


MongoDB之基础与架构
1. MongoDB的特点
1. 数据文件存储格式为BSON
2. 面向集合存储,易于存储对象类型和JSON形式的数据
3. 模式自由
一个集合中可以存储一个键值对的文档,也可以存储多个键值对的文档,还可以存储键不一样的文档
4. 支持动态查询
5. 完整的索引支持
6. 支持复制和故障恢复
7. 二进制数据存储
可以将图片文件甚至视频转换成二进制的数据存储
8. 自动分片
9. 支持多种语言
C,C++,C#,Java,Perl,PHP,Python,Ruby,Scala等开发语言
10. 使用内存映射存储引擎
MongoDB会占用所有能用的内存
2. MongoDB适用的场景
1. 适用于迭代更新快,需求变更多,以对象数据为主的网站应用
2. MongoDB也是内存型数据库
3. 大尺寸低价值的数据
4. 高伸缩性的场景
5. 用于对象及JSON数据的存储
3. MongoDB不适用的场景
1. 高度事务性的系统
2. 传统的商业智能应用
3. 使用SQL方便
4. MongoDB的结构
1. 数据库
1. 数据库的层次
一个MongoDB服务器实例可以承载多个数据库,数据库之间是完全独立的。
每个数据库有独立的权限控制,在磁盘上不同的数据库放置在不同的文件中。
一个应用的所有数据建议存储在同一个数据库中
2. 数据库的命名
不能是空字符串
不能含有空格,点,$,/ , \ ,\0
全部小写
最多64字节
3. 自带数据库
1. admin
在admin数据库中添加的用户会有管理数据库的权限。一些特定的服务器端命令也只能从这个数据库运行
2. local
这个数据库永远不会被复制,可以用来存储限于本地单台服务器的任意集合
3. config
当mongo用于分片设置,用于保存分片的相关信息
2. 集合
1. 集合的特点
无模式
2. 集合命名
不能是空字符串
不能含有\0
不能以system开头
不能有$
3. 子集合
使用.进行分开命名
集合名称.子集合名称
3. 文档
1. 文档的特点
每一个文档都有一个特殊的键"_id",它在文档所处的集合中是唯一的
文档中的键值对是有序的,前后顺序不同就是不同的文档
文档中的键值对,值可以是字符串,数值,日期等数据类型
文档的键值对区分大小写
文档的键值对不能用重复的键(同一个文档中,不会出现键一样的情况,以最后一个键的值为准)
2. 文档的命名
不能有\0
不能有.和$
不能以_开头
4. 固定集合
性能出色且有固定大小的集合,可以想象为一个环形队列
1. capped的特点
对固定集合插入速度极快
按照插入顺序的查询输出速度极快
能够在插入最新数据时,淘汰最早的数据
可以插入及更新,但更新不能超出collection的大小
不允许删除,但是可以调用drop()删除集合中的所有行
2. capped应用场景
存储日志信息
缓存一些少量的文档
5. MongoDB的数据类型
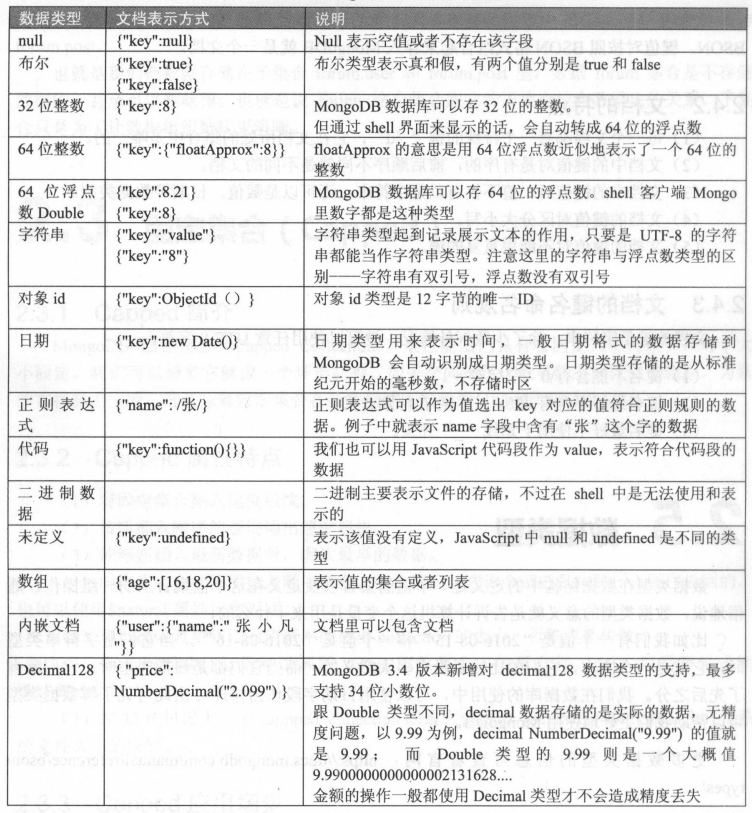
_id mongodb中的文档的唯一标识,每个文档必须有_id键
ObjectId mongodb特有的数据类型
使用12字节的存储空间

二进制类型
可以存储小文件,如:图片,视频,文件资料
6. MongoDB的存储引擎
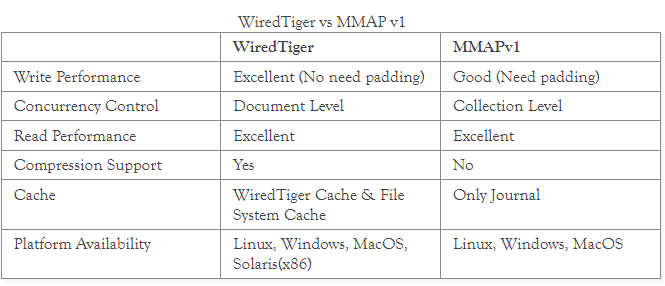
1. WiredTiger Storage Engine
从MonoDB3.2开始,默认的引擎就是WiredTiger Storage Engine.
特点:
1. 文档级别并发
多个客户端可以同时修改同一个集合的不同文档。多个客户端修改同一个文档时,必须以序列化方式执行,这意味着,如果该文档正在被修改,其他写操作必须等待,直到在该文档上的 写操作完成之后,其他写操作相互竞争,获胜的写操作在该文档上执行修改操作。对于大多数读写操作,WiredTiger使用乐观并发控制(optimistic concurrency control),只在Global,database和Collection级别上使用意向锁(Intent Lock),如果WiredTiger检测到两个操作发生冲突时,导致MongoDB将其中一个操作重新执行,这个过程是系统自动完成的。
2. 快照和检查点
快照就是创建检查点那个时间点的内存中数据的视图
检查点将内存中的数据写入到磁盘中。
检查点每60s执行一次或达到产生2GB的Journal文件。(早期版本)
检查点每60s执行一次(从3.6开始)
新的检查点没有建立成功之前,保留上一个成功的检查点。
不开启journaling,只能恢复到上一次检查点;开启journaling,可以恢复到故障点
从mongodb4.0开始,必须开启journaling
3. 日志(journaling)
更新数据之前,先将操作日志更新到日志文件。
每100毫秒更新日志到硬盘的日志文件中。
使用内存缓存区日志文件,最大128KB.
在data目录下有一个子目录Journal目录。
Journal文件的命名规则:WiredTigerLog.0000000001
文件最大为100M,满了再创建一个新的。
如果文件小于128字节,就不压缩。
自动删除Journal文件,只保留上一个checkpoint所需要的Journal文件。
4. 压缩
WiredTiger压缩所有集合和索引,减小存储空间,但是占用CPU.
默认情况下,WiredTiger使用块压缩算法来压缩集合,使用前缀压缩算法来压缩索引。
Journal日志文件也是被压缩的。
5. 内存
2. MMAPv1 Storage Engine(3.2之前默认)
MMAP的全称是Map files into Memory, 使用了一种将磁盘上的文件映射到内存的技术。
1. journal
写入数据时, 首先会将数据写入到内存, 然后每隔60秒会将内存中的数据写入磁盘。而写入磁盘前, 会以每100毫秒一条的速度将数据先写入Journal, 然后再写入磁盘。换言之, 当数据写入Journal之后, 即使数据库挂掉, 也可以从Journal中恢复数据。但是和WiredTiger不同的是, 如果你既没有用Replica Set, 也没有用Journal, 那么很有可能会出现在数据写入磁盘的过程中服务器挂掉, 而导致数据不完整, 而此时, 是无法恢复到正常状态的!2. 锁
MMAP使用Multiple Readers and Single Writer Lock来保证数据一致性。当多个Reader在读数据时, 所有的Writer就都无法工作。而一个Writer在写数据时, 不仅完全不允许其他Writer进行操作, 连其他Reader都不允许读数据
3. In-Memory Storage Engine
1. 并发
in-memory内存存储引擎将文档级并发控制用于写入操作。 因此,多个客户端可以同时修改集合的不同文档。
2. 内存使用
默认使用物理内存的50%减去1GB.
这是数值可以设置的,通过参数或者配置文件。
如果一个写操作的数据,超出内存设置的大小,会有报错,如下:"WT_CACHE_FULL: operation would overflow cache"
3. 持久性
由于In-Memory 存储引擎不会持久化存储数据,只将数据存储在内存中,读写操作直接在内存中完成,不会将数据写入到Disk文件中,因此,不需要单独的日志文件,不存在记录日志和等待数据持久化的问题,当MongoDB实例关机或系统异常终止时,所有存储在内存中的数据都将会丢失。
4. WT与MMAPv1的比较


 浙公网安备 33010602011771号
浙公网安备 33010602011771号