
卷积神经网络CNN学习笔记
CNN的基本结构包括两层:
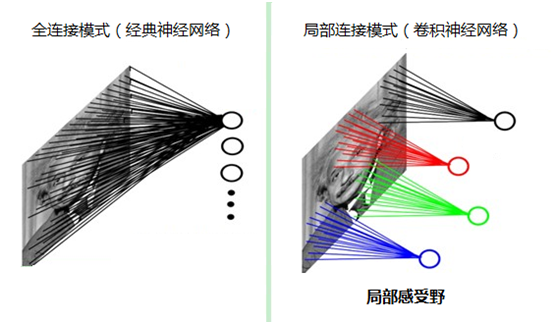
特征提取层:每个神经元的输入与前一层的局部接受域相连,并提取该局部的特征。一旦该局部特征被提取后,它与其它特征间的位置关系也随之确定下来;
特征映射层:网络的每个计算层由多个特征映射组成,每个特征映射是一个平面,平面上所有神经元的权值相等。特征映射结构采用影响函数核小的sigmoid函数作为卷积网络的激活函数,使得特征映射具有位移不变性。此外,由于一个映射面上的神经元共享权值,因而减少了网络自由参数的个数。卷积神经网络中的每一个卷积层都紧跟着一个用来求局部平均与二次提取的计算层,这种特有的两次特征提取结构减小了特征分辨率。
局部感受野:我们人类对外界的认知一般是从局部到全局,先对局部有感知的认识,再逐步对全体有认知。在图像中的空间联系也是类似,局部范围内的像素之间联系较为紧密,而距离较远的像素则相关性较弱。因而,每个神经元其实没有必要对全局图像进行感知,只需要对局部进行感知,然后在更高层将局部的信息综合起来就得到了全局的信息。
提取特征:
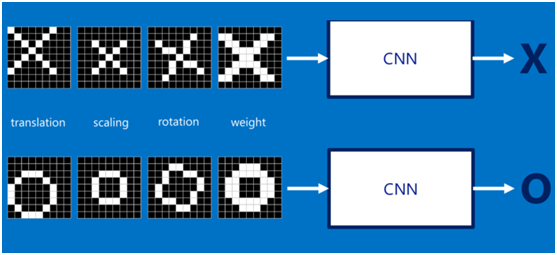
我们的目标是对于各种形态变化的X和O,都能通过CNN准确地识别出来,这就涉及到应该如何有效地提取特征,作为识别的关键因子。对于CNN来说,它是一小块一小块地来进行比对,在两幅图像中大致相同的位置找到一些粗糙的特征(小块图像)进行匹配,相比起传统的整幅图逐一比对的方式,CNN的这种小块匹配方式能够更好的比较两幅图像之间的相似性。

以字母X为例,可以提取出三个重要特征(两个交叉线、一个对角线),如下图所示:
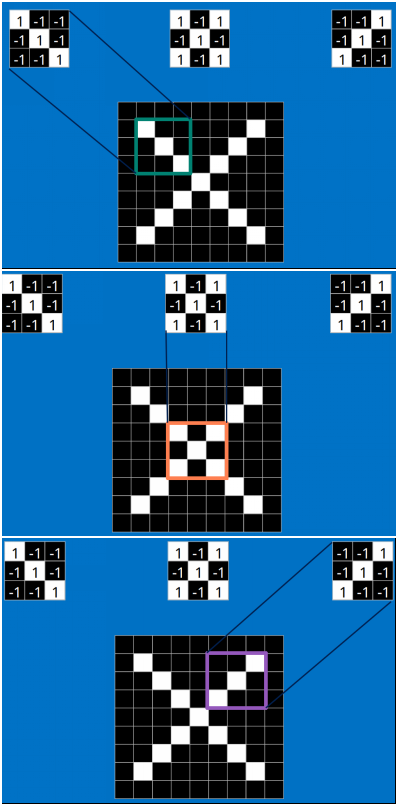
假如以像素值"1"代表白色,像素值"-1"代表黑色,则字母X的三个重要特征如下:

卷积:(进行匹配运算)
要计算一个feature(特征)和其在原图上对应的某一小块的结果,只需将两个小块内对应位置的像素值进行乘法运算,然后将整个小块内乘法运算的结果累加起来,最后再除以小块内像素点总个数即可(注:也可不除以总个数的)。
如果两个像素点都是白色(值均为1),那么1*1 = 1,如果均为黑色,那么(-1)*(-1) = 1,也就是说,每一对能够匹配上的像素,其相乘结果为1。类似地,任何不匹配的像素相乘结果为-1。具体过程如下(第一个、第二个……、最后一个像素的匹配结果):
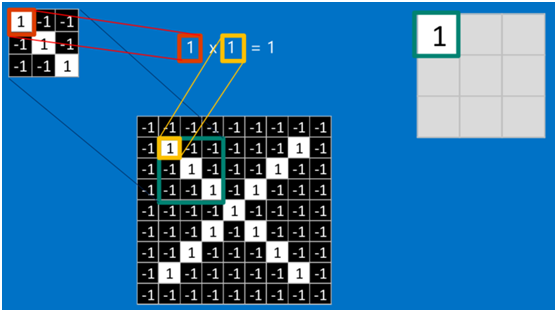


根据卷积的计算方式,第一块特征匹配后的卷积计算如下,结果为1
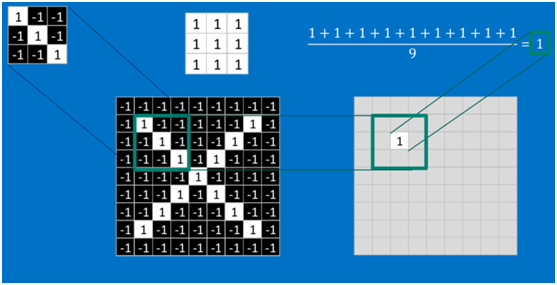
对于其它位置的匹配,也是类似(例如中间部分的匹配)
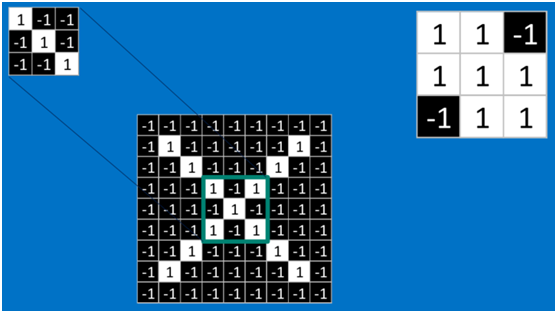
计算之后的卷积如下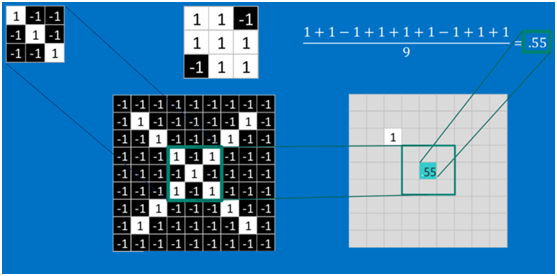
我们可以看到,这个图中的绿色框,我们称之为“窗口”,窗口可滑动。最开始在起始位置,进行卷积对应相乘运算并求得均值后,滑动窗口向右边滑动。

根据步长的不同选择滑动步幅。若步长stride=1,向右平移一个像素;

若步长stride=2,向右平移两个像素。

同理。移到最右边后,返回左边开始第二排。步长为1,向下平移一个像素;步长为2,向下平移两个像素。

但这样可能会遇到一个问题,图像左右两角只被权重通过一次,我们需要做的是让网络像考虑其他像素一样考虑角落。我们有一个简单的方法解决这一问题:把零放在权重运动的两边。(这个图不符,是从别的地方粘过来的,但可以类似看一下)

你可以看到通过添加零,来自角落的信息被再训练。图像也变得更大。这可被用于我们不想要缩小图像的情况下。
以此类推,对三个特征图像不断地重复着上述过程,通过每一个feature(特征)的卷积操作,会得到一个新的二维数组,称之为feature map。其中的值,越接近1表示对应位置和feature的匹配越完整,越是接近-1,表示对应位置和feature的反面匹配越完整,而值接近0的表示对应位置没有任何匹配或者说没有什么关联。如下图所示:
可以看出,当图像尺寸增大时,其内部的加法、乘法和除法操作的次数会增加得很快,每一个filter的大小和filter的数目呈线性增长。
池化(Pooling):将输入图像进行缩小,减少像素信息,只保留重要信息。有效减少计算量
池化的操作也很简单,通常情况下,池化区域是2*2大小,然后按一定规则转换成相应的值,例如取这个池化区域内的最大值(max-pooling)、平均值(mean-pooling)等,以这个值作为结果的像素值。
最大池化为例:
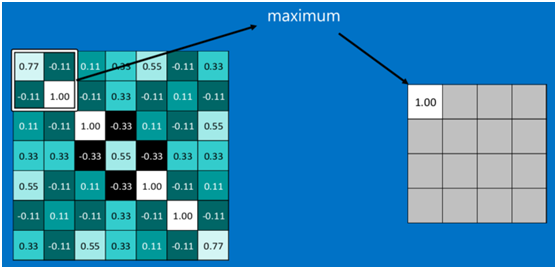

其它区域也是类似,取区域内的最大值作为池化后的结果,最后经过池化后,结果如下:

最大池化(max-pooling)保留了每一小块内的最大值,也就是相当于保留了这一块最佳的匹配结果(因为值越接近1表示匹配越好)。也就是说,它不会具体关注窗口内到底是哪一个地方匹配了,而只关注是不是有某个地方匹配上了。常用的激活函数有sigmoid、tanh、relu等等,前两者sigmoid/tanh比较常见于全连接层,后者ReLU常见于卷积层。
激活函数RelU (Rectified Linear Units)
常用的激活函数有sigmoid、tanh、relu等等,前两者sigmoid/tanh比较常见于全连接层,后者ReLU常见于卷积层。
回顾感知器,感知器在接收到各个输入,然后进行求和,再经过激活函数后输出。激活函数的作用是用来加入非线性因素,把卷积层输出结果做非线性映射。
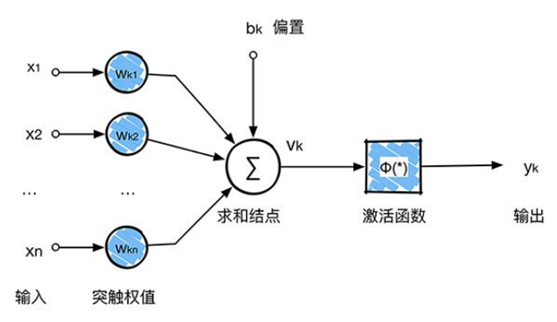
在卷积神经网络中,激活函数一般使用ReLU(The Rectified Linear Unit,修正线性单元),它的特点是收敛快,求梯度简单。计算公式也很简单,max(0,T),即对于输入的负值,输出全为0,对于正值,则原样输出。
下面看一下本案例的ReLU激活函数操作过程:
第一个值,取max(0,0.77),结果为0.77,如下图
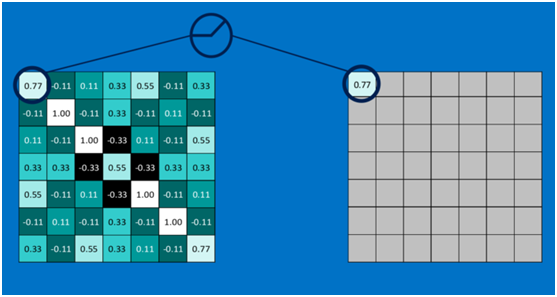
第二个值,取max(0,-0.11),结果为0,如下图

以此类推,经过ReLU激活函数后,结果如下:

深度神经网络
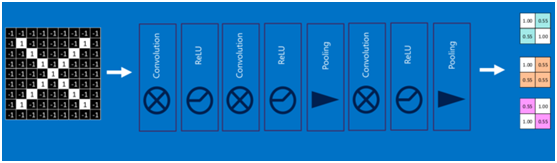
通过将上面所提到的卷积、激活函数、池化组合在一起,就变成下图:

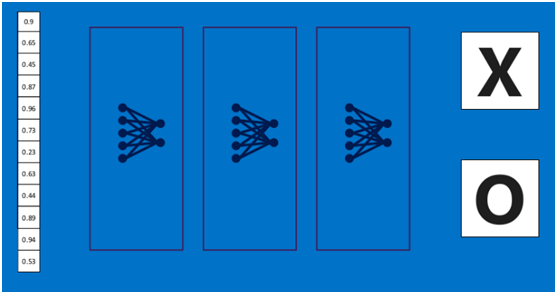
通过加大网络的深度,增加更多的层,就得到了深度神经网络,如下图:
全连接层(Fully connected layers)
全连接层在整个卷积神经网络中起到“分类器”的作用,即通过卷积、激活函数、池化等深度网络后,再经过全连接层对结果进行识别分类。
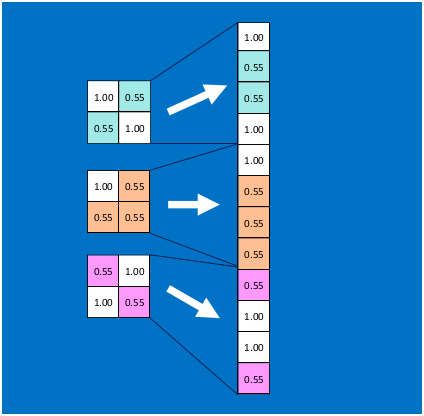
首先将经过卷积、激活函数、池化的深度网络后的结果串起来,如下图所示:
由于神经网络是属于监督学习,在模型训练时,根据训练样本对模型进行训练,从而得到全连接层的权重(如预测字母X的所有连接的权重)

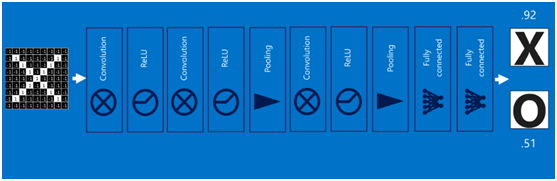
在利用该模型进行结果识别时,根据刚才提到的模型训练得出来的权重,以及经过前面的卷积、激活函数、池化等深度网络计算出来的结果,进行加权求和,得到各个结果的预测值,然后取值最大的作为识别的结果(如下图,最后计算出来字母X的识别值为0.92,字母O的识别值为0.51,则结果判定为X)

上述这个过程定义的操作为”全连接层“(Fully connected layers),全连接层也可以有多个,如下图:
卷积神经网络(Convolutional Neural Networks)
将以上所有结果串起来后,就形成了一个“卷积神经网络”(CNN)结构,如下图所示:
最后,再回顾总结一下,卷积神经网络主要由两部分组成,一部分是特征提取(卷积、激活函数、池化),另一部分是分类识别(全连接层)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号