
数据融合与采集技术第一次实验
作业①:
1)大学软工排名信息的爬取
– 要求:用urllib和re库方法定向爬取给定网址https://www.shanghairanking.cn/rankings/bcsr/2020/0812的数据。
| 2020排名 | 全部层次 | 学校名称 | 总分 |
|---|---|---|---|
| 1 | 前2% | 清华大学 | 1661.0 |
部分代码展示:
`
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.82 Safari/537.36"
}
url = urllib.request.Request(url=url, headers=headers)
data = urllib.request.urlopen(url, timeout=10)
data = data.read()
html = data.decode()
此处获取整个网页数据
soup = BeautifulSoup(html, 'html.parser') # 正则匹配内容
findrank = re.compile(r'<divclass="ranking"data-v-68e330ae="">(.?)');findtop = re.compile('<tddata-v-68e330ae="">(.?)')
findname = re.compile('imgalt="(.?)"');findtotal = re.compile('<tddata-v-68e330ae="">(.?)')
`此处用正则表达式匹配需要解析数据
`
def printlist(list):
tplt = "{0:10}\t{1:10}\t{2:8}\t{3:8}\t" #输出格式
print(tplt.format("2020排名", "全部层次", "学校类型", "总分", chr(12288))) #输出表头
tplt = "{0:10}\t{1:10}\t{2:10}\t{3:10}"
for li in list:
rank2020 = li[0]; top = li[1]; name = li[2]; total = li[3]
print(tplt.format(rank2020, top, name, total, chr(12288)))
`此处为打印函数
结果展示
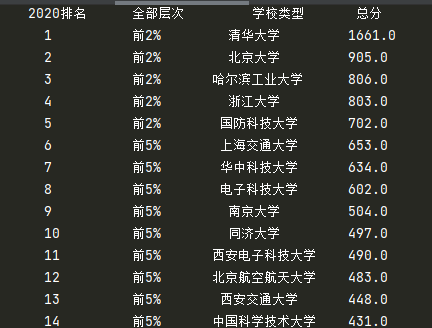
作业1心得体会:通过此题的编写我使得我对爬虫爬取数据有了更深刻感悟,有了更深的自我沉淀与技术革新,让我了解到了网页数据的爬取与输出的方法
作业②
1)城市实时空气质量信息的爬取
– 要求:用requests和Beautiful Soup库方法设计爬取https://datacenter.mee.gov.cn/aqiweb2/AQI实时报。
– 输出信息:
| 序号 | 城市 | AQI | PM2.5 | SO2 | NO2 | CO | 首要污染物 |
|---|---|---|---|---|---|---|---|
| 1 | 北京市 | 55 | 6 | 5 | 1.0 | 225 | ---- |
部分代码展示:

此处获取整个网页信息。
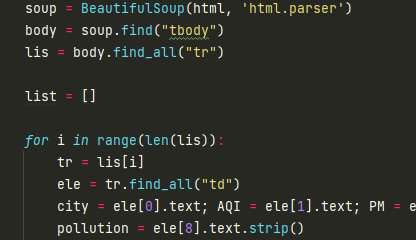
此处解析数据并存储。
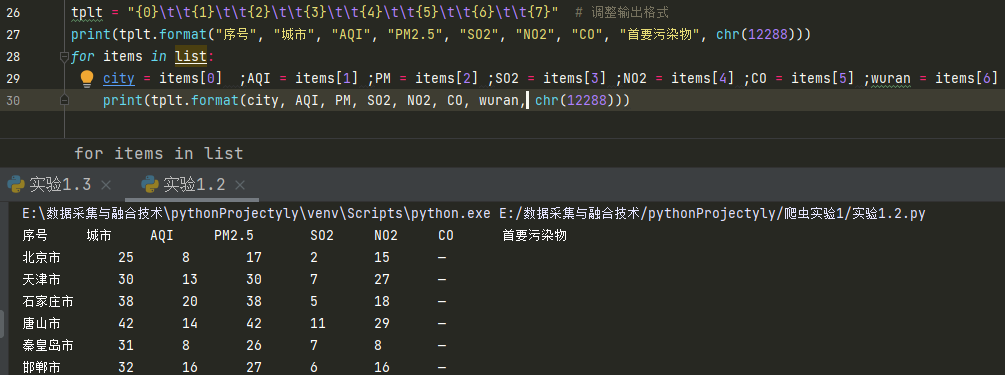
最后打印数据并展示结果。
作业2心得体会:通过此题我更为了解到了beatifulsoup库的使用,对其函数的原理以及构造有了全新的体会
作业③
1)福大新闻网图片的爬取
– 要求:使用urllib和requests和re爬取一个给定网页https://news.fzu.edu.cn/爬取该网站下的所有图片
– 输出信息:将自选网页内的所有jpg文件保存在一个文件夹中
部分代码展示:
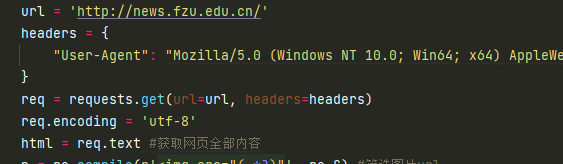
此处获取网页源代码。
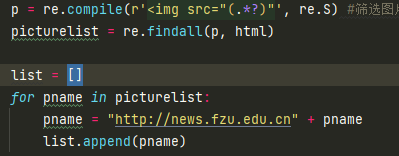
正则匹配抓取图片并保存。
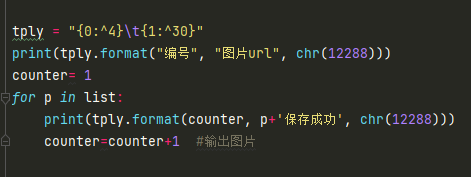
最后输出保存图片名称
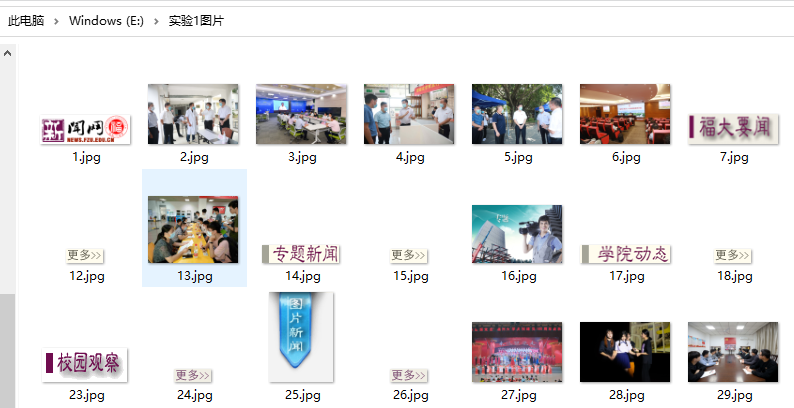
结果展示。
作业三 心得体会
在完成此题过程中我更加深刻了解到了urllib库和re库的用法,并对图片的爬取有了一定的了解,对正则表达式的使用更加灵活,悟通了其精奇之处,对我以后学习大有裨益。
