


Kafka之安装配置
1. 简介
1. 简述特性
1. 能够允许发布和订阅流数据
2. 存储流数据时提供相应的容错机制
3. 当流数据到达时能够被及时处理
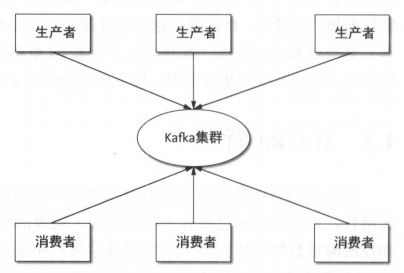
2. 基本机构
生产者负责生产消息,将消息写入kafak集群;消费者从kafka集群中拉取消息。
3. 基本概念
1. 主题
kafka将一组消息抽象归纳为一个主题。生产者将消息发送到特定主题,消费者订阅主题或主题的某些分区进行消费
2. 消息
kafka通信的基本单位,由一个固定长度的消息头和一个可变长度的消息体构成
3. 分区和副本
每个主题分成一个或多个分区
每个分区在物理上对应一个文件夹,分区的命名规则为主题名称后接"--"连接符,后接分区编号。编号从0开始,最大值为分区的总数减1.
每个分区有一个或多个副本
4. Leader副本和Follower副本
kafka会选择分区的一个副本作为Leader副本,其它就为Follower副本
Leader负责处理客户端读写请求,Follwer从Leader同步数据
Leader失效,通过相应的选举算法将从其他Follwer副本选出新的Leader副本
5. 偏移量
任何分布到分区的消息会被直接追加到日志文件的尾部,而每条消息在日志文件中的位置都会对应一个按序递增的偏移量。
6. 日志段
日至对象分别的最小单位
一个日志段对应磁盘上的一个具体日志文件和两个索引文件
7. 代理
每一个kafka实例称为代理
每个代理都有唯一的标识id,是一个非负整数
8. 生产者
生产者负责将消息发送给代理,也就是向kafka代理发送消息的客户端
9. 消费者和消费组
消费者以拉取方式获得数据
每个消费者都属于一个特定消费组,可以为每个消费者指定一个消费组,以groupId代表消费组名称,通过group.id配置设置。如果不指定消费组,默认属于test-consumer-group.
每个消费者也有一个全局唯一的id,通过client.id指定,如果没有指定,kafka会自动为消费者生成一个全局唯一的id,格式为${groupId}-${hostName}-${timestamp}-${UUID前8位字符}
一个主题下的一条消息,只能被同一个消费组下的某一个消费者消费;但是不同消费组的消费者可以同时消费该消息。
消费组是kafka用来实现对一个主题消息进行广播和单播的手段,实现消息广播只需指定各消费者属于不同的消费组,消息单播只需要让各消费者属于同一个消费组
10. ISR
Kafka在zookeeper中动态维护了一个ISR,保存同步的副本列表,该列表保存的是与Leader副本保持消息同步的所有副本对应的代理节点id,如果一个Follower副本宕机或是落后太多,则该Follower副本节点将从ISR列表中移除
11. zookeeper
kafka利用zookeeper保存相应元数据信息
元数据信息:代理节点信息,kafka集群信息,旧版消费者信息及其消费偏移量信息,主题信息,分区状态,分区副本分配方案信息,动态配置信息
zookeeper负责管理维护kafka集群,同时通过zookeeper我们能够方便地对kafka集群进行水平扩展及数据迁移
4. 应用场景
1. 具有高吞吐量来支持诸如实时的日志集这样的大规模事件流
2. 能够很好地处理大量积压的数据,能够周期性地加载离线数据进行处理
3. 能够低延迟处理传统消息应用场景
4. 能够支持分区,分布式,实时地处理消息,同时具有容错保障机制
5. 具体特性
1. 消息持久化
kafka选择文件系统来存储数据
kafka提供了相关配置让用户自己决定消息要保存多久
2. 高吞吐量
kafka支持每秒数百万级别的消息
kafka将数据写到磁盘,充分利用磁盘的顺序读写
kafka在数据写入及数据同步采用了零拷贝技术,采用sendFile()函数调用,sendFile()函数实在两个文件描述符之间直接传递数据,完全在内核中操作,操作效率极高
3. 扩展性
依赖zookeeper对集群进行协调管理,更容易进行水平扩展
4. 多客户端支持
提供了多种开发语言的接入
kafka与当前主流的大数据框架都能很好地集成,如:Flume,Hadoop,HBase,Hive,Spark,Storm
5. kafka streams
用java语言实现的用于流处理的jar文件
6. 安全机制
通过SSL和SASL,支持生产者,消费者与代理连接时的身份认证
支持代理与zookeeper连接身份验证
通信时数据加密
客户端读写权限认证
kafka支持与外部其它认证授权服务的集成
7. 数据备份
可以为每个主题指定副本数,对数据进行持久化备份
8. 轻量级
代理是无状态的
9. 消息压缩
支持Gzip,Snappy,LZ4压缩方式
6. 应用实战场景
1. 消息系统
2. 应用监控
kafka+ELK
3. 网站用户行为追踪
4. 流处理
5. 持久性日志
2. kafka安装配置
1. 基础环境配置
1. jdk安装配置
2. ssh免密钥配置
3. zookeeper安装配置
2. 安装kafka集群
1. 下载安装包
官网地址: https://kafka.apache.org/downloads.html
wget https://archive.apache.org/dist/kafka/2.1.0/kafka_2.12-2.1.0.tgz
2. 解压并设置软链接
tar -zxvf kafka_2.12-2.1.0.tgz -C /usr/local
ln -s /usr/local/kafka_2.12-2.1.0 /usr/local/kafka
3. 授权给某个用户
chown -R hadoop.hadoop kafka_2.12-2.1.0
4. 配置kafka集群
在master节点上配置config/server.properties文件
broker.id=0 host.name=master zookeeper.connect=master:2181,datanode1:2181,datanode2:2181
5. 将config/server.properties文件复制到其它节点
scp config/server.properties root@172.16.1.230:/usr/local/kafka/config/
6. 配置其它节点,只需要修改broker.id和host.name即可
3. 启动kafka集群
分别在master和其它节点,执行命令: nohup /usr/local/kafka/bin/kafka-server-start.sh /usr/local/kafka/config/server.properties &
4. 执行jps,出现kafka,就OK
3. Kafka Manager安装
为了方便对kafka集群的监控及管理,目前已有开源的kafka监控及管理工具,如:Kafka Manager,Kafka Web Console,KafkaOffsetMonitor


 浙公网安备 33010602011771号
浙公网安备 33010602011771号