



Solr之导入数据
1. Solr DIH
DIH提供了一种可配置的方式向Solr中导入数据,可以一次性全量导入,也可以增量导入
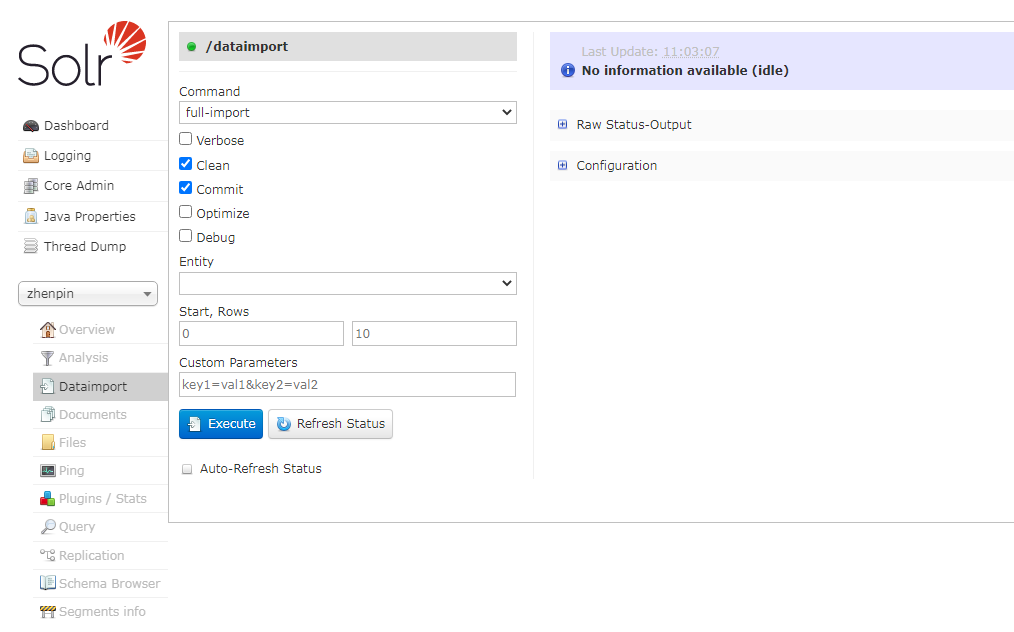
1. DIH的作用
1. 它能读取数据库的数据并创建索引
2. 它能够基于配置的方式把数据里表的列甚至多个表的数据聚合并解析成一个Document
3. 它支持基于配置的全量和增量数据导入
4. 它能实现基于配置的定时全量和增量索引
5. 它能基于HTTP方式读取并索引XML文件
6. 它支持各种基于插件式的datasource和formate配置
2. 如何开启DIH功能
需要在solrconfig.xml配置文件中配置dataimport请求处理器,并指定配置文件加载路径,默认是当前core的conf目录,也可以是绝对路径
<requestHandler name="/dataimport" class="solr.DataImportHandler">
<lst name="defaults">
<str name="config">solr-data-config.xml</str>
</lst>
</requestHandler>
3. 分析solr-data-config.xml的内容
<dataConfig>
<dataSource type="JdbcDataSource" driver="com.mysql.jdbc.Driver" url="jdbc:mysql://172.16.1.209:3306/yangjianbo" user="root" password="123.com"/>
<document>
<entity name="user" query="select * from user">
<field column="id" name="id" />
<field column="user_name" name="userName" />
<field column="sex" name="sex" />
<field column="birth" name="birth" />
<field column="salary" name="salary" />
</entity>
</document>
</dataConfig>
4. 需要在schema.xml中定义域
<field name="product_id" type="tint" indexed="true" stored="true" multiValued="false"/>
5. 拷贝solr-dataimporthandler-5.5.2.jar到/usr/local/tomcat-solr/webapps/solr/WEB-INF/lib/
cp /root/solr/dist/solr-dataimporthandler-5.5.2.jar /usr/local/tomcat-solr/webapps/solr/WEB-INF/lib/
2. 索引JSON/XML/CSV文件
3. 使用Tika索引word/excel/PDF
1. 添加Tika相关jar包
将sorl的压缩包/root/solr/contrib/extraction/lib中的jar包文件,拷贝到指定core的lib目录下
2. 在solrconfig.xml配置文件里配置外部jar包的加载路径
<lib dir="./lib" regex=".*\.jar"/>
4. 从数据库中导入数据至Solr
1. 要读取数据库需要导入数据库驱动jar包,复制到当前core的lib目录下,如果是tomcat环境,就放到/usr/local/tomcat-solr/webapps/solr/WEB-INF/lib/目录下
mysql-connector-java-5.1.39-bin.jar
2. 配置文件solr-data-config.xml
<dataConfig>
<dataSource type="JdbcDataSource" driver="com.mysql.jdbc.Driver" url="jdbc:mysql://172.16.1.209:3306/yangjianbo" user="root" password="123.com" />
<document>
<entity name="user" query="select * from user">
<field column="id" name="id">
<field column="user_name" name="userName">
<field column="sex" name="sex">
<field column="birth" name="birth">
<field column="salary" name="salary">
</entity>
</document>
</dataConfig>
name 给数据源起个别名
type solr内置的数据源的类名
driver 驱动类的完整包路劲
url jdbc连接url,注意url不要包含:<,>,&,',"
batchSize JDBC从数据库一个批次提取多少条数据,以防止一个批次返回数据量过大撑爆内存
maxRows 表示最多返回多少条数据,不设置就是返回所有
3. 在schema.xml中定义域
<field name="id" type="string" multiValued="false" indexed="true" required="true" stored="true"/> <field name="userName" type="string" multiValued="false" indexed="true" stored="true"/> <field name="sex" type="boolean" multiValued="false" indexed="true" stored="true"/> <field name="birth" type="tdate" multiValued="false" indexed="true" stored="true"/> <field name="salary" type="int" multiValued="false" indexed="true" stored="true"/>
4. 同时在schema.xml中还得有域类型
<fieldType name="string" class="solr.StrField" sortMissingLast="true"/> <fieldType name="boolean" class="solr.BoolField" sortMissingLast="true"/> <fieldType name="tdate" class="solr.TrieDateField" positionIncrementGap="0" precisionStep="6"/> <fieldType name="int" class="solr.TrieIntField" positionIncrementGap="0" precisionStep="0"/>
5. 从mongodb导入数据到solr
6. Solr Full Import全量导入
上面例子中就是全量导入
7. Solr Delta import增量导入
当增量导入操作被执行,它会读取存储在conf/deltaimport.properties配置文件,利用配置文件里记录的上一次操作时间来运行增量查询,增量导入完成后,会更新conf/deltaimport.properties配置文件里的上一次操作时间戳。首次执行增量导入时,conf/deltaimport.properties不存在,会自动新建。如果要使用增量导入,表中必须有两个字段:一个是删除标志字段;一个是数据创建时间字段。
1. 在数据表中添加一个字段update_time
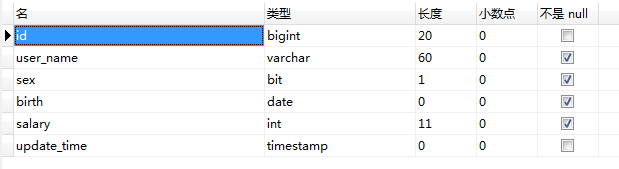
2. 在managed-schema文件中,添加filed
<field name="update_time" type="date" indexed="true" stored="true"/>
3. 在solrconfig.xml文件中,添加以下内容
<requestHandler name="/deltaimport" class="solr.DataImportHandler">
<lst name="defaults">
<str name="config">delta-data-config.xml</str>
</lst>
</requestHandler>
4. 创建delta-data-config.xml文件
<dataConfig>
<dataSource type="JdbcDataSource" driver="com.mysql.jdbc.Driver" url="jdbc:mysql://172.16.1.209:3306/yangjianbo" user="root" password="123.com"/>
<document>
<entity name="user" pk="id"
query="select * from user"
deltaImportQuery="select * from user where id='${dih.delta.id}'"
deltaQuery="select id from user where update_time > '${dih.last_index_time}'" >
<field column="id" name="id" />
<field column="user_name" name="userName" />
<field column="sex" name="sex" />
<field column="birth" name="birth" />
<field column="salary" name="salary" />
</entity>
</document>
</dataConfig>
pk 主键字段名称,如果sql语句中使用了as关键字定义了别名,pk的值要修改为主键字段的别名
query 用于指定全量导入时需要的SQL语句,这个参数只对全量导入有效,增量导入无效
deltaQuery 查询需要增量导入的主键ID所需的SQL语句
deltaImportQuery 导入所有需要增量导入的数据,其中变量${dih.delta.id}是获取deltaQuery返回的每个主键ID
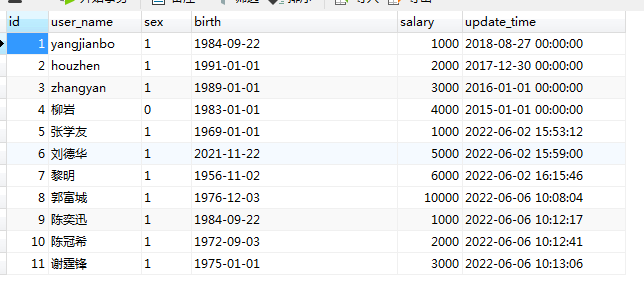
5. 往数据表中插入数据
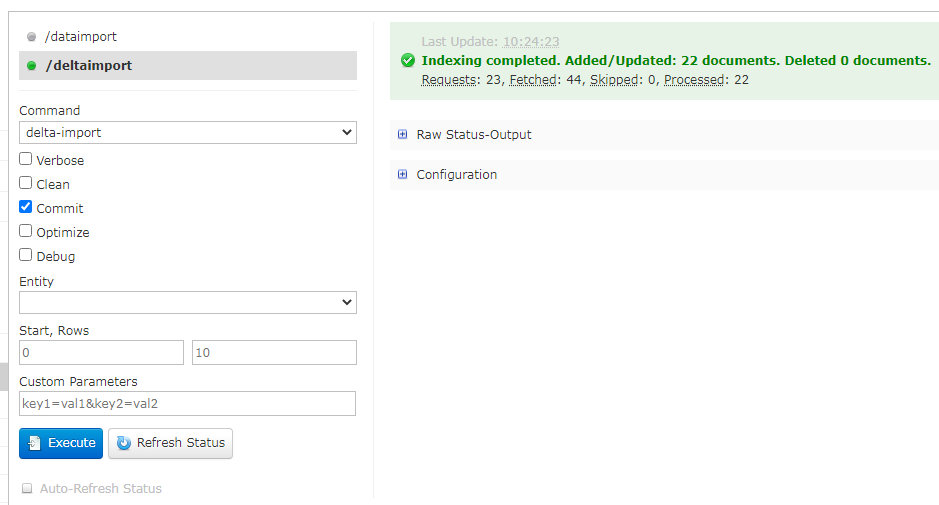
6. 在UI界面,执行增量导入
8. 定时增量导入数据
1. shell脚本
#! /bin/bash */10 ***** curl http://localhost:8080/solr/dataimport?command=delta-import
2. solr dataimport scheduler
1. 下载solr dataimport scheduler
http://code.google.com/p/solr-data-import-scheduler/
2. 配置文件dataimport.properties
# to sync or not to sync # 1 - active; anything else - inactive syncEnabled=1 # which cores to schedule # in a multi-core environment you can decide which cores you want syncronized # leave empty or comment it out if using single-core deployment syncCores=specialNewOfDay,products,brand,evaluation,suggest,bobos_product # solr server name or IP address # [defaults to localhost if empty] server=192.168.1.183 # solr server port # [defaults to 80 if empty] port=8983 # application name/context # [defaults to current ServletContextListener's context (app) name] webapp=solr # URL params [mandatory] # remainder of URL params=/dataimport?command=delta-import&clean=false&commit=true&optimize=false&debug=false&verbose=false # schedule interval # number of minutes between two runs # [defaults to 30 if empty] interval=30 # 重做索引的时间间隔,单位分钟,默认7200,即1天; # 为空,为0,或者注释掉:表示永不重做索引 reBuildIndexInterval=1440 # 重做索引的参数 reBuildIndexParams=/dataimport?command=full-import&clean=true&commit=true&optimize=false&debug=false&verbose=false # 重做索引时间间隔的计时开始时间,第一次真正执行的时间=reBuildIndexBeginTime+reBuildIndexInterval*60*1000; # 两种格式:2012-04-11 03:10:00 或者 03:10:00,后一种会自动补全日期部分为服务启动时的日期 reBuildIndexBeginTime=03:00:00
syncEnabled 表示是否同步导入,1表示激活同步导入,其它值表示不启用同步导入
syncCores 表示哪些core进行调度,多个core名称可以使用逗号进行分割
server 表示solr server的IP或者域名
port 表示solr server的端口号
webapp 表示solr web application名称,默认为solr
params 表示dataimport URL以及需要附带的请求参数
interval 表示每间隔多少分钟调度执行一次,默认为30分钟
在web.xml文件,添加以下内容:
<listener>
<listener-class>org.apache.solr.handler.dataimport.scheduler.ApplicationListener</listener-class>
</listener>


 浙公网安备 33010602011771号
浙公网安备 33010602011771号