
自学LinkedBlockingQueue源码
自学LinkedBlockingQueue源码 #
参考:http://www.jianshu.com/p/cc2281b1a6bc
本文需要关注的地方
- 生产者-消费者模式好处;
- 读取和插入操作所使用的锁是两个不同的ReentrantLock(takeLock和putLock),它们之间的操作互相不受干扰,因此两种操作可以并行完成;
- 通过Condition的线程间通信来实现线程的等待通知。特别注意:在Condition对象中,与wait、notify和notifyAll方法对应的分别是await、signal和signalAll。但是,Condition对Object进行了扩展,因而它也包含了wait和notify方法。一定要确保使用正确的版本——await和signal。
一、基础知识
阻塞队列主要用于“生产者-消费者” 设计模式。
BlockingQueue 方法以四种形式出现,对于不能立即满足但可能在将来某一时刻可以满足的操作,这四种形式的处理方式不同:第一种是抛出一个异常,第二种是返回一个特殊值(null 或 false,具体取决于操作),第三种是在操作可以成功前,无限期地阻塞当前线程,第四种是在放弃前只在给定的最大时间限制内阻塞。下表中总结了这些方法:
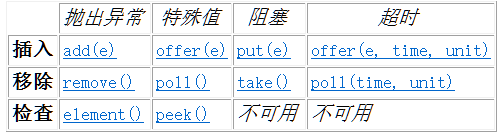
1. 阻塞队列和生产者 - 消费者模式
LinkedBlockingQueue在BlockingQueue的实现类中使用最多(如果知道队列的大小,可以考虑使用ArrayBlockIngQueue,它使用循环数组实现。但是如果不知道队列未来的大小,那么使用ArrayBlockingQueue就必然会导致数组的来回复制,降低效率)。我们主要关心可阻塞的put和take方法,以及支持定时的offer和poll方法。如果队列已经满了,那么put方法将阻塞直到有空间可用;如果队列为空,那么take方法将会阻塞直到有元素可用。队列可以是有界的也可以是无界的,无界队列永远都不会充满,因此无界队列上 的put方法也永远不会阻塞(如果没有定义上限,将使用 Integer.MAX_VALUE 作为上限)。
生产者-消费者模式好处
- 解耦:假设生产者和消费者分别是两个类。如果让生产者直接调用消费者的某个方法,那么生产者对于消费者就会产生依赖(也就是耦合)。如果将来消费者的代码发生变化, 可能会影响到生产者。而如果两者都依赖于某个缓冲区(比如阻塞队列),两者之间不直接依赖,耦合也就相应降低了,同时提高了代码可读性和可重用性
- 提高并发性能:生产者直接调用消费者的某个方法,还有另一个弊端。由于函数调用是同步的(或者叫阻塞的),在消费者的方法没有返回之前,生产者只好一直等在那边。使用了生产者/消费者模式之后,由于生产者与消费者是两个独立的并发体,他们之间是用缓冲区作为桥梁连接,生产者只需要往缓冲区里丢数据,就可以继续生产下一个数据,而消费者只需要从缓冲区里拿数据即可,减少了因为彼此的处理速度差异而引起的阻塞。
- 在高并发场景下平滑短时间内大量的服务请求:在访问量剧增的情况下,你的应用仍然需要继续发挥作用,但是这样的突发流量并不常见;如果以能处理这类峰值访问为标准来投入资源随时待命无疑是巨大的浪费。而在生产者-消费者模式中,当数据生产快的时候,消费者来不及处理,未处理的数据可以暂时存在缓冲区中,等生产者的生产速度慢下来,消费者再慢慢处理掉。
2. 源码分析
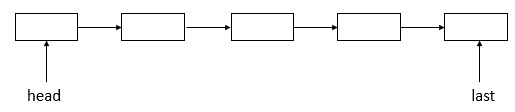
LinkedBlockingQueue采用的是单链表结构,包含了头结点和尾节点,last入队,head出队。
入队:last.next=node;last = node;,即last中保存了最后一个有效元素;
出队:Node<E> h = head; Node<E> first = h.next; head = first; E x = first.item; first.item = null; return x;,即head并没有存放有效的值(为null),将head指向的下一个节点的值返回,并将下一个节点的设为新的head。
// 所有的元素都通过Node这个静态内部类来进行存储,这与LinkedList的处理方式完全一样
static class Node<E> {
//使用item来保存元素本身
E item;
//保存当前节点的后继节点
Node<E> next;
Node(E x) { item = x; }
}
/**
阻塞队列所能存储的最大容量
用户可以在创建时手动指定最大容量,如果用户没有指定最大容量
那么最默认的最大容量为Integer.MAX_VALUE.
*/
private final int capacity;
/**
当前阻塞队列中的元素数量,由于它的入队列和出队列使用的是两个
不同的lock对象,因此无论是在入队列还是出队列,都会涉及对元素数
量的并发修改,因此这里使用了一个原子操作类来解决对同一个变量进行并发修改的线程安全问题。
*/
private final AtomicInteger count = new AtomicInteger(0);
/**
* 链表的头部
* LinkedBlockingQueue的头部具有一个不变性:
* 头部的元素总是为null,head.item==null
*/
private transient Node<E> head;
/**
* 链表的尾部
* LinkedBlockingQueue的尾部也具有一个不变性:
* 即last.next==null
*/
private transient Node<E> last;
/**
元素出队列时线程所获取的锁
当执行take、poll等操作时线程需要获取的锁
*/
private final ReentrantLock takeLock = new ReentrantLock();
/**
当队列为空时,通过该Condition让从队列中获取元素的线程处于等待状态
*/
private final Condition notEmpty = takeLock.newCondition();
/**
元素入队列时线程所获取的锁
当执行add、put、offer等操作时线程需要获取锁
*/
private final ReentrantLock putLock = new ReentrantLock();
/**
当队列的元素已经达到capactiy,通过该Condition让元素入队列的线程处于等待状态
*/
private final Condition notFull = putLock.newCondition();
通过上面的分析,我们可以发现LinkedBlockingQueue在入队列和出队列时使用的不是同一个Lock,这也意味着它们之间的操作不会存在互斥操作。在多个CPU的情况下,它们可以做到真正的在同一时刻既消费、又生产,能够做到并行处理。
put方法
/**
* 其实下面的代码等价于如下内容:
* last.next=node;
* last = node;
*/
private void enqueue(Node<E> node) {
last = last.next = node;
}
public void put(E e) throws InterruptedException {
if (e == null) throw new NullPointerException();
int c = -1;
Node<E> node = new Node(e);
/*
在这里首先获取到putLock,以及当前队列的元素数量
*/
final ReentrantLock putLock = this.putLock;
final AtomicInteger count = this.count;
/*
执行可中断的锁获取操作
*/
putLock.lockInterruptibly();
try {
/*
当队列的容量到达最大容量时,此时线程将处于等待状态,直到队列有空闲的位置才继续执行。使用while判
断依旧是为了防止线程被"伪唤醒”而出现的情况,即当线程被唤醒时而队列的大小依旧等于capacity时,线程应该继续等待。
*/
while (count.get() == capacity) {
notFull.await();
}
//让元素进行队列的末尾
enqueue(node);
c = count.getAndIncrement();
/*注:c+1得到的结果是新元素入队列之后队列元素的总和。
当前队列中的总元素个数小于最大容量时,此时唤醒其他执行入队列的线程
让它们可以放入元素,如果新加入元素之后,队列的大小等于capacity,
那么就意味着此时队列已经满了,也就没有必须要唤醒其他正在等待入队列的线程,因为唤醒它们之后,它们也还是继续等待。
*/
if (c + 1 < capacity)
notFull.signal();
} finally {
putLock.unlock();
}
/*当c=0时,即意味着之前的队列是空队列,出队列的线程都处于等待状态,
现在新添加了一个新的元素,即队列不再为空,因此它会唤醒正在等待获取元素的线程。
*/
if (c == 0)
signalNotEmpty();
}
/*
唤醒正在等待获取元素的线程,告诉它们现在队列中有元素了
*/
private void signalNotEmpty() {
final ReentrantLock takeLock = this.takeLock;
takeLock.lock();
try {
//通过notEmpty唤醒获取元素的线程
notEmpty.signal();
} finally {
takeLock.unlock();
}
}
offer方法
/**
该方法会返回一个boolean值,当入队列成功返回true,入队列失败返回false
*/
public boolean offer(E e) {
if (e == null) throw new NullPointerException();
final AtomicInteger count = this.count;
/*
当队列已经满了,它不会继续等待,而是直接返回。因此该方法是非阻塞的。
*/
if (count.get() == capacity)
return false;
int c = -1;
Node<E> node = new Node(e);
final ReentrantLock putLock = this.putLock;
putLock.lock();
try {
/*
当获取到锁时,需要进行二次的检查,因为获取锁和判断不是原子操作
*/
if (count.get() < capacity) {
enqueue(node);
c = count.getAndIncrement();
if (c + 1 < capacity)
notFull.signal();
}
} finally {
putLock.unlock();
}
if (c == 0)
signalNotEmpty();
return c >= 0;
}
take方法
public E take() throws InterruptedException {
E x;
int c = -1;
final AtomicInteger count = this.count;
final ReentrantLock takeLock = this.takeLock;
//通过takeLock获取锁,并且支持线程中断
takeLock.lockInterruptibly();
try {
//当队列为空时,则让当前线程处于等待
while (count.get() == 0) {
notEmpty.await();
}
//完成元素的出队列
x = dequeue();
/*
队列元素个数完成原子化操作-1,可以看到count元素会在插入元素的线程和获取元素的线程进行并发修改操作。
*/
c = count.getAndDecrement();
/*
当一个元素出队列之后,队列的大小依旧大于1时当前线程会唤醒其他执行元素出队列的线程,让它们也可以执行元素的获取
*/
if (c > 1)
notEmpty.signal();
} finally {
//完成锁的释放
takeLock.unlock();
}
/*
当c==capaitcy时,即在获取当前元素之前,队列已经满了,而此时获取元素之后,队列就会空出一个位置,故当前线程会唤醒执行插入操作的线程通知其他中的一个可以进行插入操作。
*/
if (c == capacity)
signalNotFull();
return x;
}
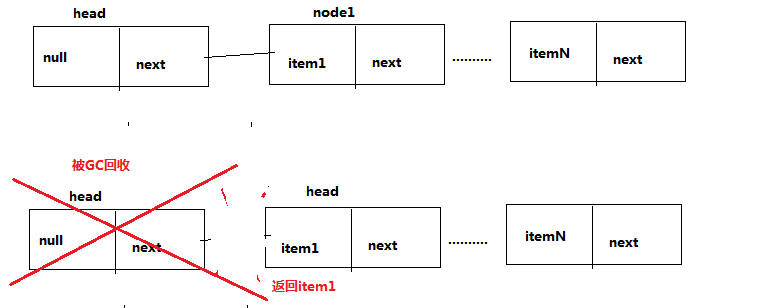
/**
* 让头部元素出队列的过程
* 其最终的目的是让原来的head被GC回收,让其的next成为head
* 并且新的head的item为null.
* 因为LinkedBlockingQueue的头部具有一致性:即元素为null。
*/
private E dequeue() {
Node<E> h = head;
Node<E> first = h.next;
h.next = h; // help GC
head = first;
E x = first.item;
first.item = null;
return x;
}
peek方法
peek类操作其实比较简单。因为有一个head节点去维护当前的队首元素。只有判断先first(head的后继)是否为空就好。
public E peek() {
if (count.get() == 0)
return null;
final ReentrantLock takeLock = this.takeLock;
takeLock.lock();
try {
Node<E> first = head.next;
if (first == null)
return null;
else
return first.item;
} finally {
takeLock.unlock();
}
}
remove方法
public boolean remove(Object o) {
if (o == null) return false;
fullyLock();//获取存元素锁和取元素锁(不允许存或取元素),因为有可能同时涉及到头尾结点的访问问题
try {
for (Node<E> trail = head, p = trail.next; p != null; trail = p, p = p.next) {// 遍历整个链表
if (o.equals(p.item)) {// 结点的值与指定值相等
unlink(p, trail); // 断开结点
return true;
}
}
return false;
} finally {
fullyUnlock();
}
}
void unlink(Node<E> p, Node<E> trail) {
p.item = null;
trail.next = p.next;// 断开p结点
if (last == p) // 尾节点为p结点
last = trail; // 重新赋值尾节点
if (count.getAndDecrement() == capacity)
notFull.signal();
}
void fullyLock() {
putLock.lock();
takeLock.lock();
}
void fullyUnlock() {
takeLock.unlock();
putLock.unlock();
}
3.LinkedBlockingQueue与ArrayBlockingQueue的比较
- ArrayBlockIngQueue,它使用循环数组实现,在创建时指定存储的大小,一定是有界的,如果不知道队列未来的大小,那么使用ArrayBlockingQueue就必然会导致数组的来回复制,降低效率;而LinkedBlockingQueue可以由用户指定最大存储容量,也可以无需指定,如果不指定则最大存储容量将是Integer.MAX_VALUE。
- ArrayBlockingQueue中在入队列和出队列操作过程中,使用的是同一个lock,所以即使在多核CPU的情况下,其读取和操作的都无法做到并行,而LinkedBlockingQueue的读取和插入操作所使用的锁是两个不同的lock,它们之间的操作互相不受干扰,因此两种操作可以并行完成,故LinkedBlockingQueue的吞吐量要高于ArrayBlockingQueue。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号