工作中的点点滴滴-MySql的索引失效问题
最近的工作内容比较枯燥,就是根据运营小姐姐的需求,给她出一些不同维度的数据报表,那么提到报表,多多少少是离不开数据库写sql的,然后就是各种Left Join 呀,Inner Join 呀,子查询呀。然后在这个过程中,避免不了条件过滤的情况,当数据表的数据量大了起来,那执行一个sql可真的是要了我的老命了。所以这个时候你就要想着怎么去优化这个sql语句了,所以创建添加索引就标的必不可少了。
首先在创建索引的前提是,你应该在哪些字段上去创建索引呢?那说到这里,肯定是需要针对一些需要条件查询的字段去创建索引呀,其实这句话只说对了一半吧。我们在建立索引的时候,首先要pass掉那种频繁修改的字段,因为你在给字段创建索引的时候,其实本质上是在B+树上创建了一个子叶节点,在你更新索引字段的时候,B+树会重建索引,这个过程是非常慢的,并且会伴随着锁表的情况。其次就是区分度不大的那种字段,比如性别这类,因为这种类型的字段建索引意义不大,性能基本上和全表扫描的性能差不多,另外就是mysql的优化器有个默认配置,就是返回数据的比例在30%以外的情况,是不会选择使用索引的,这个30%是一个大概的范围,并不是固定死的。还有一种比较特数据的,就是会有null的这种字段也不合适做索引,虽然说索引是支持null的,但是从规范上讲,null是一种没有意义的对象,可以设置一个默认值来解决这种问题。索引建立好了,并不是放在where后面跟上查询条件就可以使用了,毕竟自己也踩过坑了,要不然也不会有这个笔记的诞生了。
业务表结构和索引展示如下:

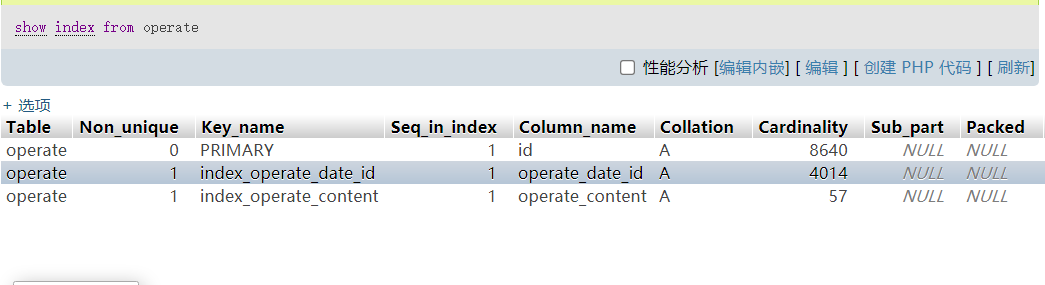
这张数据操作表的原始数据了大概是730w左右,通过数据id来查询的sql的执行计划查看如下:
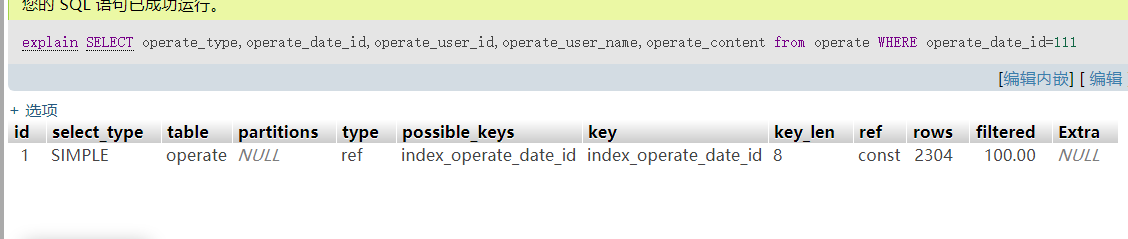
来,我们分析一下这个执行计划先,要看懂执行计划,首先我们要搞懂这每一列的含义。
select_type:查询类型主要有三种,第一种SIMPLE简单查询,这种是最优的查询语句。第二种是PRIMARY子查询,一般是最外层会被标记为PRIMARY。第三种就是联合查询UNION了,一般像Left Join,Inner Join这类查询的。table:查询涉及到的表或者别名。partitions:分区信息,一般为null。type:这一列是我们需要重点照看的字段了,这列是访问类型,也是优化的重点对象,一般这列的结果值从好到不好依次是:system(系统表,少量数据,往往不需要进行磁盘IO)> const (常量连接)> eq_ref (主键索引(primary key)或者非空唯一索引(unique not null)等值扫描)> ref (非主键非唯一索引等值扫描)> range(范围扫描) > index(索引树扫描) > ALL(全表扫描(full table scan)),所以我们常说的sql优化最先就是按照这个指标来优化的。possible_keys:查询可能会用到的索引,这个字段和后面的key有点儿类似。key:执行计划实际上使用到的索引,没有的话就是null。rows:查询结果大致估算出找到所需的记录所需要读取的行数,这个值是越小越好。filtered:和rows类型,所需要查询到的结果行占用读取行的百分比,这个值越大越好。Extra:这列比较特殊,再用到特殊的查询会体现出来,经常用到的有这些值,可以在优化sql的时候考虑进去,using temporary,使用临时表保存中间结果,比如在orderBy或者groupBy的时候。using index,查询语句中使用了覆盖索引-Covering Index时候,效率会比较好,避免访问了数据行。using where使用了where条件的时候。using index condition:虽然命中了索引,但不是所有列都在索引树上需要访问实际的记录行。using join buffer:采用关联查询或者子查询的时候需要进行嵌套循环计算。
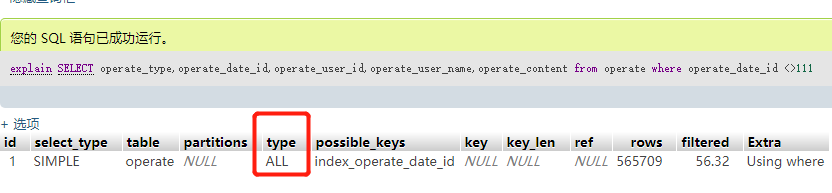
现在我们明白了执行计划了,那么看索引有没有生效,这样就会方便很多了。一:最典型的也是我们经常使用到的不等于<>,type列是All,等于是走了全表扫描。
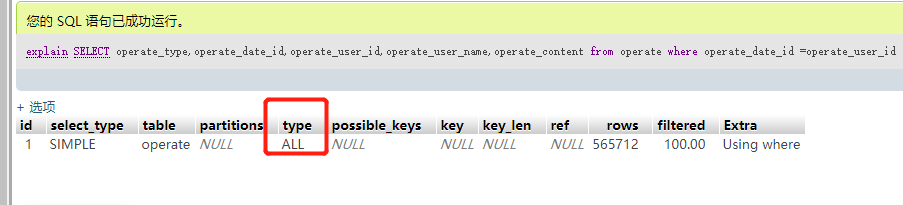
二:列和列相等去做条件查询,比如operate_date_id = operate_user_id,可以看到这种查询也是全表扫描的。
三:通过where in 条件查询,这种查询条件也比较特殊,比如operate_date_id是int类型,然后operate_date_id in ('111')这种是不会走索引的,但是operate_date_id in (111) 却是会走索引的,另外如果where in()的条件多了,也是不会走索引的,所以在使用where in的时候,一定要注意。并且像 not,not in,not exists也都是属于这类似的情况。
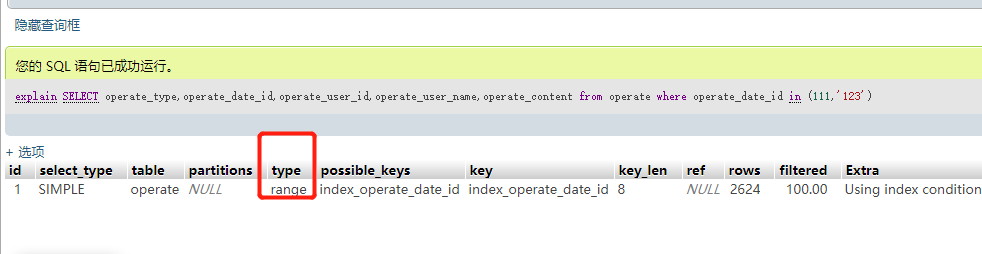
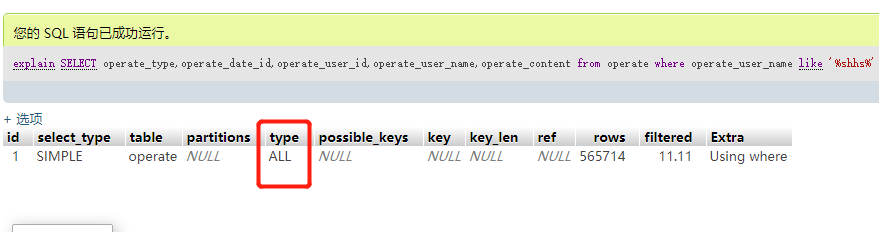
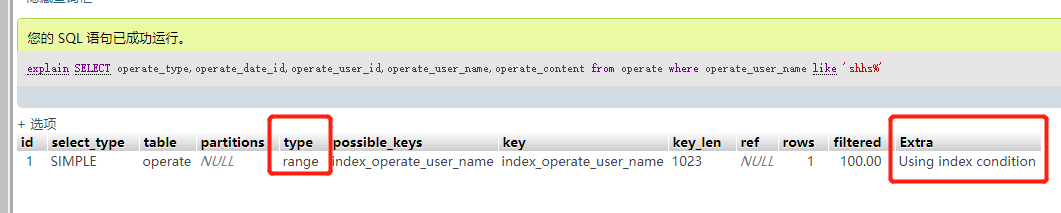
四:like通配符来模糊查询,这种查询也是比较坑,稍不留神就掉坑里了,看下面两个执行计划。当使用模糊搜索时,尽量采用后置的通配符,后匹配可以走INDEX RANGE SCAN。
另外其他的经常我们会在where条件用upper(operate_user_name)='小旭旭宝宝A',这种函数表达式,这样也是会导致索引失效。还有一种比较特殊的 大于小于号和between,通过执行计划你可以发现其实这两种条件的执行计划是一抹一样的。但是呢如果你的mysql版本是>=5.6,在information_schema中的optimizer_trace表,可以跟踪到执行计划的具体步骤,通知cost_for_plan执行计划代价指标来判断,返现大于小于这种情况的代价值往往会比between小(个人感觉不会是绝对的,虽然通过上面的业务表测试了几个类型的字段结果都是一致的,但是官方文档并没有明文支出这两种方法的差异),类似于这种大于小于比较符号,通常优化器,会更具实际查询数据量的比例来判断,如果全表扫描比索引快,则不会走索引。
那么说了索引失效的情况,那具体说为什么索引会失效呢?首先先确认一点就是mysql的索引是以B+树来存储的,那为什么选择B+树,而不是哈希索引或者平衡树,B树呢?
1,对于哈希来说他是无序的,虽然查询快,不能进行范围搜索。
2,平衡二叉树因为他的叶子节点最多拥有两个子节点,这样当数量多了之后,树的深度就会膨胀,查找IO次数多了效率就低了。
3,B+树是相对于B树的一种优化,b+树所有的子节点都能在叶子节点里找见。B+数据的非叶子节点上只会有索引key和指针,他的数据是存储在叶子节点上的。而B数他的索引,指针,数据都在同一个节点上,这样一来,在节点大小一样的情况下,B+树的每个节点上存储的索引相对于B树来说就多了很多,也就是B+ 树是矮胖的,这样有效地减少访问节点次数从而提高性能。
另外,聚集索引的结构和非聚集索引的结构还有一点区别,就是聚集索引的叶子节点存储是的数据记录,而非聚集索引的叶子节点存在的是聚集索引的key,这样一来,如果查询的时候,一不小心就会导致回表操作(下图中红色部分就是回表的路径),需要扫描两个索引树,这个在操作的时候需要尽量避免,就是在查询的字段上只包含索引列。

2019.1.2更新
大表的危害
1、慢查询:很难在短时间内过滤出需要的数据
查询字区分度低 -> 要在大数据量的表中筛选出来其中一部分数据会产生大量的磁盘 io -> 降低磁盘效率
2.对 DDL影响:
建立索引需要很长时间:
MySQL-v<5.5 建立索引会锁表 MySQL-v>=5.5 建立索引会造成主从延迟( mysql建立索引,先在组上执行,再在库上执行)
修改表结构需要长时间的锁表:会造成长时间的主从延迟('480秒延迟')
大事务带来的问题(重要)
1.什么是事务
事务是数据库系统区别于其他一切文件系统的重要特性之一
事务是一组具有原子性的SQL语句,或是一个独立的工作单元
事务要求符合:原子性、一致性、隔离性、持久性
2.事务的 ACID属性
1、原子性( atomicity):全部成功,全部回滚失败。银行存取款。
2、一致性(consistent):银行转账的总金额不变。3、隔离性(isolation):
隔离性等级:
未提交读( READ UNCOMMITED) 脏读,两个事务之间互相可见;已提交读( READ COMMITED)符合隔离性的基本概念,一个事务进行时,其它已提交的事物对于该事务是可见的,即可以获取其它事务提交的数据。可重复读( REPEATABLE READ) InnoDB的默认隔离等级。事务进行时,其它所有事务对其不可见,即多次执行读,得到的结果是一样的!可串行化( SERIALIZABLE) 在读取的每一行数据上都加锁,会造成大量的锁超时和锁征用,严格数据一致性且没有并发是可使用。
查看系统的事务隔离级别: show variables like'%iso%';开启一个新事务: begin;提交一个事务: commit;修改事物的隔离级别: setsession tx_isolation='read-committed';推荐:面试问烂的 MySQL 四种隔离级别,看完吊打面试官!关注Java技术栈微信公众号,在后台回复关键字:mysql,可以获取更多栈长整理的MySQL技术干货。
4、持久性( DURABILITY):从数据库的角度的持久性,磁盘损坏就不行了

redolog机制保证事务更新的一致性和持久性
3. 大事务
运行时间长,操作数据比较多的事务;
风险:锁定数据太多,回滚时间长,执行时间长。
1、锁定太多数据,造成大量阻塞和锁超时;
2、回滚时所需时间比较长,且数据仍然会处于锁定;
3、如果执行时间长,将造成主从延迟,因为只有当主服务器全部执行完写入日志时,从服务器才会开始进行同步,造成延迟。关注Java技术栈微信公众号,在后台回复关键字:mysql,可以获取更多栈长整理的MySQL技术干货。
解决思路:
1、避免一次处理太多数据,可以分批次处理;
2、移出不必要的 SELECT操作,保证事务中只有必要的写操作。
性能优化顺序
-
库结构设计和SQL语句
-
数据库存储引擎的选择和参数配置
-
系统选择及优化
-
硬件升级

 浙公网安备 33010602011771号
浙公网安备 33010602011771号