学习笔记-从并发到volatile
前言:
在多线程并发编程的过程中,synchronized和volatile都扮演着重要的角色。其实呢,我们可以把volatile看做是一个轻量级的synchronized。volatile可以保证在多处理器开发中保证了共享变量的“可见性”。当一个线程修改一个共享变量时,另外一个线程能读到这个修改的值。如果volatile变量修饰符使用恰当的话,它比synchronized的使用和执行成本更低,因为它不会引起线程上下文的切换和调度。既然是是线程切换就一定涉及线程状态的保存和恢复,包括寄存器、栈等私有数据。。另外,线程的调度是需要内核级别的权限的(操作CPU和内存),也就是说线程的调度工作是在内核态完成的,因此会有一个从用户态到内核态的切换。而且,不管是线程本身的切换还是特权模式的切换,都要进行CPU的上下文切换。本质上都是从“一段程序”切换到了“另一段程序”,都要设置相应的CPU上下文。每个任务运行前,CPU都需要知道任务从哪里加载、此时的状态、从哪里开始运行,也就是说,需要系统事先帮它设置好CPU寄存器和程序计数器,这些内容就是CPU上下文,这就是cup的开销,也就是为什么说我们要避免cpu的上下文切换。
0x01a3de1d: movb $0×0,0×1104800(%esi);
0x01a3de24: lock addl $0×0,(%esp);
有volatile变量修饰的共享变量进行写操作的时候会多出第二行汇编代码,Lock前缀的指令在多核处理器下会引发了两件事情:1)将当前处理器缓存行的数据写回到系统内存。2)这个写回内存的操作会使在其他CPU里缓存了该内存地址的数据无效。我们都知道java内存模型中,为了提高处理数据,处理器处理数据不是直接和内存通信的,而是把内存中的数据读取到内部缓存中,然后在对其进行操作的,但操作完不知道何时会写到内存。如果对声明了volatile的变量进行写操作,JVM就会向处理器发送一条Lock前缀的指令,将这个变量所在缓存行的数据写回到系统内存。但是,就算写回到内存,如果其他处理器缓存的值还是旧的,再执行计算操作就会有问题。于是乎,就有了第二件事,通过缓存一致性协议,通知到其他线程检查自己的缓存是否失效。这个时候如果失效了就再去内存读取。
我们记得之前的文章有一篇将到单例模式的双重检查的单例中,为什么instance要用volatile修饰。在这里在重新回顾一下。
1 public class DoubleCheckedLocking { // 1 2 private static Instance instance; // 2 3 public static Instance getInstance() { // 3 4 if (instance == null) { // 4:第一次检查 5 synchronized (DoubleCheckedLocking.class) { // 5:加锁 6 if (instance == null) // 6:第二次检查 7 instance = new Instance(); // 7:问题的根源出在这里 8 } // 8 9 } // 9 10 return instance; // 10 11 } // 11 12 }
如果第一次检查instance不为null,那么就不需要执行下面的加锁和初始化操作。因此,可以大幅降低synchronized带来的性能开销。上面代码表面上看起来,似乎两全其美。多个线程试图在同一时间创建对象时,会通过加锁来保证只有一个线程能创建对象。在对象创建好之后,执行getInstance()方法将不需要获取锁,直接返回已创建好的对象。但是我们为什么又说如果不用volatile的时候,有什么问题呢?问题的根源在哪儿呢?
memory = allocate(); // 1:分配对象的内存空间 ctorInstance(memory); // 2:初始化对象 instance = memory; // 3:设置instance指向刚分配的内存地址
memory = allocate(); // 1:分配对象的内存空间 instance = memory; // 3:设置instance指向刚分配的内存地址 // 注意,此时对象还没有被初始化! ctorInstance(memory); // 2:初始化对象
当然,如果在同一个线程里面,这样的执行顺序是没有一点儿问题的,那么我们来看下如果是有两个线程的时候,他们的执行顺序会带来什么问题,这里我用一个简单的图表来标识
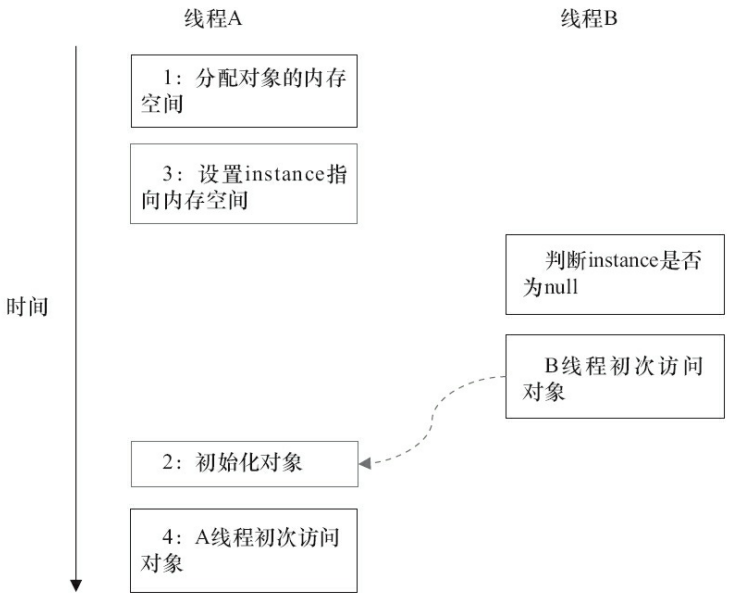
由于单线程内要遵守intra-thread semantics(语义就是,保证重排序不会改变单线程内的程序执行结果),从而能保证A线程的执行结果不会被改变。但是,当线程A和B按上图的时序执行时,B线程将看到一个还没有被初始化的对象。回到本文的主题,DoubleCheckedLocking示例代码的第7行(instance=new Singleton();)如果 发生重排序,另一个并发执行的线程B就有可能在第4行判断instance不为null。线程B接下来将 访问instance所引用的对象,但此时这个对象可能还没有被A线程初始化!下表是这个场景的 具体执行时序。

这里A2和A3虽然重排序了,但Java内存模型的intra-thread semantics将确保A2一定会排在A4前面执行。因此,线程A的intra-thread semantics没有改变,但A2和A3的重排序,将导致线程B在B1处判断出instance不为空,线程B接下来将访问instance引用的对象。此时,线程B将会访问到一个还未初始化的对象。 在知晓了问题发生的根源之后,我们可以想出两个办法来实现线程安全的延迟初始化。1)不允许2和3重排序。2)允许2和3重排序,但不允许其他线程“看到”这个重排序。 当声明对象的引用为volatile后,A2和AA3之间的重排序,在多线程环境中将会被禁止。这样线程B就可以正常的访问到对象了。
1 class VolatileFeaturesExample {
2 volatile long vl = 0L; // 使用volatile声明64位的long型变量
3 public void set(long l) {
4 vl = l; // 单个volatile变量的写
5 }
6 public void getAndIncrement() {
7 vl++; // 复合(多个)volatile变量的读/写
8 }
9 public long get() {
10 return vl; // 单个volatile变量的读
11 }
12 }
1 class VolatileFeaturesExample {
2 long vl = 0L; // 64位的long型普通变量
3 public synchronized void set(long l) {
4 // 对单个的普通变量的写用同一个锁同步
5 vl = l;
6 }
7 public void getAndIncrement() {
8 // 普通方法调用
9 long temp = get();
10 // 调用已同步的读方法
11 temp += 1L;
12 // 普通写操作
13 set(temp);
14 // 调用已同步的写方法
15 }
16 public synchronized long get() {
17 // 对单个的普通变量的读用同一个锁同步
18 return vl;
19 }
20 }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号