


Django学习
11. Django表单
1. HTTP请求
HTTP协议以"请求-回复"的方式工作。客户发送请求时,可以在请求中附加数据。服务器通过解析请求,就可以获得客户传来的数据,并根据URL来提供特定的服务。
1. GET方法
1. 在项目newpython/newpython中,创建一个search.py文件,内容如下:
# -*- coding: utf-8 -*-
from django.http import HttpResponse
from django.shortcuts import render_to_response
# 表单
def search_form(request):
return render_to_response('search_form.html')
# 接收请求数据
def search(request):
request.encoding = 'utf-8'
if 'q' in request.GET and request.GET['q']:
message = '你搜索的内容为: ' + request.GET['q']
else:
message = '你提交了空表单'
return HttpResponse(message)
2. 在模块目录templates中添加search_form.html
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>珍品网</title>
</head>
<body>
<form action="/search" method="get">
<input type="text" name="q">
<input type="submit" value="搜索">
</form>
</body>
</html>
3. 修改urls.py的内容
"""newpython URL Configuration
The `urlpatterns` list routes URLs to views. For more information please see:
https://docs.djangoproject.com/en/3.0/topics/http/urls/
Examples:
Function views
1. Add an import: from my_app import views
2. Add a URL to urlpatterns: path('', views.home, name='home')
Class-based views
1. Add an import: from other_app.views import Home
2. Add a URL to urlpatterns: path('', Home.as_view(), name='home')
Including another URLconf
1. Import the include() function: from django.urls import include, path
2. Add a URL to urlpatterns: path('blog/', include('blog.urls'))
"""
from django.contrib import admin
from django.urls import path
from django.conf.urls import url
from . import views,testdb,search
urlpatterns = [
path('admin/', admin.site.urls),
url(r'^$',views.hello),
url(r'test/',views.test),
url(r'name/',views.name),
url(r'list/',views.test_list),
url(r'dict/',views.test_dict),
url(r'base/',views.base_html),
url(r'yangjianbo/',views.yangjianbo_html),
url(r'testdb/',testdb.testdb),
url(r'^search-form$', search.search_form),
url(r'^search$', search.search),
]
4. 启动项目,报错:
from django.shortcuts import render_to_response ImportError: cannot import name 'render_to_response' from 'django.shortcuts' (D:\Python\Python37\lib\site-packages\django\shortcuts.py)
解决方法:
我使用的是Django3.0版本,这个版本已经把render_to_response移除了。使用render代替render_to_response。
语法: render有三个参数,第一个是request参数,二是待渲染的html模板文件,三个保存具体数据的字典参数。
return render(request,"information.html",{"name":"test","password":"123456"})
5. search.py内容修改为
# -*- coding: utf-8 -*-
from django.http import HttpResponse
from django.shortcuts import render
# 表单
def search_form(request):
return render(request,'search_form.html')
# 接收请求数据
def search(request):
request.encoding = 'utf-8'
if 'q' in request.GET and request.GET['q']:
message = '你搜索的内容为: ' + request.GET['q']
else:
message = '你提交了空表单'
return HttpResponse(message)
6. 访问地址: http://127.0.0.1:8000/search-form
2. POST方法
1. post.html内容
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>菜鸟教程(runoob.com)</title>
</head>
<body>
<form action="/search-post" method="post">
{% csrf_token %}
<input type="text" name="q">
<input type="submit" value="Submit">
</form>
<p>{{ rlt }}</p>
</body>
</html>
2. 在newpython/newpython下面新建一个search2.py文件
# -*- coding: utf-8 -*-
from django.shortcuts import render
from django.views.decorators import csrf
# 接收POST请求数据
def search_post(request):
ctx = {}
if request.POST:
ctx['rlt'] = request.POST['q']
return render(request, "post.html", ctx)
3. 在newpython/newpython下,修改urls.py文件
"""newpython URL Configuration
The `urlpatterns` list routes URLs to views. For more information please see:
https://docs.djangoproject.com/en/3.0/topics/http/urls/
Examples:
Function views
1. Add an import: from my_app import views
2. Add a URL to urlpatterns: path('', views.home, name='home')
Class-based views
1. Add an import: from other_app.views import Home
2. Add a URL to urlpatterns: path('', Home.as_view(), name='home')
Including another URLconf
1. Import the include() function: from django.urls import include, path
2. Add a URL to urlpatterns: path('blog/', include('blog.urls'))
"""
from django.contrib import admin
from django.urls import path
from django.conf.urls import url
from . import views,testdb,search,search2
urlpatterns = [
path('admin/', admin.site.urls),
url(r'^$',views.hello),
url(r'test/',views.test),
url(r'name/',views.name),
url(r'list/',views.test_list),
url(r'dict/',views.test_dict),
url(r'base/',views.base_html),
url(r'yangjianbo/',views.yangjianbo_html),
url(r'testdb/',testdb.testdb),
url(r'^search-form$', search.search_form),
url(r'^search$', search.search),
url(r'^search-post$', search2.search_post),
]
2. Request对象
1. Request对象的属性
|
属性 |
描述 |
|
path |
请求页面的全路径,不包括域名—例如, "/hello/"。 |
|
method |
请求中使用的HTTP方法的字符串表示。全大写表示。例如: if request.method == 'GET': |
|
GET |
包含所有HTTP GET参数的类字典对象。参见QueryDict 文档。 |
|
POST |
包含所有HTTP POST参数的类字典对象。参见QueryDict 文档。 服务器收到空的POST请求的情况也是有可能发生的。也就是说,表单form通过HTTP POST方法提交请求,但是表单中可以没有数据。因此,不能使用语句if request.POST来判断是否使用HTTP POST方法;应该使用if request.method == "POST" (参见本表的method属性)。 注意: POST不包括file-upload信息。参见FILES属性。 |
|
REQUEST |
为了方便,该属性是POST和GET属性的集合体,但是有特殊性,先查找POST属性,然后再查找GET属性。借鉴PHP's $_REQUEST。 例如,如果GET = {"name": "john"} 和POST = {"age": '34'},则 REQUEST["name"] 的值是"john", REQUEST["age"]的值是"34". 强烈建议使用GET and POST,因为这两个属性更加显式化,写出的代码也更易理解。 |
|
COOKIES |
包含所有cookies的标准Python字典对象。Keys和values都是字符串。 |
|
FILES |
包含所有上传文件的类字典对象。FILES中的每个Key都是<input type="file" name="" />标签中name属性的值. FILES中的每个value 同时也是一个标准Python字典对象,包含下面三个Keys:
注意:只有在请求方法是POST,并且请求页面中<form>有enctype="multipart/form-data"属性时FILES才拥有数据。否则,FILES 是一个空字典。 |
|
META |
包含所有可用HTTP头部信息的字典。 例如:
META 中这些头加上前缀 HTTP_ 为 Key, 冒号(:)后面的为 Value, 例如:
|
|
user |
是一个django.contrib.auth.models.User 对象,代表当前登录的用户。 如果访问用户当前没有登录,user将被初始化为django.contrib.auth.models.AnonymousUser的实例。 你可以通过user的is_authenticated()方法来辨别用户是否登录:
if request.user.is_authenticated():
# Do something for logged-in users.
else:
# Do something for anonymous users.
只有激活Django中的AuthenticationMiddleware时该属性才可用 |
|
session |
唯一可读写的属性,代表当前会话的字典对象。只有激活Django中的session支持时该属性才可用。 |
|
raw_post_data |
原始HTTP POST数据,未解析过。 高级处理时会有用处。 |
2. 请求对象
2. POST
数据类型是 QueryDict,一个类似于字典的对象,包含 HTTP POST 的所有参数。
常用于 form 表单,form 表单里的标签 name 属性对应参数的键,value 属性对应参数的值。
取值格式: 对象.方法。
get():返回字符串,如果该键对应有多个值,取出该键的最后一个值。
例子:
views.py的内容
from django.views.decorators.csrf import csrf_exempt
@csrf_exempt #关闭django的csrf
def hello(request):
name = request.POST.get("name")
return HttpResponse('姓名:{}'.format(name))
urls.py的内容
url(r'^$',views.hello),
访问,使用postman工具
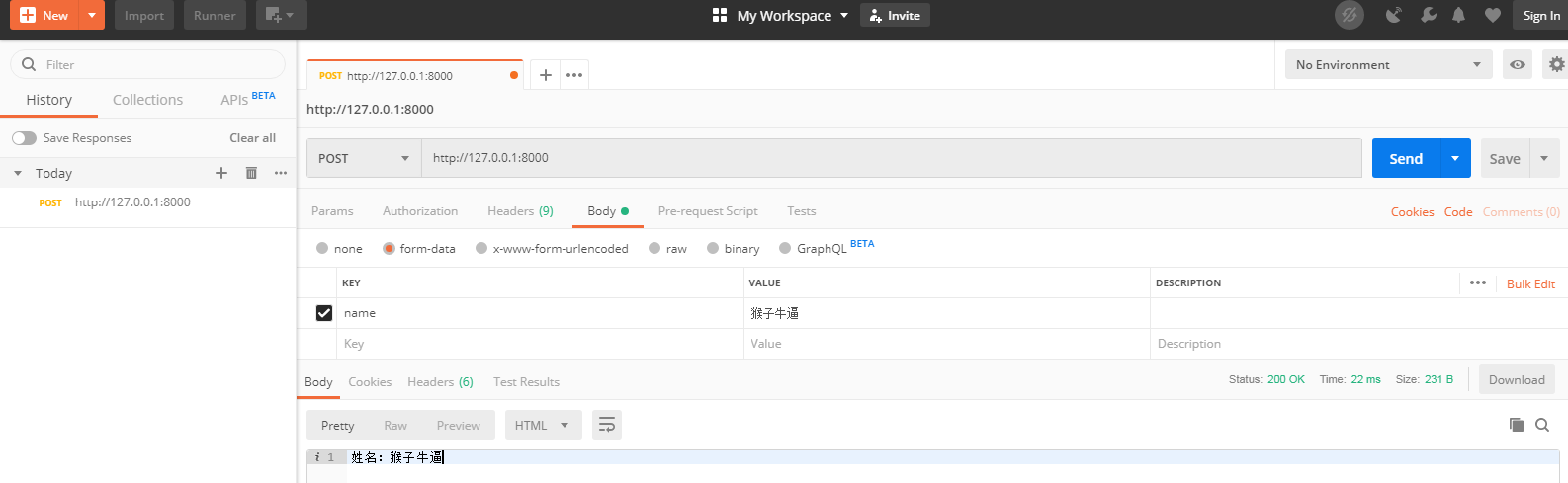
request.POST的内容:<QueryDict: {'csrfmiddlewaretoken': ['3Hdv2rdkaIyInTYS0zBcgvQxtpxz1sK2ZjdZ61O8xOWfCeiPZ3j74l5YMPDZlXZT'], 'q': ['电费水费']}>
14. Django Admin管理工具
Django提供了基于web的管理工具
Django自动 管理工具是django.contrib的一部分,可以在settings.py中的INSTALLED_APPS看到
INSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
'yangjianbo',
]
1. 激活管理工具
在项目目录下的urls.py中
# urls.py
from django.conf.urls import url
from django.contrib import admin
urlpatterns = [
url(r'^admin/', admin.site.urls),
]
2. 使用管理工具
1. 登录
http://127.0.0.1:8000/admin
2. 创建超级用户
python manage.py createsuperuser 创建对应的超级用户,记住账号和密码
16. Django ORM多表实例
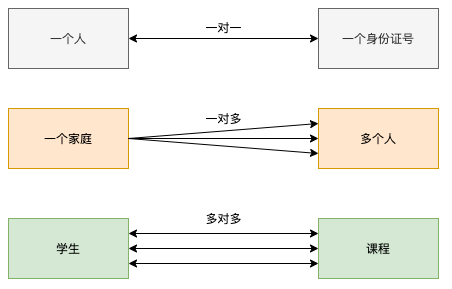
表与表之间的关系可分为以下三种
一对一:一个人对应一个身份证号码,数据字段设置unique
一对多:一个家庭有多个人,一般通过外键来实现
多对多:一个学生有多门课程,一个课程有多个学生,一般通过第三个表来实现关联
1. 创建模型
1. 表结构
书籍表 Book:title 、 price 、 pub_date 、 publish(外键,多对一) 、 authors(多对多)
出版社表 Publish:name 、 city 、 email
作者表 Author:name 、 age 、 au_detail(一对一)
作者详情表 AuthorDetail:gender 、 tel 、 addr 、 birthday

2. 创建类
class Book(models.Model):
title = models.CharField(max_length=32)
price = models.DecimalField(max_digits=5, decimal_places=2)
pub_date = models.DateField()
publish = models.ForeignKey("Publish", on_delete=models.CASCADE)
authors = models.ManyToManyField("Author")
class Publish(models.Model):
name = models.CharField(max_length=32)
city = models.CharField(max_length=64)
email = models.EmailField()
class Author(models.Model):
name = models.CharField(max_length=32)
age = models.SmallIntegerField()
au_detail = models.OneToOneField("AuthorDetail", on_delete=models.CASCADE)
class AuthorDetail(models.Model):
gender_choices = (
(0, "女"),
(1, "男"),
(2, "保密"),
)
gender = models.SmallIntegerField(choices=gender_choices)
tel = models.CharField(max_length=32)
addr = models.CharField(max_length=64)
birthday = models.DateField()
说明:
1、EmailField 数据类型是邮箱格式,底层继承 CharField,进行了封装,相当于 MySQL 中的 varchar。
2、Django1.1 版本不需要联级删除:on_delete=models.CASCADE,Django2.2 需要。
3、一般不需要设置联级更新.
4、外键在一对多的多中设置:models.ForeignKey("关联类名", on_delete=models.CASCADE)。
5、OneToOneField = ForeignKey(...,unique=True)设置一对一。
6、若有模型类存在外键,创建数据时,要先创建外键关联的模型类的数据,不然创建包含外键的模型类的数据时,外键的关联模型类的数据会找不到。
3. 创建表结构
python manage.py migrate python manage.py makemigrations yangjianbo python manage.py migrate yangjianbo
4. 通过mysql插入数据
insert into app01_publish(name,city,email) values ("华山出版社", "华山", "hs@163.com"), ("明教出版社", "黑木崖", "mj@163.com")
# 先插入 authordetail 表中多数据
insert into app01_authordetail(gender,tel,addr,birthday) values (1,13432335433,"华山","1994-5-23"), (1,13943454554,"黑木崖","1961-8-13"), (0,13878934322,"黑木崖","1996-5-20")
# 再将数据插入 author,这样 author 才能找到 authordetail
insert into app01_author(name,age,au_detail_id) values ("令狐冲",25,1), ("任我行",58,2), ("任盈盈",23,3)
2. ORM插入数据
1. 一对多(外键ForeignKey)
第一种方法:views.py
def add_book(request):
# 获取出版社对象
pub_obj = models.Publish.objects.filter(pk=2).first()
# 给书籍的出版社属性publish传出版社对象
book = models.Book.objects.create(title="菜鸟教程", price=200, pub_date="2010-10-10", publish=pub_obj)
return HttpResponse(book)
第二种方法:views.py
def add_book(request):
# 获取出版社对象
pub_obj = models.Publish.objects.filter(pk=1).first()
# 获取出版社对象的id
pk = pub_obj.pk
# 给书籍的关联出版社字段 publish_id 传出版社对象的id
book = models.Book.objects.create(title="冲灵剑法", price=100, pub_date="2004-04-04", publish_id=pk)
print(book, type(book))
2. 多对多:在第三张关系表中新增数据
步骤:
1. 获取作者对象
2. 获取书籍对象
3. 给书籍对象的authors属性用add方法传作者对象
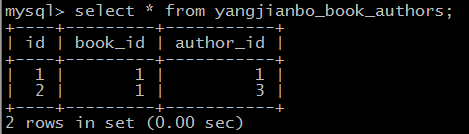
第一种方法:
views.py
def many_book(request):
#获取作者对象
ying=models.Author.objects.filter(name="任盈盈").first()
chong=models.Author.objects.filter(name="令狐冲").first()
#获取书籍对象
book=models.Book.objects.filter(title="菜鸟教程").first()
book.authors.add(ying,chong)
urls.py
from django.conf.urls import url
from yangjianbo import views
urlpatterns = [
url(r'^index/(?P<m>[0-9]{2})/$', views.index,name="index"),
url(r'login1/', views.login, name="login"),
url(r'add_book/', views.add_book),
url(r'findall_book/', views.findall_book),
url(r'filter_book/', views.filter_book),
url(r'exclude_book/', views.exclude_book),
url(r'get_book/', views.get_book),
url(r'order_book/', views.order_book),
url(r'reverse_book/', views.reverse_book),
url(r'count_book/', views.count_book),
url(r'first_book/', views.first_book),
url(r'last_book/', views.last_book),
url(r'exists_book/', views.exists_book),
url(r'values_book/', views.values_book),
url(r'values_list_book/', views.values_list_book),
url(r'distinct_book/', views.distinct_book),
url(r'delete_book/', views.delete_book),
url(r'update_book/', views.update_book),
url(r'many_book/', views.many_book),
]
结果:查看一下表yangjianbo_book_authors
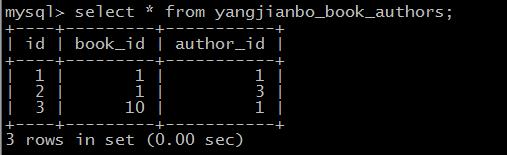
第二种方法:
views.py
def many_book(request):
#获取作者对象
chong=models.Author.objects.filter(name="令狐冲").first()
pk=chong.pk
#获取书籍对象
book=models.Book.objects.filter(title="冲灵剑法").first()
book.authors.add(pk)
结果:
3. 关联管理器
1. 前提:
多对多(双向均有关联管理器)
一对多(只有多那个类的对象有关联管理器,即反向才有)
2. 语法:
正向:属性名
反向:小写类名加_set
3. 常用方法
1. add() 用于多对多,把指定的模型对象添加到关联对象集中
例子:
views.py
def add_book(request):
book_obj=models.Book.objects.get(id=10) #获取书籍的模型对象
author_obj=models.Author.objects.filter(id__gt=2) #获取作业的id大于2的QuerySet对象
book_obj.authors.add(*author_obj) #第一种方法添加数据
book_obj.authors.add(*[2]) #第二种方法添加数据
方向例子:
views.py
def add_book(request):
ying=models.Author.objects.filter(name="任盈盈").first()
book=models.Book.objects.filter(title="冲灵剑法").first()
ying.book_set.add(book)
2. create() 创建一个新的对象,并同时把它添加到关联对象集中
views.py
def add_book(request):
pub=models.Publish.objects.filter(name="明教出版社").first()
wo=models.Author.objects.filter(name="任我行").first()
book=wo.book_set.create(title="吸星大法", price=300, pub_date="1999-9-19", publish=pub)
print(book,type(book))
3. remove() 从关联对象集中删除指定的模型对象
views.py
def remove_book(request):
author_obj=models.Author.objects.get(id=1)
book_obj=models.Book.objects.get(id=10)
author_obj.book_set.remove(book_obj)
4. clear() 从关联对象集中删除一切对象,删除关联,不会删除对象
views.py
def clear_book(request):
book = models.Book.objects.filter(title="菜鸟教程").first()
book.authors.clear()
3. ORM查询数据
1. 一对多
正向views.py
def select_book(request):
book=models.Book.objects.filter(pk=1).first() #获取书籍对象
res=book.publish.city #通过书籍正向查找对应的出版社的城市
print(res,type(res))
反向views.py
def select_book(request):
pub=models.Publish.objects.filter(name="明教出版社").first() #获取出版社对象
res=pub.book_set.all() #反向查找书籍的QuerySet对象
for i in res:
print (i.title,type(i))
2. 一对一
正向views.py
def select_book(request):
user=models.Author.objects.filter(name="令狐冲").first() #获取作者对象
res=user.au_detail.tel #使用正向查找作者的电话
print(res,type(res))
反向views.py
def select_book(request):
addr=models.AuthorDetail.objects.filter(addr="黑木崖").first() #获取地址为黑木崖的作者详细对象
res=addr.author.name #一对一的不需要使用_set,直接使用对象.表名就可以了。
print(res,type(res))
3. 多对多
正向views.py
def select_book(request):
book=models.Book.objects.filter(title="冲灵剑法").first()
res=book.authors.all()
for i in res:
print(i.name,i.au_detail.tel)
反向views.py
def select_book(request):
user=models.Author.objects.filter(name="任我行").first()
res=user.book_set.all()
for i in res:
print(i.title)
4. 基于双下划线的跨表查询
正向:属性名称__跨表的属性名称 反向:小写类名__跨表的属性名称
1. 一对多
查询菜鸟出版社出版过的所有书籍的名字与价格
正向views.py
def select_book(request):
res = models.Book.objects.filter(publish__name="明教出版社").values_list("title", "price")
反向views.py
def select_book(request):
res = models.Publish.objects.filter(name="明教出版社").values_list("book__title", "book__price")
print(res)
2. 一对一
正向views.py
查询任我行的手机号
def select_book(request):
res=models.Author.objects.filter(name="任我行").values_list("au_detail__tel")
print(res)
反向views.py
def select_book(request):
res=models.AuthorDetail.objects.filter(author__name="任我行").values_list("tel")
print(res)
3. 多对多
正向views.py
查询任我行出过的所有书籍的名字
def select_book(request):
res=models.Book.objects.filter(authors__name="任我行").values_list("title")
print(res)
反向views.py
def select_book(request):
res=models.Author.objects.filter(name="任我行").values_list("book__title")
print(res)
17. Django ORM聚合查询
1. 聚合查询
聚合查询函数是对一组值执行计算,并返回单个值。
Django使用聚合查询前要先从django.db.models引入Avg,Max,Min,Count,Sum
from django.db.models import Avg,Max,Min,Count,Sum # 引入函数
聚合查询返回值的数据类型是字典
日期数据类型可以使用Max和Min
返回的字典中:键的名称默认是(属性名称加上__聚合函数名),值是计算出来的聚合值
aggregate(别名 = 聚合函数名("属性名称"))
例子:
1. 计算所有图书的平均价格
def price_book(request):
res=models.Book.objects.aggregate(Avg("price"))
print(res)
结果: {'price__avg': Decimal('225.000000')}
2. 计算所有图书的数量,最贵价格和最便宜价格
def price_book(request):
res=models.Book.objects.aggregate(c=Count("id"),max=Max("price"),min=Min("price"))
print(res,type(res))
2. 分组查询
分组查询一般会用到聚合函数
返回值:
分组后,用values取值,则返回值是QuerySet数据类型里面为一个个字典;
分组后,用values_list取值,则返回值是QuerySet数据类型里面为一个个元组;
注意:
annotate 里面放聚合函数。
-
-
-
-
values 或者 values_list 放在 annotate 前面:values 或者 values_list 是声明以什么字段分组,annotate 执行分组。
-
values 或者 values_list 放在annotate后面: annotate 表示直接以当前表的pk执行分组,values 或者 values_list 表示查询哪些字段, 并且要将 annotate 里的聚合函数起别名,在 values 或者 values_list 里写其别名。
-
-
-
例子:
1. 统计每一个出版社的最便宜的书


 浙公网安备 33010602011771号
浙公网安备 33010602011771号