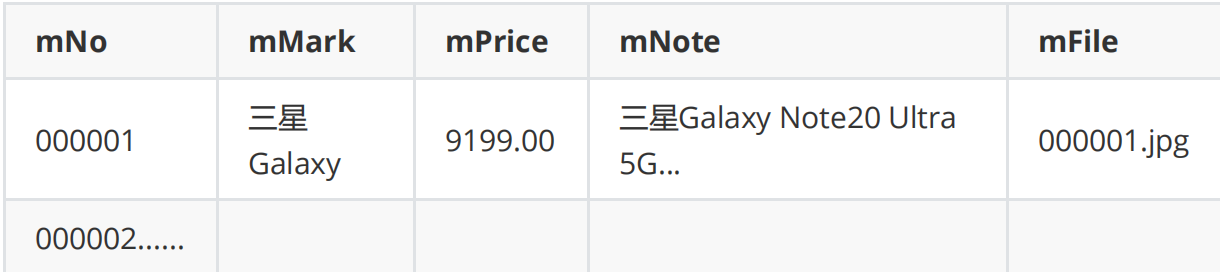
·1爬取图片信息
`
try:
src1 = li.find_element(By.XPATH,
".//div[@class='p-img']//a//img").get_attribute("src")
except:
src1 = ""
try:
src2 = li.find_element(By.XPATH,
".//div[@class='p-img']//a//img").get_attribute(
"data-lazy-img")
except:
src2 = ""
try:
price = li.find_element(By.XPATH,".//div[@class='p-price']//i").text
except:
price = "0"
`
·2解析其他信息
`
try:
note = li.find_element(By.XPATH,
".//div[@class='p-name p-name-type-2']//em").text
mark = note.split(" ")[0]
mark = mark.replace("爱心东东\n", "")
mark = mark.replace(",", "")
note = note.replace("爱心东东\n", "")
note = note.replace(",", "")
`
·3进行图片保存
def download(self, src1, src2, mFile):
page_data = None
if src1:
try:
req = urllib.request.Request(src1, headers=MySpider.headers)
resp = urllib.request.urlopen(req, timeout=10)
data = resp.read()
except:
pass
if not data and src2:
try:
req = urllib.request.Request(src2, headers=MySpider.headers)
resp = urllib.request.urlopen(req, timeout=10)
data = resp.read()
except:
pass
if data:
print("start lowdown", mFile)
fobj = open(MySpider.imagePath + "\\" + mFile, "wb")
fobj.write(data)
fobj.close()
print("download finish", mFile)`
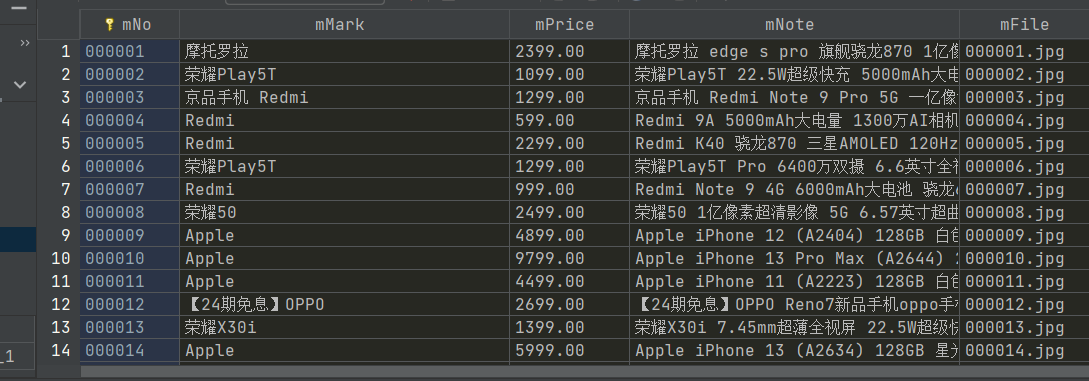
·4结果展示

5gitee链接
第一题
6实验感悟
学习到了如何用selenium和xpath的方法爬取图片并保存本地和数据库,为以后的学习奠定了基础
作业②
要求
熟练掌握 Selenium 查找HTML元素、实现用户模拟登录、爬取Ajax网页数据、等待
HTML元素等内容。
使用Selenium框架+MySQL爬取中国mooc网课程资源信息(课程号、课程名称、教学
进度、课程状态,课程图片地址),同时存储图片到本地项目根目录下的imgs文件夹
中,图片的名称用课程名来存储。
候选网站
中国mooc网:https://www.icourse163.org
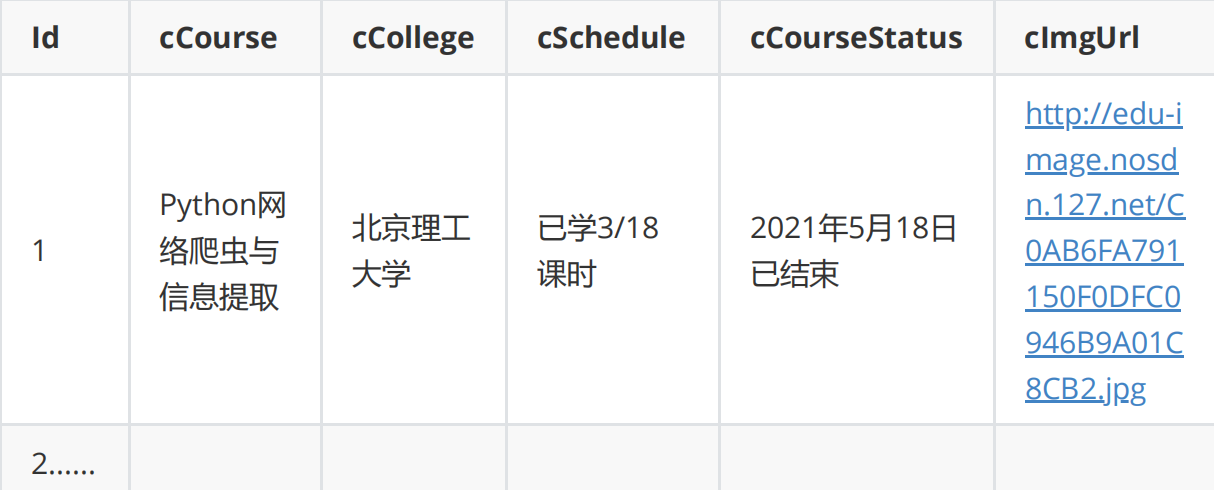
·1创建数据库
`
def openDB(self):
self.con=sqlite3.connect("CourseStatus.db")
self.cursor=self.con.cursor()
try:
self.cursor.execute("create table CourseStatus (Id varchar(16),cCourse "
"varchar(64),cCollege varchar(64),"
"cSchedule varchar(64),"
"cCourseStatus varchar(64),cImgUrl varchar("
"256),"
"constraint pk_course primary key (Id,cCourse))")
except:
self.cursor.execute("delete from CourseStatus")
`
·2编写登录函数
`
def login():
driver.get('https://www.icourse163.org/')
driver.set_window_size(1300, 800)
driver.find_element(By.XPATH,'//div[@class="u-navLogin-loginBox"]//div[@class="unlogin"]/a').click()
time.sleep(20)
`
·3解析网页数据
`
course = div.find_element(By.XPATH,'.//div[@class="title"]//span['
'@class="text"]').text
# 解析院校
college = div.find_element(By.XPATH,'.//div[@class="school"]/a').text
# 解析已学学时
schedule = div.find_element(By.XPATH,'.//div[@class="status"]//span['
'@class="course-progress-text-span"]').text
# 解析课程开设时间
courseStatus = div.find_element(By.XPATH,'.//div['
'@class="course-status"]').text
print(count,course,college,schedule,courseStatus,src_path)
# 数据保存
db.insert(count,course,college,schedule,courseStatus,src_path)
print(str(count) + 'inserted')
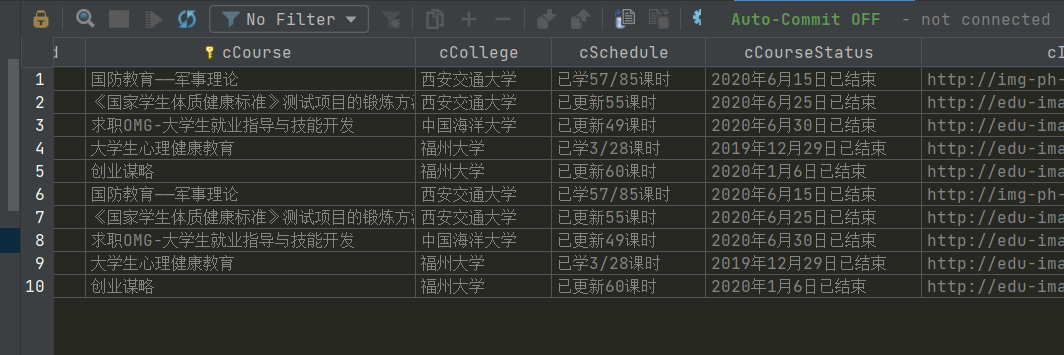
·4结果展示
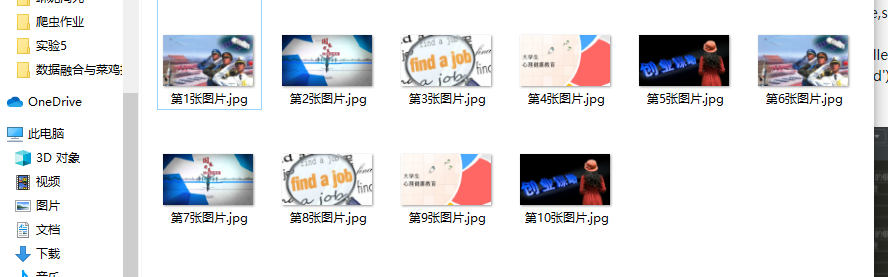
·5gitee链接
第二题
·6心得体会
学会了如何操纵网页驱动器获取登陆后的数据,并且进行图片和信息的获取,进一步熟悉了Selenium框架,Selenium 查找HTML元素、爬取Ajax网页数据。
作业③
要求:理解Flume架构和关键特性,掌握使用Flume完成日志采集任务。
完成Flume日志采集实验,包含以下步骤:
1、任务一:开通MapReduce服务
2、任务二:Python脚本生成测试数据
3、任务三:配置Kafka
4、任务四:安装Flume客户端
5、任务五:配置Flume采集数据
任务一:开通MapReduce服务
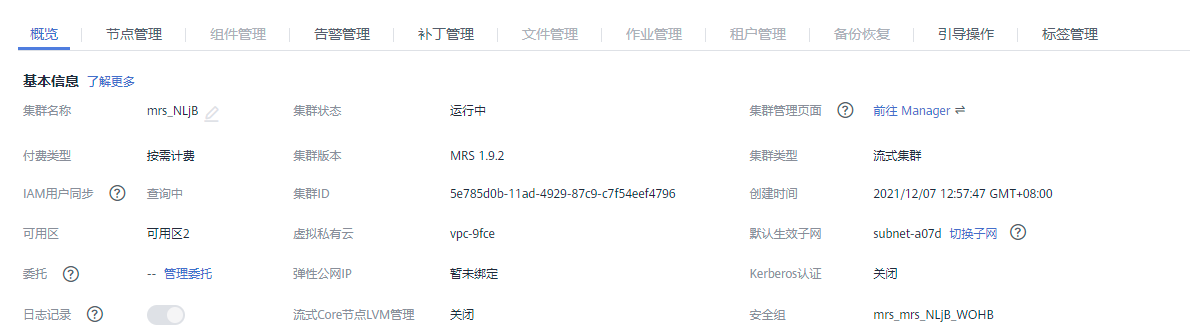
2、Python脚本生成测试数据

查看数据
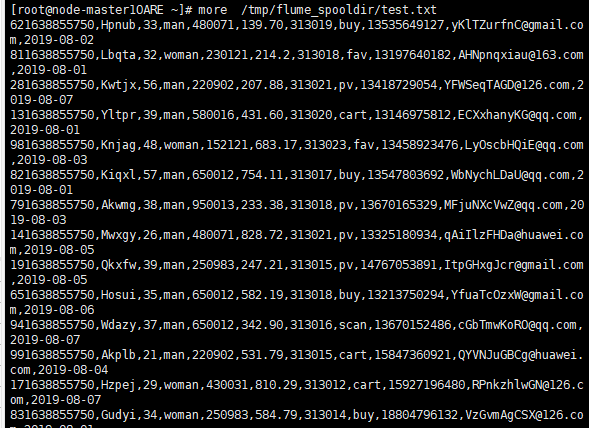
·任务三配置kafka

任务四:安装Flume客户端

任务五:配置Flume采集数据
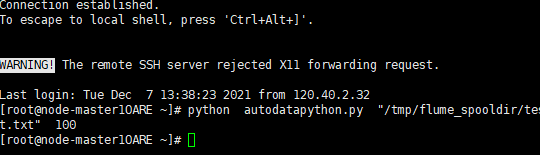

6心得体会
通过此次配置我了解到了华为云与云计算的一些皮毛,为以后的学习奠定了基础
`
