


Solr之SolrCloud工作原理
1. solrcloud入门
solrcloud是设计用来处理跨多台服务器的分布式索引和查询工具,具有高可用性、可扩展性、自动容错性的特点。在 So lrC!oud 中,索引数据被分成多个 Shard (分片),而每个Shard 可以托管在多台机器上,同时为每个 Shard 提供副本冗余来提供可扩展性和自动容错性 。 SolrCloud 利用 Zookeeper 来管理集群中所有节点 以及集 中管理集群配置文件。
2. solrcloud工作原理
1. 逻辑概念
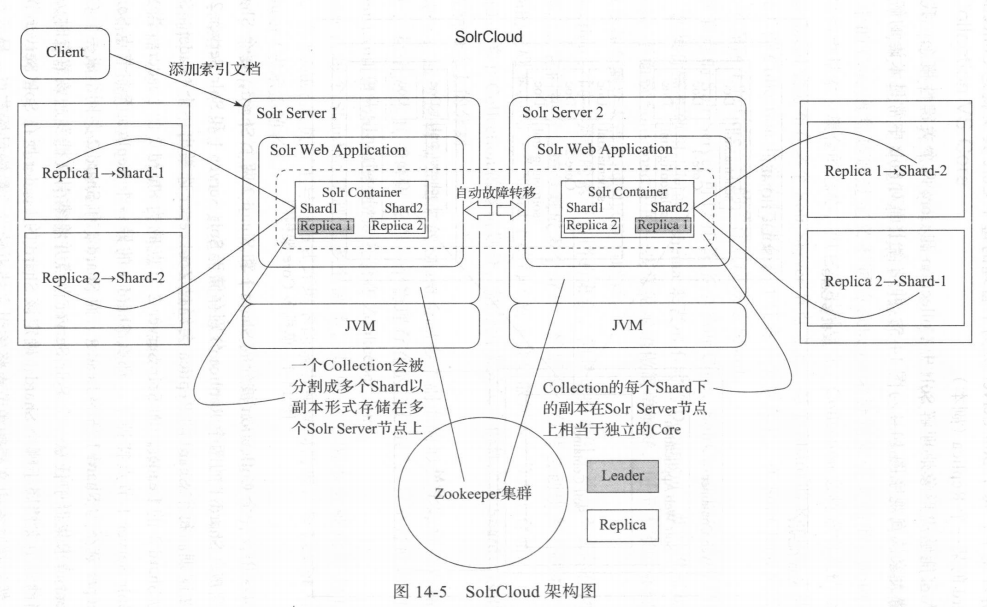
一个 Solr 集群上可以承载多个 Collection 的索引文档 。一个 Collection 由多个索引文梢组成,而一个 Collection 可以被分割成多个 Shard (分片),每个分片中包含了这个 Collection中的部分索引文档 。
2. 物理概念
一个 Solr 集群由一个或多个 SoLr 节点组成,每个 Solr 节点运行着一个 Solr Server 实例 。每个 Solr 节点可以包含多个 Core ,而集群中的每个 Core 其实就是某个逻辑概念上的分片对应的某一个物理副本 。 每个副本使用同一套配置文件,每个 Shard 的副本个数决定了 Collection
的冗余级别 、集群的自动容错度以及高负载情况下的并发查询请求数量。
3. 常用术语
Collection
同一类型的索引文挡的集合,但是这些索引文档并不实际存储在同一 台机器上,它们通常会被分割成多个分片,然后每个分片会创建多个副本,所以实际存储的是副本,同一个 Shard 下的每个副本会分散到多个节点上存储 。
Shard
单个collection的划分
Replica
每个shard以多个副本的形式分布在多个节点上,每个副本可以当做一个core
Leader
每个shard会复制出多个副本,其中一个副本被选举为Leader
Core
存在于节点硬盘上的多个索引文档集合以及这些索引文档相关的配置文件共同组成一个solr core
Node
物理服务器
Cluster
表示一个solr集群
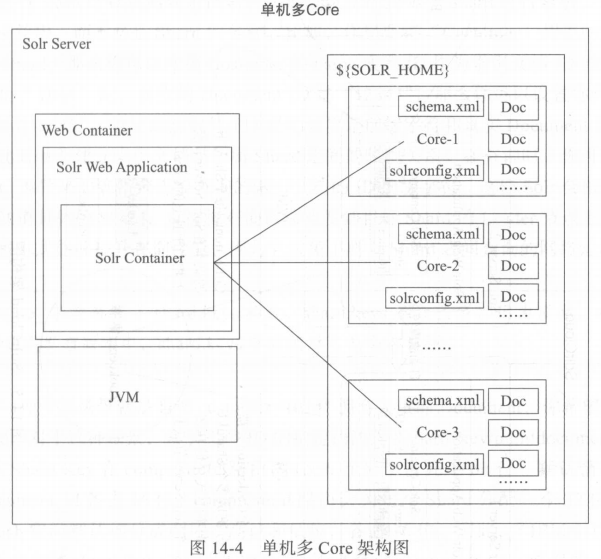
4. 单机多core结构图
5. solrcloud架构图
6. shard的几种状态
1. ACTIVE
一个Shard的默认状态
2. INACTIVE
当一个Shard被成功分出之后,它就暂时处于INACTIVE状态
3. CONSTRUCTION
当一个 Shard 被重新分割,在分割处理过程中,新分出 来的子 Shard 就处于 CONSTRUCTION 状态 。 处于该状态下的 Shard 仍然能够接收来自Shard Leader 转发的更新请求,然而它不能参与分布式查询 。
4. RECOVERY
当一个 Shard 的子 Shard 需要创建 Replica 以满足 Collection 上设置的Replica 总个数时,该 Shard 就处于阻CO VERY 状态 。 处 于此状态的 Shard 仍然能够接收来自 Shard Leader 转发的更新请求,然而它不能参与分布式查询 。
7. Replica的几种状态
1. ACTIVE
当一个Replica处于ACTIVE状态,表明当前Replica已经准备好,可以接收更新和查询请求了。
2. DOWN
宕机状态
3. RECOVERING
表示Replica正从shard Leader上执行索引恢复操作。索引恢复操作有两种:peer-sync增量同步和full replication全量同步
4. RECOVERY_FAILED
当 Replica 尝试进行数据恢复操作,但是尝试失败时会进入此状态 。 如果当前 Replica 所在 Solr 节点不在 Zookeeper 的 /live_nodes 下,那么该 Replica 的状态会被丢弃 。 因为它不在 Solr 集群中,记录该状态信息已经没有意义 。
8. solrcloud的分布式查询请求
1. 分布式Query请求流程
2. 分布式Update请求流程
9. 读写端的自动容错
1. 读操作的自动容错
solrj提供了cloudsolrclient,如果集群中某些节点离线不可用,只要每个shard至少还有一份Replica存在,集群中的其它节点就会正常响应查询请求。
2. 写操作的自动容错
当你向集群中的任意节点发送一个 Update 请求时,该节点会首先判断当前节点上是否 是该 Shard 的 Leader ,如果不是,会将请求转发到该 Leader 所在节点上 。 使用 version 来确 保每个 Replica 都是最新的,如果 Leader 挂掉了,其他 Replica 会顶替上,这种架构允许在 发生故障或灾难时恢复你的数据,即便你采用的是软提交 。 每个节点都会创建 Transaction Log (事务日志),也就是说,内容的每一步更新都会被 记录 。 事务日志用于决定当前节点上的内容应该包含在哪个 Replica 里 。 当一个新的 Replica 被创建,它会从 Leader 同步数据并且根据事务日志确定哪个更新应该包含在当前 Replica 中 。 如果数据同步操作失败了,它会根据事务日志进行重试,因为事务日志是由更新记录组 成,它能增加索引操作的健壮性,因为当索引操作突然中断时,它支持重做未提交的更新。 如果一个 Leader 挂掉了,会从其他 Replica 选举一个新的 Leader ,然后由新的 Leader 向其 他 Replica 发起一个同步操作,如果同步操作成功,那么所有 Replica 数据将保持一致 。 如 果一个 Replica 脱离太久无法同步, Leader 会向该 Replica 发送 Recovery (数据恢复)请求, 强迫该 Replica 主动进行数据恢复 。 如果由于 Core 重载而导致更新操作失败, Leader 会通 知其他节点更新失败,并启动 Recovery 过程 。 Solr 中的 Recovery 操作分为 Peer sync 和 Replication 两种方式: 口 Peer sync :如果需要 Recovery 的节点中断的时间较短,只是丢失少量的 Update 请 求,那么它可以从 Leader 的 Update log 中获取。 这个临界值是 100 个 update 请求, 如果大于 100 个,该 Replica 节点就会从 Leader 进行完整的索引快照恢复 。 口 Replication :如果该节点下线太久,以至于不能从 Leader 进行同步 ,它就会以 HTTP 的形式进行完整的索引快照恢复 。
3. zookeeper
1. solr使用zookeeper来实现3个关键操作
1. 配置文件的集中存储与分发
2. 探测和通知集群状态更新
3. shard Leader选举
2. 生产环境下zookeeper配置建议
1. 建议使用独立的zookeeper集群,这样宕机一个zookeeper节点也不需要停机维护
2. 即使整个zookeeper挂掉,solr可以继续接收查询请求,但是不能接收更新请求。
3. 当一个solr节点加入集群,它会首先创建一个znode并指示自己是一个Live Node。如果一个solr节点崩溃了,zookeeper会在到达设置的超时时间之后开始探测节点崩溃。默认超时时间15秒。
3. solr如何使用zookeeper选举shard leader
1. shard leader的职责
1. 接收Update请求
2. 递增被Update的索引文档的_version_域的值,并且强制开启并发乐观锁
3. 将该索引文档写进更新日志
4. 并发地向所有Replica发送Update请求,并且阻塞知道接收到响应
2. shard leader选举过程
一个 Shard 下的四个 Replica 同时并发加入集群,其中 一个 Replica 想要被选举为 Leader ,因此理所当然, 4 个 Replica 中第一个 Replica 首先注册申请 自己为 候选 Leader ,其他同理 。 在底层 , Solr 使用 ZooKeeper 带序号的 Znode 来记录 Replica 节点 的注册加入 ZooKeeper 的顺序 。 Znode 的序号是按照原子方式递增的,因此无论有多少个 Replica 节点并发地注册为候选 Leader 都没有关系 。 简而言之,序号值最小的 Replica 节点 会在 Shard Leader 选举中获胜(先注册的序号值越小) 。 也就是说,如果当前的 Leader 挂掉 了,在新的 Leader 选举出来之前,索引操作将无法进行,最终序号中第二小的那个正常节 点会被选举为 Leader。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号