Hello World之编译链接装载与执行(1)
一:前言
我打算写一系列博客来说说我对Hello World在计算机中的生命旅程的理解,我是一名软件工程专业的大三学生,有关这个问题我主要的参考书有《深入理解计算机系统》、《现代操作系统》、《程序员的自我修养》,除了这些,我还参考了一些大牛的博客,如果后面需要,我会贴出来,我还在我的Centos 7系统上做了一些验证。如果上面的三本书你都看过,并且看的还算认真,能回答这个问题 https://www.zhihu.com/question/53042020
(问:下面的程序需要经过链接吗?)
//1.c
-------------------------
int main()
{
return 0;
}那我觉得你可以关掉我的博客去冲杯咖啡歇歇了。如果不能回答,并且想知道答案,那我们一步一步往下走,因为我要从头说起,所以可能废话会有点多。
但是你要是想急切知道我对这个问题的看法,请点击: [尚未完成]
好了,我们还是一步步往下走吧~
二:GCC 是什么?
回答:
1、是c语言的编译器。(单纯、你不知道它还能编译其它语言吗?)
2、是GNU的编译器套件,可以编译多种语言。(司机,看来你基础不错)
3、是GUN编译系统的编译驱动程序。(我的天,老司机阿)
那为什么说GCC是GUN编译系统的编译驱动程序呢?我们继续。
三:Hello World 诞生啦!
//Hello.c
----------------------------
#include<stdio.h>
int main(int argc,char *argv[])
{
printf("Hello World\n");
return 0;
}上面的是源程序,如果想得到可运行的目标文件:

已经OK了。但是我们才不会这样呢?这个几乎瞬间完成的动作,其实是由这么几个步骤组成的。
预处理 -> 编译 -> 汇编 -> 链接 -> 装载
下面我们来依次说每个步骤。
四:预处理
1、使用GCC -E参数完成。

预处理会干什么事情:
- 展开所有的宏定义并删除 #define
- 处理所有的条件编译指令,例如 #if #else #endif #ifndef …
- 把所有的 #include 替换为头文件实际内容,递归进行
- 把所有的注释 // 和 / / 替换为空格
- 添加行号和文件名标识以供编译器使用
- 保留所有的 #pragma 指令,因为编译器要使用
- ……
处理完成之后看看我们的Hello.i,发现原来8行代码现在变成了接近700行,因为将<stdio.h>的文件被替换进来了,在最后几行找到了我们自己Hello.c的代码:

2、使用系统默认的预处理器cpp完成。
预处理除了使用GCC -E参数完成之外,我们还可以使用系统默认的预处理器cpp完成。如下所示:

我们看看Hello.ii的代码:

虽然Hello.i和Hello.ii的代码对应的行数不同,但是内容却是一模一样的,只是中间空行的数量不同而已。
OK ,接下来,继续向编译出发。
五:编译
编译是将源文件转换成汇编代码的过程,具体的步骤主要有:
词法分析 -> 语法分析 -> 语义分析 -> 中间代码生成 -> 目标代码生成。
如果不想了解具体过程,跳过下面两行~
有关词法分析,我写过一个简单的词法分析器:[点击这里]
有关语法分析,针对LL1分析法,我实现过一个简单的语法分析器:
http://blog.csdn.net/yangbodong22011/article/details/52951001
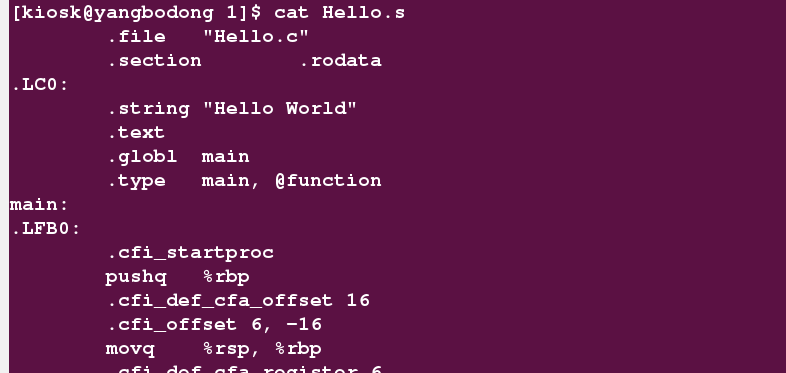
1、使用GCC -S参数完成。

查看Hello.s发现已经是汇编代码了。
2、使用系统默认的编译器cc1完成这个过程。
前面的预处理命令cpp可能大家的系统上都有,我们输入cp,然后Tab两下(Linux系统上表示提示补全命令),系统提示如下:

倒数第二个命令就是cpp了。但是我们cc同样的过程的时候却发现:

并没有cc1这个命令,但是cc1确实是Linux系统上默认的编译器呀,我们在系统上找找看:

看上图第二条,/usr/libexec/gcc/x86_64-redhat-linux/4.8.2/cc1,尝试着去看下:

有可执行权限,那为何不试试能不能用来编译Hello.ii呢?
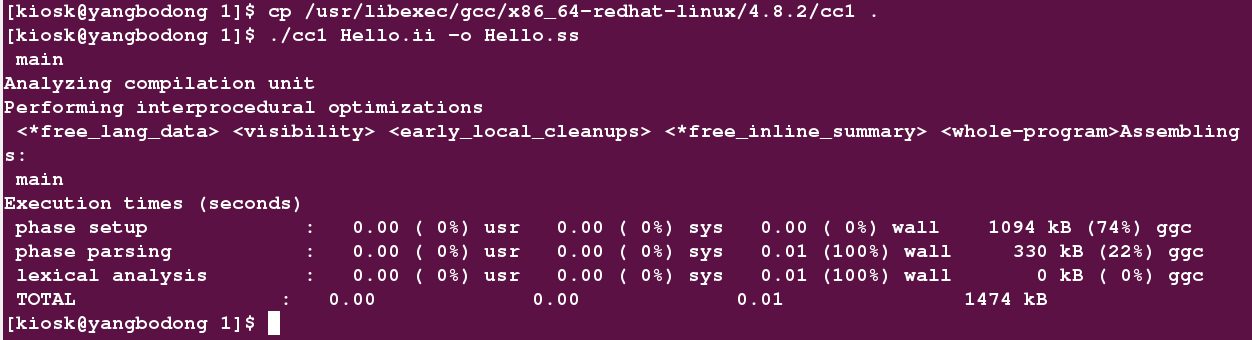
好像没有什么报错,迫不及待的看看Hello.ss的内容:
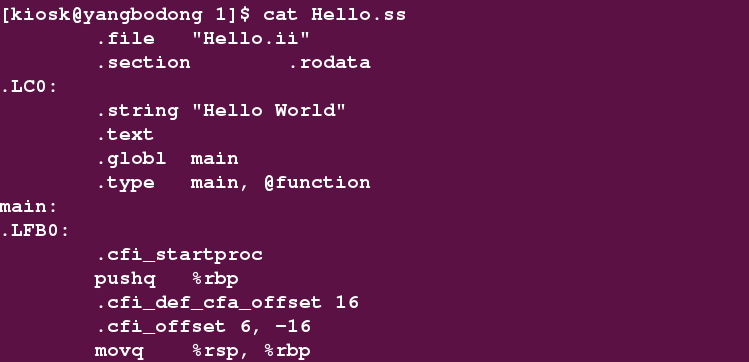
发现和Hello.s的是一样的。编译成功。Goto 汇编。
六:汇编
汇编是将汇编代码生成机器代码的过程。得到的文件叫可重定位的目标文件,机器代码是二进制代码,并且根据不同的平台,生成二进制代码也不同。
1、使用GCC -c参数完成。

其实也可以查看下Hello.o的内容:

只是乱码罢了。要是想看,我们可以使用hexedit,readelf和objdump这三个工具。
hexedit 只是个将二进制文件用十六进制打开的工具,我们执行:
$ sudo yum install hexedit
$ hexedit Hello.o可以看到:

最右边是源文件被翻译成可见字符,点.表示的都是不可见字符。这样看当然没有多大实际意义,但是一些输出的字符串Hello World,包括整个文件的类型ELF都是可以看到的。
readelf和objdump我们后面再说。
2、使用系统默认的汇编器as完成。

hexedit 看看 :

使用 cmp 命令比较Hello.oo和Hello.o
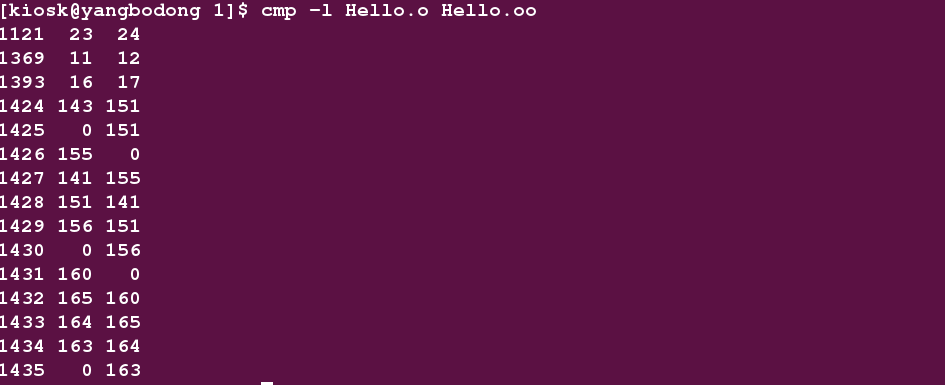
只有极少数字符不同。可能也是格式问题。下面就要进入链接这个阶段了,本篇博客就到这里吧。
总结:上面的过程中,我们已经将Hello.c源程序经过预处理,编译,汇编阶段变成了二进制代码,这三个过程我们都是用两种方法完成的,一种是GCC + 参数的方法,另一种是使用系统默认的预处理器,编译器,汇编器。但是这两种方法都达到了我们的目的,那有关本文第二部分的问题GCC是什么?的答案,我之前之所以同意第三个答案:GCC是GUN编译系统的编译驱动程序,就是因为GCC编译的过程中,真正干活的还是我们系统默认的预处理器,编译器,汇编器,如果你还是不信,GCC -v显示过程看看不就好了:
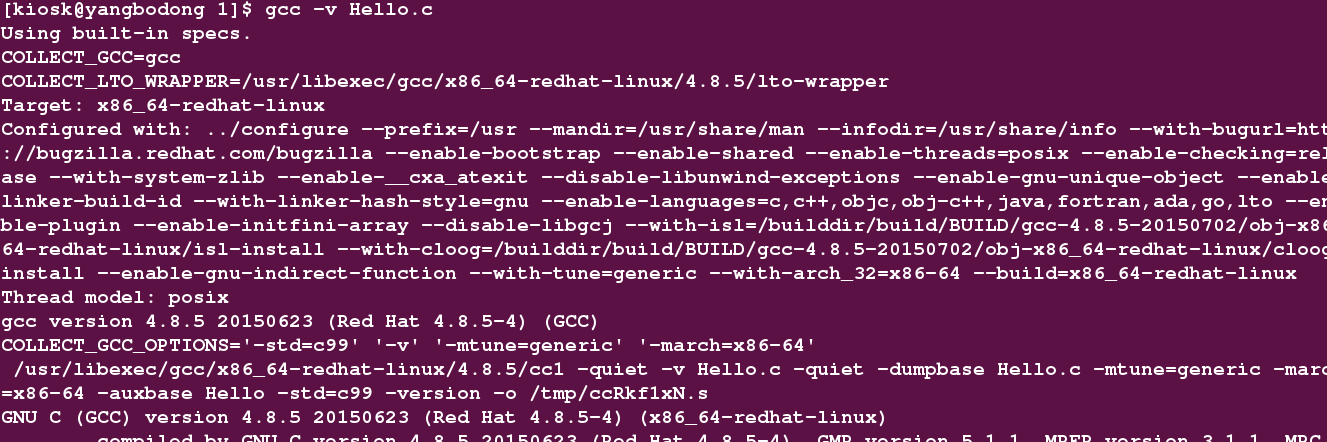
我找点有用的:

这不是调用as了吗。所以请接受我的观点。好了,时间也不早了,该问问大拿困了没,结束本文之前,我再问一个问题:
我们现在得到的
Hello.o是可以运行的吗?给它加上x权限试一试?

 浙公网安备 33010602011771号
浙公网安备 33010602011771号