java并发学习--线程池、并发容器和应用
线程池
为什么要使用线程池
①:降低了资源的消耗,在不使用到线程池的地方,工作的时候线程会创建销毁,但是在线程池就减少了创建和销毁线程的次数,每个工作线程都可以被重复利用,可执行多个任务。
②:提高响应时间,因为线程池避免砸执行任务时的线程的创建和销毁,那么占的cpu时间会减少,那么响应时间就有所提升。
③:提高了线程的课管理性,可以根据系统的承受能力,调整线程池中工作线线程的数目,防止因为消耗过多的内存,而把服务器累趴下(每个线程需要大约 1MB 内存,线程开的越多,消耗的内存也就 越大,最后死机)
线程池的继承模型
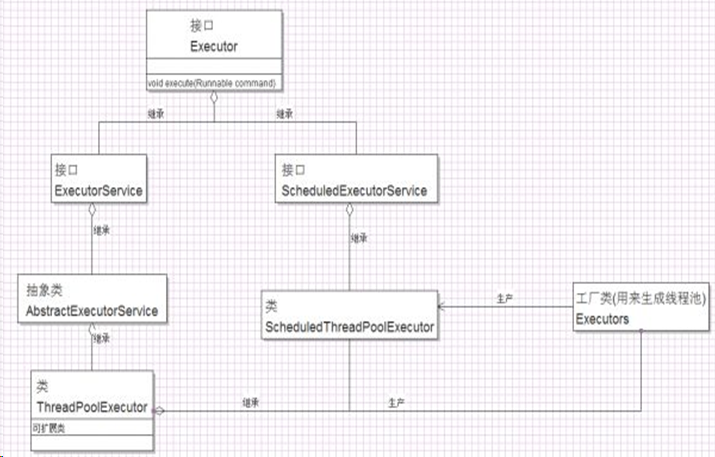
线程池的顶级接口是Executor,顶级接口派生出两个接口,ExecutorService和ScheduleExecutorService(专注于定时任务),这两个接口才可以认为是线程池实现的接口,线程池的最终实现类是ThreadPoolExecutor, 它包含以下几种线程池:FixedThreadPool、SingleThreadExecutor、CacheThreadPool、ScheduleThreadPoolExecutor。但是线程池的创建一般使用Executors的工厂类方式创建。
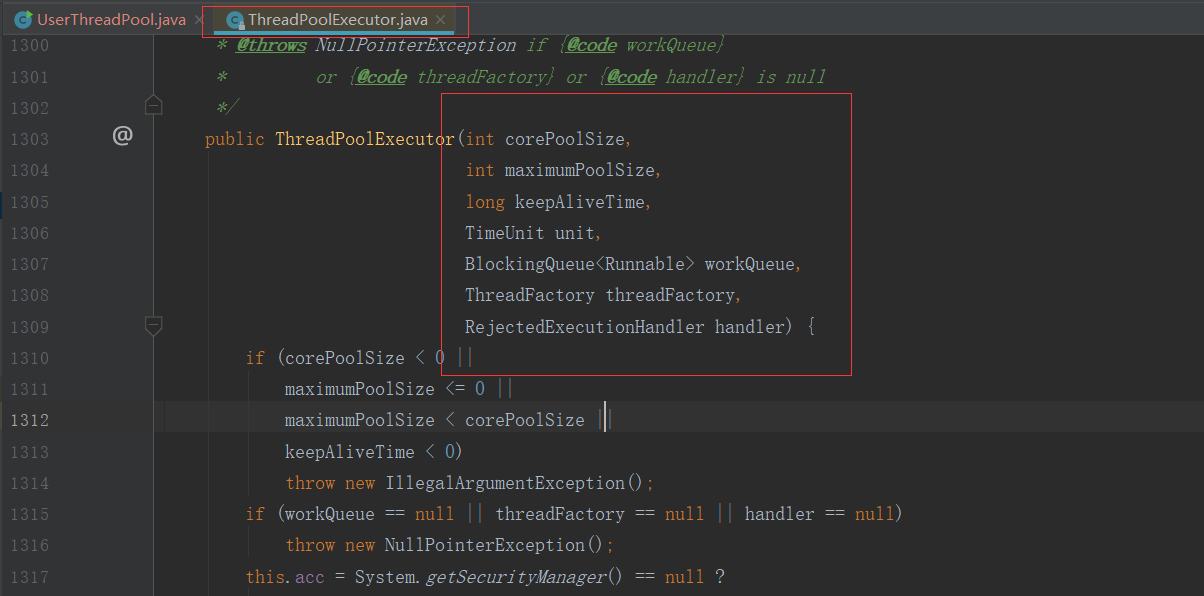
查看ThreadPoolExecutor的源码,他的构造器如下:
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {......}
corePoolSize:表示线程的核心数量。
maximumPoolSize:线程的最大线程数量。
keepAliveTime:空闲线程存活的时间,是指最大线程数量里的没有工作的线程的存活时间,核心线程空闲时不会被释放的。
unit:时间的单位。
workQueue:阻塞队列,在核心线程数量到达上限以后,往阻塞队列中存放任务,等待线程,一般分为有界队列还是无界队列。
threadFactory:线程工厂,缺省的线程命名规则:pool+数字 +thread+数字。
RejectedExecutionHandler:表示当线程池,阻塞队列满了并且已经没有空闲的工作线程的时候,这种称为饱和策略。
①:AbortPolicy:直接抛出异常,默认
②:CallerRunsPolicy:使用调用当前任务的线程去执行任务。
③:DiscardOldestPolicy:丢弃当前线程中最老的任务。
④:DiscardPolicy:直接丢弃。
查看ThreadPoolExecutor的构造函数我们知道,我们可以创建我们自己适合的线程池,也可以使用Executors创建。
关于实现类ThreadPoolExecutor的几种线程的区别:
FixedThreadPool:建时,核心线程数和最大线程数是一样的,是一个固定线程的线程池。常用于,需要限定线程使用的场景,负载比较大的服务器。他的阻塞队列是:LinkedBlockingQueue队列,这个队列是一个无界队列,容量没有限制,那么使用无界队列,当任务量多的时候,会导致阻塞队列量过多导致内存溢出,那么饱和策略也没有什么用。

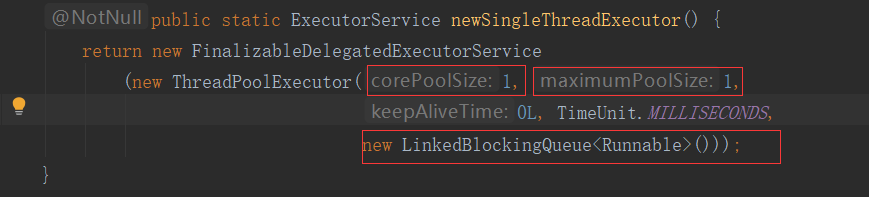
SingleThreadExecutor:创建时,核心线程数=最大线程数=1。说明这个线程池无论怎么样,他的线程都只有一个。阻塞队列也是无界队列。
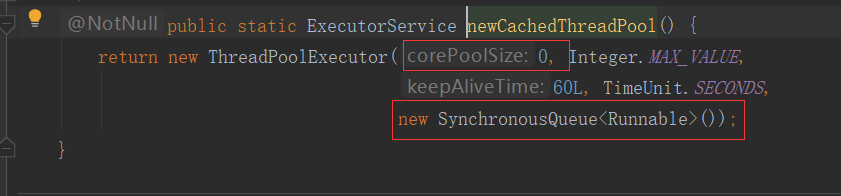
CachedThreadPool:缓冲线程池:创建时:他的核心线程数为0,最大线程数是 Integer.MAX_VALUE。说明这个线程池,使用到这个线程时,只要用任务,就会无上限的创建线程。而且他的阻塞队列是使用的是:SynchronousQueue,这个队列本身不会存储任何东西。缺点,大量提交任务时,创建太多线程消耗计算机资源。。
优点:每个任务的执行时间非常短,使用这个线程池就非常高效。
ScheduleThreadPoolExecutor:定期执行任务的线程池。有两种 ScheduleTreadPoolExecutor.只包含多个线程的。
线程池的使用:
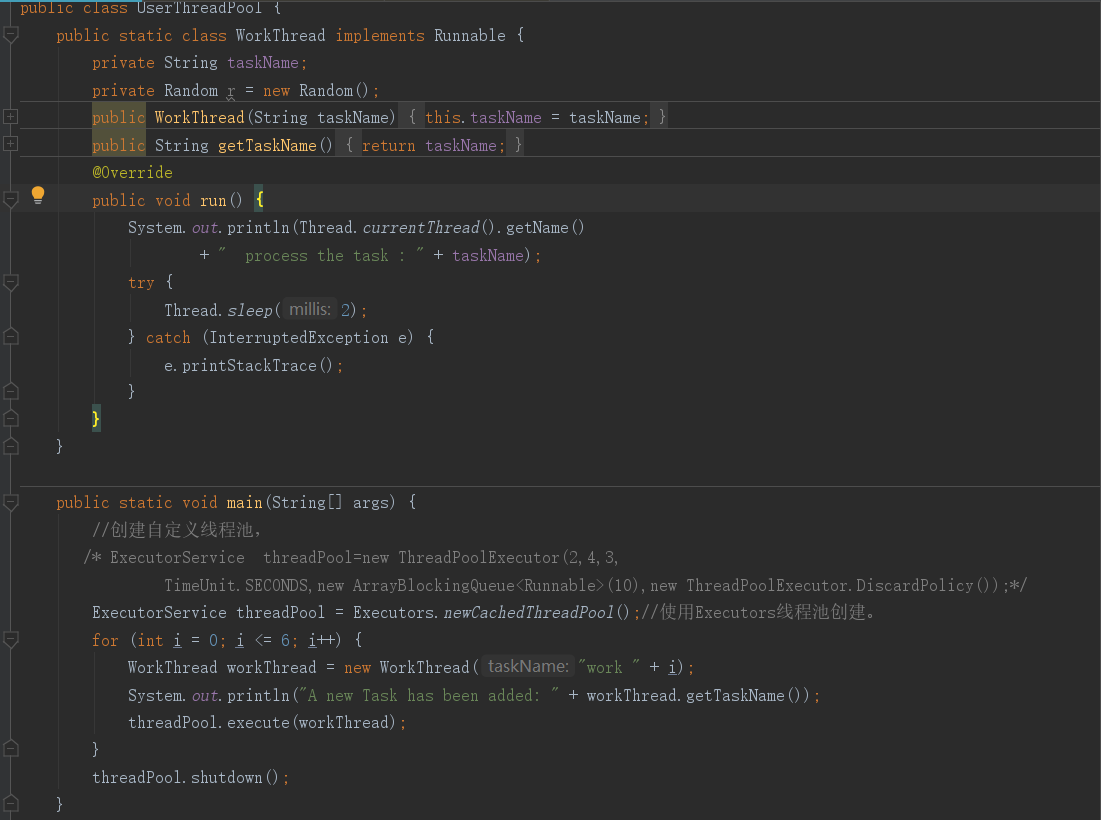
运行结果:
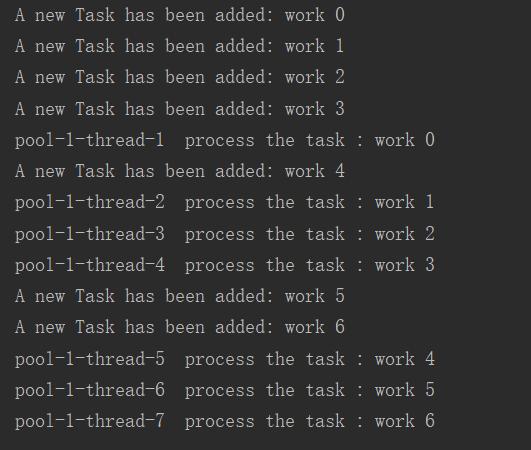


1 public class UserThreadPool { 2 public static class WorkThread implements Runnable { 3 private String taskName; 4 private Random r = new Random(); 5 public WorkThread(String taskName) { 6 this.taskName = taskName; 7 } 8 public String getTaskName() { 9 return taskName; 10 } 11 @Override 12 public void run() { 13 System.out.println(Thread.currentThread().getName() 14 + " process the task : " + taskName); 15 try { 16 Thread.sleep(2); 17 } catch (InterruptedException e) { 18 e.printStackTrace(); 19 } 20 } 21 } 22 23 public static void main(String[] args) { 24 //创建自定义线程池, 25 ExecutorService threadPool=new ThreadPoolExecutor(2,4,3, 26 TimeUnit.SECONDS,new ArrayBlockingQueue<Runnable>(4),new ThreadPoolExecutor.DiscardPolicy()); 27 /* ExecutorService threadPool = Executors.newCachedThreadPool();//使用Executors线程池创建。*/ 28 for (int i = 0; i <= 6; i++) { 29 WorkThread workThread = new WorkThread("work " + i); 30 System.out.println("A new Task has been added: " + workThread.getTaskName()); 31 threadPool.execute(workThread); 32 } 33 threadPool.shutdown(); 34 } 35 }
ScheduledThreadPoolExecutor
ScheduledThreadPoolExecutor。包含若干个线程的ScheduledThreadPoolExecutor。
SingleThreadScheduledExecutor。只包含一个线程的ScheduledThreadPoolExecutor。
有关提交定时任务的四个方法:
//提交一个仅仅执行一次的任务
public ScheduledFuture<?> schedule(Runnable command, long delay, TimeUnit unit)
//提交一个仅仅执行一次的任务,有返回值
public <V> ScheduledFuture<V> schedule(Callable<V> callable, long delay, TimeUnit unit);
// 固定时间间隔循环的执行
public ScheduledFuture<?> scheduleAtFixedRate(Runnable command, long initialDelay, long period, TimeUnit unit)
// 固定延时间隔的循环的执行
public ScheduledFuture<?> scheduleWithFixedDelay(Runnable command, long initialDelay, long delay, TimeUnit unit);
1 ** 2 * @author yangxin 3 * @time 2019/3/17 10:15 4 * 5 * 类说明:执行我们的定时任务 6 */ 7 public class ScheduleCase { 8 public static void main(String[] args){ 9 ScheduledThreadPoolExecutor schedule=new ScheduledThreadPoolExecutor(1); 10 schedule.schedule(new Runnable() { 11 @Override 12 public void run() { 13 System.out.println("Task run one"); 14 } 15 },3000, TimeUnit.MICROSECONDS); 16 17 schedule.scheduleAtFixedRate(new Runnable() { 18 @Override 19 public void run() { 20 System.out.println("FixedRate start:"+ScheduleWorker.format.format(new Date())); 21 try { 22 Thread.sleep(2); 23 } catch (InterruptedException e) { 24 e.printStackTrace(); 25 } 26 System.out.println("FixedRate end "+ScheduleWorker.format.format(new Date())); 27 } 28 },1000,3000,TimeUnit.MICROSECONDS); 29 30 schedule.scheduleAtFixedRate(new ScheduleWorker(ScheduleWorker.Normal) 31 ,1000,3000,TimeUnit.MICROSECONDS); 32 } 33 34 }
1 /** 2 * @author yangxin 3 * @time 2019/3/17 10:06 4 * 5 * 类说明:定时任务的工作 6 */ 7 public class ScheduleWorker implements Runnable { 8 public static final int Normal=0; 9 public static final int HasException=-1; 10 public static final int ProcessException=1; 11 12 public static SimpleDateFormat format=new SimpleDateFormat("YYYY-MM-DD HH:mm:ss"); 13 14 private int taskType; 15 16 public ScheduleWorker(int taskType) { 17 this.taskType = taskType; 18 } 19 20 @Override 21 public void run() { 22 if(taskType==HasException){ 23 System.out.println(format.format(new Date())+"Exception be made"); 24 throw new RuntimeException("ExceptionHappen"); 25 }else if(taskType==ProcessException){ 26 try{ 27 System.out.println(format.format((new Date()))+"Exception be made"+"will be catch"); 28 throw new RuntimeException("ExceptionHappen"); 29 }catch(Exception e){ 30 System.out.println("we catch Exception!"); 31 } 32 }else{ 33 System.out.println(format.format(new Date())+"Normal"); 34 } 35 } 36 }
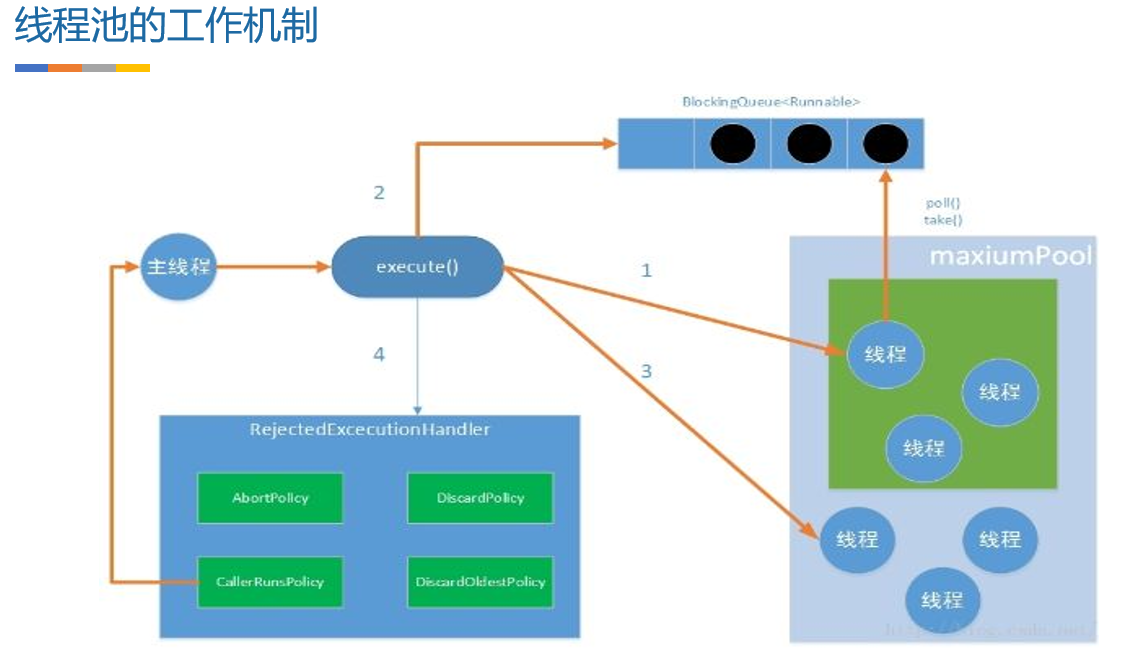
线程池之间的工作机制:线程池核心线程,最大线程,阻塞队列,饱和策略之间的关系
线程池的运行顺序:一开始任务进入线程池,首先用核心线程去执行任务,当无核心线程的时候,进来的任务会进入阻塞队列中,等待核心线程的调度,但是当阻塞队列都满了,那么最大线程数开始创建新的线程执行任务;如果线程创建到最大值,这个时候线程池称为饱和状态,于是就开始饱和策略的执行。
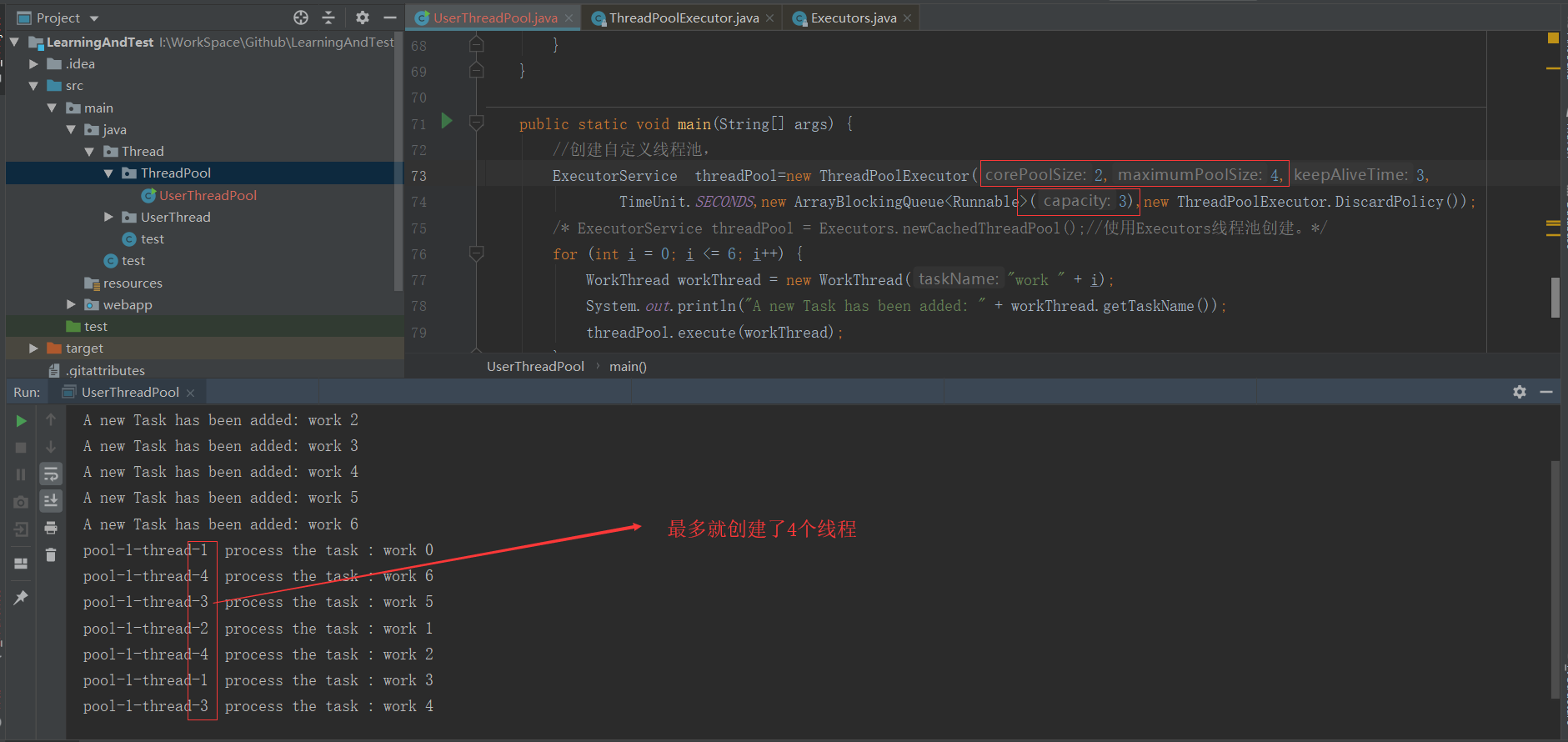
将上面的代码改动一下:
我们将核心线程设置为2,最大线程设置为4,阻塞队列是有界队列并且大小为3;模拟7个线程运行,,我们可以看到,线程最多就创建了4个线程来执行任务,因为我们的阻塞队列大小是3.当核心线程满了时,阻塞队列无法装下,就需要新建线程来执行任务,所有就只创建了4个线程。
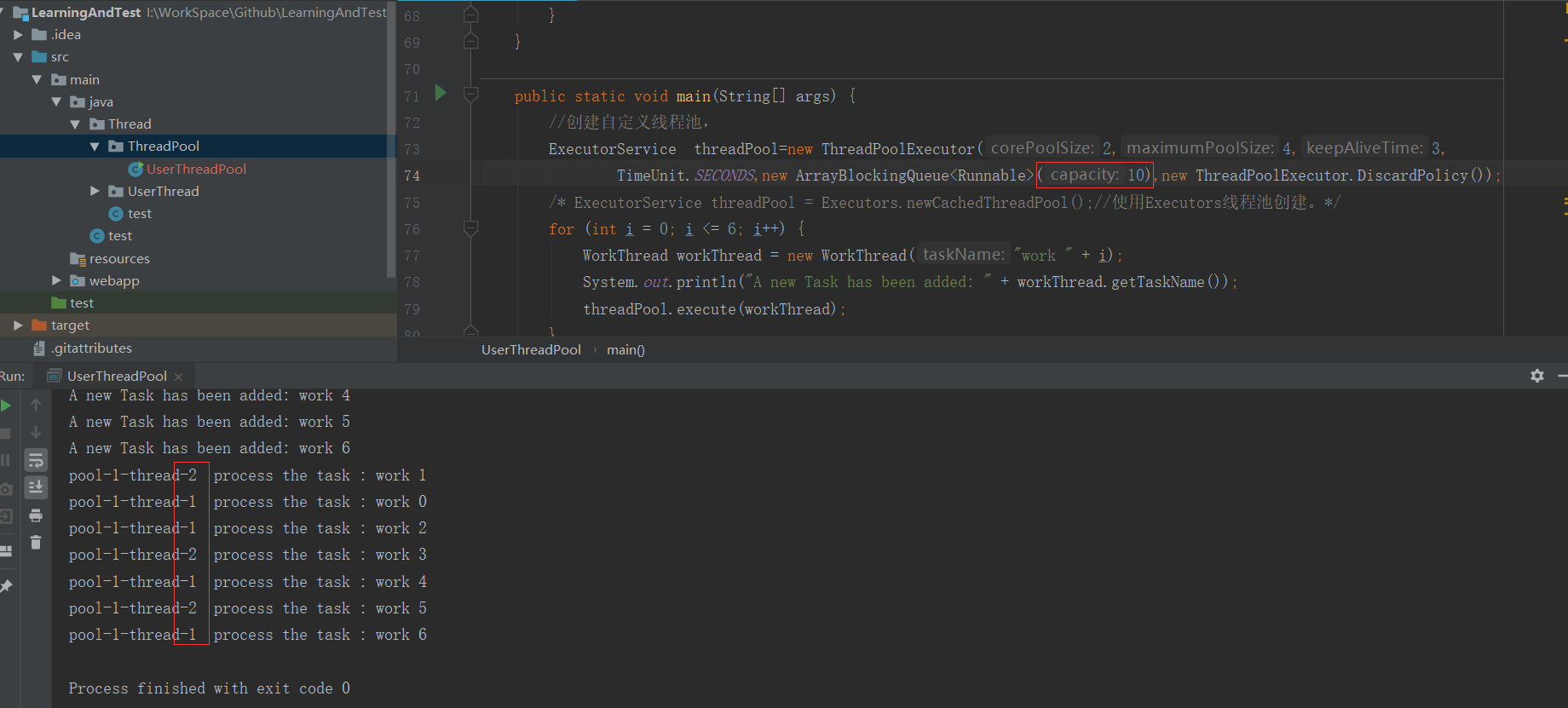
我们当把队列设置为10后,发现线程就创建了两个,因为核心线程创建的时候,阻塞队列能够装下所有的任务,所以就不会创建新的任务。
并发容器
ConcurrentHashMap:他的原型就是HashMap在线程安全的一个版本;我们都知道在Map中有HashMap和HashTable两种Map,一个是线程安全,一个是线程不安全的;但是为什么还会有一个ConcurrentHashMap的这样一个类呢???因为HashTable尽管是线程安全的,但是在并发性很高的情况下,HashTable的效率低下,不能满足开发的需要,HashMap的效率就比较高,但是不是线程安全的,所以就会衍生出ConcurrentHashMap这个类;使用方式和HashMap差别不大,不过有一个新的函数,putifAbsent()这个函数,功能是如果插入失已经存在就返回其值,没有就和put功能一样。
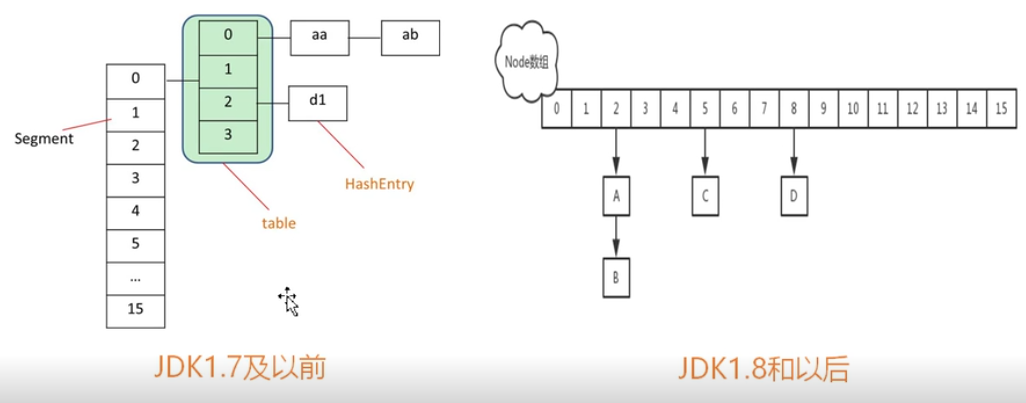
在1.7以前HashMap的结构就是一个Hash表,有一个Segment、Table、HashEntry的一个结构,Segment主要是来加锁使用的;在1.8以后,HashMap的结构是hash表+红黑树结构的,当一个桶上的链表个数超过8个的时候,这时候Map的结构就变成红黑树,1.8以后的HashMap加锁是锁的单元数据。
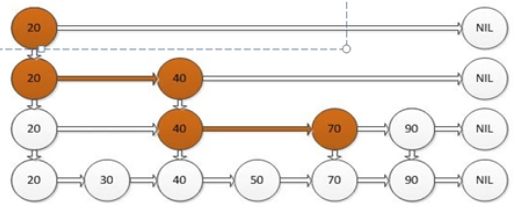
ConcurrentSkipListMap(TreeMap)、ConcurrentSkipListSet(TreeSet):Skip:简称是跳表,如下图,跳表的结构就是建立很多个索引,使得查找的效率提升,能够和红黑树媲美,如下,当我们要查找50的时候,第一个索引最大的值是20,50要大一下,那么就跳到下一条索引中,依次比较,最后找到50。这就是跳表。
ConcurrentLinkedQueue(LinkedList):linkedList一个并发版本;
add()将元素插入队列的头部
offer() 将元素插入队列的尾部
peek() 检索队列的头部拿到元素,不移除元素
poll() 检索队列的头部拿到元素,移除元素
CopyOnWriteArrayList(ArrayList):这是一个写时拷贝,在读的时候不会加锁,在更新的时候重新将整个数据复制。并发的读,读写分离。最适用于读多写少的场景。
阻塞队列:当插入或者移除元素的时候,当条件不足时,让工作线程阻塞的队列。
ArrayBlockingQueue:数组结构,是一个有界的阻塞队列,锁只有一把,生产和消费者是同一把锁,定义时需要指定大小。
LinkedBlockingQueue:是一个链表结构,是一个有界阻塞队列,锁是分离的,在元素推入队列的时候会包装成Node放入,定义时不需要确定大小。
PriorityBlockingQueue:支持优先级排序的无界队列。
DelayQueue:延时获取元素,但是使用必须实现Delayed接口。
SynchronousQueue:不存储任何元素的无界队列,有插入元素的操作就必须有取出元素的操作。
LinkedTransferQueue:链表结构的无界队列。
LinkedBlockingDeque:链表结构,双向队列。
线程池的实际应用
需求:A系统有个批量任务执行的功能,A系统的使用者在使用的过程中整个任务的执行情况,包括有多少任务成功了,多少任务做失败了,失败的原因是什么?并且当前任务的处理进度的需求,并且其他的业务也有类似的需求,甚至有的要求同时处理多个任务不同的批量任务,给这一个场景提供一个业务框架,给这些业务场景使用,并且对于使用者(开发人员的友好)更好的友好。
分析: ①:批量的任务框架,并且可以看到任务的执行情况。
②:要对开发使用人员要友好。
需要做些什么:
①:提高性能,采用多线程,并且屏蔽细节(使用者不需要知道底层是怎么样的,比如什么并发容器、阻塞队列、异步任务啥的)。
②:每个批量任务拥有自己的上下文环境。
③:定期的清除已经完成的任务
项目开始:
1.首先我们需要检测线程任务的执行情况,成功?失败?还是其他,失败的原因是什么,那么我们先定义一个枚举类:
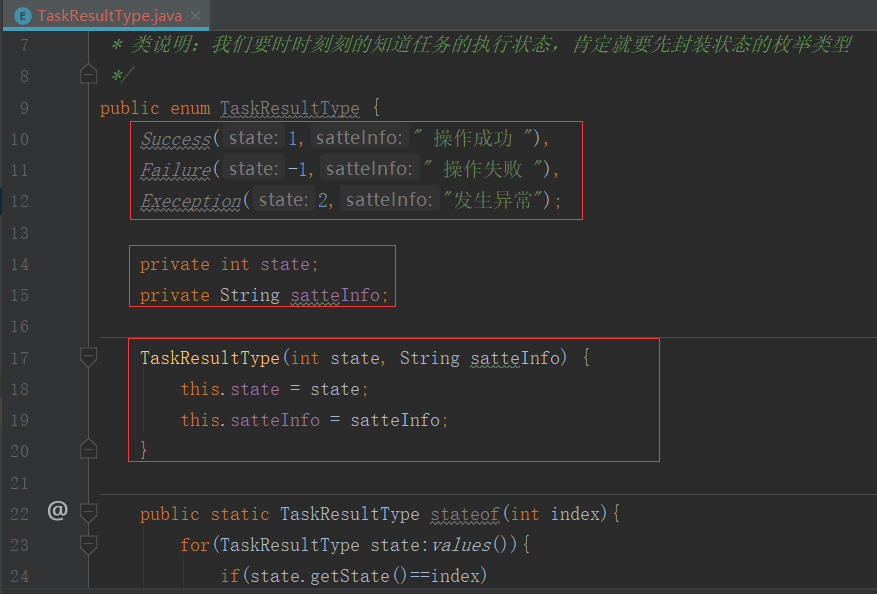
2.封装一个数据类型,表示每个任务返回的结果
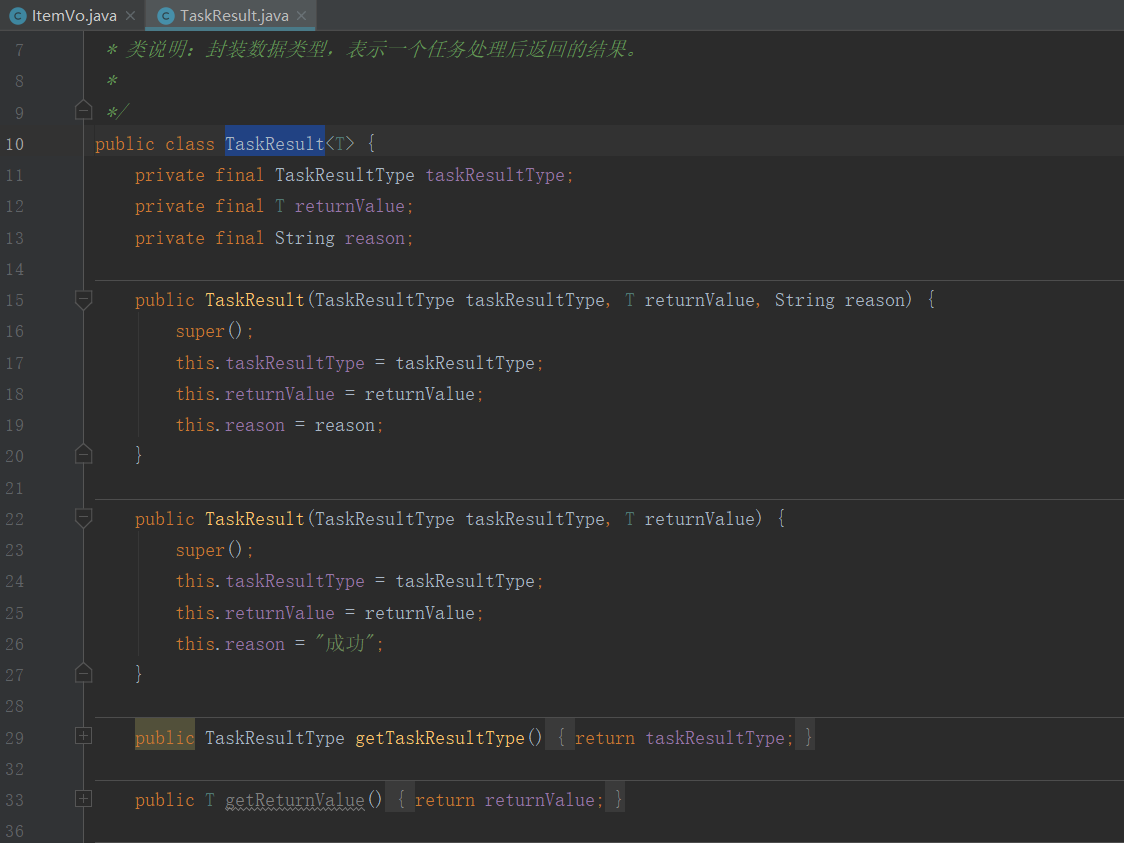
3.这是一个给使用者提供的接口,使用者使用这个框架要实现这个接口。
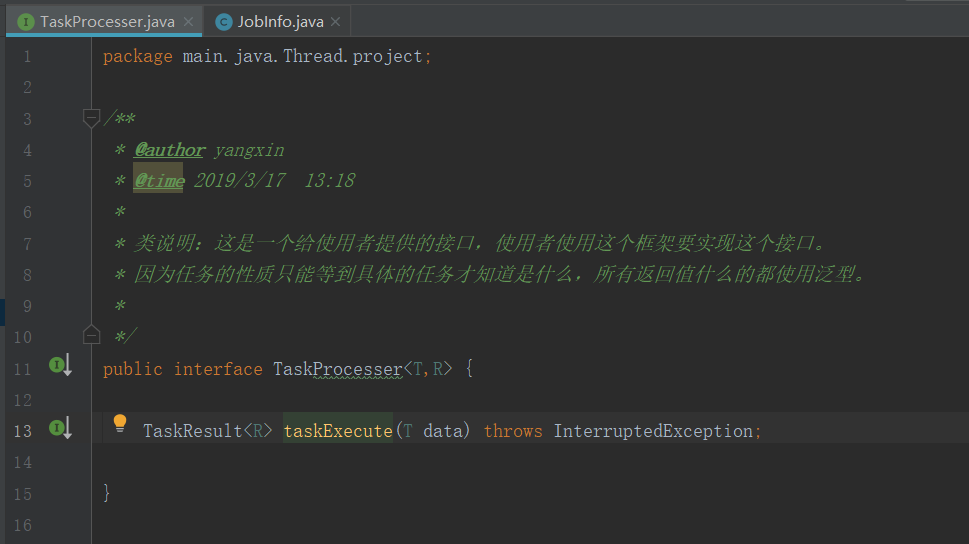
4.工作任务的处理
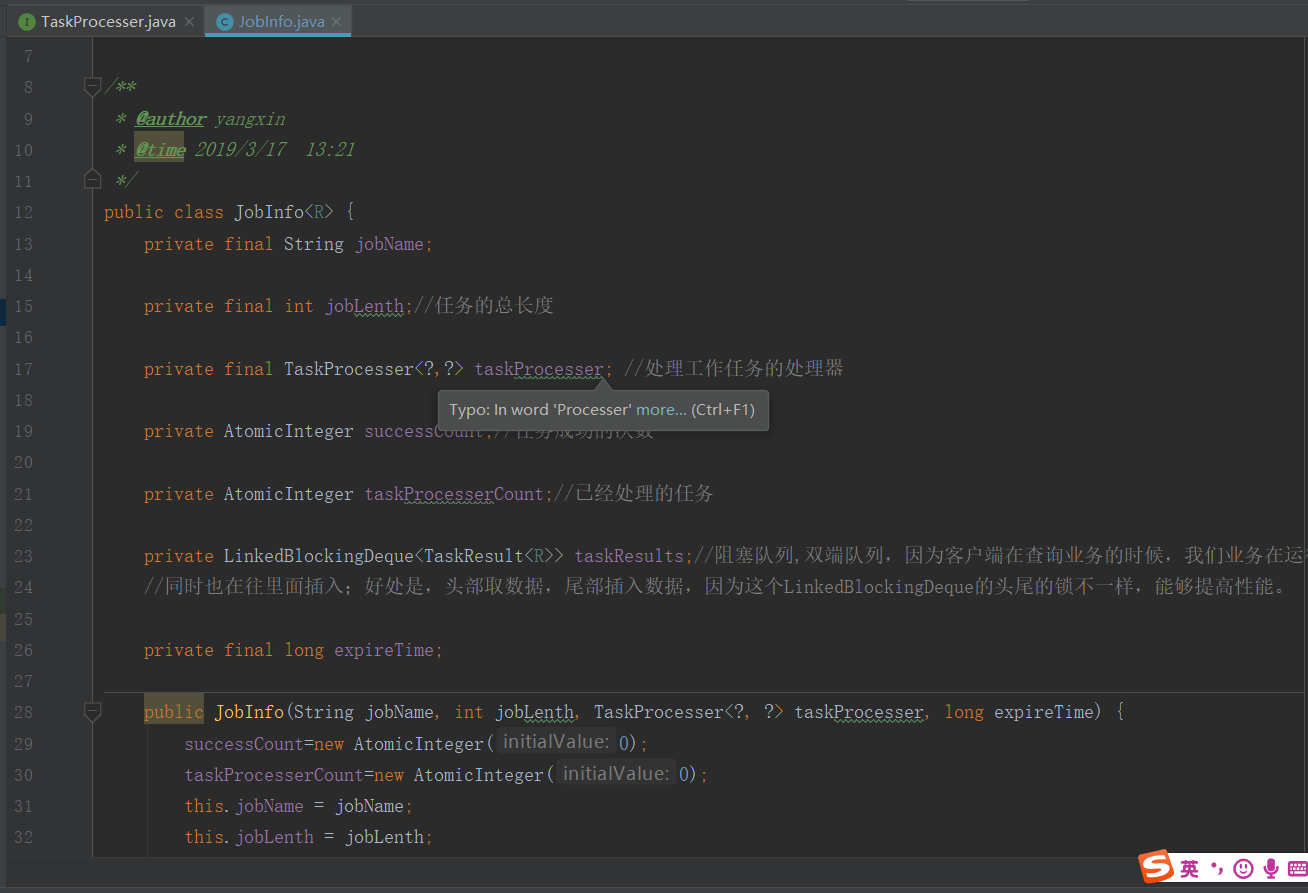
项目地址:https://github.com/fireshoot/LearningAndTest。
转载标明地址

 浙公网安备 33010602011771号
浙公网安备 33010602011771号