



Mysql之Mycat
1. 中间件软件介绍
mysql proxy mysql官方
Atlas 奇虎360
DBProxy 美团点评
Amoeba 早期阿里巴巴
cober 阿里巴巴
Mycat 阿里巴巴 官网:http://www.mycat.io/
2. Mycat关键特性
- 支持SQL92标准
- 遵守Mysql原生协议,跨语言,跨平台,跨数据库的通用中间件代理
- 基于心跳的自动故障切换,支持读写分离,支持MySQL主从,以及galera cluster集群
- 支持Galera for MySQL集群,Percona Cluster或者MariaDB cluster
- 基于Nio实现,有效管理线程,高并发问题
- 支持数据的多片自动路由与聚合,支持sum,count,max等常用的聚合函数,支持跨库分页
- 支持单库内部任意join,支持跨库2表join,甚至基于caltlet的多表join
- 支持通过全局表,ER关系的分片策略,实现了高效的多表join查询
- 支持多租户方案
- 支持分布式事务(弱xa)
- 支持全局序列号,解决分布式下的主键生成问题
- 分片规则丰富,插件化开发,易于扩展
- 强大的web,命令行监控
- 支持前端作为mysq通用代理,后端JDBC方式支持Oracle、DB2、SQL Server 、 mongodb 、巨杉
- 支持密码加密
- 支持服务降级
- 支持IP白名单
- 支持SQL黑名单、sql注入攻击拦截
- 支持分表(1.6)
- 集群基于ZooKeeper管理,在线升级,扩容,智能优化,大数据处理(2.0开发版)
3. Mycat工作原理
Mycat的原理中最重要的一个动词是“拦截”,它拦截了用户发送过来的SQL语句,首先对SQL语句做了一些特定的分析:如分
片分析、路由分析、读写分离分析、缓存分析等,然后将此SQL发往后端的真实数据库,并将返回的结果做适当的处理,最终再返回给用户。
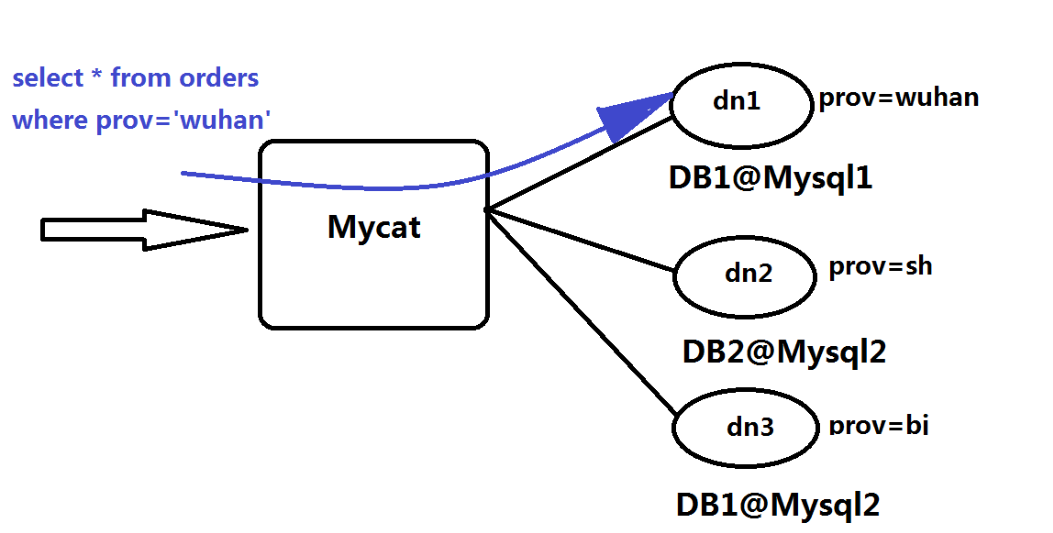
上述图片里,Orders表被分为三个分片datanode(简称dn),这三个分片是分布在两台MySQL Server上(DataHost),即datanode=database@datahost方式,因此你可以用一台到N台服务器来分片,分片规则为(sharding rule)典型的字符串枚举分片规则,一个规则的定义是分片字段(sharding column)+分片函数(rule function),这里的分片字段为prov而分片函数为字符串枚举方式。
当Mycat收到一个SQL时,会先解析这个SQL,查找涉及到的表,然后看此表的定义,如果有分片规则,则获取到SQL里分片字段的值,并匹配分片函数,得到该SQL对应的分片列表,然后将SQL发往这些分片去执行,最后收集和处理所有分片返回的结果数据,并输出到客户端。以select * from Orders where prov=?语句为例,查到prov=wuhan,按照分片函数,wuhan返回dn1,于是SQL就发给了MySQL1,去取DB1上的查询结果,并返回给用户。
如果上述SQL改为select * from Orders where prov in (‘wuhan’,‘beijing’),那么,SQL就会发给MySQL1与MySQL2去执行,然后结果集合并后输出给用户。但通常业务中我们的SQL会有Order By 以及Limit翻页语法,此时就涉及到结果集在Mycat端的二次处理,这部分的代码也比较复杂,而最复杂的则属两个表的Jion问题,为此,Mycat提出了创新性的ER分片、全局表、HBT(Human Brain Tech)人工智能的Catlet、以及结合Storm/Spark引擎等十八般武艺的解决办法。
4. Mycat应用场景
- 单纯的读写分离,此时配置最为简单,支持读写分离,主从切换;
- 分表分库,对于超过1000万的表进行分片,最大支持1000亿的单表分片;
- 多租户应用,每个应用一个库,但应用程序只连接Mycat,从而不改造程序本身,实现多租户化;
- 报表系统,借助于Mycat的分表能力,处理大规模报表的统计;
- 替代Hbase,分析大数据;
- 作为海量数据实时查询的一种简单有效方案,比如100亿条频繁查询的记录需要在3秒内查询出来结果,除了基于主键的查询,还可能存在范围查询或其他属性查询,此时Mycat可能是最简单有效的选择;
- Mycat长期路线图;
- 强化分布式数据库中间件的方面的功能,使之具备丰富的插件、强大的数据库智能优化功能、全面的系统监控能力、以及方便的数据运维工具,实现在线数据扩容、迁移等高级功能;
- 进一步挺进大数据计算领域,深度结合Spark Stream和Storm等分布式实时流引擎,能够完成快速的巨表关联、排序、分组聚合等 OLAP方向的能力,并集成一些热门常用的实时分析算法,让工程师以及DBA们更容易用Mycat实现一些高级数据分析处理功能。
- 不断强化Mycat开源社区的技术水平,吸引更多的IT技术专家,使得Mycat社区成为中国的Apache,并将Mycat推到Apache
基金会,成为国内顶尖开源项目,最终能够让一部分志愿者成为专职的Mycat开发者,荣耀跟实力一起提升。
5. Mycat不适合的应用场景
- 设计使用Mycat时有非分片字段查询,请慎重使用Mycat,可以考虑放弃!
- 设计使用Mycat时有分页排序,请慎重使用Mycat,可以考虑放弃!
- 设计使用Mycat时如果要进行表JOIN操作,要确保两个表的关联字段具有相同的数据分布,否则请慎重使用Mycat,可以考虑放弃!
- 设计使用Mycat时如果有分布式事务,得先看是否得保证事务得强一致性,否则请慎重使用Mycat,可以考虑放弃!
6. 安装mycat
1. 运行环境
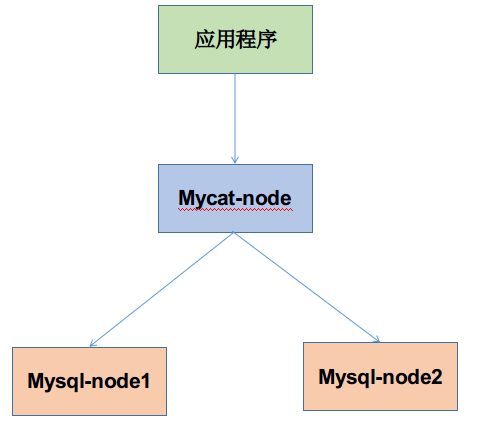
服务器主机名 ip 说明 Mycat-node 192.168.10.210 mycat服务器,连接数据库时,连接此服务器 Mysql-node1 192.168.10.205 物理数据库1,真正存储数据的数据库,这里为Master主数据库 Mysql-node2 192.168.10.206 物理数据库2,真正存储数据的数据库,这里为Slave主数据库 三台机器分布修改主机名,并做hosts绑定 # vim /etc/hosts 192.168.10.205 Mysql-node1 192.168.10.206 Mysql-node1 192.168.10.210 Mycat-node 为方便做实验,关闭三台机器的iptables防火墙和selinux
1. 配置java环境
2. 搭建node1和node2的主从复制关系,略
2. 安装mycat
1. 下载mycat
wget http://dl.mycat.io/1.6-RELEASE/Mycat-server-1.6-RELEASE-20161028204710-linux.tar.gz
tar -zxvf Mycat-server-1.6-RELEASE-20161028204710-linux.tar.gz
mv mycat /usr/local/
2. mycat目录如下
bin mycat命令,启动、重启、停止等 catlet catlet为Mycat的一个扩展功能 conf Mycat 配置信息,重点关注 lib Mycat引用的jar包,Mycat是java开发的 logs 日志文件,包括Mycat启动的日志和运行的日志。
3. mycat常用配置文件
配置文件都放在conf目录下
server.xml Mycat的配置文件,设置账号、参数等 schema.xml Mycat对应的物理数据库和数据库表的配置 rule.xml Mycat分片(分库分表)规则
4. 配置mycat
1. /usr/local/mycat/conf/server.xml 配置账号,一个用来web app连接mycat,一个用来mycat连接mysql。
<user name="root">
<property name="password">123456</property>
<property name="schemas">yangjianbo</property>
<!-- 表级 DML 权限设置 -->
<!--
<privileges check="false">
<schema name="TESTDB" dml="0110" >
<table name="tb01" dml="0000"></table>
<table name="tb02" dml="1111"></table>
</schema>
</privileges>
-->
</user>
<user name="user">
<property name="password">user</property>
<property name="schemas">yangjianbo</property>
<property name="readOnly">true</property>
</user>
root用户用来web app连接mycat,schemas用来指定与schema.xml连接的名称。
user用户用来mycat连接mysql库
2. /usr/local/mycat/conf/schema.xml 读写分离,分库分表,分片节点都是在这个文件配置
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<schema name="yangjianbo" checkSQLschema="false" sqlMaxLimit="100" dataNode="dn1">
</schema>
<dataNode name="dn1" dataHost="dbpool" database="student" />
<dataHost name="dbpool" maxCon="1000" minCon="10" balance="3"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<!-- can have multi write hosts -->
<writeHost host="master" url="192.168.1.37:3306" user="user_write" password="321">
<readHost host="read189" url="192.168.1.189:3306" user="user_read" password="321" />
<readHost host="read44" url="192.168.1.44:3306" user="user_read" password="321" />
</writeHost>
</dataHost>
</mycat:schema>
定义dataNode的名称
定义dataHost的名称
定义哪个数据库
定义写数据库
定义读数据库
参数配置:
balance=0 不开启读写分离,所有读操作都发送到当前可用的writeHost上。
balance=1 开启读写分离,全部的readhost与备用master都参与select语句的负载均衡。
balance=2 所有读操作都随机的在writeHost和readHost上分发
balance=3 所有读请求随机的分发到writeHost对应的readHost上,writeHost不负担读压力,注意balance=3只在1.4及其以后版本有。
writeType="0" 所有写操作都指向第一个writeHost,第一个挂了以后切换到第二个writeHost,重新启动后已切换后的为准。
writeType="1" 所有写操作随机发送到配置的writeHost,1.5以后废弃。
4. mysql主从复制集群的配置
1. 设置写账号。
grant select,insert,update,delete on test.* to user_write@"192.168.1.%" identified by '123';
grant select,insert,update,delete on test.* to user_write@"localhost" identified by '123';
2. 设置读账号。
grant select on test.* to user_read@"192.168.1.%" identified by '321';
grant select on test.* to user_read@"localhost" identified by '321';
5. 启动mycat
/usr/local/mycat/bin/mycat start
6. mycat测试
1. 在一台机器上,安装mysql客户端,然后使用命令:
mysql -h 192.168.1.77 -uroot -p -P8066
show databases; 显示是逻辑库的名称 yangjianbo
use yangjianbo;
show tables; 显示的是真实的表名
2. 在客户端上,再开启一个窗口,打开9066端口,
mysql -h 192.168.1.77 -uroot -p -P9066
show @@datasourc;
3. 在8066上,查询一下表,在9066上看到结果,read_load会在两台slave上增加。

4. 在8066上,插入数据,在9066看到结果,write_load会在master上增加。

5. 说明读写分离已经实现。
bin mycat命令,启动、重启、停止等catlet catlet为Mycat的一个扩展功能conf Mycat 配置信息,重点关注lib Mycat引用的jar包,Mycat是java开发的logs 日志文件,包括Mycat启动的日志和运行的日志。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号