

将RabbitMq用好需要了解的一些基础知识
本文面向有一定RabbitMq基础的童鞋.
首先,我们来理理RabbitMq的一些基本概念:
Connection: 客户端与RabbitMq服务器节点的Tcp链接.
Channel: 信道,因为一条Tcp链接建立的开销代价(三次握手之间的通信过程)比较大,所以RabbitMq采用了多路复用的设计,也就是一个Connection对应多个Channel,每个Channel都有自己的唯一标志以进行区分,同时Channel最好不要在多线程之间进行共享,在字节流通信层面会有线程安全的问题.所以这里与Nio有点相反,Nio是一个线程对应多个连接,而这里可能是多个线程对应一个连接.
Produce: 生产者
Exchange: 路由器,可以说是RabbieMq最核心的概念,实质上可以看做是一个Map<String,List<Queue>> 的数据结构,Key为我们的BindingKey,Value为绑定了这个BindingKey的队列集合.
Queue: 这个才是RabbitMq存放数据的容器,但是客户端不会直接与其通信.客户端只能通过Exchange与队列交互.
Consumer: 消费者
介绍完基本概念,再来详细说说Exchange的四种类型:
1. Direct:
这种类型,可以看做是精准匹配,类似我们sql语句里直接使用 = 条件作为判定一样,也就是bindingKey必须要与RoutingKey,一模一样才行,可以参考下面的图
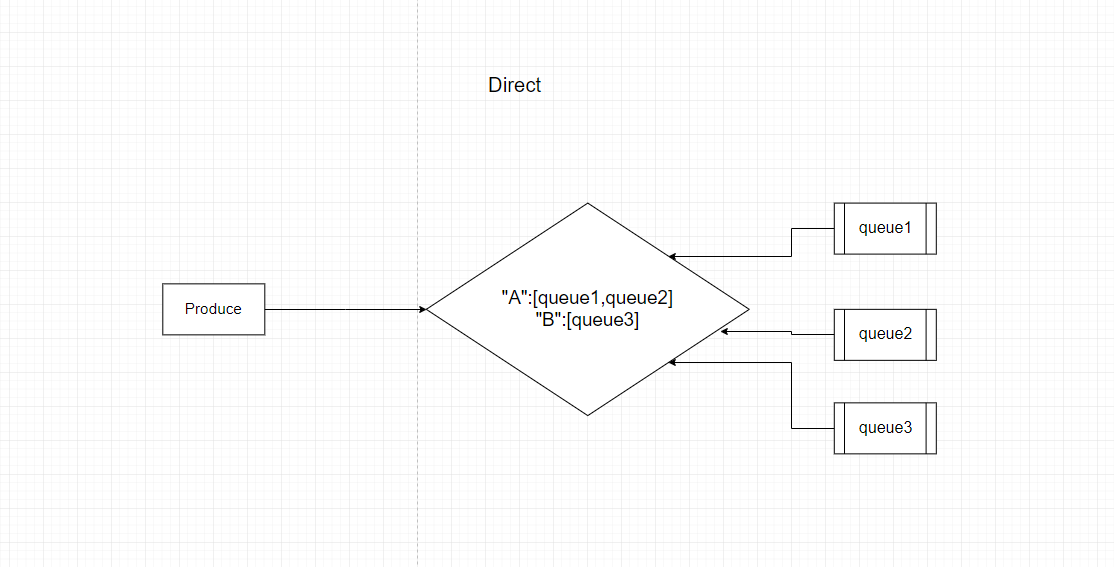
从图中可以看到,queue1和queue2的bindingKey为"A",queue3的bindingKey为"B",如果此时produce端发了一个routingKey为"A"的消息到了Exchange,那么这条消息就会发到queue1和queue2两个队列上,而如果bindingKey为"B",那么就会路由到queue3上.
2.topic:
这个模式可以看做是Direct的增强型,也就是带模糊匹配的功能,类似于sql中的%%符号,只不过Topic的符号是*匹配一个标识符,#匹配多个标识符(这里吐槽一句,按照人们的惯性思维,*才应该是匹配多个的不是吗?)
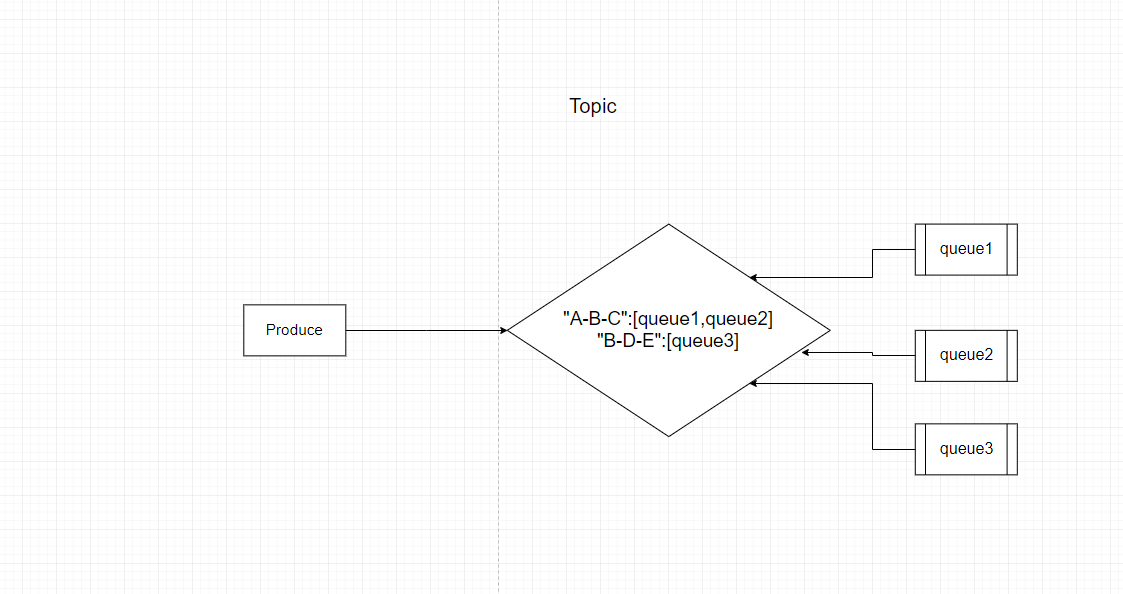
比如此时如果Produce发送了一个routingKey为*-B-*的消息,就会被路由到queue1和queue2,并在其中负载均衡选择其一进行路由,而如果是B-#或者是B#,那么此时就会路由到queue3,这个模式一般适合子类型很多,但是父类型不是很多,而每个子类型可能都有一个单独的Direct模式的队列需要精准路由匹配,而针对于父类型,则弄个统一的前缀,然后模糊匹配即可.
3.Headers:
这种跟Direct类型的 区别就是Direct只需要比较一个值,而它则需要比较一个键值对,而且性能很差,基本没有应用场景,所以这里不多说.
4.Fanout:
这种模式跟上述的区别在于,它是无视routingKey和Bindingkey的,所以如果选定了这个模式的Exchange,那么你发送的消息将会被发送到所有绑定的队列中。
队列数据的持久化:
关于RabbitMq队列数据的持久化功能,与其他的队列中间件是有所区别的,因为RabbitMq的Exchange是一个逻辑概念,queue则是真正的物理概念,同时也是内存中一个单独的进程,但queue又是完全依赖于Exchange的,所以我们首先需要让Exchange进行持久化.也就是 channel.exchangeDeclare(String exchangeNmae,String type, boolean durable,boolean autoDelete,boolean internal,Map arguments);里的第三个参数durable,在设置Exchannge的持久化之后,这里再多说一下,第四个参数的意思是,在创建了这个Exchange并且有客户端连接后,如果所有客户端全部断开连接了,那么自动删除这个Exchange,第五个参数是客户端是否可以直接连接到这个Exchange,如果是true,那么就必须要通过一个中间的Exchange连接.
在设置完了Exchange的持久化后,我们还需要对队列进行持久化,但是要注意的是,队列的持久化并不是指队列数据的持久化,而是单单指这个队列元数据(队列名称,参数,bindingKey等等)的持久化,channel.queueDeclare(String queueName,boolean durable,boolean exclusive,boolean autoDelete,Map arguments);将第二个参数设置为true即可实现队列元数据的持久化,这里说下第三个参数exclusive的意思是,这个队列是否排他,如果设置为true,那么这个队列就仅仅能被这个Connection下的channel所用.而在设置完queue的持久化后,我们还必须要针对于每条消息都指明其实持久化数据,rabbitMq客户端已经为我们封装了现成的properties了,也就是channel.basicPublish("exchange.persistent", "persistent", MessageProperties.PERSISTENT_TEXT_PLAIN, "persistent_test_message".getBytes());里的MessageProperties.PERSISTENT_TEXT_PLAIN,其实也就是将BasicProperties中的deliverMode属性设置为2而已.
所以rabbitmq的持久化顺序为: Exchange->Queue->具体的消息
事务与确认机制:
RabbitMq是提供事务功能的,也就是channel.txSelect();使用此方法即可开始事务,之后使用tryCatch包裹住发送消息的代码,在catch里使用channel,txRollback()方法,如果没有异常则使用channel.txCommit()方法进行提交即可,但是要注意的是,事务机制会增加四次通信,分别是,像服务端发送开始事务确认消息,等待服务器确认消息,在发送完消息之后则是事务提交消息,以及等待服务端返回事务提交成功消息,因为这个过程完全是同步的,所以会极大的拖低效率,所以不推荐使用,而针对于事务功能的效率低下,也就出现了我们即将要说的确认机制.
首先说明,确认机制分为两种,一种是同步,一种是异步,其实确认机制相比事务只是少了一次commit确认消息提交这一次客户端到服务端的交互而已,所以确认机制的同步并不能多好的提升效率,真正能提升效率的是确认机制的异步,相当于一个补偿机制,发送完消息后,不需要阻塞等待,而是注册一个回调事件等服务器回调即可,不过这样的问题在于在某些业务场景下,因为异步补偿的重发机制,所以可能会有后发的消息实际上先消费而导致出问题,所以这点在编写业务代码的时候需要考虑进去.
消费者的ack:
这里要注意,rabbitmq一定要把autoAck设置false,因为rabbitmq如果设置为true的话,那么在服务器推送了这条消息到消费端后,马上就会把这条消息设置为已经被ack了,但实际上消费端可能会出异常或者挂掉,此时消息就会丢失,而使用手动ack的话,消费端可以手动将消息重新入队,调用channel.basicReject()或者channel.basicNack()方法即可,这两者的区别在于前者只能一次拒绝或重新入队一条,而后者可以指定一个消息id,批量的直接拒绝或重新入队这个id之前的所有消息.
还有一点要说明的就是,rabbitmq如果设置为手动ack的话,那么如果客户端一直不ack并且没有断开连接,此时消息在rabbitmq的节点里就一直处于未ack的状态,不管多久,没有时间限制.哪怕设置了ttl过期时间也没用,因为ttl消息过期时间是针对于未被消费的消息的.
消费者推模式和拉模式:
推模式:
此种模式是最常用的,也就是继承一个DefaultConsumer()类,复写一个方法(其实就是设置回调方法,当服务器推送消息时,就会调用这个),有一个问题在于,服务端不知道客户端的消费情况,又因为每个服务器的性能和业务逻辑都不同导致有的队列一直在消费,而有的队列则很闲,但是服务端都一视同仁的对这些消费者客户端负载均衡,所以使用一个channel.basicQos(int count);来指定此消费者同时能消费的消息数量,只有当一条消息被ack后,消费端同时在消费消息数量才会-1.
拉模式:
也就是调用channel.basicGet()方法,此种方法的问题与推模式相反.也就是客户端不知道服务端的状态,必须要轮询或者定时去访问服务端,但是很难掌握好这个时间节点,因为间隔太短会导致服务端压力太大,而太长则导致消息不能及时获取,并且这种方法一次只能拉一条.
死信队列与延迟队列:
一条消息如果找不到对应的路由队列并且没有设置备份队列并且没有mandatory(是否将找不到queue的消息返回给客户端)参数或者说这条消息设置了ttl过期时间,并且已经超过了过期时间还没有被消费的话,那么此时就会进入死信队列,不过要注意的是,死信队列也只是一个普通的队列,也是可以被监听的,所以一般死信队列的应用场景更多的在于将其和ttl相结合变成一个延迟队列,比如如果想弄设置一个一个小时后才会被消费的任务,只需要弄一个没有被任何消费者监听的队列,然后发送一条消息到这个队列上,并且设置ttl为一个小时,在一个小时没有被消费后,这条消息就会进入死信队列,此时再设置一个消费者监听这个队列,就完成了延迟队列的功能.
消息的优先级:
rabbitmq是有优先级这个功能的,但是实际上因为不是强顺序性,所以使用场景并不是很多,这里不多描述.
关于负载均衡:
在rabbitmq中,多个不同队列使用相同的bindingkey并不会使消息均衡的落在这些队列上,而是每个队列都可以获得对应这个bindingkey的routingkey的全量消息(fanout模式会忽略bindingkey和routingkey,只要绑在这个exchange上了就会全部获得),所以rabbitmq的负载均衡只能存在于消费者端,也就是多个消费者消费同样的队列即可负载均衡
拓展:
rabbitmq的集群概念:
rabbitmq的集群状态下,每个节点都会拥有集群的全量元数据(vhost,用户权限,exchange和queue的元数据),而不是具体的消息数据,原因也很简单,如果是全量的消息数据的话,那么内存最小的节点就会是集群的瓶颈,所以如果想要设置备份数据的话,可以使用rabbitmq的镜像队列功能
最后,rabbitmq和其他分布式系统一样也有针对于网络分区的功能,这点请感兴趣的自行了解.百度orGoogle rabbitmq 网络分区 即可.


 浙公网安备 33010602011771号
浙公网安备 33010602011771号