


Solr之分词
1. 分词的基本概念
分词就是将用户输入的一串文本分割成一个个token,一个个token组成了tokenStream,然后遍历tokenStream对其进行过滤操作,比如:去除停用词,特殊字符,标点符号和统一转换成小写形式。
2. Analyzer
Analyzer包含两个核心组件:Tokenizer和TokenFilter,前者用于生成Token流,后者用于对tokenizer进行过滤。
1. 常规用法
<fieldType name="text_ca" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.ElisionFilterFactory" articles="lang/contractions_ca.txt" ignoreCase="true"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.StopFilterFactory" words="lang/stopwords_ca.txt" ignoreCase="true"/>
<filter class="solr.SnowballPorterFilterFactory" language="Catalan"/>
</analyzer>
</fieldType>
2. 一个相同的分词器在两种阶段下被应用
<fieldType name="ancestor_path" class="solr.TextField">
<analyzer type="index">
<tokenizer class="solr.KeywordTokenizerFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="solr.PathHierarchyTokenizerFactory" delimiter="/"/>
</analyzer>
</fieldType>
3. Tokenizer
Analyzer必须要有一个Tokenizer,而TokenFilter可以没有。
Tokenizer不能直接被使用,需要通过TokenizerFactory工厂类来创建对应的Tokenizer
1. solr自带的Tokenizer
1. KeywordTokenizer
将整个文本当作一个Token.它的工厂类是KeywordTokenizerFactory
<analyzer type="query">
<tokenizer class="solr.KeywordTokenizerFactory"/>
</analyzer>
2. LetterTokenizer
提取出文本的所有连续的字母序列,并去除非字母字符
<analyzer type="query">
<tokenizer class="solr.LetterTokenizerFactory"/>
</analyzer>
3. LowerCaseTokenizer
继承LetterTokenizer的特性,还会将每个Token转换成小写形式。
<analyzer type="query">
<tokenizer class="solr.LowerCaseTokenizer"/>
</analyzer>
4. NGramTokenizer
根据给定的GramRange对域的文本生成n-gram token.它的工厂类是NGramTokenizerFactory
NGramTokenizerFactory有两个可选参数
1. minGramSize 必须大于0,默认值是1
2. maxGramSize 必须大于0,默认值是2
NGramTokenizer不会按照空格进行分词
<analyzer type="query">
<tokenizer class="solr.NGramTokenizerFactory" minGramSize="2" maxGramSize="6"/>
</analyzer>
输入文本: "hey man"
输出结果: h, e, y, m ,a, n ,he ,ey ,y ,m ,ma , an
5. EdgeNGramTokenizer
每次都是从最左边或最右边开始n-gram
<analyzer type="query">
<tokenizer class="solr.EdgeNGramTokenizerFactory" minGramSize="2" maxGramSize="6"/>
</analyzer>
6. WhitespaceTokenizer
使用空白字符作为Token的定界分隔符来提取Token
<analyzer type="query">
<tokenizer class="solr.WhitespaceTokenizerFactory" rule="java"/>
</analyzer>
输入: I miss you,I do
结果: I, miss ,you ,I ,do
7. StandardTokenizer
它会按照逗号或者连接符-进行断词,会剔除标点符号,#$%&等特殊字符,不会转换大小写
maxTokenLength 默认值255
<analyzer type="index">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" />
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.ReversedWildcardFilterFactory" withOriginal="true"
maxPosAsterisk="3" maxPosQuestion="2" maxFractionAsterisk="0.33"/>
</analyzer>
4. TokenFilter
TokenFilter是Tokenizer的过滤器,它用于对Tokenizer处理后的token进行二次过滤
在solr中,TokenFilter都是在schema.xml配置文件中先声明的
在<analyzer>元素下配置一个<filter>元素,<filter>元素的class属性配置成TokenFilter的工厂类
1. StopFilter
StopFilter会过滤掉在停用词字典里出现的Token,停用词字典文件默认名称为stopwords.txt,需要放置在core/conf目录下。工厂类是StopFilterFactory,有以下可选参数
words 配置停用词字典文件的加载路径,文件里的空白行和#开头将会被忽略
ignoreCase 是否忽略大小写,默认为false
<filter class="solr.StopFilterFactory" format="snowball" words="lang/stopwords_de.txt" ignoreCase="true"/>
2. LowerCaseFilter
用于将每个Token转换成小写形式
<filter class="solr.LowerCaseFilterFactory"/>
3. LengthFilter
过滤掉不符合规定字符长度限制的Token,工厂类是LengthFilterFactory
min token字符的最小长度
max token字符的最大长度
4. TrimFilter
剔除Token前面和后面的空格字符,不会剔除Token中间包含的空格字符。工厂类是TrimFilterFactory
<filter class="solr.TrimFilterFactory"/>
5. SynonymFilter
用于Token的同义词映射,需要提前在同义词字典文件里声明
synonyms 配置同义词字典文件的加载路径
ignoreCase 忽略大小写,默认false
expand 表示同一行的单词互为同义词
<filter class="solr.SynonymFilterFactory" synonyms="synonyms.txt" ignoreCase="true" expand="false"/>
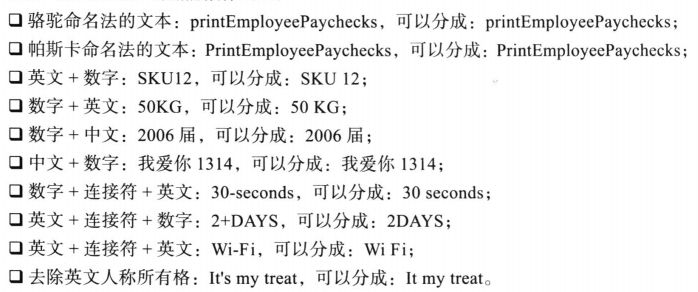
6. WordDelimiterFilter
用于处理骆驼命名法的文本,帕斯卡命名法的文本,数字与非数字字符串混排的文本
<filter class="solr.WordDelimiterFilterFactory" protected="protwords.txt"/>
7. EnglishPossessiveFilter
剔除英文里的人称代词所有格
<filter class="solr.EnglishPossessiveFilterFactory"/>
8. PorterStemFilter
去除单词结尾的ed/s/ing
<filter class="solr.PorterStemFilterFactory"/>
9. EnglishMinimalStemFilter
将英文单词复制转换为单数
<filter class="solr.EnglishMinimalStemFilterFactory"/>
5. 中文分词器
1. IK分词器
https://gitee.com/wltea/IK-Analyzer-2012FF
项目很久未更新,需要用户自己修改一下源码,否则在solr 5.x中不能使用
2. Ansj分词器
3. MMSeg4J
https://code.google.com/p/mmseg4j/
MMSeg4J源码包含3个子模块:mmseg4j-core mmseg4j-analysis mmseg4j-solr
mmseg4j包含三种算法:simple complex maxword
1. mmseg4j支持solr5需要使用两个jar包
将文件上传至/usr/local/tomcat-solr/webapps/solr/WEB-INF/lib目录下
mmseg4j-core-1.10.0.jar和mmseg4j-solr-2.3.0.jar
2. 修改managed-schema文件
<fieldType name="textComplex" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="com.chenlb.mmseg4j.solr.MMSegTokenizerFactory" mode="complex" dicPath="dic"/>
</analyzer>
</fieldType>
<fieldType name="textMaxWord" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="com.chenlb.mmseg4j.solr.MMSegTokenizerFactory" mode="max-word" />
</analyzer>
</fieldType>
<fieldType name="textSimple" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="com.chenlb.mmseg4j.solr.MMSegTokenizerFactory" mode="simple" dicPath="n:/custom/path/to/my_dic" />
</analyzer>
</fieldType>
3. 修改字段类型
<field name="userName" type="textSimple" multiValued="false" indexed="true" stored="true"/>
4. 重启一下tomcat,使配置生效
5. 配置用户自定义字典
<tokenizer class="com.chenlb.mmseg4j.solr.MMSegTokenizerFactory" mode="simple" dicPath="/var/solr/data/zhenpin/conf/dic" />
6. 在/var/solr/data/zhenpin/conf/dic目录下,创建一个文件名为words.dic,重启tomcat,使配置生效。
<fieldtype name="textComplex" class="solr.TextField" positionIncrementGap="100">
<analyzer type="index">
<tokenizer class="com.chenlb.mmseg4j.solr.MMSegTokenizerFactory" mode="complex" dicPath="/var/solr/dic" />
<filter class="solr.StopFilterFactory" ignoreCase="false" words="stopwords.txt"/>
<filter class="solr.WordDelimiterFilterFactory" protected="protwords.txt"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.NGramFilterFactory" minGramSize="1" maxGramSize="20"/>
<filter class="solr.StandardFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="com.chenlb.mmseg4j.solr.MMSegTokenizerFactory" mode="complex" dicPath="/var/solr/dic" />
<filter class="solr.SynonymFilterFactory" synonyms="synonyms.txt" ignoreCase="true" expand="true"/>
<filter class="solr.StopFilterFactory" ignoreCase="false" words="stopwords.txt"/>
<filter class="solr.WordDelimiterFilterFactory" protected="protwords.txt"/>
<filter class="solr.LowerCaseFilterFactory"/>
<!-- <filter class="solr.EdgeNGramFilterFactory" minGramSize="1" maxGramSize="20"/> -->
<filter class="solr.RemoveDuplicatesTokenFilterFactory"/>
</analyzer>
</fieldtype>


 浙公网安备 33010602011771号
浙公网安备 33010602011771号