
Java序列化
Java序列化 #
参考:http://blog.csdn.net/jiangwei0910410003/article/details/18989711/
http://www.cnblogs.com/guanghuiqq/archive/2012/07/18/2597036.html
一、Serializable接口
1. Java序列化与反序列化
Java序列化是指把Java对象转换为字节序列的过程;而Java反序列化是指把字节序列恢复为Java对象的过程。即序列化就是将Java Object转成byte[];反序列化就是将byte[]转成Java Object。
2. 为什么需要序列化与反序列化
- 实现了数据的持久化,通过序列化可以把数据永久地保存到文件中或者数据库;
- 利用序列化实现远程通信,即在网络上传送对象的字节序列。
3. 利用Serializable接口实现序列化与反序列化
将需要序列化的类实现Serializable接口就可以了,Serializable接口中没有任何方法,可以理解为一个标记,即表明这个类可以序列化。
3.1 JDK类库中序列化API
java.io.ObjectOutputStream:表示对象输出流
它的writeObject(Object obj)方法可以对参数指定的obj对象进行序列化,把得到的字节序列写到一个目标输出流中。
java.io.ObjectInputStream:表示对象输入流
它的readObject()方法从输入流中读取字节序列,再把它们反序列化成为一个对象,并将其返回。
3.2 JDK类库中序列化的步骤
- 步骤一:创建一个对象输出流,它可以包装一个其它类型的目标输出流,如文件输出流:ObjectOutputStream out = new ObjectOutputStream(new fileOutputStream(“D:\objectfile.obj”));
- 步骤二:通过对象输出流的writeObject()方法写对象:out.writeObject(“Hello”);或者out.writeObject(new Date());
3.3 JDK类库中反序列化的步骤
- 步骤一:创建一个对象输入流,它可以包装一个其它类型输入流,如文件输入流:ObjectInputStream in = new ObjectInputStream(new fileInputStream(“D:\objectfile.obj”));
- 步骤二:通过对象输出流的readObject()方法读取对象:String obj1 = (String)in.readObject();或者Date obj2 = (Date)in.readObject();
说明:为了正确读取数据,完成反序列化,必须保证向对象输出流写对象的顺序与从对象输入流中读对象的顺序一致。
4. 例子
Student类:
import java.io.Serializable;
public class Student implements Serializable {
private String name;
private char sex;
private int year;
public Student() {}
public Student(String name, char sex, int year) {
this.name = name;
this.sex = sex;
this.year = year;
}
public void setName(String name) {
this.name = name;
}
public void setSex(char sex) {
this.sex = sex;
}
public void setYear(int year) {
this.year = year;
}
public String getName() {
return this.name;
}
public char getSex() {
return this.sex;
}
public int getYear() {
return this.year;
}
}
测试类:
import java.io.*;
public class UseStudent {
public static void main(String[] args) {
Student st = new Student("Tom", 'M', 20);
File file = new File("D:\\home\\IO\\student.txt");
try {
file.createNewFile();
} catch (IOException e) {
e.printStackTrace();
}
try {
// Student对象序列化过程
FileOutputStream fos = new FileOutputStream(file);
ObjectOutputStream oos = new ObjectOutputStream(fos);
oos.writeObject(st);
oos.flush();
oos.close();
fos.close();
// Student对象反序列化过程
FileInputStream fis = new FileInputStream(file);
ObjectInputStream ois = new ObjectInputStream(fis);
Student st1 = (Student) ois.readObject();
System.out.println("name = " + st1.getName());
System.out.println("sex = " + st1.getSex());
System.out.println("year = " + st1.getYear());
ois.close();
fis.close();
} catch (ClassNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}
生成的序列化文件:

5. 理解对象序列化后的文件格式
第一部分是序列化文件头
每个文件都是以下面这两个字节的“魔幻数字”开始的:AC ED
后面紧跟着对象序列化格式的版本号,目前是:00 05
73:TC_OBJECT声明这是一个新的对象
第二部分是序列化类的描述
72:TC_CLASSDESC声明这里开始一个新class
00 07:class名字的长度是7字节
53 74 75 64 65 6E 74:类名(ASCII码:Student,注意:我们这里并没有定义Student所属的包,正常情况下这里应该是包名.Student)
84 07 FA B3 1D A2 24 08: SerialVersionUID
02:标记号,该值声明该对象支持序列化
00 03:该类所包含的域的个数为3
第三部分是对象中各个属性项的描述
43::域类型,代表C,表示Char类型
00 03:域名字的长度,为3
73 65 78:sex属性的名称
49:域类型,代表I,表示Int类型
00 04:域名字的长度,为4
79 65 61 72:year属性的名称
4C:域类型,代表L,表示String类型
00 04:域名字的长度,为4
6E 61 6D 65:name属性的名称
74 00 12:实例域的类名及其长度
4C 6A 61 76 61 2F 6C 61 6E 67 2F 53 74 72 69 6E 67 3B:Ljava/lang/String;
第四部分输出该对象父类信息描述,这里没有父类,如果有,则数据格式与第二部分一样
78:TC_ENDBLOCKDATA,对象块结束标志
70:TC_NULL,说明没有其他超类的标志
第五部分输出对象的属性的实际值,如果属性项是一个对象,那么这里还将序列化这个对象,规则和第2部分一样。
00 4D:M
00 00 00 14:20
74 00 03:字符串类型及其长度
54 6F 6D:Tom
当存储一个对象时,这个对象所属的类也必须存储。但不是类的所有的class信息都被存储,只包含一些能唯一性确定类的描述。这个类的描述包含:
- 类名。
- 序列化的版本惟一的ID,它是数据域类型和方法签名的指纹。
- 描述序列化方法的标志集。
- 对数据域的描述。
指纹是通过对类、超类、接口、域类型和方法签名按照规范方式排序,然后将安全散列算法(SHA)应用于这些数据而获得的。在读入一个对象时,会拿其指纹与它所属的类的当前指纹进行比对,如果它们不匹配,那么就说明这个类的定义在该对象被写出之后发生过变化,因此会产生一个异常。
总结:
- 对象流输出中包含所有对象的类型和数据域。
- 每个对象都被赋予一个序列号。
- 相同对象的重复出现将被存储为对这个对象的序列号的引用。
- 序列化的流只记录了对象所属类的一些定义和域的值,其写入和读取是分别由客户端程序和服务端程序组装完成的,如果双方没有一个共同的基础(同一个类),是无法完成的。
6. serialVersionUID
简单来说,Java的序列化机制是通过在运行时判断类的serialVersionUID来验证版本一致性的。在进行反序列化时,JVM会把传来的字节流中的serialVersionUID与本地相应实体(类)的serialVersionUID进行比较,如果相同就认为是一致的,可以进行反序列化,否则就会出现序列化版本不一致的异常(InvalidCastException)。
serialVersionUID的生成方式: 根据类名、接口名、成员方法及属性等来生成一个64位(8字节的long型)的哈希字段,比如:private static final long serialVersionUID = xxxxL;
当实现java.io.Serializable接口的实体(类)没有显式地定义一个名为serialVersionUID(类型为long的变量)时,Java序列化机制会根据编译的class(根据类名、接口名、成员方法及属性等来生成一个64位的哈希字段,理论上是一一映射的关系,也就是唯一的)自动生成一个serialVersionUID作序列化版本,这种情况下,如果class文件(类名,方法名等)没有发生变化,就算再编译多次,serialVersionUID也不会变化的。如果我们不希望通过编译来强制划分软件版本,就需要显式地定义一个名为serialVersionUID,类型为long的变量,不修改这个变量值的序列化实体都可以相互进行序列化和反序列化。
我们考虑以下几个问题:
1、问题一:假设有A端和B端,如果2处的serialVersionUID不一致,会产生什么错误呢?
答:会报错版本不一致(解答可以见下面的测试)。
2、问题二:假设2处serialVersionUID一致,如果A端增加一个字段,B端不变,(或者A端不变,B端减少一个字段)会是什么情况呢?
答:序列化,反序列化正常,A端增加的字段丢失(被B端忽略)。
3、问题三:假设2处serialVersionUID一致,如果B段增加一个字段,A端不变,(或者A端减少一个字段,B端不变)会是什么情况呢?
答:序列化,反序列化正常,B端新增加的int字段被赋予了默认值0。
强烈建议所有可序列化类都显式声明 serialVersionUID 值,原因是计算默认的 serialVersionUID 对类的详细信息具有较高的敏感性,根据编译器实现的不同可能千差万别,这样在反序列化过程中可能会导致意外的 InvalidClassException。还强烈建议使用 private 修饰符显示声明 serialVersionUID(如果可能),原因是:serialVersionUID 字段不应该对子类起作用。数组类不能声明一个明确的 serialVersionUID,因此它们总是具有默认的计算值,但是数组类没有匹配 serialVersionUID 值的要求。
下面展开测试
有两个包,模拟A端和B端,分别有自己的Student实体类。测试在A端序列化,在B端反序列化。程序结构:
A包:
package A;
import java.io.File;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.ObjectOutputStream;
public class SerialA {
public static void main(String[] args) {
Student student = new Student(1, "song");
System.out.println("Object SeStudent" + student);
try {
File file = new File("D:\\home\\IO\\student.txt");
try {
file.createNewFile();
} catch (IOException e) {
e.printStackTrace();
}
FileOutputStream fos = new FileOutputStream(file);
ObjectOutputStream oos = new ObjectOutputStream(fos);
oos.writeObject(student);
oos.flush();
oos.close();
fos.close();
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}
package A;
import java.io.Serializable;
public class Student implements Serializable {
private static final long serialVersionUID = 6977402643848374753L;
int id;
String name;
public Student(int id, String name) {
this.id = id;
this.name = name;
}
public String toString() {
return "DATA: " + id + " " + name;
}
}
B包:
package B;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.io.ObjectInputStream;
public class SerialB {
public static void main(String[] args) {
Student student;
try {
File file = new File("D:\\home\\IO\\student.txt");
FileInputStream fis = new FileInputStream(file);
ObjectInputStream ois = new ObjectInputStream(fis);
student = (Student) ois.readObject();
ois.close();
fis.close();
System.out.println("Object DeStudent" + student);
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
}
}
package B;
import java.io.Serializable;
public class Student implements Serializable {
private static final long serialVersionUID = 6977402643848374753L;
int id;
String name;
public Student(int id, String name) {
this.id = id;
this.name = name;
}
public String toString() {
return "DATA: " + id + " " + name;
}
}
我们在A端序列化,B端反序列化,得到:

也就是利用不同包下的类,是不能完成反序列化的
修改测试程序结构如下,程序代码不变:
我们在A端序列化,B端反序列化,得到:

问题1:假设有A端和B端,如果2处的serialVersionUID不一致,会产生什么错误呢?
我们首先在A端进行序列化,然后在B端反序列化之前,将Student.java中的serialVersionUID改为:
private static final long serialVersionUID = 1L;,
得到:
java.io.InvalidClassException: model.Student; local class incompatible: stream classdesc serialVersionUID = 6977402643848374753, local class serialVersionUID = 1
at java.io.ObjectStreamClass.initNonProxy(Unknown Source)
at java.io.ObjectInputStream.readNonProxyDesc(Unknown Source)
at java.io.ObjectInputStream.readClassDesc(Unknown Source)
at java.io.ObjectInputStream.readOrdinaryObject(Unknown Source)
at java.io.ObjectInputStream.readObject0(Unknown Source)
at java.io.ObjectInputStream.readObject(Unknown Source)
at B.SerialB.main(SerialB.java:17)
问题2:假设2处serialVersionUID一致,如果A端增加一个字段,B端不变,(或者A端不变,B端减少一个字段)会是什么情况呢?
我们首先在A端进行序列化,然后在B端反序列化之前,将Student.java改为:

得到:
Object DeStudentDATA: 1
问题3:假设2处serialVersionUID一致,如果B段增加一个字段,A端不变,(或者A端减少一个字段,B端不变)会是什么情况呢?
我们首先在A端进行序列化,然后在B端反序列化之前,将Student.java改为:
得到:
Object DeStudentDATA: 1 song 0
7. 其他注意点
Serializable接口序列化属于深复制
反序列化还原后的对象地址与原来的的地址不同。即直接将对象序列化到输出流中,然后将其读回,这样产生的新对象是对现有对象的一个深拷贝或者深复制。但是注意:使用这种方式深复制虽然比较方便,但是他比显式的构建新对象并赋值数据域慢很多。
transient关键字
标记某些数据域是不可以序列化的。当某个字段被声明为transient后,默认序列化机制就会忽略该字段。transient关键字只能修饰变量,而不能修饰方法和类。注意,本地变量是不能被transient关键字修饰的。变量如果是用户自定义类变量,则该类需要实现Serializable接口。
静态变量不能序列化
序列化会忽略静态变量,即序列化不保存静态变量的状态。静态成员属于类级别的,所以不能序列化。即 序列化的是对象的状态不是类的状态。这里的不能序列化的意思,是序列化信息中不包含这个静态成员域。由于该值是JVM加载该类时分配的值,所以读取该对象时这个值依然存在。
当父类继承Serializable接口时,所有子类都可以被序列化;如果序列化的属性是对象,则这个对象也必须实现Serializable接口,否则会报错;当一个对象的实例变量引用其他对象,序列化该对象时,也把引用对象进行序列化;static,transient后的变量不能被序列化
二、实现序列化的其它方式
如果仅仅只是让某个类实现Serializable接口,而没有其它任何处理的话,就是使用默认序列化机制。使用默认机制,在序列化对象时,不仅会序列化当前对象本身,还会对该对象引用的其它对象也进行序列化,同样地,这些其它对象引用的另外对象也将被序列化,以此类推。所以,如果一个对象包含的成员变量是容器类对象,而这些容器所含有的元素也是容器类对象,那么这个序列化的过程就会较复杂,开销也较大,所以我们介绍两种比较快速的序列化方式。
代码
实体类:
import java.io.Serializable;
public class Student implements Serializable {
private String name;
private char sex;
private int year;
public Student() {}
public Student(String name, char sex, int year) {
this.name = name;
this.sex = sex;
this.year = year;
}
public void setName(String name) {
this.name = name;
}
public void setSex(char sex) {
this.sex = sex;
}
public void setYear(int year) {
this.year = year;
}
public String getName() {
return this.name;
}
public char getSex() {
return this.sex;
}
public int getYear() {
return this.year;
}
}
序列化类:
import com.alibaba.fastjson.JSON;
import com.dyuproject.protostuff.LinkedBuffer;
import com.dyuproject.protostuff.ProtobufIOUtil;
import com.dyuproject.protostuff.ProtostuffIOUtil;
import com.dyuproject.protostuff.runtime.RuntimeSchema;
import com.test.serializationTest.model.Student;
import java.io.*;
public class Test {
private Student st = new Student("Tom", 'M', 20);
public void testSerializable() {
ByteArrayOutputStream os = new ByteArrayOutputStream();
try {
//序列化
ObjectOutputStream oos = new ObjectOutputStream(os);
oos.writeObject(st);
oos.flush();
oos.close();//只是为了方便简洁的做个例子,真实编程要放到finally下
System.out.println("Serializable字节数:"+os.toByteArray().length);
System.out.println("Serializable字节流:"+os);
//反序列化
ObjectInputStream ois = new ObjectInputStream(new ByteArrayInputStream(os.toByteArray()));
Student st2 = (Student) ois.readObject();
System.out.println("Serializable反序列化:"+st2.getName()+st2.getSex()+st2.getYear());
ois.close();
} catch (ClassNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
public void testJSON() {
String json = JSON.toJSONString(st);
System.out.println("JSON字节数::"+json.getBytes().length);
System.out.println("JSON字符串:"+json);
Student st2 = JSON.parseObject(json,Student.class);
System.out.println("JSON反序列化:"+st2.getName()+st2.getSex()+st2.getYear());
}
public void testProtostuff() {
RuntimeSchema<Student> schema = RuntimeSchema.createFrom(Student.class);
//序列化
byte[] data = ProtobufIOUtil.toByteArray(st, schema, LinkedBuffer.allocate(LinkedBuffer.DEFAULT_BUFFER_SIZE));
System.out.println("Protostuff字节数::"+data.length);
System.out.println("Protostuff字节流:"+data);
//反序列化
Student st2 = schema.newMessage();
ProtostuffIOUtil.mergeFrom(data,st2, schema);
System.out.println("Protostuff反序列化:"+st2.getName()+st2.getSex()+st2.getYear());
}
测试类:
public class SerializationTestApplication {
public static void main(String[] args) {
Test test = new Test();
test.testSerializable();
test.testJSON();
test.testProtostuff();
}
}
输出:
Serializable字节数:114
Serializable字节流:�� sr (com.test.serializationTest.model.Student=;
S^��Y C sexI yearL namet Ljava/lang/String;xp M t Tom
Serializable反序列化:TomM20
JSON字节数::34
JSON字符串:{"name":"Tom","sex":"M","year":20}
JSON反序列化:TomM20
Protostuff字节数::9
Protostuff字节流:[B@2b9ed6da
Protostuff反序列化:TomM20
Java的序列化:
优点:使用方便,可序列化所有类,不需要提供第三方的类库。
缺点:速度慢,无法跨语言,字节数占用比较大(完全利用反射实现序列化和反序列化,并且保存了关于类的一些信息)。
Protostuff
Protostuff是一个开源的、基于Java语言的序列化库。Protostuff支持的序列化格式包括:json;xml;POJO(可以理解为只包括属性和对应的set/get方法的实体类)...。
典型应用见上面的代码。
原理
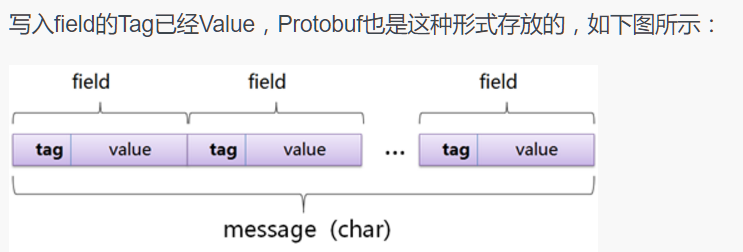
如上图所示,将对象中的属性和值按照tag和value的形式存储,其中tag表示的类似于属性编号(为了最小化空间),value表示的是属性的值,所以如果类中的属性顺序变化,会导致反序列化不正确。
优点:速度快;占用字节数很小(相比Java的序列化缩小10倍以上),适合网络传输节省io;跨语言 。
缺点:反序列化时需用户自己初始化序列化后的对象,Protostuff负责将该对象进行赋值;依赖于第三方jar类库;二进制格式导致可读性差;并且支持的格式比较少,比较有用的仅仅是POJO的序列化。
为什么Protostuff速度快
- Java序列化和反序列化是利用反射,不需要通过属性的get,set方法;而Protostuff通过反射解析类文件后,可以进行缓存,然后通过set和get方法进行序列化和反序列化(反序列化时只是赋值操作)。
- Java序列化时类型必须完全匹配(全路径类名+序列化id);Protostuff反序列化时并不要求类型匹配,比如包名、类名甚至是字段名,它仅仅需要序列化类型A 和反序列化类型B 的字段类型可转换(比如int可以转换为long),并且按照编号可以对应即可。
阿里巴巴的FastJson
Fastjson是一个Java语言编写的高性能的JSON处理器,由阿里巴巴公司开发。无依赖,不需要例外额外的jar,能够直接跑在JDK上。FastJson采用独创的算法,将parse的速度提升到极致,超过所有json库。
严格意义上JSON并不是序列化技术,它是将对象包装成JSON字符串传输,格式类似于键值对形式,{"name":"Tom","sex":"M","year":20},由于包含有多余的括号,引号,冒号等,序列化后包含34字节,但是相比于Java的序列化,占用字节数减小了三倍以上。
优点:明文结构一目了然,可以跨语言,属性的增加减少对解析端影响较小,支持类型比Protostuff多。
缺点:字节数较多,依赖于不同的第三方类库。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号