
1999年——2019年十年国家人口比率分析
一、选题背景
新中国成立前期,由于国际局势紧张和斗争带来的影响,我国鼓励生育,后来由于人口的过快增长给社会经济发展带来了严重影响,我国从1970年开始实施计划生育,人口自然增长率开始下降,到现代由于老龄化危机和人口增长跟不上经济发展需求,中国逐步放开二胎政策(全面二胎)。由此可以看出,人口问题是影响我国经济发展的重要因素之一,因此有必要研究在新形势下自然增长率的情况。在进入新世纪以来,我国人口形势发生了重大变化。习同志指出:“当前,我国人口结构呈现明显的高龄少子特征,适龄人口生育意愿明显降低,妇女总和生育率明显低于更替水平。”这是对新时代人口发展特征的深刻概括。我们必须正视新情况、分析新问题、应对新挑战。所以本次课程设计根据相关统计数据分析我国1999年-2019年10年来的自然人口增长率。
二.主题式网络爬虫设计方案
1.主题式网络爬虫名称:国家数据网不同年份的人口比率
2.主题式网络爬虫爬取的内容:人口出生率死亡率及自然增长率
3.设计方案概述:
实现思路:爬取网站内容,之后分析提取需要的数据,进行数据清洗,之后数据可视化,并计算不同比率的相关系数
技术难点:因为用的是json分析,所以需要通过查找的方式获取数据,以及后面的3D模型图需要将整数转成浮点数
三、主题页面的结构特征分析
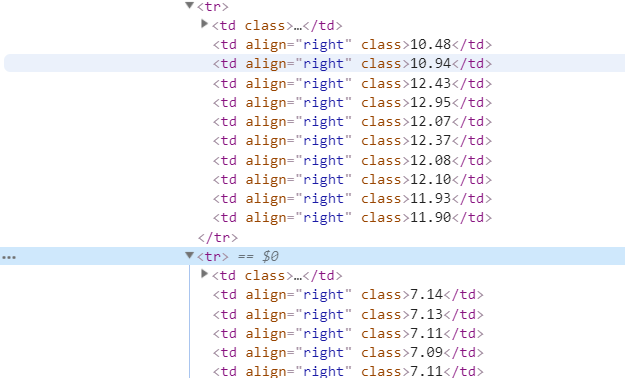
1.主题页面的结构与特征分析:打开开发者工具,通过逐个查找找到需要数据的所在位置,发现所需要的数据都在<tbody>
下的<tr>中
2. http://data.stats.gov.cn/easyquery.htm?m=QueryData&dbcode=hgnd&rowcode=sj&colcode=zb&wds=[]&dfwds={}

3.
四、网络爬虫程序设计
1.数据爬取与采集
1 import matplotlib.pyplot as plt
2 import numpy as np
3 import matplotlib
4 from mpl_toolkits.mplot3d import Axes3D
5 import seaborn as sns
6 import pickle
7
8 matplotlib.rcParams['font.sans-serif']=['SimHei']
9 # 用黑体显示中文
10 matplotlib.rcParams['axes.unicode_minus']=False
11 # 正常显示负号
12 dfwds = '[{"wdcode": "sj", "valuecode": "LAST21"}, {"wdcode":"zb","valuecode":"A0302"}]'
13 #网址的dfwds为上面所写的,以便更快的获取需要的数据
14 url='http://data.stats.gov.cn/easyquery.htm?m=QueryData&dbcode=hgnd&rowcode=sj&colcode=zb&wds=[]&dfwds={}'
15 #获取url
16 response = requests.get(url.format(dfwds)) #获取网页的数据
17 z=response.json() #获取网址的json
18 z=z['returndata'] #通过字典的key值,获取数据
19
20 z=z['datanodes']
21 print(z)
获取dfwds和url

2.对数据进行清洗和处理
1 birth_rate={} #分别设置三个字典,用来装后面的值
2 death_rate={}
3 natural_growth_rate={}
4 for i in range(len(z)//3): #通过循环,获取结果
5 #print("年份{}:出生率{}".format(z[i]['wds'][1]['valuecode'],z[i]['data']['data']))
6 birth_rate[z[i]['wds'][1]['valuecode']]=z[i]['data']['data']
7 #print(birth_rate)
8 for i in range(len(z)//3,len(z)//3*2):
9 #print("年份{}:死亡率{}".format(z[i]['wds'][1]['valuecode'],z[i]['data']['data']))
10 death_rate[z[i]['wds'][1]['valuecode']]=z[i]['data']['data']
11 #print(death_rate)
12 for i in range(len(z)//3*2,len(z)):
13 #print("年份{}:自然增长率{}".format(z[i]['wds'][1]['valuecode'],z[i]['data']['data']))
14 natural_growth_rate[z[i]['wds'][1]['valuecode']]=z[i]['data']['data']
15 #print(natural_growth_rate)
16 years=list(birth_rate.keys()) #把字典里面的key和value都拿出来,分别转成列表类型
17 rate1=list(birth_rate.values())
18 rate2=list(death_rate.values())
19 rate3=list(natural_growth_rate.values())
20 d={'出生率 ':rate1, #将数值带入
21 '死亡率 ':rate2,
22 '自然增长率 ':rate3}
23 df=pd.DataFrame(d,index=years) #将年份和比率结合一起
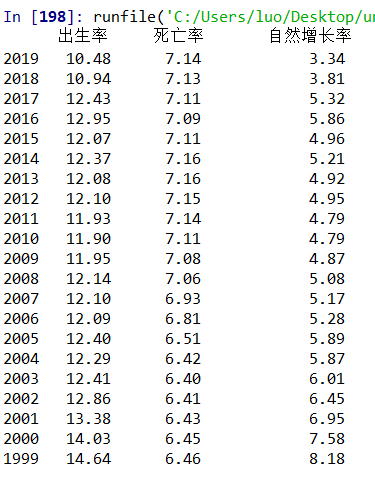
24 print(df) #输出结果
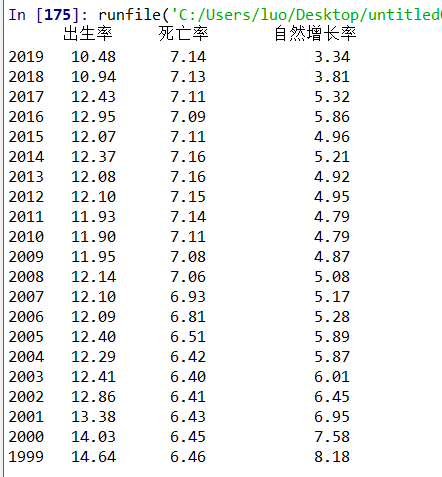
3.文本分析(可选):因为都是数字,所以这里没有用到文本分析
4.数据分析与可视化:
(1)折线图

(2)柱状图
1 #绘制柱状图
2 plt.figure(figsize=(12,8),dpi=80) #设置绘制的图像和字体大小
3 x = np.arange(21) #总共有几组,就设置成几,我们这里有21组,所以设置为21
4 total_width, n = 0.8, 3
5 # 有多少个类型,只需更改n即可,比如这里我们对比了3个,那么就把n设成3
6 width = total_width / n
7 x = x - (total_width - width) / 2
8 plt.bar(x, rate1, color = "r",width=width,label='birth_rate')
9 plt.bar(x + width, rate2, color = "y",width=width,label='death_rate')
10 plt.bar(x + 2 * width,rate3 , color = "c",width=width,label='natural_growth_rate')
11 plt.xlabel("year")
12 plt.ylabel("rate")
13 plt.legend(loc = "best")
14 plt.xticks([0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21],years)
15 #这里之所以一个个打,因为快一点
16 my_y_ticks = np.arange(0, 20, 2)
17 plt.ylim((0, 20))
18 plt.yticks(my_y_ticks)
19 plt.show()
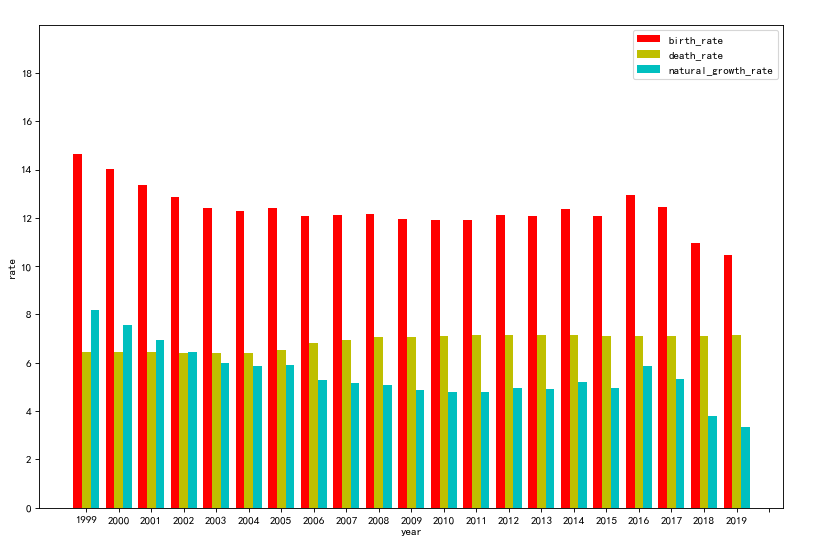
(3)直方图
1 #绘制直方图
2 plt.figure(figsize=(12,8),dpi=80)
3 plt.hist(rate1,bins=40, normed=0, facecolor="blue", edgecolor="blue", alpha=0.7)
4 #bins是直方图的长条形数目
5 plt.hist(rate2,bins=40, normed=0, facecolor="yellow", edgecolor="yellow", alpha=0.7)
6 #normed是否将得到的直方图向量归一化
7 plt.hist(rate3,bins=40, normed=0, facecolor="green", edgecolor="green", alpha=0.7)
8 plt.xlabel("比率")
9 plt.ylabel("总数")
10 plt.title("人口比率直方图")
11 plt.show() #蓝色是出生率,黄色是死亡率,绿色是自然增长率

(4)堆叠条形图

(5)横向柱状图
1 #绘制横向的柱状图 2 plt.figure(figsize=(12,8),dpi=80) 3 a=0.3 #设置分开的间隔 4 index = np.arange(1999,2020) 5 plt.barh(index,rate1, a, color = 'brown', label = 'birth_rate') 6 plt.barh(index+a, rate2, a, color = 'pink', label = 'death_rate') 7 plt.barh(index+2*a, rate3, a, color = 'orange',label = 'natural_growth_rate') 8 plt.legend()
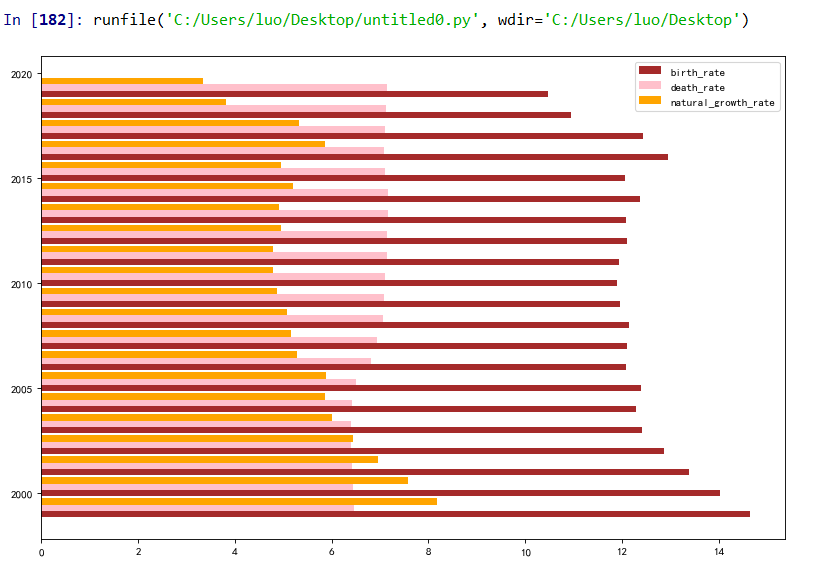
(6)饼图
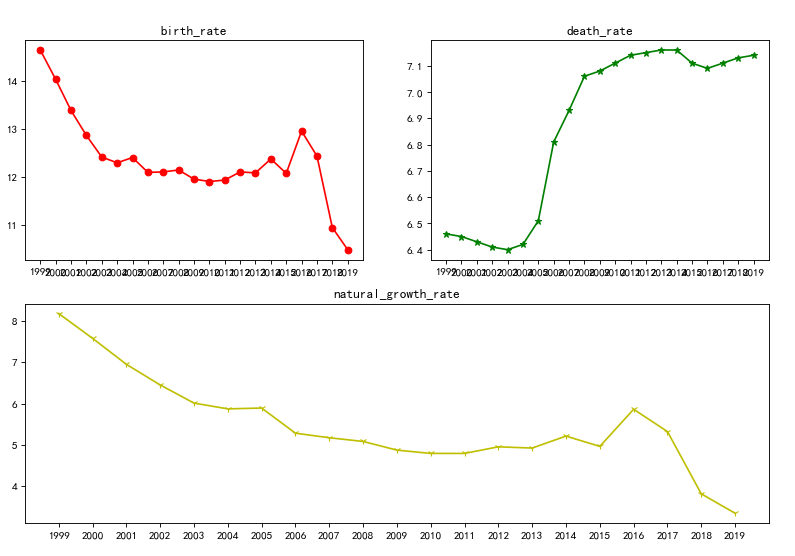
(7)子图
(8)三维图
(9)三维曲面图
1 #绘制三维曲面 2 fig = plt.figure(figsize=(14,8),dpi=80) #定义新的三维坐标轴 3 ax3 = plt.axes(projection='3d') 4 ratel1=[] 5 ratel2=[] 6 ratel3=[] 7 for i in rate1: #这里因为不是整数就运行不了,所以将浮点数类型变成整数类型 8 ratel1.append(int(i)) 9 for i in rate2: 10 ratel2.append(int(i)) 11 for i in rate3: 12 ratel3.append(int(i)) 13 xx = ratel1 #这样能更清晰的知道X,Y,Z轴 14 yy = ratel2 15 zz = ratel3 16 X, Y = np.meshgrid(xx, yy) 17 Z = np.sin(X)+np.cos(Y) +2 18 ax3.plot_surface(X,Y,Z,cmap='rainbow') 19 #x代表出生率,y代表死亡率,z代表自然增长率 20 plt.show()
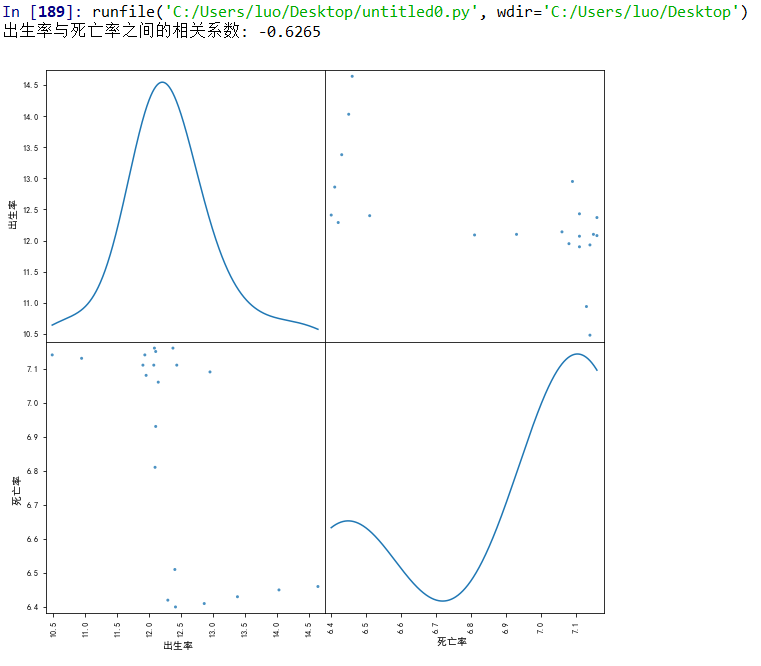
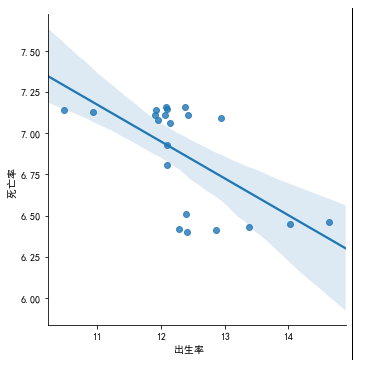
5.根据数据之间的关系,分析两个变量之间的相关系数,画出散点图,并建立变量之间的回归方程
(1)年份与出生率
1 #年份与出生率之间的相关系数,以及散点图
2 yearl=[]
3 years=years[::-1] #因为df出生率是正的,而之前年份倒过来过,所以这里需要倒一次
4 for i in years:
5 yearl.append(float(i))
6 year = pd.Series(yearl) #利用Series将列表转换成新的、pandas可处理的数据
7 birth_rate = pd.Series(rate1)
8 corr_gust = round(year.corr(birth_rate), 4) #计算标准差,round(a, 4)是保留a的前四位小数
9 print('年份与出生率之间的相关系数:', corr_gust)
10 plt.figure(figsize=(12,8),dpi=80)
11 sns.stripplot(x =years,y = '出生率 ',data = df)

(2)出生率与死亡率
6.数据持久化

7.将以上各部分的代码汇总,附上完整程序代码
五、结论
1.经过对主题数据的分析与可视化得到的结论:通过对数据的分析以及可视化可以看出,近几十年来我国的出生率逐渐降低,死亡率逐渐升高,自然增长率也因此逐年下降
2.对本次程序设计任务完成的情况做一个简单的小结:
回顾本次的课程设计,至今我仍感慨颇多,从理论到实践,在这段日子里,能够说得是苦多于甜,但是能够学到很多很多的东西,同时不但能够巩固了以前所学过的知识,而且学到了很多在书本上所没有学到过的知识。通过这次课程设计我懂得了理论与实际相结合是很重要的,只有理论知识是远远不够的,只有把所学的理论知识与实践相结合起来,从理论中得出结论,才能真正为社会服务,从而提升自己的实际动手水平和独立思考的水平。在设计的过程中我遇到了很多问题,能够说得是困难重重,但可喜可贺的是最终都得到了解决。本来以为自己都学的差不多了 ,但是实际自己动手操作起来,才发现没有那么简单,很多东西都要查资料,同时也发现了如CDSN这样的博客网以及博客园和CDSN都有的众多文章可以参考,总结前人的经验补充自己的知识。在这次对1999年-2019年十年国家数据网的人口比率分析的过程中,我也从中学会了不少函数及用法。编程一行还是要不断学习不断动手才可以越走越远,如同逆水行舟不进则退。今后我将更加努力学习,每天进步一点点做最好的自己,加油!

