

正则表达式
可以接收大量的数据来源,然后借助通配符、元字符、关键字等来标识数据流中的信息,将匹配成功的数据留存下来。
基本正则表达式 和 扩展正则表达式 是两种不同的语法规范,主要区别在于元字符(如 +、?、|、 () 、{})是否需要转义(扩展不需要转义),以及支持的功能范围。
正则表达式 用来在文件中匹配符合条件的字符串,主要是目的是包含匹配。
grep、awk、sed 等命令可以支持正则表达式。
通配符 用来匹配符合条件的文件名,通配符是完全匹配。- ls、find、cp 之类命令不支持正则表达式,可以借助于shell通配符来进行匹配。
shell通配符:
.:匹配任意一个字符
*:匹配任意内容
?:匹配任意一个内容
[]:匹配中括号中的一个字符
字符匹配
单字符匹配
. 匹配任意单个字符,当然包括汉字的匹配
[] 匹配指定范围内的任意单个字符- 示例:[shuji]、[0-9]、[a-z]、[a-zA-Z]
[^] 匹配指定范围外的任意单个字符- 示例:[^shuji]
| 匹配管道符左侧或者右侧的内容
锚定字符
^ 行首锚定, 用于模式的最左侧
$ 行尾锚定,用于模式的最右侧
^PATTERN$ 用于模式匹配整行
^$ 空行
^[[:space:]]*$ 空白行
\< 词首锚定,用于单词模式的左侧
\> 词尾锚定,用于单词模式的右侧
\<PATTERN\> 匹配整个单词
分组符号
分组符合 ()
每一个匹配的内容都会在一个独立的()范围中
按照匹配的先后顺序,为每个()划分编号
第一个()里的内容,用 \1代替,第二个()里的内容,用\2代替,依次类推
\0 代表正则表达式匹配到的所有
源文件:
server.1=10.0.0.12:2182:2183
命令:
grep server.1 zoo.cfg | sed -r "s/(.*)=(.*):(.*):(.*)/\3/"
结果:
2182
限定符号
* 匹配前面的字符任意次,包括0次,贪婪模式:尽可能长的匹配
.* 任意长度的任意字符
? 匹配其前面的字符出现0次或1次,即:可有可无
+ 匹配其前面的字符出现最少1次,即:肯定有且 >=1次
{m} 匹配前面的字符m次
{m,n} 匹配前面的字符至少m次,至多n次
{,n} 匹配前面的字符至多n次,<=n
{n,} 匹配前面的字符至少n次
邮箱匹配
egrep "^[0-Z_]+\@[0-Z]+\.[0-Z]{2,5}$" testemail.txt
手机号匹配
egrep '\<1[3-9][0-9]{9}\>' phone.txt
文件查找与压缩
文件查找
locate
locate是Linux系统中用于快速查找文件和目录的一个非常实用的命令行工具。它主要通过搜索事先构建的文件数据库来定位文件。
--非实时查找 索引的构建是在系统较为空闲时自动进行(周期任务),执行updatedb可以更新数据库
--查找速度快 locate 查询系统上预建的文件索引数据库
/var/lib/mlocate/mlocate.db
--模糊查找 搜索的是文件全路径,不仅仅是文件名
--索引构建过程需要遍历整个根文件系统,很消耗资源
--可能只搜索用户具备读取和执行权限的目录
Ubuntu系统
apt install -y mlocate
Rocky系统
yum install -y plocate
命令格式:
locate 选项 文件
find
find是Linux系统中一个功能强大且灵活的命令行工具,用于在目录结构中搜索文件和目录。
--查找速度略慢
--精确查找
--实时查找
--查找条件丰富
--只搜索用户具备读取和执行权限的目录
命令格式:
find 路径 选项 表达式
-name 文件名
-iname 忽略大小写,文件名
-size 文件大小
-type 文件类型
不指定路径,表示当前路径。
-type 值
f #普通文件
d #目录文件
l #符号链接文件
s #套接字文件
b #块设备文件
c #字符设备文件
p #管道文
-size [+|-]N UNIT # N为数字,UNIT为常用单位 k, M, G, c(byte) 等
#解释
10k #表示(9k,10k],大于9k 且小于或等于10k
-10k #表示[0k,9k],大于等于0k 且小于或等于9k
+10k #表示(10k,∞),大于10k
以天为单位
-atime [+|-]N -mtime [+|-]N -ctime [+|-]N
以分钟为单位
-amin [+|-]N -mmin [+|-]N -cmin [+|-]N
#解释
N #表示[N,N+1),大于或等于N,小于N+1,表示第N天(分钟)
+N #表示[N+1,∞],大于或等于N+1,表示N+1天之前(包括) -N #表示[0,N),大于或等于0,小于N,表示N天(分钟)
-ls:以ls -dils的格式显示匹配的文件。
find -name "f*.txt" -ls 类似于 ls -l
-fls:查找结果保存至文件
find -name "f*.txt" -fls ls.log‘
-delete
find -name "*.sh" -delete
与xargs结合
find ./ -name "*.txt" | xargs -I {} rename 's/.txt$//' {}
文件查找
locate命令
locate命令是Linux系统中用于快速查找文件和目录的一个非常实用的命令行工具。它主要通过搜索事先构建的文件数据库来定位文件
命令格式:
locate 选项 表达式
updatedb 更新数据库
find命令
find命令是Unix/Linux系统中一个功能强大且灵活的命令行工具,用于在目录结构中搜索文件和目 录。它不仅能够根据文件名、类型、大小、修改时间等属性进行搜索,还可以对搜索结果执行各种操作,如删 除、移动、复制等。
命令格式
find 搜索路径 选项 表达式
搜索路径:指定find命令开始搜索的目录。可以是一个或多个路径。不指定路径,表示当前路径。
选项:用于定义搜索的条件,如文件名、文件类型、大小、时间等。
表达式:用于进一步细化搜索条件,可以与选项组合使用来构建复杂的搜索逻辑。
常用选项
-name:按文件名匹配,区分大小写。
-type:按文件类型搜索。
-size:按文件大小搜索。
-mtime:按天数查找文件最后修改时间。
-iname:忽略大小写。
-regex:正则表达。
类型查找
-type 选项
type值
f #普通文件
d #目录文件
l #符号链接文件
s #套接字文件
b #块设备文件
c #字符设备文件
p #管道文件
文件属性查找
-size [+|-]NUNIT # N为数字,UNIT为常用单位 k, M, G, c(byte) 等
#解释
10k #表示(9k,10k],大于9k 且小于或等于10k
+10k #表示[0k,9k],大于等于0k 且小于或等于9k
-10k #表示(10k,∞),大于10k
文件时间属性查找
以天为单位
-atime [+|-]N -mtime [+|-]N -ctime [+|-]N
以分钟为单位
-amin [+|-]N -mmin [+|-]N -cmin [+|-]N
#解释
N #表示[N,N+1),大于或等于N,小于N+1,表示第N天(分钟)
+N #表示[N+1,∞],大于或等于N+1,表示N+1天之前(包括) -N #表示[0,N),大于或等于0,小于N,表示N天(分钟)内
动作处理
对搜索结果执行各种操作。
-print:打印搜索结果(默认行为)。
-print0 :不换行输出,常用于配合xargs
-exec:对每个匹配的文件执行指定的命令。命令以{}代表当前文件,命令结尾以;或+结束。
-ls:以ls -dils的格式显示匹配的文件。
打包压缩
gz包
命令格式
gzip 选项 文件
gunzip 选项 文件
tar包
命令格式
tar 选项 文件
选项
-c #创建一个新归档
-d #找出归档和文件系统的差异
-r #追加文件至归档结尾
-t #列出归档内容
-x #从归档中解出文件
-z #通过 gzip 压缩或解压缩
-f #表示指定存档文件名
-v #列出文件详细信息
-C #改变输出目录
压缩
tar zcf
解压
tar xcf
查看压缩文件列表
tar tvf
zip包
解压
unzip
-d #输出目录
du -sh
查看目录大小
软件管理
软件相关概念
ABI
ABI(应用程序二进制接口)是一种定义了应用程序与操作系统或者硬件之间交互方式的接口标准,不同的操作系统,他的ABI接口是不一样的。每个种操作系统,都有对外的ABI接口,软件要想运行,就必须符合其接口规范才可以。它为开发人员提供了在不同平台上编写、编译和执行应用程序的一致性。
windows 中的是 PE格式
Linux 中的是 ELF格式
API
API (应用程序编程接口)可以在各种不同的操作系统上实现给应用程序提供完全相同的接口。
由于操作系统的不同,API又分为Windows API和Linux API。
在Windows平台开发出来的软件在Linux上无法运行,在Linux上开发的软件在Windows上又无法运行。
posix
为了方便软件开发人员在不同操作系统中的程序正常开发,要求操作系统应该提供通用功能的接口实现,而这就是POSIX。
程序编译
程序编译的目的主要是将人类可读的高级语言代码转换成硬件能够识别的二进制语言,即机器语言或目标代码。

软件链接
程序编译过程中的链接是编译过程的一个重要阶段,它主要负责将多个目标文件(通常是由编译和汇编阶段生成的)以及所需的库文件合并成一个可执行文件或库文件。
链接类型
静态链接:
在程序编译时,将程序中使用的所有库文件(包括标准库和用户自定义库)中的代码和数据都 "复制" 到最终的可执行文件中。
这种方式的优点是程序在运行时不需要额外的库文件支持,但缺点是生成的可执行文件体积较大,且如果库文件更新,需要重新编译整个程序。
动态链接:
在程序编译时,不将库文件中的代码和数据复制到可执行文件中,而是在程序运行时 "由操作系统动态加
载" 所需的库文件。
这种方式的优点是减少了可执行文件的大小,且库文件更新后不需要重新编译整个程序,但缺点是程序运
行时需要依赖外部库文件。
软件包管理
Linux系统中的软件包是Linux发行版用来组织、安装和管理软件的一种方式。它们通常以压缩包的形式存在,包含了软件的二进制文件、库文件、配置文件、文档等必要组件。
软件包分类
源码包:
包含软件的源代码文件、编译指令和配置文件。
需要用户自行编译安装,过程相对复杂,但灵活性高,可以定制安装选项。
文件格式通常为.tar.gz、.tar.bz2等压缩格式。
注意:软件运行所有的文件都会在同一个包文件里面
二进制包:
包含已经编译好的可执行文件、库文件、配置文件、帮助文件等,用户可以直接安装使用。
常见的二进制包格式有RPM包、DEB包等。
注意:软件运行所有的文件分别放到相互依赖的多个包文件里面。
RPM包:
主要在Red Hat、Fedora、CentOS等Linux发行版中使用。
可以通过rpm命令进行安装、卸载、查询等操作。
DEB包:
主要在Debian、Ubuntu等Linux发行版中使用。
使用dpkg命令进行安装、卸载等操作,但apt命令更为常用,因为它能自动处理依赖关系。
包管理工具
apt(Debian/Ubuntu):
用于Debian及其衍生版如Ubuntu中的软件包管理,能够自动处理依赖关系,并提供丰富的软件包仓库。
yum/dnf(CentOS/RHEL):
CentOS和Red Hat Enterprise Linux(RHEL)等发行版中的软件包管理工具,同样支持自动处理
依赖关系和软件包的搜索、安装、升级等操作。
包命名
源码包命名格式
命名规则:
name-VERSION.tar.gz|bz2|xz
命名示例:
nginx-1.25.4.tar.gz
------
nginx 基础文件名:反映软件包名称或项目名称。
1.25.4 样式:主版本号.次版本号.修正版本号
tar.gz 扩展名:.tar表示tar归档,.gz或.bz2表示压缩格式。
二进制包命名
命名示例:
httpd-2.4.57-15.el9.x86_64.rpm:
------
httpd 软件包名。
2.4.57 包的版本号,格式为“主版本号.次版本号.修正号”。
15 二进制包发布的次数,表示这是第几次编译生成的。
el9 软件发行商,表示此包是由Red Hat公司发布
x86_64 表示此包使用的硬件平台。
rpm:RPM 包的扩展名,表明这是编译好的二进制包,可以直接使用rpm命令安装。
获取软件包
获取软件源码包的地址:
软件官网、github、第三方软件镜像站
获取软件包二进制的地址
cdrom、软件官网、github、第三方软件镜像站、自己制作
包管理器rpm
安装
命令格式
rpm {-i|--install} [install-options] PACKAGE_FILE
常用选项
-ivh # 安装软件
-evh # 卸载软件
-q # 检查安装软件
安装:
rpm -ivh vsftpd-3.0.3-49.el9.x86_64.rpm
卸载:
rpm -evh vsftpd
包查询
命令格式:
rpm {-q|--query} [select-options] [query-options]
常用选项
-i #查询包详细信息
-l #查看指定的程序包安装后生成的所有文件
-f #查看指定的文件由哪个程序包安装生成
查询包详细信息:
rpm -qi tree
列出包内所有文件:
rpm -ql tree
根据文件查询包信息:
rpm -qf /bin/tree
yum和dnf
简介
yum 和 dnf 都是 Linux 系统中用于软件包管理的工具[python脚本],它们允许用户安装、更新、
删除和查询软件包。尽管它们在功能上非常相似,但它们属于不同的软件包管理系统,并且在技术实现和背后
的设计上存在一些差异。
YUM 最初是为基于 RPM 的 Linux 发行版(如 Fedora、CentOS、RHEL 等)设计的。它起源于
Yellowdog Linux 发行版,后来经过修改和扩展,成为许多主流 Linux 发行版中不可或缺的一部分。
DNF 是 Fedora 项目开发的一个新的包管理器,旨在作为 YUM 的继任者。它最初是作为 YUM 的一个分支项目出现的,但随着时间的推移,它逐渐发展成为了一个独立且更加先进的软件包管理工具。
工作原理
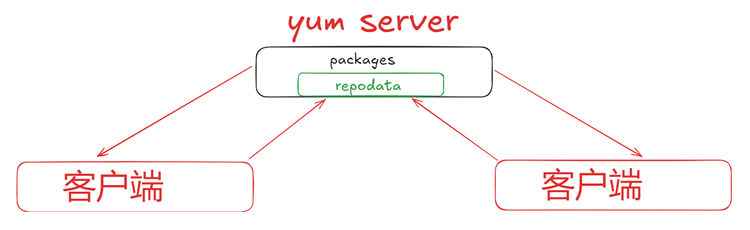
架构模式
yum/dnf 是基于C/S 模式
yum 服务器存放rpm包和相关包的元数据库
yum 客户端访问yum服务器进行安装或查询等
yum实现过程
先在yum服务器上创建 yum repository(仓库),在仓库中事先存储了众多rpm包,以及包的相关的
元数据文件(放置于特定目录repodata下),当yum客户端利用yum/dnf工具进行安装包时,会自动下载
repodata中的元数据,查询元数据是否存在相关的包及依赖关系,自动从仓库中找到相关包下载并安装。
环境配置
yum客户端配置文件
/etc/yum.conf #为所有仓库提供公共配置
/etc/yum.repos.d/*.repo #为每个仓库的提供配置文件
基础命令
获取软件源信息
yum makecache
清理软件源信息
yum clean all
查看源
yum repolist
查看源信息
yum repolist -v
全局配置
[仓库标识 id]
name=仓库名字 #仓库名称
baseurl=仓库的url地址 #仓库地址
gpgcheck={1|0} #是否对包进行校验,默认值为1
enabled={1|0} #是否启用,默认值为1
gpgkey={URL} #校验key的地址
定制软件源--阿里源
[aliyun-baseos]
name=aliyun baseos
baseurl=https://mirrors.aliyun.com/rockylinux/9.4/BaseOS/x86_64/os/
gpgcheck=0
定制光盘源
挂载本地光盘到目录
[root@rocky9 ~]# mount /dev/cdrom /mnt/
[root@rocky9 ~]# ls /mnt/
AppStream BaseOS EFI images isolinux LICENSE media.repo
定制专属的本地镜像源信息
------
[root@rocky9 yum.repos.d]# cat cdrom.repo
[cdrom-appstream]
name=cdrom appstream
baseurl=file:///mnt/AppStream/
gpgcheck=0
[cdrom-baseos]
name=cdrom baseos
baseurl=file:///mnt/BaseOS/
gpgcheck=0
BaseOS目录
内容:存储着操作系统的核心组件和基本系统工具,如内核、shell工具、系统服务等。
功能:提供操作系统的基本功能和支持,确保系统的正常运行。
AppStream目录
内容:存储着用户可能需要的应用程序和软件包的元数据信息,以及软件包依赖关系等。
功能:使用户可以方便地安装和管理这些软件,通常包含用户界面软件、开发工具、数据库工具等
应用程序。
关联关系:
BaseOS和AppStream两个目录之间的关系是互补的。
在安装和管理软件时,系统会从这两个目录中获取所需的软件包和依赖关系,以确保系统的完整性
和稳定性。
yum命令
命令格式:
yum 选项 命令
常见子命令
autoremove #卸载包,同时卸载依赖
clean #清除本地缓存
install #包安装
list #列出所有包
makecache #重建缓存
search #包搜索,包括包名和描述
update #更新
默认显示所有 enable 的 repo
yum repolist
查看所有软件
yum list
安装软件
yum install [options] PACKAGE [...]
删除软件
yum remove [options] PACKAGE [...]
更新软件
yum update [options] PACKAGE [...]
软件组管理
yum grouplist [options] #列出所有包组
yum groupinstall [options] group1 [...] #包组安装
yum groupupdate [options] group1 [...] #包组升级
yum groupremove [options] group1 [...] #包组卸载
yum groupinfo [options] group1 [...] #包组查询
groupinstall 之后,如果发现内核版本发生了改变,最好执行一下 update一下,以免出现系统软
件版本兼容性问题,导致登录界面崩溃。
Ubuntu 软件管理
Debian 软件包通常为预编译的二进制格式的扩展名“.deb”,类似 rpm 文件,因此安装快速,无需编 译软件。包文件包括特定功能或软件所必需的文件、元数据和指令。
dpkg:
package manager for Debian,类似于rpm, dpkg是基于Debian的系统的包管理器。可以安装,删除和构建软件包,但无法自动下载和安装软件包或其依赖项。
apt:
Advanced Packaging Tool,功能强大的软件管理工具,甚至可升级整个Ubuntu的系统,基于客户/服务器架构(c/s)
配置文件
deb URL section1 section2
#字段说明
deb #固定开头,表示是二进制包的仓库,如果deb-src开头,表示是源码库
URL #库所在的地址,可以是网络地址,也可以是本地镜像地址
section1
#Ubuntu版本的代号,可用 lsb_release -sc 命令查看,也可以用 cat /etc/os-release
section2
#软件分类,main完全自由软件 restricted不完全自由的软件,universe社区支持的软件multiverse非自由软件
section1 #主仓
section1-backports #后备仓
section1-security #修复仓
section1-updates #非安全性更新仓
section1-proposed #预更新仓
定制源文件
root@ubuntu24:~# vim /etc/apt/sources.list
# 定制阿里云镜像仓库
deb https://mirrors.aliyun.com/ubuntu/ noble main restricted universe multiverse
deb https://mirrors.aliyun.com/ubuntu/ noble-security main restricted universe
multiverse
deb https://mirrors.aliyun.com/ubuntu/ noble-updates main restricted universe
multiverse
deb https://mirrors.aliyun.com/ubuntu/ noble-backports main restricted universe
multiverse
# 定制清华源镜像仓库
deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ noble main restricted universe
multiverse
deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ noble-updates main restricted
universe multiverse
deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ noble-backports main restricted
universe multiverse
dpkg 包管理器
命令格式:
dpkg [<option> ...] <command>
常用选项:
-i #安装软件
-r #卸载软件
-v #检查包是否安装
-s #显示已安装包详细的信息
-L #列出包内所有文件
-S #根据文件查询包信息
apt 命令
命令格式
apt [options] command
一般选项
list #根据名称列出软件包
search #搜索软件包描述
show|info #显示软件包细节
install #安装软件包
purge #移除软件包及配置文件
update #更新可用软件包列表,只更新索引文件
upgrade #通过 安装/升级 软件来更新系统
彻底卸载并清理某软件的完整流程:
apt purge <软件名>
apt autoremove
软件源更新 APT与YUM
| ubuntu | rocky | |
|---|---|---|
| 获取软件源 | apt update | yum makecache |
| 清理软件源缓存 | yum clean | |
| 更新软件 | apt upgdate | yum update |
软件本地安装 dpkg与rpm
| ubuntu | rocky | |
|---|---|---|
| 安装软件 | dpkg -i | rpm -i |
| 删除软件 | dpkg -r | rpm -e |
| 查看软件 | dpkg -l | rpm -q |
| 软件信息 | dpkg -s | rpm -qi |
| 软件文件列表 | dpkg -L | rpm -ql |
| 反查文件 | dpkg -S | rpm -qf |
源码包部署
虽然有很多开源软件将软件打成包,供人们使用,但并不是所有源代码都打成包,如果想使用开源软件, 可能需要自已下载源码,进行编译安装。另外即使提供了包,但是生产中需要用于软件的某些特性,仍然需要 自行编译安装。
1 部署make编译环境
2 获取项目源代码文件
3 解压软件包
4 编译安装软件
- configure定制配置
-> make编译生成配置文件
-> make install转移文件到安装目录
5 将可执行文件路径加入PATH环境变量
6 测试效果
系统默认启动模式设置为 多用户文本模式
systemctl set-default multi-user.target
文件系统
文件系统是操作系统用于明确存储设备或分区上的文件的方法和数据结构;即在存储设备上组织文件的方法。
操作系统中负责管理和存储文件信息的软件结构称为文件管理系统,简称文件系统
内核中的模块:ext4, xfs, vfat
Linux的虚拟文件系统:VFS
用户空间的管理工具:mkfs.ext4, mkfs.xfs,mkfs.vfat
查看磁盘使用的文件系统类型
lsblk -f
lsblk -f /dev/sdb
常见的文件系统类型
Linux:
ext4 #ext 文件系统的最新版。
xfs #SGI 支持最大8EB的文件系统
swap #交换分区专用的文件系统
iso9660 #光盘文件系统
Windows:
FAT32 #最多只能支持16TB的文件系统和4GB的文件
NTFS #最多只能支持16EB的文件系统和16EB的文件
mkfs命令*
命令格式
mkfs [options] [-t <type>] [fs-options] <device> [<size>]
mkfs.ext4
将 /dev/sdb 磁盘格式化为 ext4 文件系统
mkfs.ext4 /dev/sdb
磁盘存储
设备文件
字符设备文件:
--字符设备文件是一种按字节流进行操作的设备,如串口、键盘、鼠标等。它们提供的是一种基于字符的输入输出接口,可以使用标准的文件操作函数(如read、write、open和close)对其进行操作。
块设备文件:
--块设备文件是一种按块进行操作的设备,如硬盘、U盘等。它们提供的是一种基于块的输入输出接口,通常使用特定的块设备操作函数(如request_queue、submit_bio等)进行操作。
网络设备文件:
--网络设备文件是一种用于网络通信的设备,如网卡等。它们提供的是一种基于数据包的输入输出接口,可以使用特定的网络操作函数(如sendmsg、recvmsg等)进行操作。
硬盘接口
IDE:133MB/s,并行接口,早期家用电脑
SCSI:640MB/s,并行接口,早期服务器,并行接口因为相互影响,所以可能会因为某个接口慢,导致整体
慢。
SATA:6Gbps,SATA数据端口与电源端口是分开的,即需要两条线,一条数据线,一条电源线
SAS:6Gbps,SAS是一整条线,数据端口与电源端口是一体化的,SAS中是包含供电线的,而 SATA中不包
含供电线。SATA标准其实是SAS标准的一个子集,二者可兼容,SATA硬盘可以插入SAS主板上,反之不行
USB:480MB/s
M.2
常见硬盘
硬盘(HDD)
传统的硬盘类型,采用磁性存储技术,通过盘片的旋转和磁头的移动来读写数据。
存储容量大、价格相对较低,但读写速度相对较慢,且存在机械结构,易受震动影响。
固态硬盘(SSD)
采用闪存芯片作为存储介质的新型硬盘,没有机械结构,因此读写速度极快,抗震性能优越。
价格相对较高,但随着技术进步逐渐亲民;存储容量虽然有限,但已能满足大多数应用需求;适用于需要高读写速度和稳定性的场景。
MBR & ZBR
在计算机存储领域,MBR和ZBR分别代表了不同的硬盘分区方法和存储优化技术。MBR主要应用于硬盘的引 导记录和分区管理,而ZBR则是一种优化硬盘存储空间的方法。
MBR(Master Boot Record, MBR)的作用至关重要,硬盘的第一个扇区(0道0头1扇区),包含硬盘的主引导程序和分区表。它是计算机启动的关键,包含了引导代码,能够加载操作系统,并告诉计算机硬盘上的分区信息。
ZBR(Zoned Bit Recording),即区位记录,是一种物理优化硬盘存储空间的方法。与传统的硬盘存储方式相比,ZBR不再采用每个磁道扇区数固定的方式,而是根据磁道半径的不同,将更多的扇区放到磁盘的外部磁道,以获取更多的存储空间。这种设计使得外部磁道的数据传输速度要快于内部磁道,因为单位时间内扫过的扇区数在外部磁道更多。
常见命令
文件系统查看工具 df
命令格式:
df [OPTION]... [FILE]...
df 查看文件系统相关信息
df -Th
文件系统目录信息统计工具 du
命令格式:
du [OPTION]... [FILE]...
du [OPTION]... --files0-from=F
查看指定目录空间大小信息
du -sh /etc
文件系统文件定制工具 dd
命令格式:
dd [OPERAND]...
dd OPTION
常用格式
dd if=/PATH/FROM/SRC of=/PATH/TO/DEST bs=N count=N
测试硬盘写速度
dd if=/dev/zero of=/tmp/1Gb.file bs=1024 count=1000000
查看磁盘起始扇区原始数据
hexdump -vC -n 512 /dev/sda
lsblk 显示设备和分区的基本信息
命令格式:
lsblk [options] [<device> ...]
常用选项
-l|--list #以列表显示
fdisk 操作管理分区
命令格式:
fdisk [options] -l [<disk>]
-l #显示
fdisk 分区管理
fdisk -l /dev/sda 查看分区信息

创建分区
命令(输入 m 获取帮助):n # 输入n 创建新分区
分区类型
p 主分区 (0 primary, 0 extended, 4 free)
e 扩展分区 (逻辑分区容器)
选择 (默认 p): # 按Enter 创建主分区
分区号 (1-4, 默认 1): # 按Enter 创建编号1的主分区
第一个扇区 (2048-419430399, 默认 2048): # 按Enter 使用默认空间起始点
最后一个扇区,+/-sectors 或 +size{K,M,G,T,P} (2048-419430399, 默认 419430399): +10G
# 使用 +/-sectors 或 +size{K,M,G,T,P} 来设定分区空间大小
命令(输入 m 获取帮助):w # 输入 w 保存分区
非交互式创建分区-echo
echo -e 'n\np\n\n\n+10G\nw' | fdisk /dev/sdb
挂载信息
临时挂载
mount 设备 挂载点
取消挂载
umount 设备 挂载点
永久挂载:vim /etc/fstab
#UUID="c8dd6954-1b4b-4f9f-a187-a9a27452be84" /mount/xfs xfs defaults 0 0
设备路径|uuid UUID="c8dd6954-1b4b-4f9f-a187-a9a27452be84"
挂载点 /mount/xfs
文件系统类型 xfs
挂载属性 defaults
磁盘的使用逻辑
获取 - 分区 - 格式化 - 挂载
RAID
RAID的工作原理是在多个磁盘上分配数据,并以标准化方式促进输入/输出操作的重叠。通过将数据分布在多个磁盘上,RAID技术可以实现数据冗余,提高容错能力,并在多个磁盘上并行读写数据,从而提升数据传输速度和存储性能。
简单来说,RAID把多个硬盘组合成为一个逻辑硬盘,因此,操作系统只会把它当作一个实体硬盘。
RAID分类
RAID-0
以 chunk 单位,读写数据,因为读写时都可以并行处理,所以在所有的级别中,RAID 0的速度是最快
的。但是RAID 0既没有冗余功能,也不具备容错能力,如果一个磁盘(物理)损坏,所有数据都会丢失.
RAID-1
也称为镜像(Mirroring),它将数据同时写入两个磁盘,实现数据的完全冗余。RAID 1提供了最高的数据安全性,在一些多线程操作系统中能有很好的读取速度,理论上读取速度等于硬盘数量的倍数,但磁盘利用率只有50%,且写入速度相对较慢。它适用于保存关键性重要数据的场合。
RAID-5
也称为分布式奇偶校验(Distributed Parity),它将数据和奇偶校验信息分散在多个磁盘上。RAID 5可以容错一个磁盘的故障,同时提供较高的读写速度和磁盘利用率。它是目前综合性能最佳的数据保护解决方案之一,广泛应用于数据中心等场景。
RAID-6
与RAID 5类似,但提供了更强的容错能力,可以容错两个磁盘的故障。然而,RAID 6需要更多的磁盘空间,成本更高,且写入性能相对较差。它主要用于对数据安全等级要求非常高的场合。
RAID-10
RAID-10也被称为RAID 1+0,是RAID 1与RAID 0的结合体。它首先创建多个RAID 1镜像对,然后将这些镜像对组合成一个RAID 0阵列。这种结构既提供了RAID 0的高性能,又具备了RAID 1的数据冗余和容错能力。
由于采用了RAID 0的条带化技术,RAID-10能够并行读写多个磁盘,从而显著提高数据传输速度。
LVM
LVM 即逻辑卷管理器,是Linux系统下对磁盘分区进行管理的一种机 制。LVM在硬盘分区和文件系统之间添加了一个逻辑层,为文件系统屏蔽了下层的磁盘分区布局,提供了一个抽 象的卷组,用户可以在这个卷组上创建文件系统。
物理存储介质:
指系统的存储设备,如硬盘,是存储系统的最低层存储单元。
------
PV(物理卷):
是LVM存储管理的最底层,可以是整个物理硬盘或实际物理硬盘上的分区。
物理卷在加入LVM之前需要经过特殊处理,以便LVM能够识别和管理。
VG(卷组):
是建立在物理卷之上的一个逻辑层,它包含了一个或多个物理卷。
卷组将多个物理卷组合在一起,形成一个可管理的单元,类似于非LVM系统中的物理硬盘。
LV(逻辑卷):
是建立在卷组之上的一个逻辑层,它类似于非LVM系统中的硬盘分区。
逻辑卷可以在其上建立文件系统,并挂载到不同的挂载点,用于存储数据。
------
PE(物理区域):
是物理卷中可用于分配的最小存储单元。PE的大小是可配置的,默认为4MB。
在建立卷组时,物理区域的大小会被指定,并且一旦确定就不能更改。
同一卷组中的所有物理卷的物理区域大小必须一致。
LE(逻辑区域):
是逻辑卷中可用于分配的最小存储单元。
逻辑区域的大小取决于逻辑卷所在卷组中的物理区域的大小,即一个LE对应一个PE。

PE与PV的关系:
PE是物理卷(PV)中可用于分配的最小存储单元。
每个物理卷都会被划分为多个PE,这些PE是LVM进行存储分配的基本单位。
------
LE与LV的关系:
LE是逻辑卷(LV)中可用于分配的最小存储单元。
每个逻辑卷都会被划分为多个LE,这些LE与卷组中的PE一一对应。
------
VG与PV的关系:
卷组(VG)建立在物理卷(PV)之上,一个卷组可以包含多个物理卷。
物理卷在加入卷组之前需要被初始化为LVM物理卷。
------
LV与VG的关系:
逻辑卷(LV)建立在卷组(VG)之上,卷组中的未分配空间可以用于创建新的逻辑卷。
逻辑卷在创建后可以动态地扩展和缩小空间,以适应不同的存储需求。
环境部署
Rocky系统
yum install -y lvm2
Ubuntu系统
apt install -y lvm2
基础知识
物理卷信息查看命令:
pvs #简要pv信息显示
pvdisplay #显示详细信息
创建PV命令:
pvcreate /dev/DEVICE #创建物理卷
删除PV命令
pvremove /dev/DEVICE
------
卷组信息查看命令:
vgs #简要vg信息显示
vgdisplay #显示详细信息
创建VG命令:
vgcreate [-s Size ] vgname pv1 [pv2...] # 创建VG
# -s 指定PE大小,数字加单位,单位为 k|K|m|M|g|G|t|T|p|P|e|E
删除卷组命令
vgremove vgname #删除vg之前,要先把对应的 pv 解除绑定 (pvmove)
------
逻辑卷信息查看命令
lvs #简要lv信息显示
Lvdisplay #显示详细信息
lvscan #查看lv的具体名称路径
创建LV命令:
lvcreate {-L N[mMgGtT]|-l N} -n NAME VolumeGroup
选项参数:
-L|--size N[mMgGtT] #指定大小
-l|--extents N #指定PE个数,也可用百分比
-n Name #逻辑卷名称
删除lv命令
lvremove /dev/VG_NAME/LV_NAME
创建LVM流程
- pvcreate → 初始化物理设备为 PV
- vgcreate → 将 PV 组合为 VG
- lvcreate → 从 VG 划分空间创建 LV
- mkfs.xxx → 格式化 LV
- mount → 挂载使用(并配置永久挂载)
将两个物理磁盘分区,创建两个pv
pvcreate /dev/sdb1 /dev/sdc1
检测当前的pv信息
pvs
查看/dev/sdb1的信息
pvdisplay /dev/sdb1
将两个物理卷,创建一个vg
vgcreate -s 16M testvg /dev/sdb1 /dev/sdc1
检测当前的vg信息
vgs
查看testvg的详情信息
vgdisplay testvg
从 testvg 中创建lv1,大小为 100个PE
lvcreate -l 100 -n lv1 testvg
检测当前的vg信息
lvs
查看testvg的详情信息
lvdisplay /dev/testvg/lv1
格式化lv
mkfs.ext4 /dev/testvg/lv1
挂载lv环境
mount /dev/testvg/lv1 /mount/lvm/
扩展逻辑卷
要先保证卷组上还有空间
扩展方式1:
先扩展逻辑卷
lvextend -L [+]N[mMgGtT] /dev/VG_NAME/LV_NAME
再扩容文件系统
resize2fs /dev/VG_NAME/LV_NAME
xfs_growfs MOUNTPOINT
同步文件系统
针对ext:resize2fs /dev/VG_NAME/LV_NAME
针对xfs:xfs_growfs MOUNTPOINT
扩展方式2: 一步实现容量和文件系统的扩展
lvresize -r -l +100%FREE /dev/VG_NAME/LV_NAME
缩减逻辑卷
缩减逻辑卷:
缩减有数据损坏的风险,建议先备份再缩减,不支持在线缩减,要先取消挂载,xfs文件系统不支持缩减
1 取消挂载
umount /dev/VG_NAME/LV_NAME
2 文件系统检测,e2fsck可写成fsck
e2fsck -f /dev/VG_NAME/LV_NAME
3 缩减文件系统到指定大小
resize2fs /dev/VG_NAME/LV_NAME N[mMgGtT]
4 缩减逻辑卷
lvreduce -L [-] N[mMgGtT] /dev/VG_NAME/LV_NAME
5 重新挂载
mount /dev/VG_NAME/LV_NAME mountpoint
注意:
3+4 可以简写为 lvreduce -L N[mMgGtT] -r /dev/VG_NAME/LV_NAME
lvm资源删除
卸载逻辑卷:使用umount命令卸载逻辑
umount /mount/lvm
删除逻辑卷:使用lvremove命令删除逻辑卷。
lvremove /dev/testvg/lv1
删除卷组:使用vgremove命令删除卷组
vgremove testvg
删除物理卷:使用pvremove命令删除物理卷。
pvremove /dev/sdb1 /dev/sdc1 /dev/sdd1

 浙公网安备 33010602011771号
浙公网安备 33010602011771号