《网络攻防实践》14.0
20199110 2019-2020-2 《网络攻防实践》综合实践
0. 前情提要
本次综合实践我选择的BLAG: Improving the Accuracy of Blacklists来自NDSS 2020中Session 6A: Network Defense,是一篇包含分析、设计、实验、评估全过程的文章。
文章作者是南加州大学信息科学研究所的Sivaram Ramanathan和Jelena Mirkovic,以及哈佛大学的Minlan Yu。其中,南加州大学的两个是第一作者,哈佛大学的是第二作者。通讯作者是南加州大学的Sivaram Ramanathan,邮箱为satyaman@usc.edu。
该项目由美国国土安全部科学技术理事会根据合同编号D15PC00184提供资金,部分经费由美国国家科学基金CNS1413978资助。
这篇文章的项目介绍存放在https://steel.isi.edu/Projects/BLAG/中,项目代码存放在GitHub的https://github.com/sivaramakrishnansr/BLAG中。
1. 摘要解读
IP地址黑名单是有关重复攻击者的有用信息源。通过黑名单,我们可以对恶意源和合法源进行快速鉴别。在拦截恶意源的同时,保障合法通信。但是黑名单存在过度专业化的问题,每类黑名单有自己独立的黑名单系统。
为此,文章提出了BLAG(BLacklist AGgregator,黑名单聚合器),一个评估和聚合多个黑名单提要的系统,生成一个更有用、更准确和更及时的主黑名单,并根据特定的客户网络进行定制。
BLAG使用客户网络入站流量的合法来源的样本来评估地址空间区域上每个黑名单的准确性。然后,它利用推荐系统选择最准确的信息汇总到主黑名单中。最后,BLAG识别主黑名单中可以扩展到更大地址区域(例如/24个前缀)的部分,从而以最小的附带损害发现更多的恶意地址。
通过对157个不同攻击类型的黑名单和3个地面真实数据集的评估表明,BLAG具有高达99%的特异性,与竞争方法相比,召回率提高了114倍,检测攻击的速度提高了13.7天,是一种很有前景的黑名单生成方法。
2. 分析设计
2.1 黑名单
2.1.1 黑名单定义
IP黑名单通常包含此前攻击者的IP地址,作为应急响应系统一部分,可以实现攻击者重攻击的快速甄别和拦截。在应对新型攻击和大规模攻击中,IP黑名单可作为第一防线,对攻击者IP进行快速甄别和拦截。这有利于减轻防御系统的负担,提高防御效率。
但是单个黑名单面临三个问题:一是漏放恶意攻击源,二是黑名单是特定时间恶意源的快照,三是恶意源通常存在于管理不善的网络中。
2.1.2 现存问题
第一部分介绍了信息分散的问题。主要说明了当前黑名单系统各自为战,覆盖率低,不同黑名单系统之间存在攻击IP重叠的问题;
第二部分介绍了重攻击问题。很多在前面被用于进行攻击活动的IP地址可能会被攻击者再次利用,这说明了历史黑名单的重要性;
第三部分介绍了恶意源IP同网的问题。攻击者喜欢通过控制无管理网络进行攻击活动,这样可以节省时间成本和提高攻击效率。但是当前黑名单一般只对具体IP进行收集,没有进行适当的/24扩展,筛选效果不高;
第四部分主要介绍了误分类问题。如果只是对各类黑名单进行简单聚合和扩展,那么可能会造成大量的误分类问题。因为黑名单中存在合法源或者已经不具备攻击属性的IP存在,简单聚合和扩展会把误分类问题进行放大。
2.2 BLAG
2.2.1 工作流程
首先,我们通过一张图片来了解BLAG。
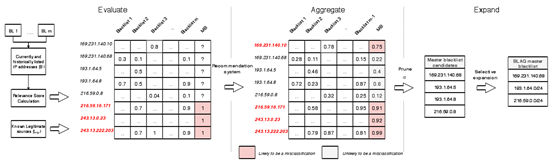
从图中,我们可以看到BLAG工作的各个阶段,包括evaluate、aggregate、expand三个主阶段。
首先是evaluate部分,对每个测试IP进行相关性分析,分析角度主要是时间维度。分数越高,相关性越高,合法源概率越高。
接下来是aggregate部分,这一部分主要引入了MB(misclassification blacklist,误分类黑名单)这一概念。计算MB列相关度使用的是采用协同过滤算法的推荐系统,下面是它的一个计算过程。
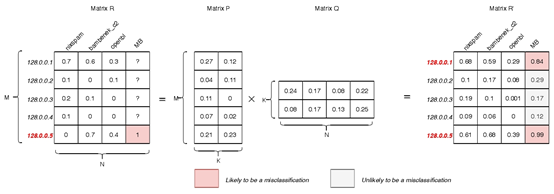
上图是MB列相关度计算的方式。在MB相关度算出来之后,选定阈值α进行取舍。α和K值的选择在参数调整一部分进行了说明。
最后一部分是expand部分,这部分主要是一个归类问题,提高检测效率。由于攻击者经常利用无管理网络进行攻击活动,因此/24前缀相同的IP存在高相似性,该网下所有IP被利用于攻击概率很大。这个时候我们可以对这些同前缀IP进行选择性的扩展,提高黑名单的覆盖率和检测效果。
BLAG的高准确性就是依靠这三大法宝,环环相扣,缺一不可。将三者按照先后顺序进行连通,这就是一个完整的BLAG工作流程。
2.2.2 数据集
在黑名单数据集一块,作者使用的是2016年1月到11月收集到的157份公开可用的黑名单,每份黑名单更新时间在15分钟到7天之间。迄今为止,已经获得了176million个黑名单IP地址。文中使用到的黑名单数据集包括不同种类的黑名单,包括垃圾邮件、木马、DDoS攻击等。黑名单来源有DShield、Nixspam、Spamhaus等。
文中涉及三种场景,恶意邮件或者垃圾邮件攻击、校园网上的DDoS攻击、域名根服务器上的DDoS攻击。每种攻击场景下都包括三种相同的数据集:训练集、验证集和测试集。
实验场景数据集的限制因素有:一个是,在定点定时,一次只能捕获少量合法或者恶意IP地址;第二个是,文章使用的数据集是2016年获取的,显得有点过时;第三个是,不具备域名根服务器上DDoS攻击场景下的验证集
3. 实验评估
3.1 评估
这部分主要内容是不同场景下不同黑名单技术的对比分析。
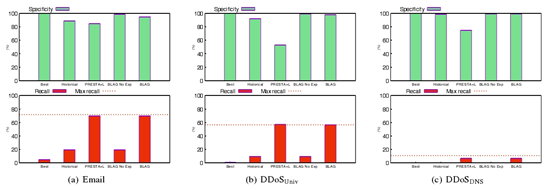
从上图,我们可以看到评估指标有两个:specificity(特异性)和recall(召回率)。特异性指的是未被列入黑名单合法源百分比,召回率指的是被列入黑名单恶意源百分比。通俗点,就是特异性代表的是误分类处理的效果,召回率代表的是聚合的效果。而本次实验,我们要追求的是双高。
从图中,我们可以看到BLAG在不同场景下的效果都很好。相比于竞争性比较高的PRESRA+L,虽然两者召回率相差不大,但是BLAG特异性显著强于PRESTA+L。其他类型的竞品均存在较大的差距。
其中,需要说明的是,作者对无扩展BLAG也列入了对比项。这一部分主要是对选择性扩展对BLAG的贡献做一个说明。我们可以看到,在特异性几乎相同的情况下,扩展BLAG比无扩展BLAG召回率高的多,这说明选择性扩展提高了BLAG的覆盖率。
上述图片和分析过程主要对BLAG的准确性和覆盖率进行了一个看图作文,体现了BLAG的高准确性和高覆盖率。下面我们通过一张图片了解BLAG的快。

从图中,我们可以看到竞品检测速率在BLAG下不堪一击。不同场景下,竞品的检测速率均远低于BLAG。这张图体现了BLAG的快。
集快、准、狠于一身的BLAG优势尽显,将竞品摁在地上摩擦。
3.2 敏感性分析
这一块,感觉像是对各部件的论功行赏。包括选择性扩展的贡献、推荐系统的贡献、个人黑名单的贡献、已知合法源的贡献四大块内容。
首先分析一下选择性扩展。这部分主要对三个关键点进行了说明:一个是BLAG性能强弱与聚合能力和扩展能力有关,另一个是BLAG优于最优扩展和历史扩展,最后一个是BLAG使用了BGP前缀和AS级别的扩展方法。
下面介绍一下推荐系统在BLAG中的作用。图像描述比文字描述更加形象,下面我们通过一张图来了解推荐系统的作用。
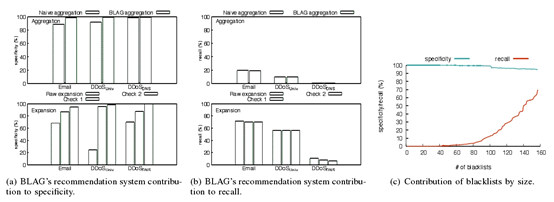
(a)和(b)体现了推荐系统在BLAG特异性和召回率的贡献是很大的。
然后是单个黑名单在BLAG中的作用,这里可以看下上图中的(c)。BLAG通过聚合不同类型黑名单的方式来实现单单多类检测。足够丰富的单个黑名单为BLAG提供了足够多的训练数据,这有利于BLAG主黑名单召回率的提升。因为足够大的训练样本,可以提供更多的恶意源数据。当然,由于合法源数据值有限,训练样本的提升在一定程度上会降低特异性。
最后一部分是关于已知合法源对BLAG的影响。在BLAG中,已知合法源在推荐系统中用于降低误分类数量,也就是量化为提高特异性数值。
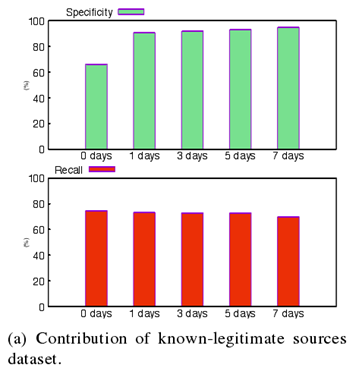
足够多的合法源IP有利于进行误分类合法IP的消除,但是也会对召回率造成一定程度的干扰。
3.3 参数调整
这里主要对BLAG中涉及的几个参数进行了解释说明。
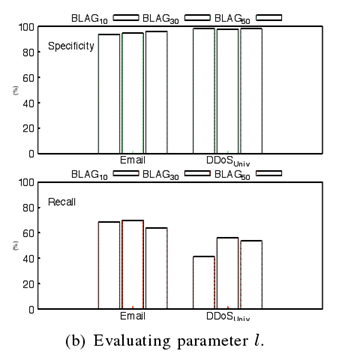
第一个是在进行相关性分析过程中的 l 参数,这是个历史衰减参数。这个参数的作用是对时间维长度进行定量分析,文章选定了10、30、50三个值进行对比实验分析,最后确定30取得的效果是最好的。30也是本文在进行相关性分析中使用的值。
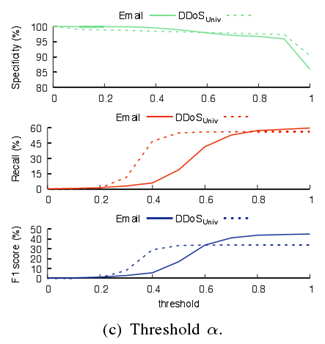
第二个是推荐系统中使用到的阈值 α 参数,这个参数主要是在使用推荐系统进行误分类删除时起作用。通过不同值的对比分析,不同场景下,阈值不一样。在垃圾邮件攻击和域名根服务器DDoS攻击两种场景中,阈值选定为0.8,而在校园网DDoS场景中,选定的阈值则为0.6。
最后一个做说明的参数时矩阵分解参数 K ,这个参数表示的是潜在特征个数。理想状况下,K 值越小,效果越好。在经过实验评估,本文选定的值大小为1000。
3.4 相关工作
本部分主要介绍了现有的一些黑名单分析、黑名单改进和黑名单聚合的工作。
首先是黑名单分析一块,这部分主要通过举证别人的研究来说明当前黑名单不够准确这个特性,从而支撑文章的观点。在结尾部分,作者又对BLAG进行一通表扬,表示BLAG比当前黑名单更加准确。
在黑名单改进一块,主要对PRESTA进行了说明。在对比论证的过程中,作者基于公共黑名单对PRESTA进行试验,取得的效果与原文基于付费黑名单差别较大。这也突出了BLAG使用野生的公共黑名单的优越性。
在黑名单聚合一块,主要列举了基于网页排序算法的HPB(高预测黑名单)和一种通过监控email服务器和垃圾邮件陷阱的新型垃圾邮件黑名单系统。通过对比说明,作者一句话总结了BLAG的技术优点:适用于拦截不同类型攻击。
4. 讨论总结
现有BLAG技术面临一个问题,那就是BLAG无法区分低质量和高质量信息。当攻击者使用合法IP进行诱骗攻击时,BLAG无法有效区分,进而对合法资源进行删除。这个问题在现有黑名单技术也是存在的,因此这不能算是BLAG的特一性问题。文章作者也将这一问题列为了下一步工作的重点。
当前黑名单存在专业化和高重叠问题,通常会错过大量攻击IP。本文通过提出BLAG这一黑名单新技术,有效的提高了黑名单应对新型或者大规模攻击的应急响应效率。同时,与优势竞品PRESTA+L相比,BLAG表现更加突出,BLAG比现有生成黑名单技术更快、更准、更狠。
5. 论文阅读总结
BLAG是一项全新的生成黑名单的技术,与竞品相比,BLAG准确性更高,而且适用范围更广。通过相关性分析、推荐系统和聚合三重奏,有效提高了生成黑名单的准确性和普适性。
我起初相中这篇文章,是因为blacklists。因为我的邮箱和短信总能收到一些垃圾东西,于是就想看看BLAG到底是个东西。在经过本篇论文的阅读和理解,我逐渐意识到生成一个准确的黑名单确实挺难的。首先要考虑抓住攻击IP,同时又要保证合法通信不被过滤。
本文提到的BLAG是一种比较新颖的黑名单生成技术,它比较多的结合了机器学习当中的知识。这也反映出机器学习对于相关学科的推动发展作用。
6. 项目复现
这里简单说明介绍一下它涉及到的几条操作指令。
首先,我们需要通过pip install surprise pandas安装surprise包,它是python语言当中用于运行推荐系统的包。
然后,运行python process_blacklists.py --start_date "" --end_date "" --blacklist_folder ""指令生成一个processed_blacklists文件,文件里头是用于下一步操作的IP地址。其中,blacklist_folder就是文件夹中的blacklists/
最后,通过python blag.py --end_date "" --misclassifications "" --output_file ""生成推荐分数。其中,misclassifications包含已知合法源IP,样例中的false_positives就是使用到的误分类文件。
上面就是本项目需要使用到的三条指令,下面讲一下复现过程中遇到的一些问题:
-
第一,刚开始使用项目脚本时,几乎每个脚本都存在问题……这就非常尴尬了。在我使用pycharm进行修改之后,问题没了,但是结果也没有出现……这就更尴尬了。于是,我给通讯作者发了一封邮件,他回复说会去查验。经过一段时间的查验,作者对工程进行了较大的改动。
-
第二,在对校正的项目脚本运行之后,脚本没有问题,但是输出出问题了。第二条命令运行之后,输出了一个空的
processed_blacklists文件;第三条命令运行之后,报了一个PicklingError。于是我又去了一封邮件……然后现在还在等作者的解决方案。
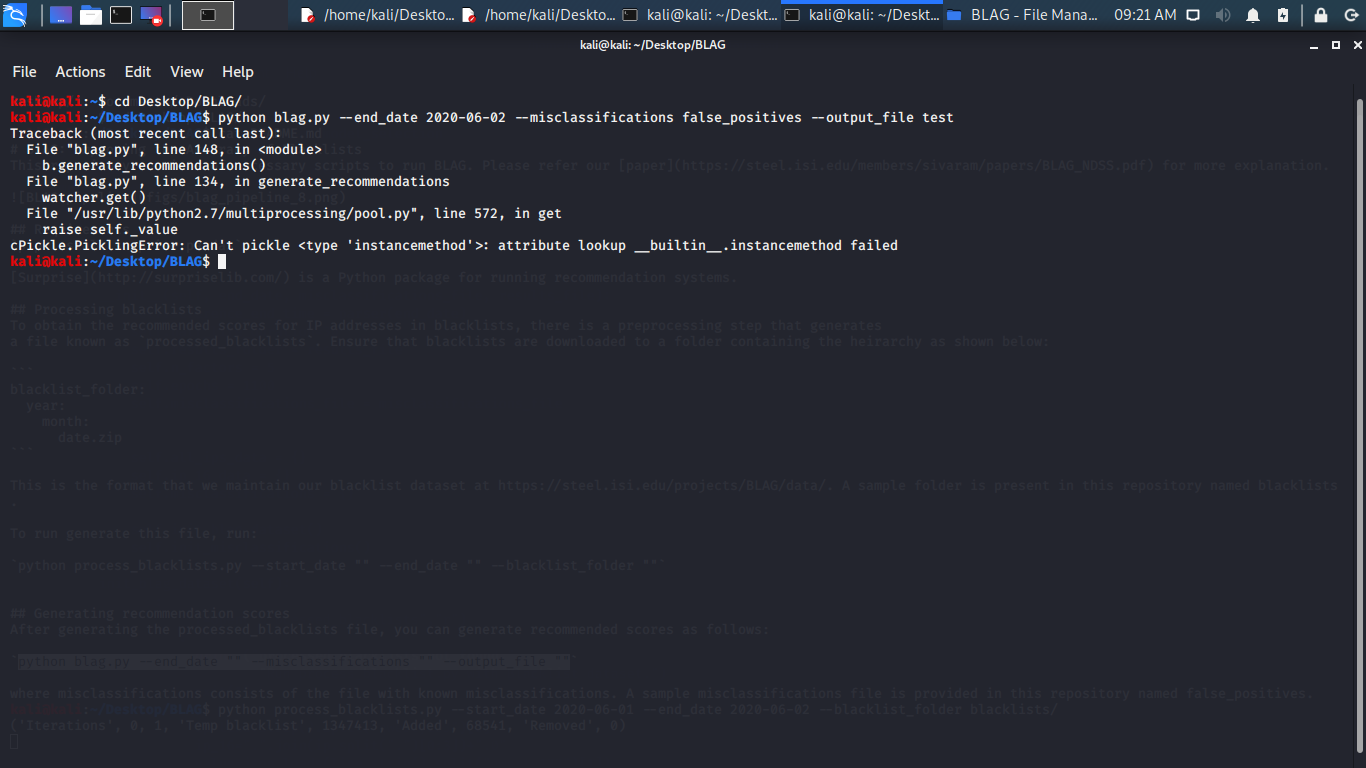
- 第三,在复现项目的过程中,我发现
pip安装部分包比apt-get要顺利很多,不知道是不是两者安装源或者包源不一样。在使用sudo apt-get install surprise pandas时,老是提示无法定位到包源。在查找博客完成pip安装,再使用pip install surprise pandas安装成功。如果以后遇到类似的问题,或许有了新的思路。
最后总结一下复现的过程吧。虽然没能成功复现结果,没有达到老师要求的“只看结果,不重过程”,略显遗憾,但是复现过程的收获还是不小的。
-
一是尝试与项目作者进行邮件沟通,在一定程度上帮助了作者优化项目脚本和
README,也锻炼了自己的表达能力; -
二是意识到顶会的项目同样会存在问题,出错原因千奇百怪,需要自己排查和询问项目作者双向并行;
-
三是在“出现问题——分析问题——解决问题”这条路子上有了更多理解,并不是所有问题都能通过自己解决,很多时候要向外寻求帮助。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号