

卷积神经网络入门
卷积神经网络入门
CNN 通过卷积层(特征提取)→ 归一化(稳定训练)→ 激活(非线性)→ 池化(降维)→ 全连接(分类)的协同流程实现端到端学习
卷积层
负责 局部特征提取,通过滑动窗口(卷积核)在输入数据上计算加权和,生成具有空间层次结构的特征图。
从卷积核开始,这是一个小的权值矩阵。这个卷积核在 2 维输入数据上「滑动」,对当前输入的部分元素进行矩阵乘法,然后将结果汇为单个输出像素。
| 参数 | 说明 | 默认值 |
|---|---|---|
| kernel_size | 卷积核大小(K,如 3 或 (3, 5)) |
- |
| stride | 滑动步长 | 1 |
| padding | 边缘填充(像素数) | 0 |
| dilation | 空洞卷积(控制核的稀疏性) | 1 |
| bias | 是否添加偏置项(β) |
True |
| in_channels | 输入通道数(C_in) |
- |
| out_channels | 输出通道数(C_out) |
- |
输出矩阵的大小计算公式:
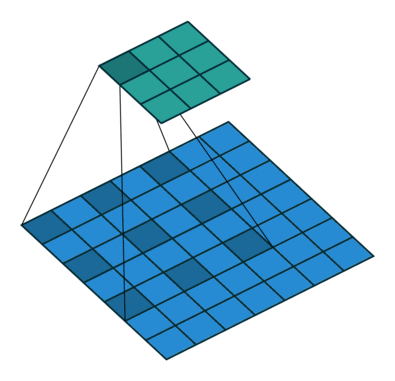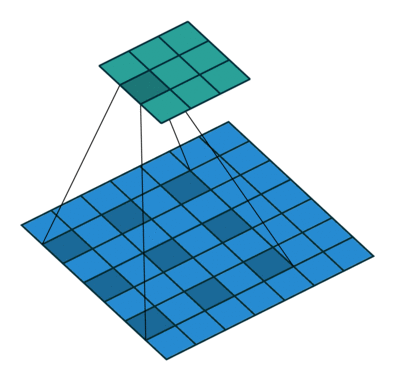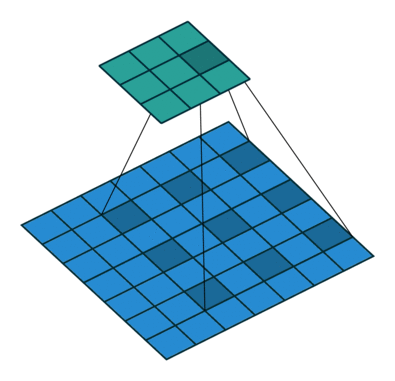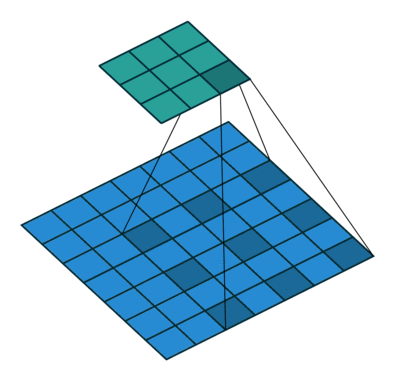
场景1(常规场景):
kernel_size = 3
stride = 1
padding = 0
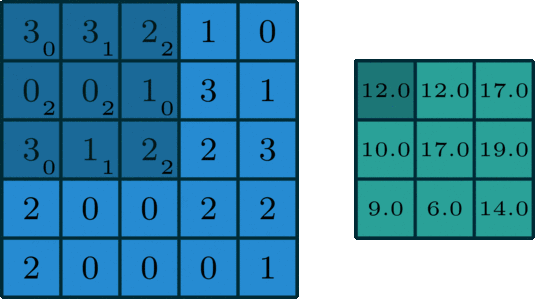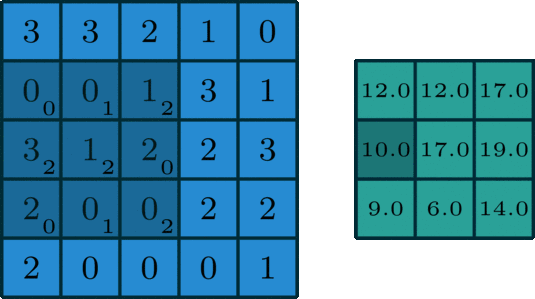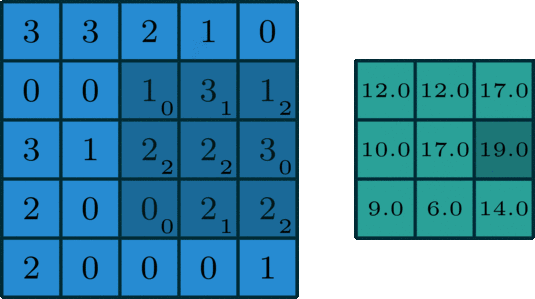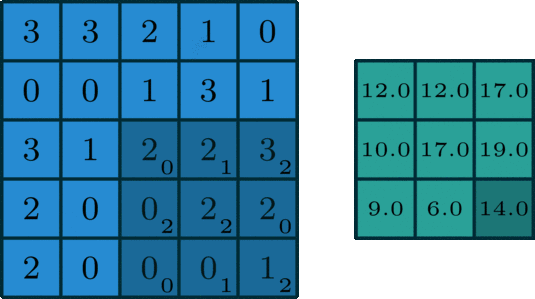
此时输出矩阵的大小为:
场景2(边缘填充):
kernel_size = 3
stride = 1
padding = 1
在上图的卷积核滑动的过程中,将 5x5 特征矩阵转换为 3x3 的特征矩阵,边缘上的像素永远不在卷积核的中心。
Padding 做了一些非常机智的办法来解决这个问题:用额外的「假」像素(通常值为 0, 因此经常使用的术语「零填充」)填充边缘。这样,在滑动时的卷积核可以允许原始边缘像素位于其中心,同时延伸到边缘之外的假像素,从而产生与输入相同大小的输出。
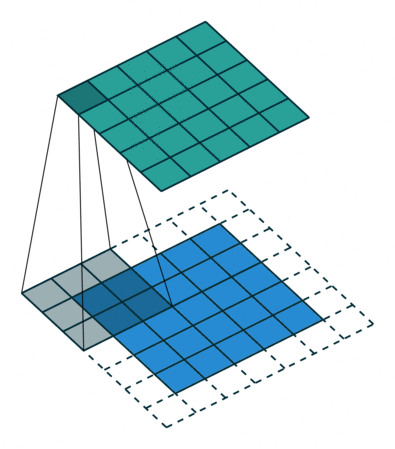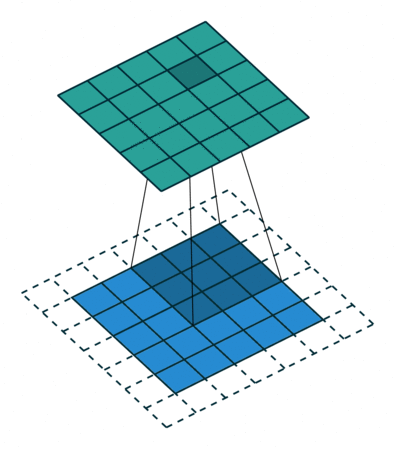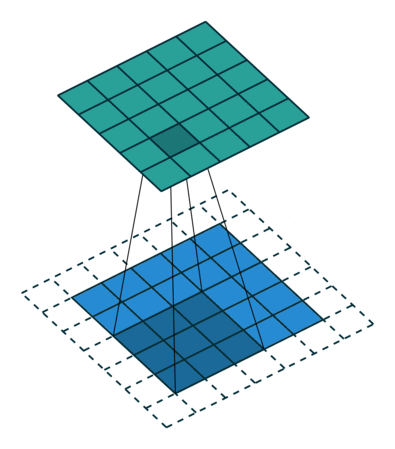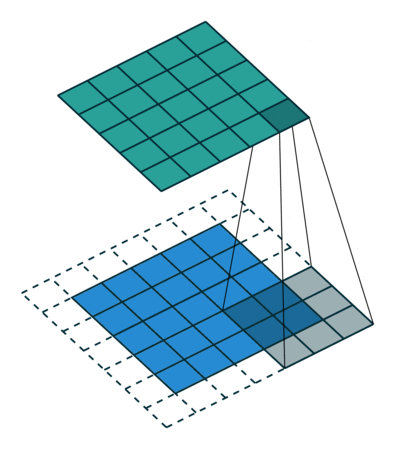
此时输出矩阵的大小为:
场景3(步长>1):
kernel_size = 3
stride = 2
padding = 0
Stride 是改变卷积核的移动步长跳过一些像素。Stride 是 1 表示卷积核滑过每一个相距是 1 的像素,是最基本的单步滑动,作为标准卷积模式。Stride 是 2 表示卷积核的移动步长是 2,跳过相邻像素,图像缩小为原来的 1/2。Stride 是 3 表示卷积核的移动步长是 3,跳过 2 个相邻像素,图像缩小为原来的 1/3。
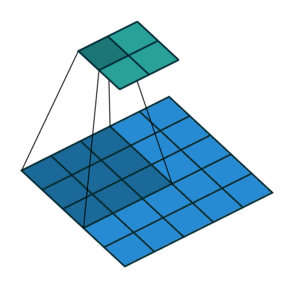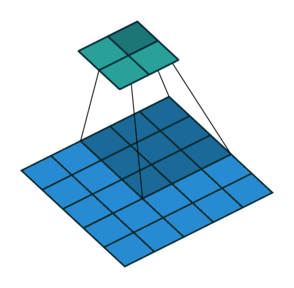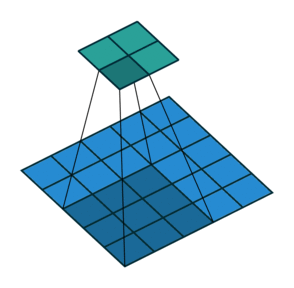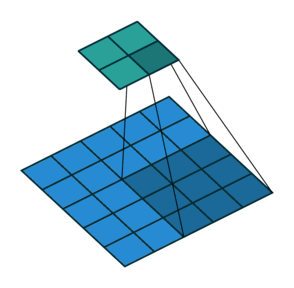
此时输出矩阵的大小为:
场景4(空洞卷积):
kernel_size = 3
stride = 2
padding = 0
dilation = 2
通过引入空洞率(dilation rate)来扩大卷积核感受野的特殊卷积方式,在不增加参数量或计算量的情况下捕捉更广范围的上下文信息
此时输出矩阵的大小为:
归一化层
将每层的输入调整为均值为0、方差为1的分布,避免内部协变量偏移,对每个通道单独归一化,保留空间信息。
最常用的归一化层类型是 BatchNorm2d
参数
| 参数名 | 作用 | 默认值 |
|---|---|---|
| num_features | 输入通道数(C) |
- |
| eps | 数值稳定项(防止除零) | 1e-5 |
| momentum | 运行统计量的动量(EMA衰减率) | 0.1 |
| affine | 是否启用可学习的γ和β | True |
| track_running_stats | 是否跟踪运行统计量 | True |
num_features是最常用参数
输入输出
输入:(N, C, H, W)
N:Batch Size
C:通道数(需与 num_features 一致)
H, W:特征图高度和宽度
输出:(N, C, H, W)(尺寸不变)
仅对通道维度进行归一化,空间维度(H, W)完全保留。
激活层
作用
- 引入非线性:突破线性模型的限制(否则多层网络等效于单层)。
- 控制输出范围:如Sigmoid将输出压缩到(0,1),适合概率。
- 稀疏激活:如ReLU的“单侧抑制”可增加稀疏性。
常用激活函数及特性
| 激活函数 | 适用场景 | 注意事项 |
|---|---|---|
| ReLU | 大多数CNN/全连接层 | 小心“神经元死亡” |
| LeakyReLU | 需要缓解ReLU缺陷的深层网络 | 调参negative_slope |
| Sigmoid | 二分类输出层 | 避免用于隐藏层 |
| Tanh | RNN、生成模型 | 梯度消失问题 |
| Swish/GELU | Transformer、现代CNN | 计算量略高 |
| Softmax | 多分类输出层 | 需配合交叉熵损失 |
输入输出
- 输入:任意形状张量(如 (N, C, H, W))
- 输出:与输入形状完全相同,仅对每个元素独立应用激活函数
池化层
作用
- 降维:减少特征图尺寸,降低计算量和内存消耗。
- 平移不变性:对微小位置变化不敏感(如Max Pooling保留最强特征)。
- 防止过拟合:减少参数数量,类似正则化效果。
- 扩大感受野:通过降维,后续卷积层能覆盖更大输入区域
常见的池化层类型
- 最大池化(Max Pooling)
- 平均池化(Average Pooling)
- 全局池化(Global Pooling)
参数
| 参数名 | 作用 | 默认值 |
|---|---|---|
kernel_size |
池化窗口大小(如2x2) | - |
stride |
滑动步长 | 同kernel_size |
padding |
边缘填充(较少用) | 0 |
ceil_mode |
尺寸计算向上取整(True/False) | False |
输入输出
输入尺寸:(H_in, W_in)
输出尺寸:(H_out, W_out)
全连接
作用
- 特征整合:将卷积层和池化层提取的 空间特征 转换为一维向量,并进行高阶组合。
- 分类/回归:输出每个类别的概率(配合 Softmax)或回归值(如目标检测中的边界框坐标)。
- 可学习参数:通过权重矩阵实现特征间的全局交互。
参数
| 参数名 | 作用 | 示例值 |
|---|---|---|
in_features |
输入特征维度(需展平后大小) | 1024 |
out_features |
输出特征维度(如类别数) | 10 |
bias |
是否添加偏置项(True/False) |
True |
输入输出
- 输入形状:一般为
(N, *, in_features),其中*表示可选的额外维度(需先展平)。 - 输出:
(N, out_features)(N为 Batch Size,out_features如类别数)


 浙公网安备 33010602011771号
浙公网安备 33010602011771号