三剑客实战Nginx日志分析
主要价值:
掌握linux的基本命令
掌握shell的管道机制
掌握三剑客的常见用法
大纲:
linux数据统计基本命令:sort head tail uniq less vim
LINUX系统命令 ps top netstat
实战环境
命令分类:
linux的抽象哲学,所有的都是文件,everything is file
大数据的处理,|管道进行处理数据
三剑客 grep: 数据查找定位
awk: 数据切片
sed: 数据修改
awk的官方文档,建议看一遍
正则,扩展正则
实战1
将进行操作的日志,cp到自己的目录下; 或者将日志,cp到自己的linux机器上面;
命令:cp /tmp/nginx.log nginx.log
scp root@shell.ceshiren.com:/tmp/nginx.log nginx.log
注意修改:账户,密码是hogwarts
223.104.7.59 - - [05/Dec/2018:00:00:01 +0000] "GET /topics/17112 HTTP/2.0" 200 9874 "https://www.googleapis.com/auth/chrome-content-suggestions" "Mozilla/5.0 (iPhone; CPU iPhone OS 12_1 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) CriOS/70.0.3538.75 Mobile/15E148 Safari/605.1" 0.040 0.040 .
作业:找出log文件中,404,500的服务器返回值,用函数的方法执行。
例子:user_count(){
w | sed '1,2d' | awk '{print $1}' |sort |uniq -c |wc -l
}
[ck186943@shell.ceshiren.com ~]$ user_count(){
> w | sed '1,2d' | awk '{print $1}' |sort |uniq -c |wc -l
> }
> [ck186943@shell.ceshiren.com ~]$ user_count
> 11
> [ck186943@shell.ceshiren.com ~]$
实例展示完毕。
作业:
awk -F ' ' '/500/{print $0}' nginx.log | grep -n 'HTTP/1.1" 500'
解释:1. 没有连续的将404和500打印出来
-
太繁琐的命令,实际上一个命令就可以搞定
标准答案:思路,分析404和500所在的位置,一行中的字段排版格式,直接使用切片的方式得到404和500的错误。
命令:awk ‘$9~/404|500{print $9}’ nginx.log
写成函数就是:
find_error_log(){
awk ‘$9~/404|500{print $9}’ nginx.log
}
[ck186943@shell.ceshiren.com ~]$ awk 'NR==1{print $1}' nginx.log
223.104.7.59
[ck186943@shell.ceshiren.com ~]$ head -1 nginx.log
223.104.7.59 - - [05/Dec/2018:00:00:01 +0000] "GET /topics/17112 HTTP/2.0" 200 9874 "https://www.googleapis.com/auth/chrome-content-suggestions" "Mozilla/5.0 (iPhone; CPU iPhone OS 12_1 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) CriOS/70.0.3538.75 Mobile/15E148 Safari/605.1" 0.040 0.040 .
[ck186943@shell.ceshiren.com ~]$ head -2 nginx.log
223.104.7.59 - - [05/Dec/2018:00:00:01 +0000] "GET /topics/17112 HTTP/2.0" 200 9874 "https://www.googleapis.com/auth/chrome-content-suggestions" "Mozilla/5.0 (iPhone; CPU iPhone OS 12_1 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) CriOS/70.0.3538.75 Mobile/15E148 Safari/605.1" 0.040 0.040 .
123.125.71.60 - - [05/Dec/2018:00:00:02 +0000] "GET /yuanyibo/topics?locale=en HTTP/1.1" 200 12164 "-" "Mozilla/5.0 (compatible; Baiduspider/2.0; +http://www.baidu.com/search/spider.html)" 0.032 0.032 .
[ck186943@shell.ceshiren.com ~]$ awk 'NR==2{print $1}' nginx.log
123.125.71.60
扩展:将每一行的字段,都列出来,能够清楚的知道,想要甄别的信息在哪个位置
命令:awk ‘NR==1{for(i=1;i<=NF;i++){print i "="$i}}’ nginx.log
NF : 浏览记录的域的个数;就是分割成多少域
NR : 已读的记录数;就是第几行
实战2
找出500错误时候的上下文,找出500错误的前两行,考察grep高级用法,并把这个参数的描述信息贴上。
[ck186943@shell.ceshiren.com ~]$ find_before(){
> grep -C2 'HTTP/1.1" 500' nginx.log
> }
> [ck186943@shell.ceshiren.com ~]$ find_before
> 123.127.112.18 - - [05/Dec/2018:00:09:18 +0000] "GET /cable HTTP/1.1" 101 1017 "-" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36" 70.577 70.577 .
> 139.180.132.174 - - [05/Dec/2018:00:09:20 +0000] "GET /bbs.zip HTTP/1.1" 404 1264 "-" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36" 0.011 0.011 .
> 139.180.132.174 - - [05/Dec/2018:00:09:12 +0000] "GET /__zep__/js.zip HTTP/1.1" 500 2183 "-" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36" 0.018 0.018 .
> 141.8.142.131 - - [05/Dec/2018:00:09:12 +0000] "GET /topics/14442 HTTP/1.1" 200 21980 "-" "Mozilla/5.0 (compatible; YandexBot/3.0; +http://yandex.com/bots)" 0.195 0.195 .
> 220.181.108.181 - - [05/Dec/2018:00:09:13 +0000] "GET /syyair/following?locale=zh-CN HTTP/1.1" 200 13355 "-" "Mozilla/5.0 (compatible; Baiduspider/2.0; +http://www.baidu.com/search/spider.html)" 0.035 0.035 .
> [ck186943@shell.ceshiren.com ~]$解释:
-C :返回匹配行和匹配行的前后两行
grep -C2 2 text.txt
-A :返回匹配行和匹配行的后一行
-B :返回匹配行和匹配行的前一行
实战3
find top3,找出访问量最高的ip,统计分析,取出top3。
[ck186943@shell.ceshiren.com ~]$ cat nginx.log |awk '{print $1}' |sort |uniq -c|sort -r -n | awk 'NR<=3{print $0}'
282 216.244.66.241
130 136.243.151.90
110 127.0.0.1
解释:sort -r ,倒序排序;-n,将数字进行排序。
友好提示:请在文件大小比较大的时候,加上less命令,不然太多数据,执行会很慢
实战4
找出/topics的平均响应时间,响应时间在倒数第二个字段
0) 求和**
[root@redis-server1 ~]# awk '{a+=$1}END{print a}' a
2348
**1) 求最大值**
[root@redis-server1 ~]# awk '$0>a{a=$0}END{print a}' a
2333
**2) 求最小值(思路:先定义一个最大值)**
[root@redis-server1 ~]# awk 'BEGIN{a=9999999}{if($1<a) a=$1 fi}END{print a}' a
1
**3)求平均值**
第一种方法:在上面求和的基础上,除以参数个数
[root@redis-server1 ~]# awk '{a+=$1}END{print a/NR}' a
391.333
以上是举例
[ck186943@shell.ceshiren.com ~]$ awk '$7=="/topics"' nginx.log | awk '{print $(NF-1)}'| awk '{sum+=$1}END{print sum/NR}'
0.0935
[ck186943@shell.ceshiren.com ~]$ awk '$7=="/topics"' nginx.log | awk '{print $(NF-1)}' |awk '{a+=$1}{print a/NR}'
0.144
0.1055
0.0993333
0.0935
[ck186943@shell.ceshiren.com ~]$ awk '$7=="/topics"' nginx.log | awk '{print $(NF-1)}' |awk '{a+=$1}END{print a/NR}'
0.0935

解释:/topics的后面,没有任何东西;然后需要将后面的请求响应时间做统计,并计算平均值。
awk '$7=="/topics"' nginx.log
意思:默认空格隔开,在第七个位置寻找"/topics",在这个log文件里查找,并展示属于这一行的信息。
awk '$7=="/topics"' nginx.log | awk '{print $(NF-1)}'
意思:在符合这个条件的情况下,定位到倒数第二个值,倒数第二个值就是响应时间的值;NF是空格分割后,所有域的总值。是awk中的,代表含义。
awk '$7=="/topics"' nginx.log|awk '{print $(NF-1)}' |awk '{a+=$1}END{print a/NR}'
意思:a+=$1,是获取总值信息,END,是先执行前面完了,最后执行END后面的命令;a/NR,就是总值除以总行数。得到平均值。NR,就是awk命令中的总行数
注意:高能出现!!!
以上命令都是易读性比较好的命令,但是进程占用多;下面将上面命令进行整合,整合成高性能的命令!
awk '$7=="/topics"{total+=$(NF-1);count+=1}END{print total/count}' nginx.log
解释:total;总时间。count;总行数。
实战5
性能统计
ps -ef | head -5
ps aux | head -5
top -p 123 -b
区别:ps只是一瞬间的快照;top是实时跟进的,查看电脑信息。
top -b,-b参数:不会让数据变为交互模式了,就可以进行文件的处理
-d :参数,刷新频率,top -p 123 -b -d 1 ,一秒刷新一次
题目:
统计aliyundun进程的cpu与mem,
-要求统计10次,一次间隔1s,
-最后输出平均cpu与mem数据,
-字段之间用tab隔开,平均数与之前的数据错开一行,
-支持输入不同的进程标记来统计不同进程的数据。
[ck186943@shell.ceshiren.com ~]$ perf_avg systemd$ 3
CPU MEM
0.0 0.1
0.0 0.1
0.0 0.1
avg:0 0.1
[ck186943@shell.ceshiren.com ~]$ type perf_avg
perf_avg is a function
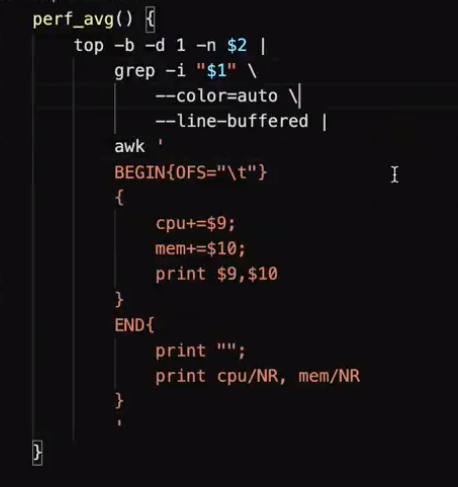
perf_avg ()
{
top -b -d 1 -n $2 | grep --color=auto --color=auto --line-buffered -i $1 | awk '{OFS="\t"}BEGIN{print "CPU MEM"}{cpu+=$9;mem+=$10}{print $9 ,$10}END{print ""; print "avg:"cpu/NR,mem/NR}'
}
top -b -d 1 -n $2 | grep --color=auto --color=auto --line-buffered -i "$1" | awk '{OFS="\t"}BEGIN{print "CPU MEM"}{cpu+=$9;mem+=$10}{print $9 ,$10}END{print ""; print "avg:"cpu/NR,mem/NR}'
但是要注意:函数中的值,最好用“”,双引号标记下,不然当函数传值是空格时,就会影响语法,报错!“$1”/"$2"
[ck186943@shell.ceshiren.com ~]$ top -p 1 -b -d 1 -n 3| grep systemd --line-buffered |awk 'BEGIN{print "cpu 内存"}{print $9," "$10 x}{sum+=$9;mem+=$10}END{print ""; print "AVG:"sum/NR" ",mem/NR}'
cpu 内存
0.0 0.1
0.0 0.1
0.0 0.1
AVG:0 0.1
这上面是自己第一次做的,low比!
如果将函数进行优美化:
实战5第二题
朋友圈取数据!


做题:
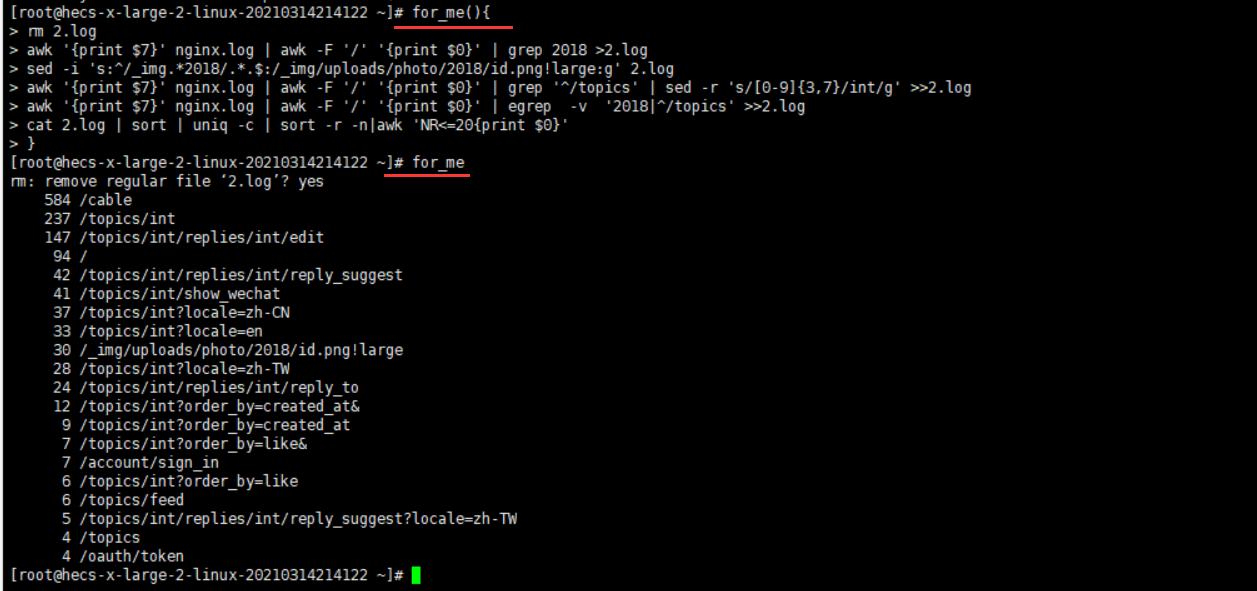
[root@hecs-x-large-2-linux-20210314214122 ~]# type for_me
for_me is a function
for_me ()
{
rm -i 2.log;
awk '{print $7}' nginx.log | awk -F '/' '{print $0}' | grep --color=auto 2018 > 2.log;
sed -i 's:^/_img.*2018/.*.$:/_img/uploads/photo/2018/id.png!large:g' 2.log;
awk '{print $7}' nginx.log | awk -F '/' '{print $0}' | grep --color=auto '^/topics' | sed -r 's/[0-9]{3,7}/int/g' >> 2.log;
awk '{print $7}' nginx.log | awk -F '/' '{print $0}' | egrep --color=auto -v '2018|^/topics' >> 2.log;
cat 2.log | sort | uniq -c | sort -r -n | awk 'NR<=20{print $0}'
}
。。。

linux: 1. netstat -tnp | grep 端口 netstat -t,参数,列出所有tcp -n, 以数字形式显示地址和端口号 -p,显示进程的pid和名字
2. top top执行后,有Tasks这一行,会有所有进程的总结信息。 -p,获取指定端口的进程的数据 -d ,间隔时间,每隔多长时间更新一次, -n , 获取多次cpu的执行情况,top -n 4
3. tar -xf tar.gz tar -xf tar.gz -C ./路径/ 参数 “-C” ,后面跟指定解压的路径
4. scp 账户@ip(域名):/路径/需要复制文件 复制的文件放置位置 记得要输入密码。
sql: 有两张表,学生表(student)课程表(grade)基本信息如下 学生student(学号id,姓名 name,年龄 age) 课程grade(课程号 no,学号 id,课程名 course,分数 score)
1.查询所有学生的数学成绩,显示学生姓名name,分数score,由高到低 SELECT a.name,b.score,b.course FROM student a ,grade b where b.course = "数学" and a.id = b.id ORDER BY b.score DESC;
-- 2.统计每个学生的总成绩,显示字段:姓名,总成绩
select a.name,SUM(b.score) s FROM student a ,grade b where a.id = b.id GROUP BY b.id ORDER BY s DESC;
如果将分数以大到小的排序,该怎么做?加一个order by 注意:函数一定记得重命名,尤其后面用的时候,涉及到性能问题!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号