Hadoop之Hive安装与应用
1. Hive简介
1. Hive的产生
Hadoop体系将数据存入HDFS中,并且通过MapReduce的Java程序分析和处理数据。但是对于进行数据分析的人来说不方便,于是Hive就产生了。
起源于FaceBook,后贡献给了Apache
2. Hive的作用
在Hive中执行的SQL语句被转换成一个MapReduce任务运行在YARN上,从而处理HDFS的数据。
3. Hive的体系结构
2. Hive安装
1. 前提条件
需要安装在已经成功部署的hadoop上,并且能够正常运行
将Hive安装master节点上
由于Hive需要将元信息存入关系型数据库中,需要提前准备好mysql
2. 准备Mysql数据库
1. 安装配置mysql
2. 为Hive创建数据库和对应的用户
3. Hive的嵌入模式
使用Hive内置的Derby数据存储元信息
适用于开发和测试
4. Hive的远程模式
1. 下载Hive安装包
地址:https://dlcdn.apache.org/hive/hive-2.3.9/apache-hive-2.3.9-bin.tar.gz
2. 解压并设置软链接
tar -zxvf apache-hive-2.3.9-bin.tar.gz -C /usr/local/
ln -s apache-hive-2.3.9-bin hive
3. 配置Hive
1. 创建hive-site.xml文件
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>hive.metastore.local</name>
<value>true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://172.16.1.209:3306/yangjianbo?characterEncoding=UTF-8</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name >javax.jdo.option.ConnectionPassword</name>
<value>123.com</value>
</property>
</configuration>
2. 复制java connector到依赖库
cp /root/mysql-connector-java-5.1.39-bin.jar /usr/local/hive/lib
4. 配置环境变量
export HIVE_HOME=/usr/local/hive
export PATH=$PATH:$HIVE_HOME/bin
source /etc/profile
5. 验证Hive
hive --help
6. 初始化元数据
schematool -dbType mysql -initSchema
3. Hive的基本应用
1. 命令行模式
1. 创建表
hive -e 'create table testDB(id int,name string,age int);'
2. 查看表
hive -e 'show tables;'
2. Hive Shell模式
1. 创建库
hive> create database test_db;
2. 查看库
hive> show databases;
3. 设置显示当前数据库
set hive.cli.print.current.db=true;
只对当前会话有效
3. 查看Hive的元信息
登录到mysql服务器上
1. 查看表名和表类型
select * from TBLS;
2. 查看表字段信息
select * from COLUMNS_V2;
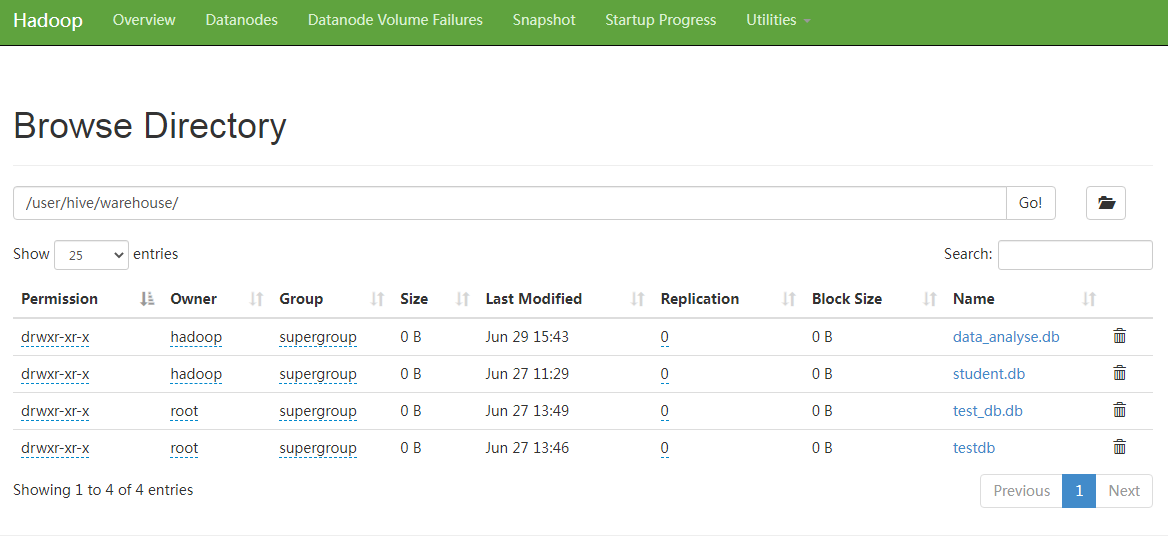
4. 通过HDFS web console查看hive的数据

 浙公网安备 33010602011771号
浙公网安备 33010602011771号