

Python高级应用程序设计
一、主题式网络爬虫设计方案(15分)
1.主题式网络爬虫名称:爬取华图教育官网2019年福建公务员招聘岗位信息
2.主题式网络爬虫爬取的内容与数据特征分析:爬取2019年福建公务员招聘岗位信息
3.主题式网络爬虫设计方案概述(包括实现思路与技术难点)
3.主题式网络爬虫设计方案概述(包括实现思路与技术难点)
1).从网络上获取华图教育福建公务员招聘岗位信息内容 ,需要先看清楚要爬取的内容
2).提取网页内容中信息核实的数据结构,提取时需注意所需要的内容所在的标签,前后容易混淆
3).创建文件夹自动下载招聘信息表
4).利用数据结构展示并输出结果,绘制分析图其中选择的x、y轴的信息
二、主题页面的结构特征分析(15分)
1.主题页面的结构特征
1.主题页面的结构特征
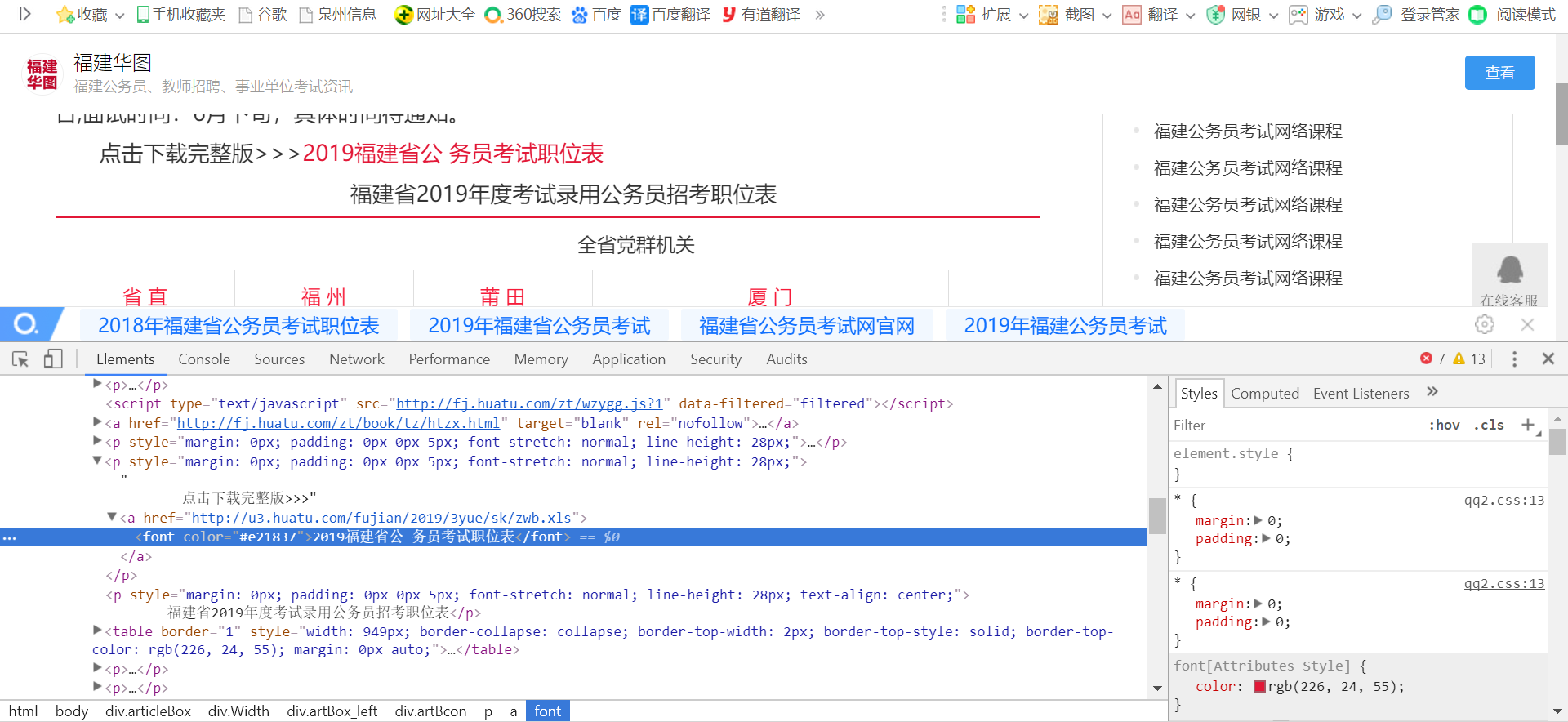
2.Htmls页面解析
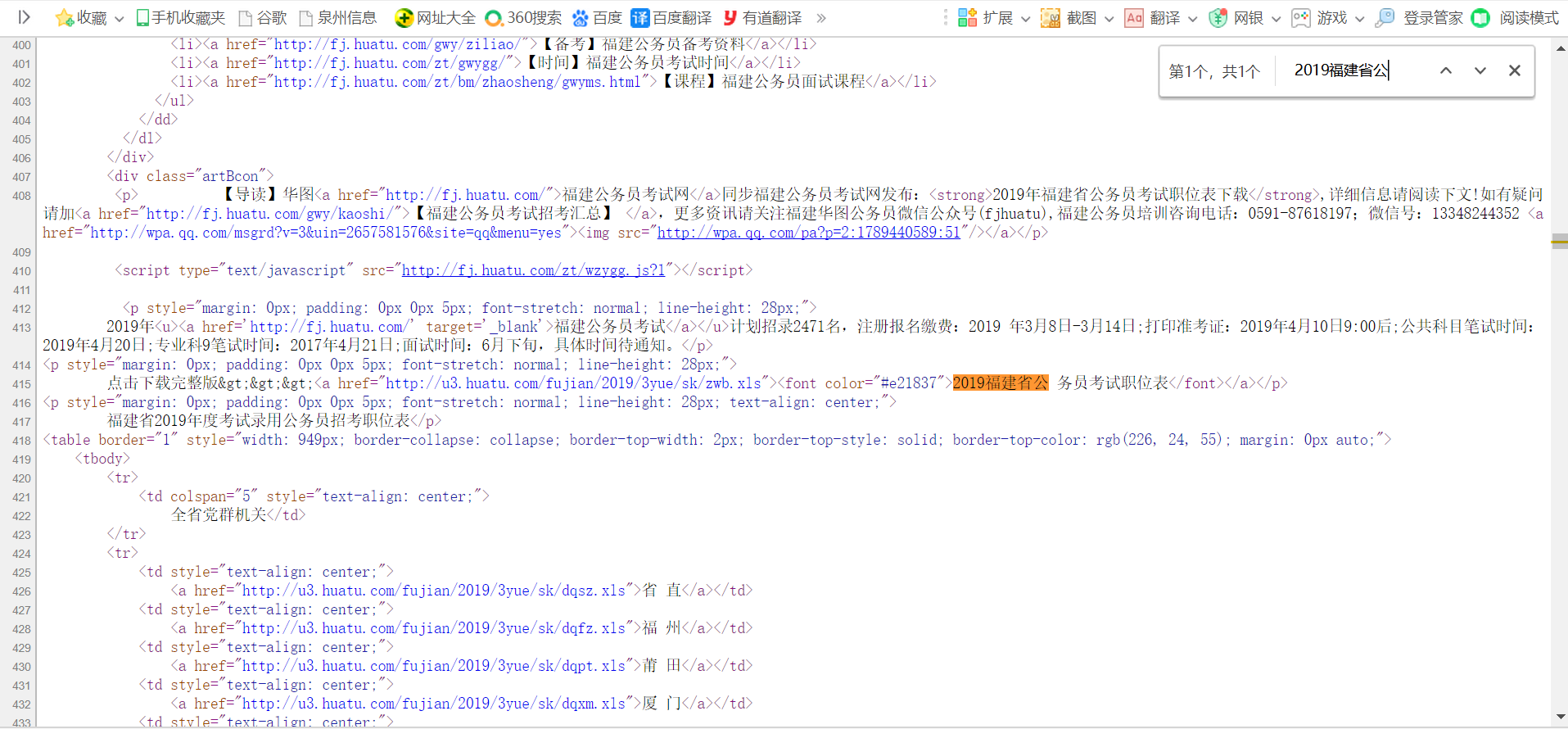
3.节点(标签)查找方法与遍历方法
查找方法:find_all
遍历方法:for循环
三、网络爬虫程序设计(60分)
爬虫程序主体要包括以下各部分,要附源代码及较详细注释,并在每部分程序后面提供输出结果的截图。
1.数据爬取与采集
1 import requests 2 from bs4 import BeautifulSoup 3 url="http://zw.huatu.com/skzwb/" 4 def getHTMLText(url): #请求url链接 5 try: 6 r=requests.get(url,timeout=30) #get获取url信息,并且设置时间是30秒 7 r.raise_for_status() #根据返回的Response对象,调用raise_for_status()方法判断返回的内容是否正常 8 #状态200表示返回的内容正确;状态不是200,则引发HTTPError异常 9 r.encoding=r.apparent_encoding #用encoding替代apparent_encoding使返回内容的解码正确 10 return r.text #返回网页内容 11 except: 12 return"产生异常" 13 print(getHTMLText(url))
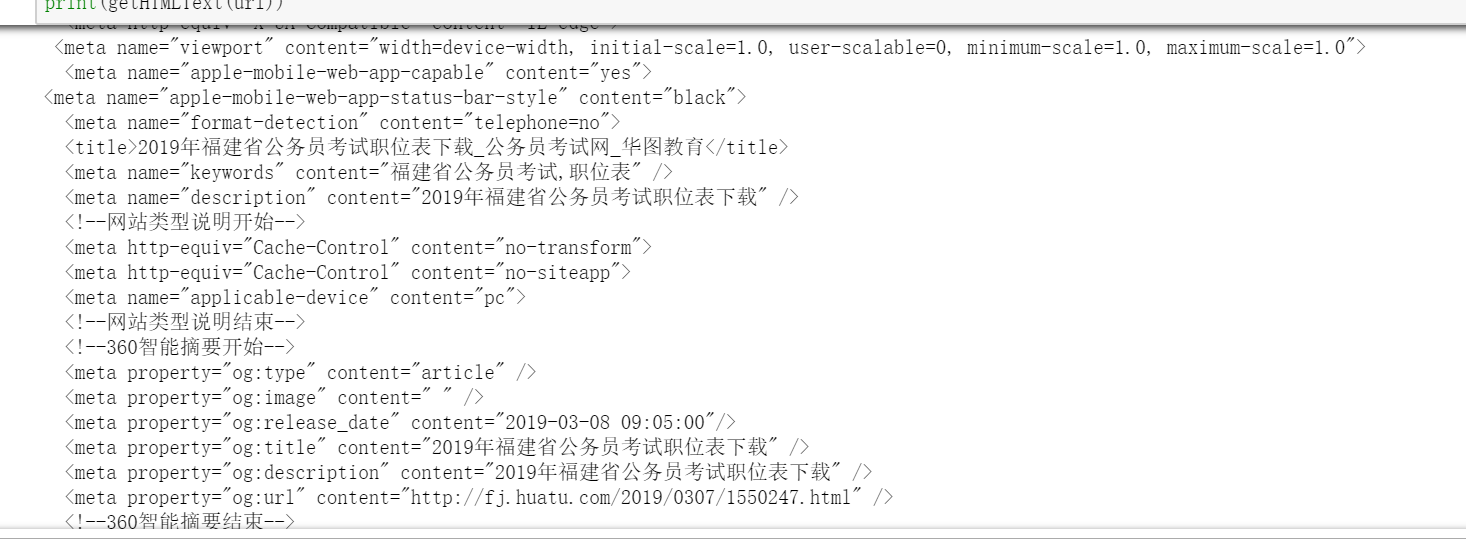
1 import requests 2 from bs4 import BeautifulSoup 3 filelist = [] 4 getFile(html,filelist) #获取文件名 5 url = 'http://fj.huatu.com/2019/0307/1550247.html' 6 r = requests.get(url) 7 r.encoding=r.apparent_encoding 8 def getFile(html,filelist): #获取文件名 9 soup = BeautifulSoup(html,"html.parser") 10 for p in soup.find_all("p"): #遍历所有属性为p的p标签 11 for a in p.find_all("a"): #遍历p标签中的a标签 12 if '2019' in a.attrs['href']: #判断a标签中的herf属性中是否含有“2019” 13 filelist.append(a.get_text()) #将含有“2019”的a的文本内容存储在filelist列表中 14 print(filelist)

1 import requests 2 from bs4 import BeautifulSoup 3 import os 4 5 url = "http://fj.huatu.com/2019/0307/1550247.html" #华图教育公务员考试网 6 7 html = getHTMLText(url) #获取页面html代码 8 filelist = [] #存储文件名 9 getFile(html,filelist) #获取文件名 10 urllist = [] #存储目标url链接 11 getURL(html,urllist) #获取目标的url链接 12 13 def getHTMLText(url): #请求url链接 14 try: 15 r = requests.get(url,timeout=30) #get获取url信息,并且设置时间是30秒 16 r.raise_for_status() #根据返回的Response对象,调用raise_for_status()方法判断返回的内容是否正常 17 #状态200表示返回的内容正确;状态不是200,则引发HTTPError异常 18 r.encoding = r.apparent_encoding #用encoding替代apparent_encoding使返回内容的解码正确 19 return r.text #返回页面内容 20 except: 21 return "产生异常" #如果爬取失败,返回“产生异常” 22 23 def getFile(html,filelist): #获取文件名 24 soup = BeautifulSoup(html,"html.parser") 25 for p in soup.find_all("p"): #遍历所有属性为p的p标签 26 for a in p.find_all("a"): #遍历p标签中的a标签 27 if '2019' in a.attrs['href']: #判断a标签中的herf属性中是否含有“2019” 28 filelist.append(a.get_text()) #将含有“2019”的a的文本内容存储在filelist列表中 29 return filelist 30 31 def getURL(html,urllist): #获取目标链接 32 soup = BeautifulSoup(html,"html.parser") 33 for p in soup.find_all("p"): #遍历所有属性为p的p标签 34 for a in p.find_all("a"): #遍历p标签中的a标签 35 if '2019' in a.attrs['href']: #判断a标签中的herf属性中是否含有“2019” 36 urllist.append(a.attrs['href']) #将含有“2019”的a中的链接存储在urllist列表中 37 return urllist 38 39 def dataStore(file,name): #数据存储 40 try: 41 os.mkdir("D:\省考职位表") #创建文件夹 42 except: 43 "" 44 try: 45 with open("D:\\省考职位表\\{}.xls".format(name),"wb") as fp: #创建文件存储爬取到的数据 46 fp.write(file.content) 47 print("下载成功") 48 except: 49 "存储失败" 50 51 for i in range(0,len(urllist)): #将目标信息存储在本地 52 file=requests.get(urllist[i]) #获取链接下的文件信息 53 dataStore(file,filelist[i]) #将文件信息存储在本地
![]()

2.对数据进行清洗和处理
1 #导入数据集 2 import pandas as pd 3 fj=pd.DataFrame(pd.read_excel('D:\省考职位表/2019福建省公 务员考试职位表.xls')) 4 fj.head()

1 # 删除无效列 2 fj.drop('机关代码', axis = 1, inplace=True) 3 fj.head()

1 # 查找重复值 2 fj.duplicated()
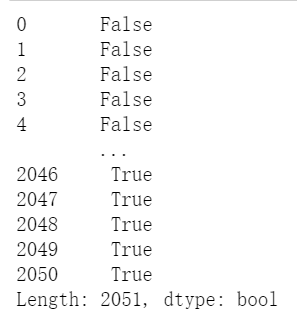
1 # 删除重复值 2 fj = fj.drop_duplicates() 3 fj.head()

1 # 统计空值的个数 2 fj['备注'].isnull().value_counts()

1 # 使用fillna方法填充空值 2 fj['备注'] = fj['备注'] .fillna('无') 3 fj

1 #使用describe查看统计信息 2 fj.describe()

3.数据分析与可视化
(例如:数据柱形图、直方图、散点图、盒图、分布图、数据回归分析等)
1 # 数据柱形图 2 import pandas as pd 3 import numpy as np 4 import matplotlib.pyplot as plt 5 plt.rcParams['font.sans-serif']=['Arial Unicode MS'] #用来正常显示中文标签 6 plt.rcParams['axes.unicode_minus']=False #用来正常显示负号 7 data=np.array([1056,493,110,230,162]) 8 index=['A类','A类(乡镇)','A类加考公安','B类','B类加考法语'] 9 s = pd.Series(data, index) 10 s.name='省考考试类别' 11 s.plot(kind='bar',title='省考考试类别') 12 plt.show()

1 #饼图 2 import matplotlib.pyplot as plt 3 Labels = ['福州', '龙岩', '南平', '宁德', '莆田', '泉州', '三明', '厦门','省直','漳州'] 4 Data = [563,192,405,214,121,194,235,96,598,96] 5 #cols = ['r','g','y','coral'] 6 #绘制饼图 7 plt.pie(Data ,labels=Type, autopct='%1.1f%%') 8 plt.axis(aspect='equal') #将横、纵坐标轴标准化处理,设置显示图像为正圆 9 plt.rcParams['font.sans-serif']=['SimHei'] #设置字体样式 10 plt.title('2019年福建省公务员各地区招考人数比例') 11 plt.show()

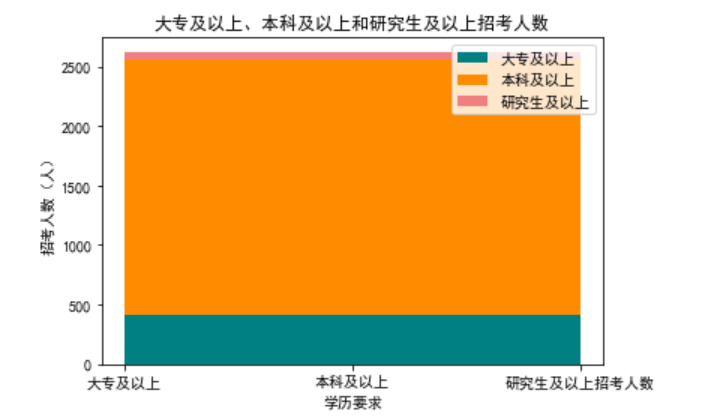
1 # 绘制堆叠图 2 academic_requirements=['大专及以上','本科及以上','研究生及以上招考人数'] 3 junior_college=[416] 4 undergraduate=[2148] 5 graduate_student=[52] 6 x=list(range(len(junior_college))) 7 plt.stackplot(academic_requirements,junior_college,undergraduate,graduate_student, colors=['teal','darkorange','lightcoral'], labels=['大专及以上', '本科及以上','研究生及以上']) 8 plt.title("大专及以上、本科及以上和研究生及以上招考人数") 9 plt.xlabel("学历要求") 10 plt.ylabel("招考人数(人)") 11 plt.legend() 12 plt.show()
4.数据持久化
5.全部代码
1 import requests 2 from bs4 import BeautifulSoup 3 import os 4 5 url = "http://fj.huatu.com/2019/0307/1550247.html" #华图教育公务员考试网 6 7 html = getHTMLText(url) #获取页面html代码 8 filelist = [] #存储文件名 9 getFile(html,filelist) #获取文件名 10 urllist = [] #存储目标链接 11 getURL(html,urllist) #获取目标链接 12 13 def getHTMLText(url): #请求url链接 14 try: 15 r = requests.get(url,timeout=30) #get获取url信息,并且设置时间是30秒 16 r.raise_for_status() #根据返回的Response对象,调用raise_for_status()方法判断返回的内容是否正常 17 #状态200表示返回的内容正确;状态不是200,则引发HTTPError异常 18 r.encoding = r.apparent_encoding #用encoding替代apparent_encoding使返回内容的解码正确 19 return r.text #返回页面内容 20 except: 21 return "产生异常" #如果爬取失败,返回“产生异常” 22 23 def getFile(html,filelist): #获取文件名 24 soup = BeautifulSoup(html,"html.parser") 25 for p in soup.find_all("p"): #遍历所有属性为p的p标签 26 for a in p.find_all("a"): #遍历p标签中的a标签 27 if '2019' in a.attrs['href']: #判断a标签中的herf属性中是否含有“2019” 28 filelist.append(a.get_text()) #将含有“2019”的a的文本内容存储在filelist列表中 29 return filelist 30 31 def getURL(html,urllist): #获取目标链接 32 soup = BeautifulSoup(html,"html.parser") 33 for p in soup.find_all("p"): #遍历所有属性为p的p标签 34 for a in p.find_all("a"): #遍历p标签中的a标签 35 if '2019' in a.attrs['href']: #判断a标签中的herf属性中是否含有“2019” 36 urllist.append(a.attrs['href']) #将含有“2019”的a中的链接存储在urllist列表中 37 return urllist 38 39 def dataStore(file,name): #数据存储 40 try: 41 os.mkdir("D:\省考职位表") #创建文件夹 42 except: 43 "" 44 try: 45 with open("D:\\省考职位表\\{}.xls".format(name),"wb") as fp:#创建文件存储爬取到的数据 46 fp.write(file.content) 47 print("下载成功") 48 except: 49 "存储失败" 50 51 for i in range(0,len(urllist)): #将目标信息存储在本地 52 file=requests.get(urllist[i]) #获取链接下的文件信息 53 dataStore(file,filelist[i]) #将文件信息存储在本地
四、结论(10分)
1.经过对主题数据的分析与可视化,可以得到哪些结论?
1.经过对主题数据的分析与可视化,可以得到哪些结论?
1)、省考考试类别中,A类最多,其次是A类(乡镇),而后是B类加考法语、B类,A类加考公安
2)、招考人数中,省直地区最多,再是福州和南平,其余相差无几
3)、招考人数的学历要求中,本科及以上远远高于大专及以上和研究生及以上
2.对本次程序设计任务完成的情况做一个简单的小结。
通过本次的设计任务,更好地了解主题式网络爬虫。在从一开始的选题就首先要注意,不是随意选择就可以进行爬取的。除了依据自己的能力,还需根据对应的网站或者网页进行判断。在查找内容位置的标签等还需更加仔细。基本上完成了大致的数据提取以及清洗和处理。在过程中遇到困惑的问题,通过查找资料以及请教同学进行解决。对一些相关的知识点还是不够熟悉,还需要进一步加强。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号