利用爬虫技术爬取“火星引力”的小说“天辰”
一、前沿
首先推荐一个好看的网络小说网站:武侠world,又可以学英语,又可以看小说,还可以治疗各种上瘾症(无法治疗小说瘾),非常不错。
这段时间真是小说荒,好看的网络小说本来就少,而且更新得实在是太慢,于是想到把之前得小说再翻出来看看。虽然,网上免费的小说网站不少,但广告实在是太多,于是想自己把小说下载下来,方便又无广告,总之就是绿色无污染,还可以练习一下爬虫技术。这里选择爬取“火星引力”的小说“天辰”,推荐大家阅读“火星引力”的小说。
一、爬虫思路
首先,在利用国内最大的爬虫之百度,找到想要爬去的网站,主要是测试一下网站的访问速度,再确定是否为选择目标。这次选择的目标就是笔趣阁
选择目标后,接着就是分析网站,看看网站爬去的难度,再根据难度选择爬去目标的工具。
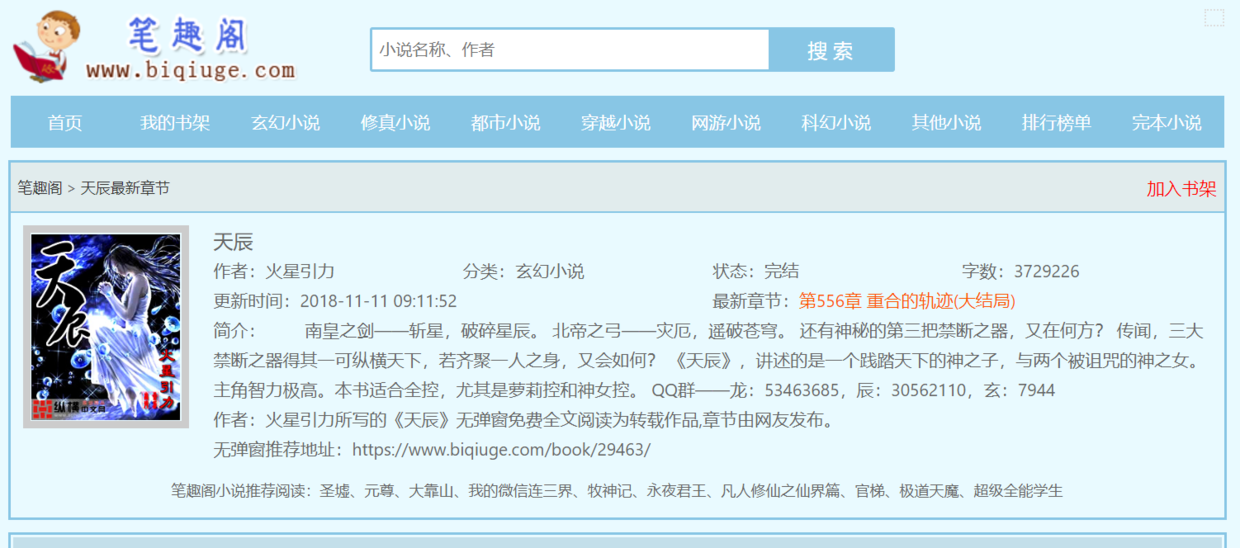
经过分析,该网站的请求方式为GET,连续点击“下一章”,发现没有采用AJAX等技术,URL规则也比较简单,确定初始URL及最终URL后就可以爬取所有的章节了,总之,爬取不会有什么难度,先选择单线程的方式实现。
最后,具体的实现过程,先考虑爬取一章的内容,再保存在本地txt文件中,接着进行格式的调整,让文章格式看起来更舒服,用户体验感更好,最后再扩展到爬取所有的章节,保存所有的章节。这些都完成后,还可以考虑采取多线程、进程、协程等方式提高爬取的效率,当然这是后话。
三、具体实现过程
开始撸代码
import requests
from fake_useragent import UserAgent
import random
from lxml import etree
import time
def parse_page(url,offset):
headers = {
'Cookie': 'fikker-tShm-4UR5=LUtS2wHKlLdAbGv9tKnSBCJKZGZWP3pA; fikker-tShm-4UR5=LUtS2wHKlLdAbGv9tKnSBCJKZGZWP3pA; UM_distinctid=16a5797e00ca7-02a4dfb07b62ea-3b65470f-e1000-16a5797e00e1b4; CNZZDATA1273376891=1130256466-1556246740-https%253A%252F%252Fwww.baidu.com%252F%7C1556246740; bcolor=; font=; fontcolor=; width=; size=12pt',
'Host': 'www.biqiuge.com',
'Referer': 'https://www.biqiuge.com/book/29463/1823{0}.html'.format(offset-1),
'User-Agent': random.choice([UserAgent().chrome, UserAgent().firefox, UserAgent().ie])
}
resp = requests.get(url,headers=headers)
#判断请求是否成功
if resp.status_code == 200:
fp = open('tiancheng.txt','a',encoding='utf-8')
#设置网站的编码方式
resp.encoding = resp.apparent_encoding
tree = etree.HTML(resp.text)
#获取标题
title = tree.xpath('//div[@class="content"]/h1/text()')[0]
#获取小说内容
contents = tree.xpath('//div[@id="content"]//text()')
print('正在保存“天辰”:{0}'.format(title))
#多方尝试,还是这种一行行的保存格式更好看
fp.write(title + '\n')
for content in contents[:-3]:
content = ''.join(content).strip()
fp.write('\n' + content)
fp.write(100 * '=' + '\n')
fp.close()
else:
print("请求页面出错:{0}".format(resp.status_code))
def main():
for offset in range(3971,4536):
url = 'https://www.biqiuge.com/book/29463/1823{0}.html'.format(offset)
parse_page(url,offset)
#限制一下爬取的速度
time.sleep(1)
print("下载完毕")
if __name__ == '__main__':
main()
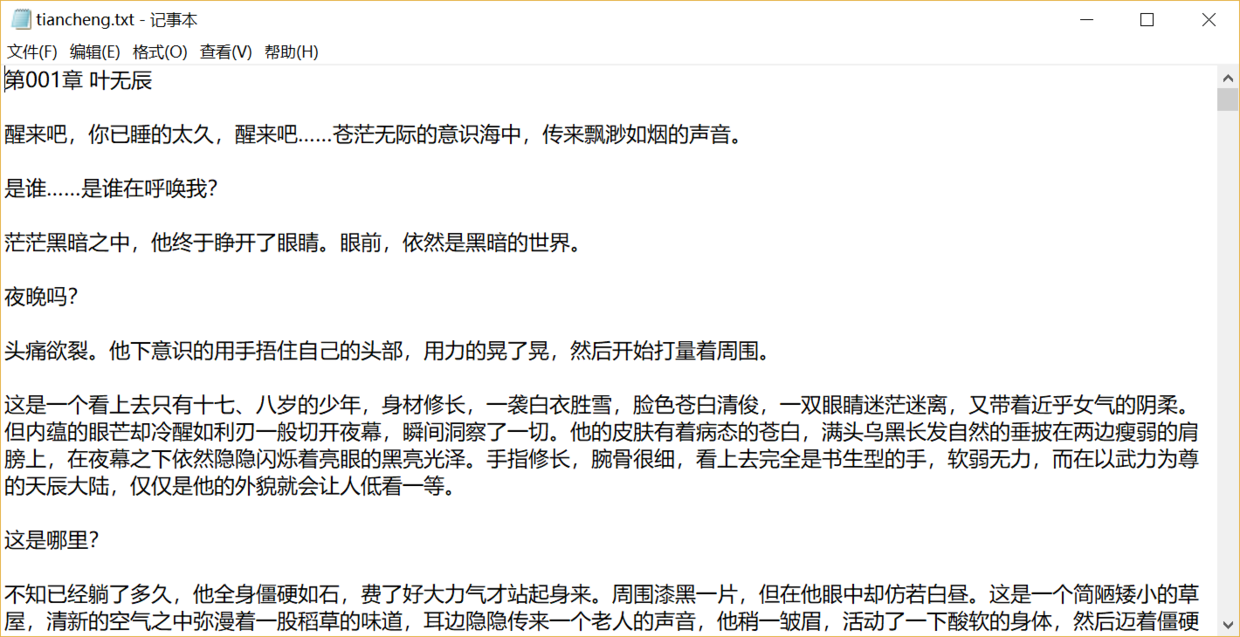
四、展示成果

五、分析小说内容
from matplotlib.pylab import plt
from wordcloud import WordCloud
import jieba
import re
string = []
text = 'tiancheng.txt'#文件名称
fp = open(text,'r',encoding='utf-8')#打开文件
cut = jieba.cut(fp.read())#读取小说
strings = ' '.join(cut)#切割内容转换成字符串
string_data = re.sub(r'【|】|=|“|”|《|》|%|\d+|—','', strings)#将字符串中的特殊字符替换位空字符
string.append(string_data)
font = 'C:\Windows\Fonts\msyh.ttc'#微软黑体字体安装路径
wc = WordCloud(font_path=font,
background_color='white',
width=1000,
height=800)
wc.generate_from_text("".join(string))#生成词云
wc.to_file('tiancheng.png')#保存图片
plt.imshow(wc)#用plt显示图片
plt.axis('off')#不显示坐标轴
plt.show()#显示图片
fp.close()#关闭文件

最后,不用看也知道主角是谁了吧。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号