工作中的点点滴滴-基于redis的一个分布式锁以及对redis的一点儿认识
背景
公司的一套交易系统推广了一段时间了,用户量也逐渐上来了,当用户量起来了,各种奇葩的问题也就接踵而来了。早上来公司刚坐下,产品就说有个客户产生了两笔一样的订单,订单商品和金额都是一样的,并且订单的生产时间都只有几十毫秒的差别。好家伙,打开日志一开,果然在在两台服务器上看到一模一样的订单生成日志,也就是说在同时有两个请求到达了后台服务器,不管是客户急速手动点了两次,还是说LBS流量分派有问题,那种的订单肯定是认为异常订单不应该出现的。
问题解决思路
1.前端提交过来的订单数据因为都是会带有一个购物车Id,也就是说同一个购物车id最多正能生成一个订单。我们在生成订单的时候先用这个购物车id去订单里面查询一下,如果存在了,那么就返回前端当前购物车已经生产订单了。这个方式是通过数据库数据验证来实现的,但是从日志查询情况看,两个订单那生成的时间极度接近,这样就会导致,第一个订单在还没有把数据insert到数据库的时候,第二个订单的请求就到达了服务器,这个时候查询购物车id,在数据是不是就还没有数据,那么第二个订单也就顺理通过验证了。
2.在数据的订单表那里,把购物车id这个字段做成一个唯一索引,这种方式也是最快最便捷的,一句sql语句就可以搞定这个问题了,但是这样的话当并发请求高了数据库的压力就会变得很大,另外就是相对而言效率比较低。
3.通过Redis来实现一个分布式锁,在同时只能有一个购物车id能够进去订单生成的逻辑,基于内存的性能会比数据库的性能会高一些,其次这个把他做成一个通用组件,不仅可以在当前场景来使用,大概思路就是在生产订单的时候,先判断数据库订单表有没有这个购物车id,如果有了,就直接返回前端提示语,如果没有,就看内存中有没有,如果有了就直接返回,如果没有就把把购物车id放入内存,订单生产完毕删除内存。
设计思路
1.作为一个锁,互斥性是一定要保证的,同一时刻只能有一个线程获得锁。
2.就是性能的问题,这也就是为什么要放弃数据库,而用redis这种内存性数据库,不要获取一个锁要几秒钟,或者释放一个锁又得半天。这样系统瓶颈也就不远了,所以这个情况锁的粒度就尽量的小一些。
3.死锁,死锁问题,在数据层面是一个避之不及的问题,所以采用redis锁的时候,一定要加一个过期时间。
代码实现
这里我们用的是Redisson客户端,其实Redisson的api已经实现了大部分锁的功能了,另外在有的场景中,比如锁的失效场景是4s,但是业务逻辑却处理的5s,这样导致了在业务逻辑没有处理完锁就失效了,所以在Redisson中就引入了WatchDog组件,它的作用就是当一个线程 业务还没有执行完,时间就过了,线程还想持有锁的话,就会启动一个watch dog后台线程,不断的延长锁key的生存时间。但是正常这个看门狗线程是不启动的,还有就是这个看门狗启动后对整体性能也会有一定影响,所以不建议开启看门狗。watchDog 只有在未显示指定加锁时间时才会生效,所以如果想不启用,就要设置这个值。 具体来看一下他的锁实现的大体流程是什么样子的。
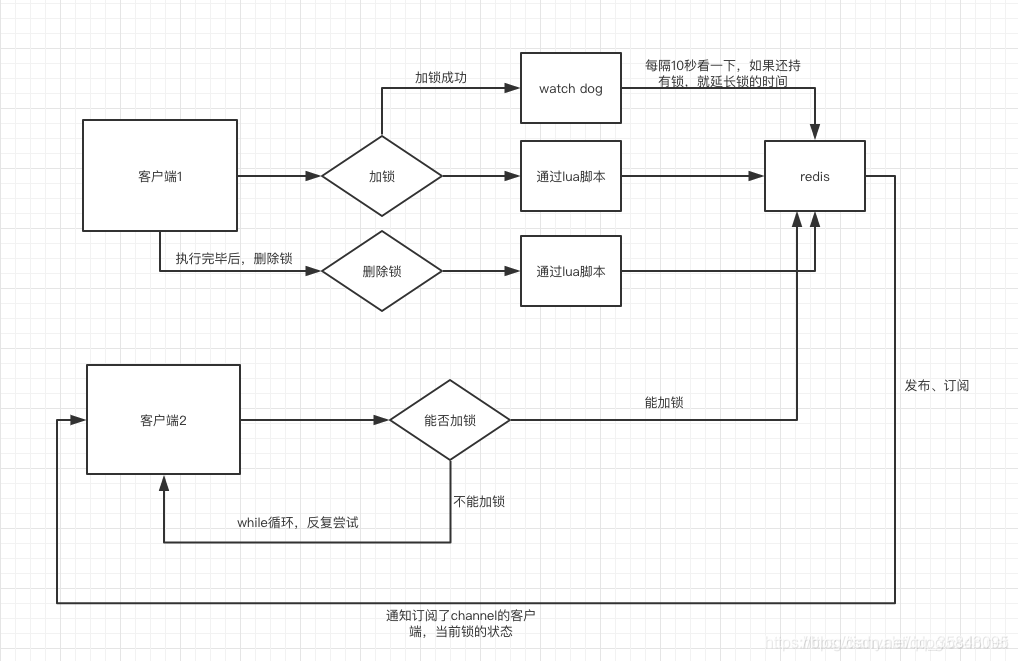
Redisson的所得实现类:
1 @Slf4j
2 public class RedissonLock {
3
4
5 private RedissonManager redissonManager;
6 private Redisson redisson;
7
8
9 public RedissonLock(RedissonManager redissonManager) {
10 this.redissonManager = redissonManager;
11 this.redisson = redissonManager.getRedisson();
12 }
13
14 public RedissonLock() {}
15
16 /**
17 * 加锁操作 (设置锁的有效时间)
18 * @param lockName 锁名称
19 * @param leaseTime 锁有效时间
20 */
21 public void lock(String lockName, long leaseTime) {
22 RLock rLock = redisson.getLock(lockName);
23 rLock.lock(leaseTime,TimeUnit.SECONDS);
24 }
25
26 /**
27 * 加锁操作 (锁有效时间采用默认时间30秒)
28 * @param lockName 锁名称
29 */
30 public void lock(String lockName) {
31 RLock rLock = redisson.getLock(lockName);
32 rLock.lock();
33 }
34
35 /**
36 * 加锁操作(tryLock锁,没有等待时间)
37 * @param lockName 锁名称
38 * @param leaseTime 锁有效时间
39 */
40 public boolean tryLock(String lockName, long leaseTime) {
41
42 RLock rLock = redisson.getLock(lockName);
43 boolean getLock = false;
44 try {
45 getLock = rLock.tryLock(leaseTime, TimeUnit.SECONDS);
46 } catch (InterruptedException e) {
47 log.error("获取Redisson分布式锁[异常],lockName=" + lockName, e);
48 e.printStackTrace();
49 return false;
50 }
51 return getLock;
52 }
53
54 /**
55 * 加锁操作(tryLock锁,有等待时间)
56 * @param lockName 锁名称
57 * @param leaseTime 锁有效时间
58 * @param waitTime 等待时间
59 */
60 public boolean tryLock(String lockName, long leaseTime,long waitTime) {
61
62 RLock rLock = redisson.getLock(lockName);
63 boolean getLock = false;
64 try {
65 getLock = rLock.tryLock( waitTime,leaseTime, TimeUnit.SECONDS);
66 } catch (InterruptedException e) {
67 log.error("获取Redisson分布式锁[异常],lockName=" + lockName, e);
68 e.printStackTrace();
69 return false;
70 }
71 return getLock;
72 }
73
74 /**
75 * 解锁
76 * @param lockName 锁名称
77 */
78 public void unlock(String lockName) {
79 redisson.getLock(lockName).unlock();
80 }
81
82 /**
83 * 判断该锁是否已经被线程持有
84 * @param lockName 锁名称
85 */
86 public boolean isLock(String lockName) {
87 RLock rLock = redisson.getLock(lockName);
88 return rLock.isLocked();
89 }
90
91
92 /**
93 * 判断该线程是否持有当前锁
94 * @param lockName 锁名称
95 */
96 public boolean isHeldByCurrentThread(String lockName) {
97 RLock rLock = redisson.getLock(lockName);
98 return rLock.isHeldByCurrentThread();
99 }
100
101 public RedissonManager getRedissonManager() {
102 return redissonManager;
103 }
104
105 public void setRedissonManager(RedissonManager redissonManager) {
106 this.redissonManager = redissonManager;
107 }
108 }
从这个代码中可以看出,所有的加锁,释放锁的都是对RLock的,那我们就看下一下RLock是个啥东东。

看到Lock是不是就熟悉了很多。相对于Lock,RLock在加锁的方法上面是多了leaseTime属性,因为RLock锁的标识是放在缓存中的一个key,这个key是需要有过期时间的。
这个锁的实现基本上都是基于缓存key+lua来实现原子操作,保证了加锁和释放锁的准确性,我们在来看一下是怎么使用的。
1 /**
2 * 第二个参数就是获取锁需要等待的时间,同时用这个参数也是开启看门狗。
3 */
4 if (redissonLock.tryLock("trylock", 2L, 200L)) {
5 Thread.sleep(500);
6 redissonLock.unlock("trylock");
7 } else {
8 log.info("获取锁失败");
9 }
另外一种就是首先加锁,然后在释放锁的时候先去判断一下锁的是不是当前线程。如果该线程还持有该锁,那么释放该锁。如果该线程不持有该锁,说明该线程的锁已到过期时间,自动释放锁
1 public void testLock() throws Exception {
2 redissonLock.lock("testLock", 20L);
3 Thread.sleep(500);
4 if (redissonLock.isHeldByCurrentThread("testLock")) {
5 redissonLock.unlock("lock");
6 }
7 }
在上面我们有提到lua来保证原子性,那么lua为什么可以保证原子性呢?其实Redis行段lua脚本可以作为一个整体,这样将多条Redis命令写入lua,即可以实现事务的原子性。同时,Redis保证以一种原子性的方式来执行脚本:当lua脚本在执行的时候,不会有其他脚本和命令同时执行。所以也就是很多企业运维redis会禁用脚本执行,因为如果你执行了一个比较慢的脚本的时候,其他的客户端这个时候也要执行一个脚本,那么整个redis性能就会下降。
这个文档是Redission的官方文档,有兴趣可以看看,里面写的挺详细的,参考文档:https://github.com/redisson/redisson/wiki/%E7%9B%AE%E5%BD%95
通过前面对RediSsion的使用体会,我们也老是提到了一个点,就是使用redis可以让程序性能提高,那为什么Redis会让程序性能提高这么多呢?
1首先大家都知道Redis是内存数据库,内存的读写比磁盘要快很多,毕竟内存和磁盘从内部物理结构上也是有很大的区别的,磁盘读写是需要转动磁头到指定位置后才可以开始读写的,而内存是通过电信号转换的,
2在4.0的版本之前是单线的,需要注意的是redis 单线程指的是网络请求模块使用了一个线程,即一个线程处理所有网络请求。避免了多线程上下文切换引起的性能开销,这里为什么会上线文切换回引起性能问题呢?因为每个线程的执行时间段都是cpu来分配的,当前的这个时间段用完了, cpu就会把这个线程挂起,等到下次cpu重新给你分配时间段,这个过程其实是伴随的资源抢占的过程,因为是抢占,所以就会有等过的过程导致执行变慢。那么4.0为什么又引入了多线程呢?这里也需要注意的是,所谓的多线程也只是在某些删除命令上才会使用,比如UNLINK、FLUSHALL ASYNC 和 FLUSHDB ASYNC。当在客户端使用del删除key的操作,如果这个key值达到了几M,甚至几十M,在释放内存的时候并不会几毫秒完成就会阻塞待处理的任务,然而释放内存空间的工作其实可以由后台线程异步进行处理,这也就是 UNLINK 命令的实现原理了。
3.就是IO多路复用,简单理解是在单个线程中通过记录跟踪每一个sock(I/O流) 的状态来管理多个I/O流,在操作系统中,当你的某个socket可读或者可写的时候,系统它可以给你一个通知,这样话,即使是多个sock或者II/O操作都能在一个线程内并发交替地顺序完成任务。
4.就是内部数据结构优化,我们都知道redis对外的数据类型,有string,list,hash,set,zset常用类型,通过encoding成内部数据结构他们分别对应到下面这个表格中,当然自己也可以在redis客户端通过OBJECT ENCODING来验证一下。
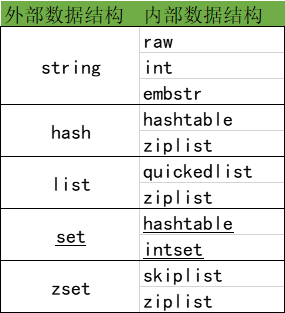
一:首先来说,对于字符串redis的优策略
在redis中,sdshdr类型的变量来存储字符串,在3.2的版本之前,sdshdr数据结果是单一的,主要由len:字符串长度,free:buf中剩余的空间,和buf[]:字符串的内容三个属性。在3.2之后,字符串的类型变得更加丰富了,一共有五种,#####redis根据字符串大小选择合适的数据存储结构,每个类型占用的空间大小也是不一样的。
SDS_TYPE_5因为只有flags+buf,没有free,所以不能动态扩展,所以redis也没有使用sdshdr5这种数据结构,never used。回过头来,我们在看下embstr,我们都知道在一套标准的64位系统中cpu的缓存64byte,而redisObject和sdshdr8正好占用20个字节,所以当业务数据大小在64-20=44字节之内的话,可以利用cpu缓存行特性提高数据新能。这也就是embstr做的事情了。当字符串长度大于44或者使用append追加字符串,那么这时就变成了raw。如果当键值内容可以用一个64位有符号整数表示时,Redis会将键值转换成long类型来存储,并且在在Redis服务启动的时候,预先建立10000个分别存储从0到9999这些数字的redisObject类型变量作为共享对象,如果要设置的字符串键值在这10000个数字内(如SET key1 123)则可以直接引用共享对象而不用再建立一个redisObject了, 虽然整形底层存储encoding是int类型,但是在获取长度计算时会转换为字符串计算长度。
二:对于散列hash的优化策
在redis中散列的内部编码有两种,一个是hashtable,一个是压缩表ziplist。在redis的配置文件中,这两个属性,hash-max-ziplist-entries和hash-max-ziplist-value配合使用来标记什么时候使用ht或者ziplist,当散列的存储个数小于hash-max-ziplist-entries并且每一个对象值都小于hash-max-ziplist-value(单位字节)redis就是用zipList。ziplist是一种紧凑的编码格式,它牺牲了部分读取性能以换取极高的空间利用率,适合在元素较少时使用。该编码类型同样还在列表类型和有序集合类型中使用。
ziplist的数据结构分为5个部分。

1.zlbytes是uint32_t类型, 表示整个结构占用的空间。
2.zltail也是uint32_t类型,表示到最后一个元素的偏移,记录zltail使得程序可以直接定位到尾部元素而无需遍历整个结构,执行从尾部弹出(对列表类型而言)等操作时速度更快。
3.zllen是uint16_t类型,存储的是元素的数量。
4.zlend是一个单字节标识,标记结构的末尾,值永远是255。
5.entryList是元素的列表。
当我们在执行hash命令的时候,删除和插入都需要移动后面的内存数据,而且查找操作也需要遍历才能完 成,可想而知当散列键中数据多时性能将很低,所以不宜将hash-max-ziplist-entries和hash-max- ziplist-value两个参数设置得很大。
三:对于列表的优化粗略中
其内部编码方式有ziplist和quickList,同样在配置文件中可以设置每个ziplist的最大容量和quickList的数据压缩范围,提升数据存取效率。quickList的本质是一个双向链表,并且他的每个元素还是ziplist。
数据结构的表层结构如下:
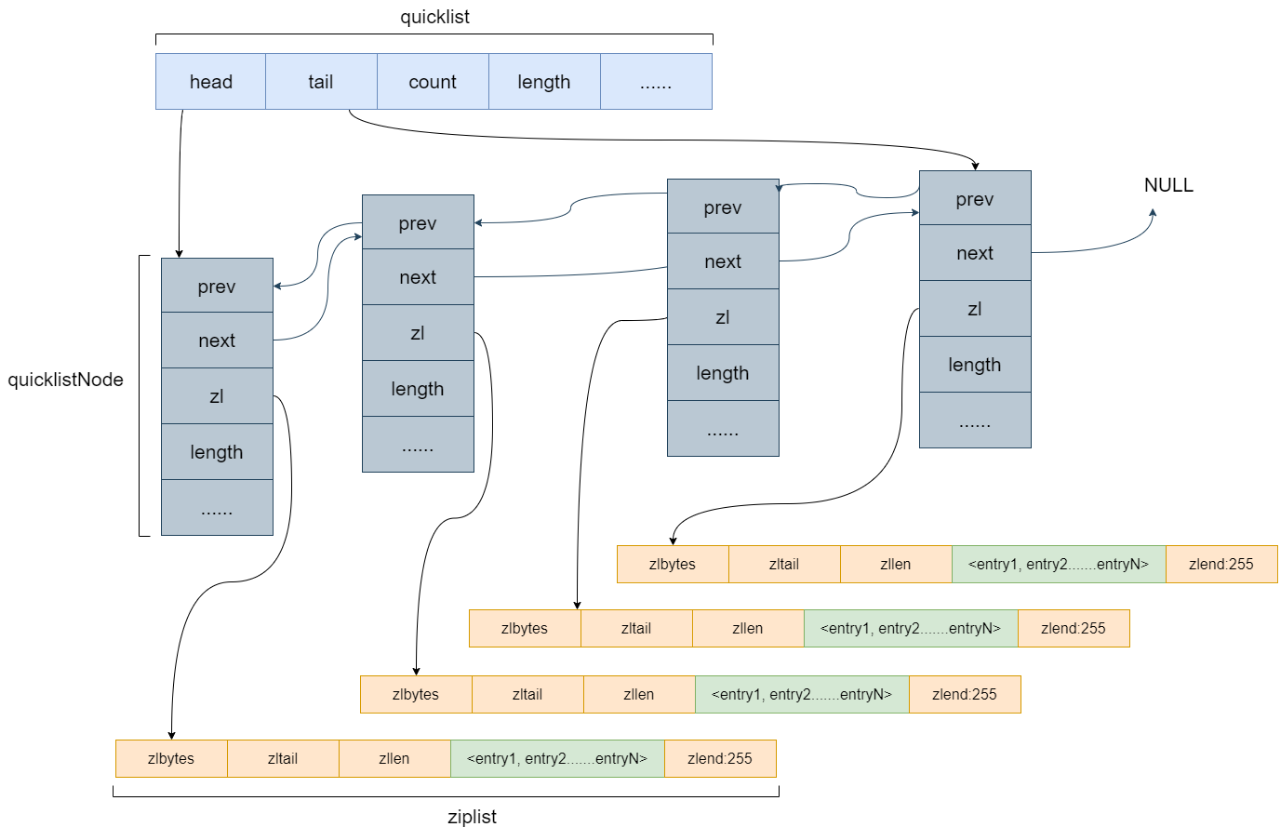
1 typedef struct quicklistNode { 2 struct quicklistNode *prev; /*指向链表前一个节点的指针*/ 3 struct quicklistNode *next; /*指向链表后一个节点的指针*/ 4 unsigned char *zl;/*数据指针。如果当前节点的数据没有压缩,那么它指向一个ziplist结构;否则,它指向一个quicklistLZF结构。*/ 5 unsigned int sz; /*表示zl指向的ziplist的总大小(包括zlbytes, zltail, zllen, zlend和各个数据项)。需要注意的是:如果ziplist被压缩了,那么这个sz的值仍然是压缩前的ziplist大小。/* 6 unsigned int count : 16; /* 表示ziplist里面包含的数据项个数。 */ 7 unsigned int encoding : 2; /* RAW==1(未压缩) or LZF==2 (压缩了并采用LZF压缩算法)*/ 8 unsigned int container : 2; /* 使用的容器 NONE==1 or ZIPLIST==2(默认值) */ 9 unsigned int recompress : 1; /* 我们使用类似lindex这样的命令查看了某一项本来压缩的数据时,需要把数据暂时解压,这时就设置recompress=1做一个标记,等有机会再把数据重新压缩 */ 10 unsigned int attempted_compress : 1; /* node can't compress; too small */ 11 unsigned int extra : 10; /* 其他扩展字段(未使用) */ 12 } quicklistNode; 13 14 typedef struct quicklistLZF { 15 unsigned int sz; /* 表示压缩后的ziplist大小*/ 16 char compressed[]; /*是个柔性数组(flexible array member),存放压缩后的ziplist字节数组/* 17 } quicklistLZF; 18 19 20 typedef struct quicklist { 21 quicklistNode *head; ?/*指向头节点(左侧第一个节点)的指针。*/ 22 quicklistNode *tail; /*指向尾节点(右侧第一个节点)的指针。*/ 23 unsigned long count; /* quicklist节点的个数 */ 24 unsigned int len; /* number of quicklistNodes */ 25 int fill : 16; /* ziplist大小设置,存放list-max-ziplist-size参数的值 */ 26 unsigned int compress : 16; /* 节点压缩深度设置,存放list-compress-depth参数的值 */ 27 }
quicklist的设计是一个空间和时间的折中,双向链表便于在表的两端进行push和pop操作,但是它的内存开销很大,1.每个节点上除了要保存数据之外,还要额外的保存两个指针。2.各个节点是单独的内存块,地址不连续,节点多了容易产生内存碎片。ziplist是一块连续的内存,所以存储效率很高。但是,它不利于修改操作,每次数据变动都会引发内存的realloc重新分配内存。一次realloc可能会导致大量的数据拷贝,进一步降低性能。
quicklist结合了双向链表和ziplist的优点,但是同样也存在一个问题,一个quicklist包含多长的ziplist合适呢?需要找到一个平衡点。
四:在集合类型优化策略中
redis内部使用到了hashtable和intset。当集合中的所有元素都是整数且元素的个数小于配置文件中的set-max-intset-entries参数指定值(默认是512)时Redis会使用intset编码存储该集合,否则会使用 hashtable来存储。
intset数据结构:

其中contents存储的就是集合中的元素值,根据encoding的不同,每个元素占用的字节大小 不同。默认的encoding是INTSET_ENC_INT16(即2个字节),当新增加的整数元素无法使用2个字节表示时,Redis会将该集合的encoding升级为INTSET_ENC_INT32(即4个字节)并调整之前所有元素的位置和长度,同样集合的encoding还可升级为INTSET_ENC_INT64(即8个字节)。 并且contents[]内存储的整数元素是顺序存储的。REDIS_ENCODING_INTSET编码以有序的方式存储元素(所以使用SMEMBERS命令获得的结果是有序的),使得可以使用二分算法查找元素。但是无论是添加还是删除元素,Redis都需要调整后面元素的内存位置,所以当集合中的元素太多时性能较差。当新增加的元素不是整数或集合中的元素数量超过了set-max-intset-entries参数指定值时,Redis会自动将该集合的存储结构转换成hashtable。反过来,当集合元素减少的时候,不会从hasttable转变穿intset哦。
五:最后有序结集合的优化策略
在redis中内部编码有ziplist和skiplist,也同样是通过配置来的,当集合元素个数大于zset-max-ziplist-entries或者单个元素大于zset-max-ziplist-value的时候,都是会使用skiplist。那什么是skiplist的呢?通过字面意思,那么他肯定也还是一个list,那实际上呢它是在有序链表的基础上发展起来的。首先我们来看一下有序链表的结构。

在这样的一个链表中,当我们查找某一个元素,那么就需要从第一个元素按照顺序往后找,也就是说时间复杂度为O(n)。同理在插入数据的时候也需要走一遍这个过程。但是如果我们每相邻两个节点增加一个指针,让指针指向下下个节点。指针连成了一个新的链表,但它包含的节点个数只有原来的一半。

比如,当在查找23的时候:23首先和7比较,再和19比较,比它们都大,继续向后比较。但23和26比较的时候,比26要小,因此回到下面的链表(原链表),与22比较。23比22要大,沿下面的指针继续向后和26比较。23比26小,说明待查数据23在原链表中不存在,而且它的插入位置应该在22和26之间。这个思路就有点儿类似于二分查找了。同理,利用同样的方式,我们可以在上层新产生的链表上,继续为每相邻的两个节点增加一个指针,从而产生第三层链表。当链表足够长的时候,这种多层链表的查找方式能让我们跳过很多下层节点,大大加快查找的速度。
另外除了上面说的这些,redis还有一套自己的内存淘汰策略,来保证在redis中存储的都是热点数据,提高这些热点数据读取的性能。在redis有提供这六种淘汰策略可供客户端使用。

2018.08.19更新
redis位图数据类型
在redis 2.2.0版本之后,新增了一个位图数据,其实它不是一种数据结构。实际上它就是一个一个字符串结构,只不过value是一个二进制数据,每一位只能是0或者1。redis单独对bitmap提供了一套命令。可以对任意一位进行设置和读取。
bitmap的核心命令:SETBIT,
语法:SETBIT key offset value
例如:
setbit abc 5 1 ----> 00001
setbit abc 2 1 ----> 00101
GETBIT,
语法:GETBIT key offset
例如:
getbit abc 5 ----> 1
getbit abc 1 ----> 0
bitmap的其他命令还有bitcount,bitcount,bitpos,bitop等命令。都是对位的操作。因为bitmap的每一位只占据1bit的空间 ,所以利用这个特性我们可以把每一天作为key,value为1亿用户的活跃度状态。假设一个用户一天内只要登录了一次就算活跃。活跃我们就记为1,不活跃我们就记为0。把用户Id作为偏移量(offset)。这样我们一个key就可以存储1亿用户的活跃状态。
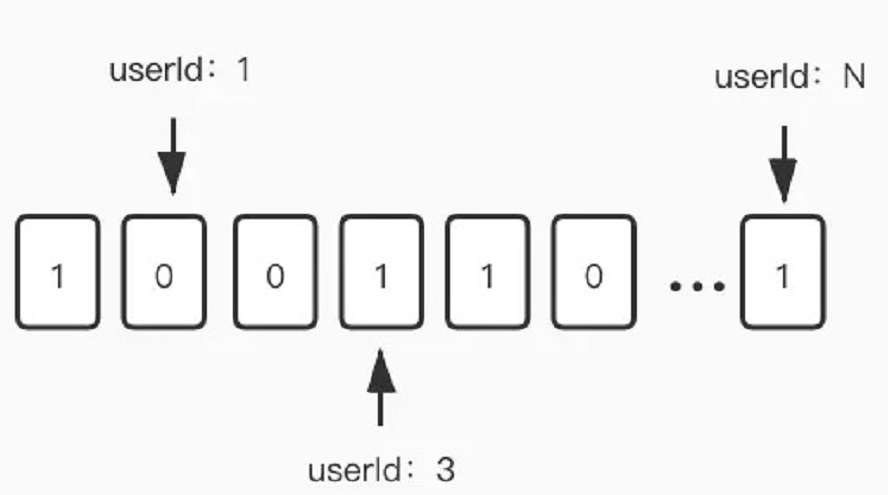
我们再来算下,这样一个位图结构的值对象占据多少空间。每一个位是1bit,一亿用户就是一亿bit。8bit=1Byte,100000000/8/1024/1024=11.92M,我用测试工程往一个key里通过lua塞进了1亿个bit,然后用rdb tools对内存进行统计,一天1亿用户也就消耗12M的内存空间。这完全符合要求。1年的话也就4个G。几年下来的话,redis可以集群部署来进行扩容存储。我们也可以用位图压缩算法对bitmap进行压缩存储。例如WAH,EWAH,Roaring Bitmaps。
我们把每一天1亿用户的登陆状态都用bitmap的形式存进了redis,那要获取某一天id为88000的用户是否活跃,直接使用getbit命令:getbit 2020-01-01 88000 [时间复杂度为O(1)],如果要统计某一天的所有的活跃用户数,使用bitcount命令,bitcount可以统计1的个数,也就是活跃用户数:bitcount 2019-01-01 [时间复杂度为O(N)],如果要统计某一段时间内的活跃用户数,需要用到bitop命令。这个命令提供四种位运算,AND(与),(OR)或,XOR(亦或),NOT(非)。我们可以对某一段时间内的所有key进行OR(或)操作,或操作出来的位图是0的就代表这段时间内一次都没有登陆的用户。那只要我们求出1的个数就可以了。以下例子求出了2019-01-01到2019-01-05这段时间内的活跃用户数。
bitop or result 2019-01-01 2019-01-02 2019-01-03 2019-01-04 2019-01-05 [时间复杂度为O(N)] bitcount result
从时间复杂度上说,无论是统计某一天,还是统计一段时间。在实际测试时,基本上都是秒出的。符合我们的预期。bitmap可以很好的满足一些需要记录大量而简单信息的场景。所占空间十分小。通常来说使用场景分2类:
1.某一业务对象的横向扩展,key为某一个业务对象的id,比如记录某一个终端的功能开关,1代表开,0代表关。基本可以无限扩展,可以记录2^32个位信息。不过这种用法由于key上带有了业务对象的id,导致了key的存储空间大于了value的存储空间,从空间使用角度上来看有一定的优化空间。
2.某一业务的纵向扩展,key为某一个业务,把每一个业务对象的id作为偏移量记录到位上。这道面试题的例子就是用此法来进行解决。十分巧妙的利用了用户的id作为偏移量来找到相对应的值。当业务对象数量超过2^32时(约等于42亿),还可以分片存储。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号