AI教父的自监督直觉——SimCLR
文章链接: A Simple Framework for Contrastive Learning of Visual Representations
挡在大规模AI应用从PPT到GDP征途中的最大障碍———巨大的数据标注成本,是一个棘手的问题。
简单如识别一张图中是否有喵,就得动辄上万张各种姿势的喵图外带上万张不是喵的图喂给饕餮一样的神经网络。这里面的痛点就是你不仅要搜集这些图,还得划分每张图的种类,那如果要搞一个能识别所有动物的机器人得花费多少心血。现在,如果给你一个模型,不需要标注,只要写个爬虫让它自己在网上看图看片,它就自己琢磨出了图里面到底是什么个东西,是不是会感觉赛博朋飞升之日可期可盼?
这篇文章就提供了这么一种方法,不过暂时,要做出这么个机器需要上百张TPU(百万大洋)。作者是图灵奖获得者的Hinton教授,文章没有复杂的数学公式,也没有太多奇淫巧计,因此也不那么晦涩难懂。
主干思路提炼
当前分类问题的流行思路就是,将原始特征(如图、音频)映射到一个线性可分的空间。那么,SimCLR就是试图去学习这么一个空间。
训练准则可以简化成如下步骤:
- 找一个图像数据集,如CIFAR10、ImageNet,也可以是网上搜集的一堆图
- 在每一步训练中,抽出一批图像,如N张图
- 这N张图的每一张都做一次随机数据增强,这样一共就有2N张图
- 经过一个网络f映射到空间h, 这个h就是想要得到的目标空间
- 拟定只要是同一张图衍生的匹配对,就是正例,否则是反例。使用一个比较函数统计损失更新参数
- 重复2
上述过程中,比较函数为一个两层(带ReLU)的MLP(g)外加一个Cosine匹配函数:
以上公式中,如果原始图像序列设为 x,y,z 那么扩充后的处理序列为 x,x',y,y',z,z',系数tau设定为0.1最好。
训练细节与结论
使用了256到8192张图每一个batch,可想而知多么吃显存。因为每一批容量很大所以使用了LARS优化器,这个优化器是专门应对大batch使用的。
同时,该方法还用了GN,主要就是平均多卡的均值与方差,可以看作BN的多卡版本。
以下实验结果表明,随机裁剪与颜色变换的组合在ImageNet上准确率最高:
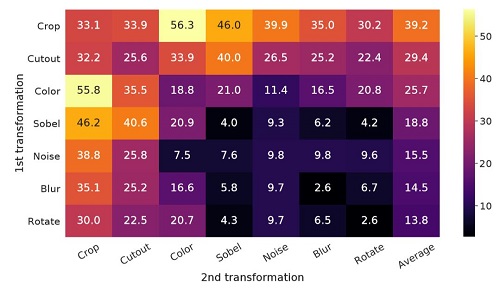
文章中指出了,数据增强对该方法来说十分重要。
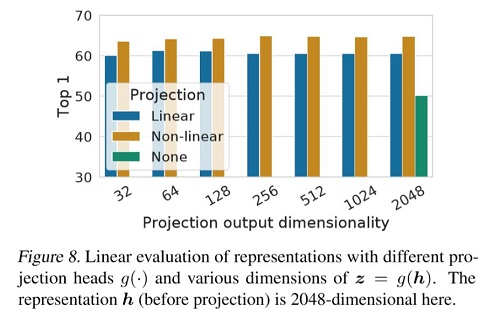
以下结论也十分重要,道出了这个g映射的重要性:
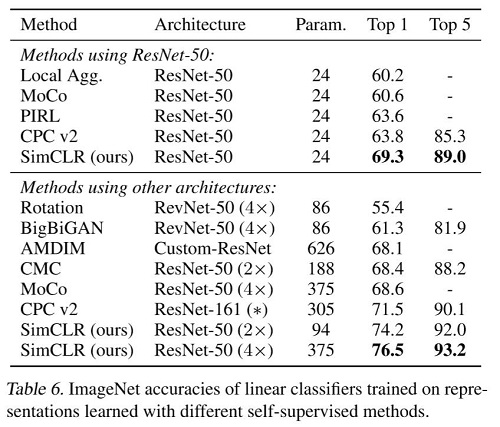
训练结果看起来很香,特别地,更长的训练周期以及更大的batch效果更好:
扯蛋环节
现在很多研究一直致力于得到一个强有力的表示空间h能够正确地表示一些常见的特征分布(比如如果用来区分动物,这些特征有眼睛形状、毛发长度、四肢、是否直立、头长哪屁股长哪等等)。有监督学习的目标就是要确保同种类别在特征空间h的表示尽可能相似。对于没有标注的图像,唯一能确定的是,与图像x同类的图像就是它自己或者它自己的增强。SimCLR就是那么一个大力出奇迹的方法,它假设任意一张图及其的增强为一个类,使用一个超大的样本集合(batrch)来训练一个近乎无限类别的任务,试图最终得到一个能提取任意一张图中某些不变(裁剪、旋转、平移、颜色变换)特征的映射方法(这里就是卷积神经网络)。那么,蕴含在其中的这些不变性,可能就是眼睛、毛发、躯干形状等等特征的一些与或组合、分布以及关系。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号