利用selenium爬取妹子图
一、妹子图爬取前分析
1、首先要知道爬取网站的url,这里妹子图的url就是它https://www.mzitu.com/
2、接着我们分析妹子图的请求方式,看看它以什么方式渲染。这里妹子图只是利用了传统的网页(没有使用Ajax或js)。
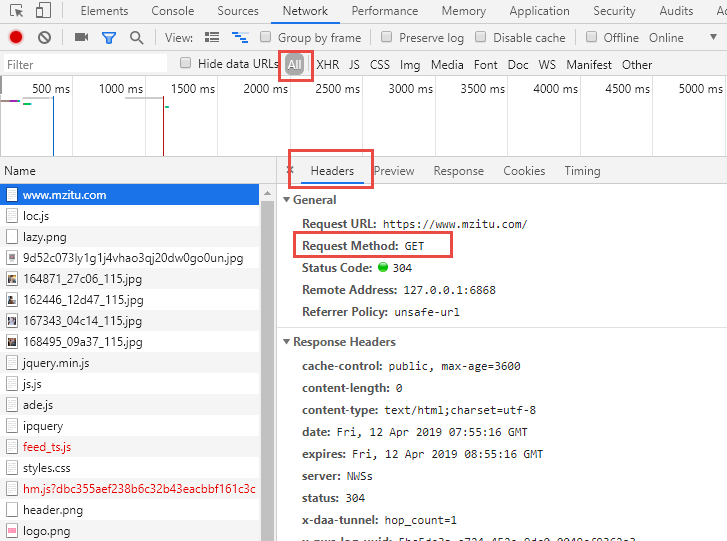
3、接着点击进入页面,连续点击下一页,发现url存在一定规律,如图,url最后4会变成5、6、7
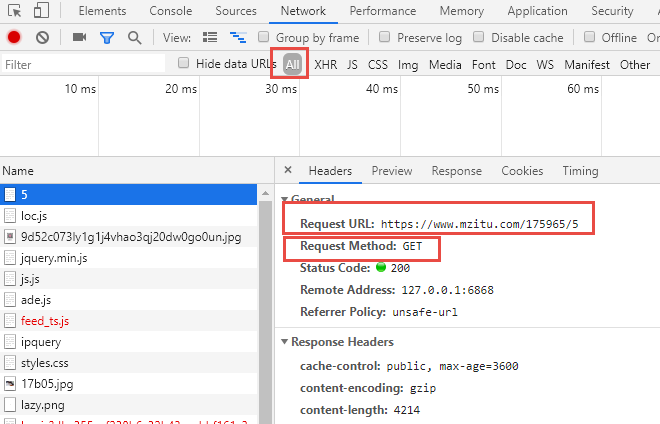
4、再查看具体页面的请求方式,这里使用的是GET方法,没有什么特别的。
二、妹子图爬取代码布局
1、大体了解妹子图使用的技术后,我们就可以开始尝试爬取妹子图了,首先我们爬取首页面所有的”妹子“url
2、接着再进入特定的”妹子“页面,再进行具体的”妹子图片“爬取,获取到图片的地址信息
3、最后再将获得的图片地址下载保存在本地即可
注意:妹子图具有简单的反爬虫设置,我们需要设置好请求头,否则下载下来的图片为空。
三、技术使用
很久没有使用selenium,这里我就决定使用它,其他技术都可以,不过,由于妹子图有反爬虫设置,这里需要引入requests包。
四、代码实现
from selenium import webdriver
from lxml import etree
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
import requests
#创建MeiZiTuSpaider类
class MeiZiTuSpaider(object):
#chrome浏览器驱动地址
driver_path = r'D:\python爬虫相关软件\chromedriver.exe'
#绑定类的属性
def __init__(self):
self.driver = webdriver.Chrome(executable_path = MeiZiTuSpaider.driver_path)
self.url = 'https://www.mzitu.com/'
#解析妹子图主页html
def run(self):
self.driver.get(self.url)
#浏览器窗口最大化
self.driver.maximize_window()
#解析主页
source = self.driver.page_source
self.get_page_url(source)
#解析妹子图分类url
def get_page_url(self,source):
tree = etree.HTML(source)
page_urls = tree.xpath('//div[@class="postlist"]/ul//li/a/@href')
for page_url in page_urls:
self.get_img_url(page_url)
#获取图片地址
def get_img_url(self,page_url):
#在新的窗口打开妹子图片页面
self.driver.execute_script("window.open('%s')"%page_url)
#浏览器切换到新的页面,也就是从主页跳转到妹子图片页
self.driver.switch_to_window(self.driver.window_handles[1])
while True:
#找到页面中“下一页»”文本链接元素
next_page = self.driver.find_elements_by_partial_link_text('下一页»')
# 找到页面中“下一页»”元素
next_bnt = self.driver.find_element_by_xpath('//div[@class="pagenavi"]/a[last()]')
#等待页面加载文本链接“下一页»”元素5秒时间,若超过5秒则抛出异常
WebDriverWait(self.driver,timeout=5).until(
EC.presence_of_element_located((By.XPATH,'//div[@class="pagenavi"]/a[last()]')))
#若找到页面中“下一页»”文本链接元素,则执行下面代码,否则跳出循环
if next_page:
source = self.driver.page_source
tree = etree.HTML(source)
#获取图片地址
img_url = tree.xpath('//div['
'@class="main-image"]/p//img/@src')[0]
print(img_url)
self.down_img(img_url)
next_bnt.click()
else:
break
#若无法找到页面中“下一页»”文本链接元素,说明此分类的妹子图已经全部找到,然后关闭本浏览器窗口
self.driver.close()
#浏览器窗口切换到主页
self.driver.switch_to_window(self.driver.window_handles[0])
#下载妹子图
def down_img(self,img_url):
# 妹子图有反爬虫机制,需要设置好请求头
headers = {
'user-agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Mobile Safari/537.36',
'cookie': 'Hm_lvt_dbc355aef238b6c32b43eacbbf161c3c=1528013189,1528123045,1528211821,1528376611',
'referer': 'https://www.mzitu.com/'
}
#文件保存路径
root = "C:\\meizitu\\"
#取出图片地址最后的文件扩展名
pic_num = img_url.split('/')[-1]
#重构图片名称
pic_name = root + '/' + pic_num
#二进制保存图片
pic = requests.get(img_url,headers=headers).content
#保存图片
with open(pic_name,'wb') as fb:
fb.write(pic)
print("保存成功")
if __name__ == '__main__':
spider = MeiZiTuSpaider()
spider.run()
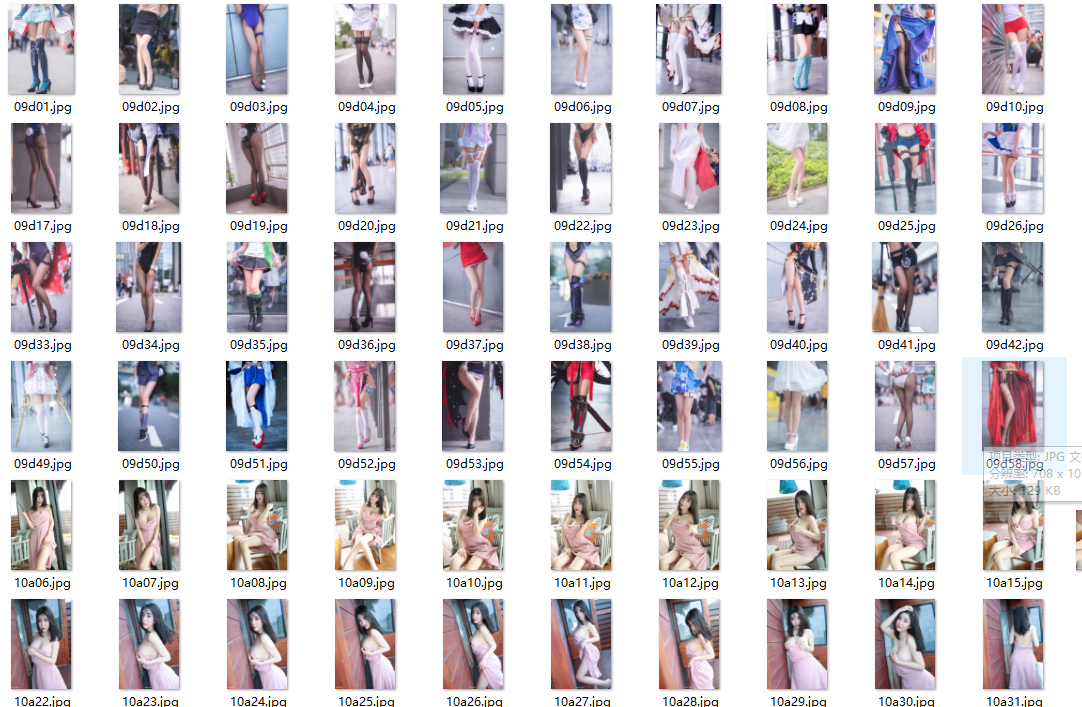
五、效果图

 浙公网安备 33010602011771号
浙公网安备 33010602011771号