
Redis Sentinel(哨兵核心机制) 初步深入
##### 1、Redis 的 Sentinel 系统用于管理多个 Redis 服务
该系统执行以下三个任务:
1、监控(Monitoring): Sentinel 会不断地检查你的主服务器和从服务器是否运作正常。
2、提醒(Notification): 当被监控的某个 Redis 服务器出现问题时, Sentinel 可以通过 API 向管理员或者其他应用程序发送通知。
3、自动故障迁移(Automatic failover): 当一个主服务器不能正常工作时, Sentinel 会开始一次自动故障迁移操作, 它会将失效主服务器的其中一个从服务器升级为新的主服务器, 并让失效主服务器的其他从服务器改为复制新的主服务器; 当客户端试图连接失效的主服务器时, 集群也会向客户端返回新主服务器的地址, 使得集群可以使用新主服务器代替失效服务器。
说白了就是进行redis服务的监控,看redis服务是否能正常运行,如果不能进行通知,如果主机挂掉了,再让从节点进行投票重新选举主节点。 ###### 哨兵本身也是分布式的,作为一个哨兵集群去运行,互相协同工作 ``` 故障转移时,判断一个master node是宕机了,需要大部分的哨兵都同意才行,涉及到了分布式选举的问题,即使部分哨兵节点挂掉了,哨兵集群还是能正常工作的 ``` ##### 2、哨兵的核心知识 (1)哨兵至少需要3个或三个以上的实例,来保证自己的健壮性
(2)哨兵配合redis replication 的部署架构,是不能保证数据不丢失的,他们的主要作用是为了让redis集群的高可用 ``` # 语法:sentinel monitor
#
# Tells Sentinel to monitor this master, and to consider it in O_DOWN
# (Objectively Down) state only if at least sentinels agree.
# 解释:告诉哨兵去监控主机(master),并且去思考再仅仅在ODOWN(客观宕机)下至少在你设置的quorum的数量的哨兵都同意才可以
# Note that whatever is the ODOWN quorum, a Sentinel will require to
# be elected by the majority of the known Sentinels in order to
# start a failover, so no failover can be performed in minority.
#解释:注意无论quorum 设置的值是多少,哨兵都将必须在多数(majority)哨兵选举下执行故障转移,因此少数情况下是不允许进行故障转移的
# Replicas are auto-discovered, so you don't need to specify replicas in
# any way. Sentinel itself will rewrite this configuration file adding
# the replicas using additional configuration options.
# Also note that the configuration file is rewritten when a
# replica is promoted to master.
#解释:主从是自发现的,因此你无需指定从机,哨兵自己将重写配置文件添加到从机的配置选项,还要注意,在将从机提升为主机的时候,将重写配置文件。
```
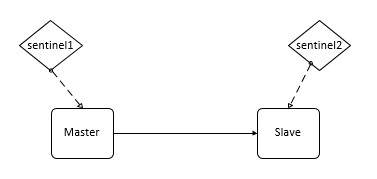
##### 3、为什么redis哨兵集群只有2个节点无法正常工作?
如果哨兵集群仅仅部署了个2个哨兵实例,quorum=1
```
Configuration: quorum = 1
```
###### master如果宕机,Sentinel1和Sentinel2中只要有1个哨兵认为master宕机就可以进行切换,同时s1和s2中会选举出一个哨兵来执行故障转移,同时这个时候,需要majority,也就是大多数哨兵都是运行的,2个哨兵的majority就是2(2的majority=2,3的majority=2,5的majority=3,4的majority=2),2个哨兵都运行着,就可以允许执行故障转移。但是如果整个master运行的机器宕机了,那么哨兵只有1个了(Sentinel2),此时就没有majority来允许执行故障转移,虽然另外一台机器还有一个Sentinel2,但是故障转移不会执行
###### 4、经典的3节点哨兵集群
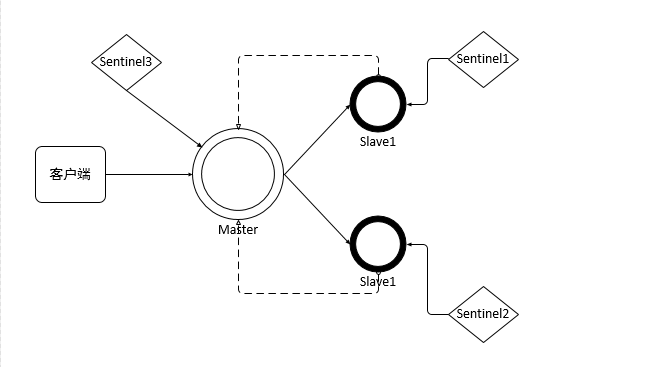
```
Configuration: quorum = 2,majority
```
###### 如果Master所在机器宕机了,那么3个哨兵还剩下2个,剩下的哨兵可以一致认为Master宕机了,然后选举出一个来执行故障转移,因为3个哨兵的majority是2,所以即使主机宕机了但是还剩下的2个哨兵运行着,就可以允许执行故障转移
###### 5、两种数据丢失的情况
主备切换的过程,可能会导致数据丢失的两种情况:
1、异步复制导致的数据丢失
因为master -> slave的复制是异步的,所以可能有部分数据还没复制到slave,master就宕机了,此时这些部分数据就丢失了。
2、脑裂导致的数据丢失
在高可用(HA)系统中,当联系2个节点的“心跳线”断开时,本来为一整体、动作协调的HA系统,就分裂成为2个独立的个体。由于相互失去了联系,都以为是对方出了故障。两个节点上的HA软件像“裂脑人”一样,争抢“共享资源”、争起“应用服务”,就会发生严重后果——或者共享资源被瓜分、2边“服务”都起不来了;或者2边“服务”都起来了,但同时读写“共享存储”,导致数据损坏(常见如数据库轮询着的联机日志出错)。
对于HA系统“裂脑”的对策,目前达成共识的的大概有以下几条:
1)添加冗余的心跳线,例如:双线条线(心跳线也HA),尽量减少“裂脑”发生几率
2)启用磁盘锁。正在服务一方锁住共享磁盘,“裂脑”发生时,让对方完全“抢不走”共享磁盘资源。但使用锁磁盘也会有一个不小的问题,如果占用共享盘的一方不主动“解锁”,另一方就永远得不到共享磁盘。现实中假如服务节点突然死机或崩溃,就不可能执行解锁命令。后备节点也就接管不了共享资源和应用服务。于是有人在HA中设计了“智能”锁。即:正在服务的一方只在发现心跳线全部断开(察觉不到对端)时才启用磁盘锁。平时就不上锁了。
3)设置仲裁机制。例如设置参考IP(如网关IP),当心跳线完全断开时,2个节点都各自ping一下参考IP,不通则表明断点就出在本端。不仅“心跳”、还兼对外“服务”的本端网络链路断了,即使启动(或继续)应用服务也没有用了,那就主动放弃竞争,让能够ping通参考IP的一端去起服务。更保险一些,ping不通参考IP的一方干脆就自我重启,以彻底释放有可能还占用着的那些共享资源。 ###### redis中发生的脑裂场景,也就是说,某个master所在机器突然脱离了正常的网络,跟其他slave机器不能连接,但是实际上master还运行着,此时哨兵可能就会认为master宕机了,然后开启选举,将其他slave切换成了master,这个时候,集群里就会有两个master,也就是所谓的脑裂。此时虽然某个slave被切换成了master,但是可能client还没来得及切换到新的master,还继续写向旧master的数据可能也丢失了。因此旧master再次恢复的时候,会被作为一个slave挂到新的master上去,自己的数据会清空,重新从新的master复制数据。 ##### 6、解决异步复制和脑裂导致的数据丢失 ``` # It is possible for a master to stop accepting writes if there are less than # N replicas connected, having a lag less or equal than M seconds. # # The N replicas need to be in "online" state. # # The lag in seconds, that must be <= the specified value, is calculated from # the last ping received from the replica, that is usually sent every second. # # This option does not GUARANTEE that N replicas will accept the write, but # will limit the window of exposure for lost writes in case not enough replicas # are available, to the specified number of seconds. # # For example to require at least 3 replicas with a lag <= 10 seconds use: # redis提供了可以让master停止写入的方式,如果配置了min-replicas-to-write, # 健康的slave的个数小于N,mater就禁止写入。master最少得有多少个健康的 # slave存活才能执行写命令。这个配置虽然不能保证N个slave都一定能接收到 # master的写操作,但是能避免没有足够健康的slave的时候,master不能写入来 # 避免数据丢失。设置为0是关闭该功能 # min-replicas-to-write 3 # 延迟小于min-replicas-max-lag秒的slave才认为是健康的slave # min-replicas-max-lag 10 # 设置1或另一个设置为0禁用这个特性。 # Setting one or the other to 0 disables the feature. # By default min-replicas-to-write is set to 0 (feature disabled) and # min-replicas-max-lag is set to 10. ``` 1、减少异步复制的数据丢失
有了min-slaves-max-lag这个配置,就可以确保说,一旦slave复制数据和ack延时太长,就认为可能master宕机后损失的数据太多了,那么就拒绝写请求,这样可以把master宕机时由于部分数据未同步到slave导致的数据丢失降低的可控范围内 2、减少脑裂的数据丢失
如果一个master出现了脑裂,跟其他slave丢了连接,那么上面两个配置可以确保说,如果不能继续给指定数量的slave发送数据,而且slave超过10秒没有给自己ack消息,那么就直接拒绝客户端的写请求,这样脑裂后的旧master就不会接受client的新数据,也就避免了数据丢失。因此在脑裂场景下,最多就丢失10秒的数据 帮忙关注一下 微信公众号一起学习 :chengxuyuan95(不一样的程序员)
2、提醒(Notification): 当被监控的某个 Redis 服务器出现问题时, Sentinel 可以通过 API 向管理员或者其他应用程序发送通知。
3、自动故障迁移(Automatic failover): 当一个主服务器不能正常工作时, Sentinel 会开始一次自动故障迁移操作, 它会将失效主服务器的其中一个从服务器升级为新的主服务器, 并让失效主服务器的其他从服务器改为复制新的主服务器; 当客户端试图连接失效的主服务器时, 集群也会向客户端返回新主服务器的地址, 使得集群可以使用新主服务器代替失效服务器。
说白了就是进行redis服务的监控,看redis服务是否能正常运行,如果不能进行通知,如果主机挂掉了,再让从节点进行投票重新选举主节点。 ###### 哨兵本身也是分布式的,作为一个哨兵集群去运行,互相协同工作 ``` 故障转移时,判断一个master node是宕机了,需要大部分的哨兵都同意才行,涉及到了分布式选举的问题,即使部分哨兵节点挂掉了,哨兵集群还是能正常工作的 ``` ##### 2、哨兵的核心知识 (1)哨兵至少需要3个或三个以上的实例,来保证自己的健壮性
(2)哨兵配合redis replication 的部署架构,是不能保证数据不丢失的,他们的主要作用是为了让redis集群的高可用 ``` # 语法:sentinel monitor
1、异步复制导致的数据丢失
因为master -> slave的复制是异步的,所以可能有部分数据还没复制到slave,master就宕机了,此时这些部分数据就丢失了。
2、脑裂导致的数据丢失
在高可用(HA)系统中,当联系2个节点的“心跳线”断开时,本来为一整体、动作协调的HA系统,就分裂成为2个独立的个体。由于相互失去了联系,都以为是对方出了故障。两个节点上的HA软件像“裂脑人”一样,争抢“共享资源”、争起“应用服务”,就会发生严重后果——或者共享资源被瓜分、2边“服务”都起不来了;或者2边“服务”都起来了,但同时读写“共享存储”,导致数据损坏(常见如数据库轮询着的联机日志出错)。
对于HA系统“裂脑”的对策,目前达成共识的的大概有以下几条:
1)添加冗余的心跳线,例如:双线条线(心跳线也HA),尽量减少“裂脑”发生几率
2)启用磁盘锁。正在服务一方锁住共享磁盘,“裂脑”发生时,让对方完全“抢不走”共享磁盘资源。但使用锁磁盘也会有一个不小的问题,如果占用共享盘的一方不主动“解锁”,另一方就永远得不到共享磁盘。现实中假如服务节点突然死机或崩溃,就不可能执行解锁命令。后备节点也就接管不了共享资源和应用服务。于是有人在HA中设计了“智能”锁。即:正在服务的一方只在发现心跳线全部断开(察觉不到对端)时才启用磁盘锁。平时就不上锁了。
3)设置仲裁机制。例如设置参考IP(如网关IP),当心跳线完全断开时,2个节点都各自ping一下参考IP,不通则表明断点就出在本端。不仅“心跳”、还兼对外“服务”的本端网络链路断了,即使启动(或继续)应用服务也没有用了,那就主动放弃竞争,让能够ping通参考IP的一端去起服务。更保险一些,ping不通参考IP的一方干脆就自我重启,以彻底释放有可能还占用着的那些共享资源。 ###### redis中发生的脑裂场景,也就是说,某个master所在机器突然脱离了正常的网络,跟其他slave机器不能连接,但是实际上master还运行着,此时哨兵可能就会认为master宕机了,然后开启选举,将其他slave切换成了master,这个时候,集群里就会有两个master,也就是所谓的脑裂。此时虽然某个slave被切换成了master,但是可能client还没来得及切换到新的master,还继续写向旧master的数据可能也丢失了。因此旧master再次恢复的时候,会被作为一个slave挂到新的master上去,自己的数据会清空,重新从新的master复制数据。 ##### 6、解决异步复制和脑裂导致的数据丢失 ``` # It is possible for a master to stop accepting writes if there are less than # N replicas connected, having a lag less or equal than M seconds. # # The N replicas need to be in "online" state. # # The lag in seconds, that must be <= the specified value, is calculated from # the last ping received from the replica, that is usually sent every second. # # This option does not GUARANTEE that N replicas will accept the write, but # will limit the window of exposure for lost writes in case not enough replicas # are available, to the specified number of seconds. # # For example to require at least 3 replicas with a lag <= 10 seconds use: # redis提供了可以让master停止写入的方式,如果配置了min-replicas-to-write, # 健康的slave的个数小于N,mater就禁止写入。master最少得有多少个健康的 # slave存活才能执行写命令。这个配置虽然不能保证N个slave都一定能接收到 # master的写操作,但是能避免没有足够健康的slave的时候,master不能写入来 # 避免数据丢失。设置为0是关闭该功能 # min-replicas-to-write 3 # 延迟小于min-replicas-max-lag秒的slave才认为是健康的slave # min-replicas-max-lag 10 # 设置1或另一个设置为0禁用这个特性。 # Setting one or the other to 0 disables the feature. # By default min-replicas-to-write is set to 0 (feature disabled) and # min-replicas-max-lag is set to 10. ``` 1、减少异步复制的数据丢失
有了min-slaves-max-lag这个配置,就可以确保说,一旦slave复制数据和ack延时太长,就认为可能master宕机后损失的数据太多了,那么就拒绝写请求,这样可以把master宕机时由于部分数据未同步到slave导致的数据丢失降低的可控范围内 2、减少脑裂的数据丢失
如果一个master出现了脑裂,跟其他slave丢了连接,那么上面两个配置可以确保说,如果不能继续给指定数量的slave发送数据,而且slave超过10秒没有给自己ack消息,那么就直接拒绝客户端的写请求,这样脑裂后的旧master就不会接受client的新数据,也就避免了数据丢失。因此在脑裂场景下,最多就丢失10秒的数据 帮忙关注一下 微信公众号一起学习 :chengxuyuan95(不一样的程序员)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号