Hadoop之HDFS安装
1. HDFS的特点
1. 适用的场景
1. 专为存储大文件设计,支持GB级别大小的文件,能够提供很大的数据带宽并且能够在集群中拓展到成百上千个节点;一个实例能够支持千万数量级别的文件
2. 适用于流式的数据访问,保证高吞吐量
3. 容错性
4. 支持一次写入多次读取的模型,而且写入过程文件不会经常变化
5. 移动计算优于移动数据
6. 兼容各种硬件和软件平台
2. 不适用的场景
1. 大量小文件
2. 低延迟数据访问
3. 多用户写入
2. 主要组件与架构
NameNode 运行master
SecondaryNameNode 运行master
DataNode 运行slave
3. HDFS架构分析
1. 数据块
HDFS使用块存储
默认数据块大小为64MB
2. NameNode
NameNode管理着文件系统的命名空间,它维护文件系统树及树中的所有文件和目录。也负责维护所有文件或目录的打开关闭移动重命名等操作。管理和维护HDFS的元信息文件(fsimage)和操作日志文件(edits)
1. 元信息(fsimage)
1. 种类
文件名目录名及它们之间的层级关系
文件目录的所有者及其权限
每个文件快的名及文件有哪些块组成
2. 元信息的持久化
存放元信息的文件是fsimage
在系统运行期间所有对元信息的操作都保存在内存中并被持久化到另一个文件edits中,并且 edits文件和fsimage文件会被SecondaryNameNode周期性地合并
3. 元信息查看器
找到元信息所在的目录
hdfs oiv -i fsimage_0000000000000018740 -o /tmp/1.xml -p XML
2. 操作日志文件(edits)
该文件用于记录客户端操作,文件与元信息放在同一目录下
hdfs oev -i edits_0000000000000018708-0000000000000018740 -o /tmp/2.xml
3. NameNode单点故障问题
1. 将 Hadoop 元数据写入到 本地文件系统的同时再实时同步到 一个远程挂载的网络文件系统( NFS )。
2. 运行一个 SecondaryNameNode , 它的作用是与 NameNode进行交互,定期通过编辑日志文件合并命名空间镜像 。当NameNode发生故障时,它会通过自己合井的命名空间镜像副本来 恢 复。需要注意 的 是 SecondaryNameNode 保存的状态总是滞后于NameNode ,所以这种方式难免会导致丢失部分数据 。
3. DataNode
DataNode是HDFS中的Worker节点,它负责存储数据块 ,也负责为系统客户端提供数据块 的读写服务,同时还会根据 NameNode 的指示来进行创建、删除和复制等操作 。
此外, 它还会通过心跳定期向 NameNode 发送所存储文件块列表信息 。 当对 HDFS 文件系统进行读写 时, NameNode 告知客户端每个数据驻留在哪个 DataNode,客户端直接与
DataNode 进行通信,DataNode还会与其他DataNode通信,复制这些块以实现冗余 。
数据块存放的目录:
/usr/local/hadoop/hdfs/data/current/BP-640349375-127.0.0.1-1655341460555/current/finalized/subdir0/subdir0目录
4. SecondaryNameNode
并不是NameNode的备份
为了解决edits和fsimage合并而影响Hadoop重启的速度而诞生
定期合并edits和fsimage
合并步骤
(1 ) 合并之前告知 NameNode 把所有的操作写到新的 edites 文件并将其命名为
edits.new 。
( 2) SecondaryNameNode 从 NameNode 请求 fsimage 和 edits 文件 。
( 3) SecondaryNameNode 把 fsimage 和 edits 文件合并成新的 fsimage 文件 。
( 4) NameNode 从 SecondaryNameNode 获取合并好的新的 fsimage 并将旧的替换掉,
并把 edits 用 (1 )创建的 edits.new 文件替换掉。
( 5)更新 fstime 文件中的检查点。
fsimage:保存的是上个检查点 的 HDFS 的元信息 。
edits:保存的是从上个检查点开始发生的 HDFS 元信息状态改变信息 。
fstime:保存了最后一个检查点 的时间戳 。
5. 数据备份
NameNode负责各个数据块的备份
默认有3个副本
6. 通信协议
基于TCP/IP协议
7. 可靠性保证
DataNode定期3s向NameNode发送心跳
HDFS检测数据块损坏
4. 文件操作过程分析
1. 读文件
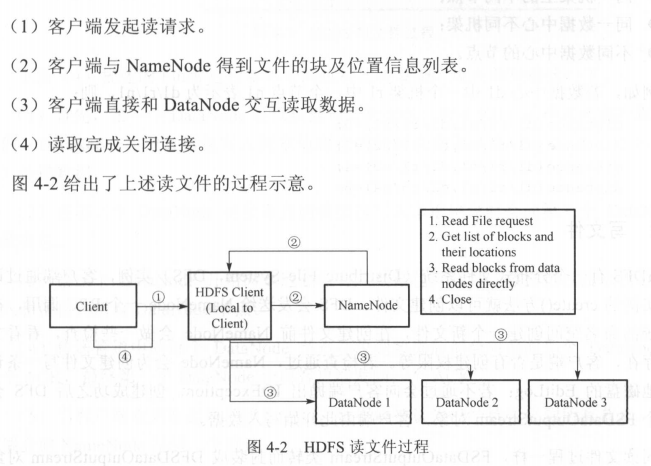
2. 写文件
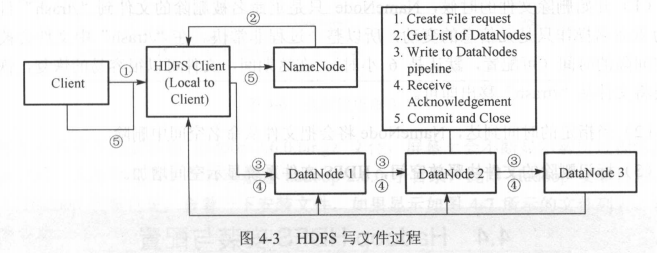
3. 删除文件
(1 )开始删除文件的时候, NameNode 只是重命名被 删 除的文件到 “ /trash ” 目录 ,
因为重命名操作只是元信息 的变动,所以整个过程非常快。在“/trash ” 中文件会被保留
一定间隔的时间(可配置,默认是 6 小时),在这期间,文件可以很容易的恢复,恢复只
需要将文件从 “ /trash”移出即可 。
(2 )当指定的时间到达, NameNode 将会把文件从命名空间中删除。
(3 )标记删除的文件块释放 空 间, HDFS 文件系统显示空间增加。
5. Hadoop HDFS安装与配置
1. 准备工作
三台机器172.16.1.228/229/230
229 namenode secondarynamenode
228/230 datanode
配置/etc/hosts一致
关闭防火墙,selinux
hadoop版本:2.8.5
java:1.8,配置java环境变量
系统时间保持一致
创建一个普通用户和组hadoop groupadd hadoop;useradd -g hadoop hadoop
使用hadoop用户生成密钥对,分别拷贝其它各个节点上
2. 下载hadoop
https://archive.apache.org/dist/hadoop/common/hadoop-2.8.5/hadoop-2.8.5.tar.gz
3. 解压
tar -zxvf hadoop-2.8.5.tar.gz -C /usr/local
4. 建立软链接
ln -s hadoop-2.8.5 hadoop
5. 修改部分文件
cd /usr/local/hadoop/etc/hadoop
1. 配置hadoop环境变量hadoop-env.sh
最后一行添加 export JAVA_HOME=/usr/java/jdk1.8.0_212-amd64
2. 配置yarn环境变量yarn-env.sh
最后一行添加 export JAVA_HOME=/usr/java/jdk1.8.0_212-amd64
3. 配置核心组件文件core-site.xml
<configuration>
<!--配置hdfs文件系统的命名空间-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<!-- 配置操作hdfs的存冲大小 -->
<property>
<name>io.file.buffer.size</name>
<value>4096</value>
</property>
<!-- 配置临时数据存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/tmp</value>
</property>
</configuration>
4. 配置文件系统hdfs-site.xml
<configuration>
<!--配置副本数-->
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<!--hdfs的元数据存储位置-->
<property>
<name>dfs.namenode.name.dir</name>
<value>/usr/local/hadoop/hdfs/name</value>
</property>
<!--hdfs的数据存储位置-->
<property>
<name>dfs.datanode.data.dir</name>
<value>/usr/local/hadoop/hdfs/data</value>
</property>
<!--hdfs的master的web ui 地址-->
<property>
<name>dfs.http.address</name>
<value>master:50070</value>
</property>
<!--hdfs的snn的web ui 地址-->
<property>
<name>dfs.secondary.http.address</name>
<value>master:50090</value>
</property>
<!--是否开启web操作hdfs-->
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<!--是否启用hdfs权限(acl)-->
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
5. 配置yarn-site.xml
<configuration>
<!--指定resourcemanager所启动的服务器主机名-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<!--指定mapreduce的shuffle-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!--指定resourcemanager的内部通讯地址-->
<property>
<name>yarn.resourcemanager.address</name>
<value>master:8032</value>
</property>
<!--指定scheduler的内部通讯地址-->
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8030</value>
</property>
<!--指定resource-tracker的内部通讯地址-->
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8031</value>
</property>
<!--指定resourcemanager.admin的内部通讯地址-->
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:8033</value>
</property>
<!--指定resourcemanager.webapp的ui监控地址-->
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8088</value>
</property>
</configuration>
6. 配置MapReduce计算框架文件mapred-site.xml
cp -a mapred-site.xml.template mapred-site.xml
<configuration>
<!--指定maoreduce运行框架-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value> </property>
<!--历史服务的通信地址-->
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<!--历史服务的web ui地址-->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
</configuration>
7. 配置Master的slaves文件
[root@master hadoop]# cat slaves datanode1 datanode2
6. 将上述文件都拷贝到另外两个节点上
scp core-site.xml hdfs-site.xml yarn-site.xml mapred-site.xml root@172.16.1.230:/usr/local/hadoop/etc/hadoop/ scp core-site.xml hdfs-site.xml yarn-site.xml mapred-site.xml root@172.16.1.228:/usr/local/hadoop/etc/hadoop/ scp hadoop-env.sh mapred-env.sh yarn-env.sh root@172.16.1.230:/usr/local/hadoop/etc/hadoop/ scp hadoop-env.sh mapred-env.sh yarn-env.sh root@172.16.1.228:/usr/local/hadoop/etc/hadoop/
7. 配置操作系统环境变量
修改/etc/profile
export JAVA_HOME=/usr/java/jdk1.8.0_212-amd64 export HADOOP_HOME=/usr/local/hadoop export PATH=.:$HADOOP_HOME/bin:$PATH:$JAVA_HOME/bin:$STORM_HOME/bin:/opt/scala/sbt/ export HADOOP_COMMON_LIB_NATIVE_DIR=/usr/local/hadoop/lib/native export HADOOP_OPTS="-Djava.library.path=/usr/local/hadoop/lib"
source /etc/profile
8. 所有节点上创建hadoop数据目录
mkdir -p /usr/local/hadoop/hdfs/{name,data,tmp}
9. 所有节点修改文件属主
chown -R hadoop.hadoop /usr/locla/hadoop-2.8.5
10. 主节点上格式化文件系统
切换为hadoop用户,执行hdfs namenode -format
正常结果有这样的字样
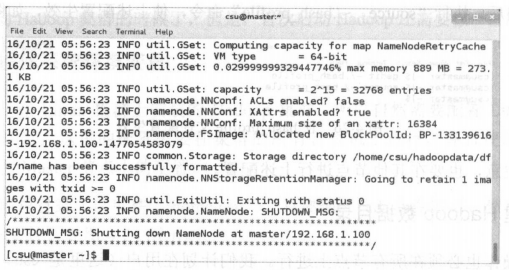
如果出现异常,需要把hdfs数据目录删除,然后重新格式化一下
11. 主节点上启动和关闭hadoop
1. 即将弃用的方式
start-all.sh
stop-all.sh
2. 新的方式
start-dfs.sh;start-yarn.sh
stop-yarn.sh;stop-dfs.sh
12. 验证Hadoop是否启动成功
1. 主节点
30194 SecondaryNameNode 30362 ResourceManager 6044 Jps 29982 NameNode
2. 数据节点
20166 DataNode 29911 Jps 20284 NodeManager
3. web界面监视系统状况
hdfs的master的web ui地址 http://172.16.1.229:50070
yarn.resourcemanager的地址 http://172.16.1.229:8088

 浙公网安备 33010602011771号
浙公网安备 33010602011771号