
Python学习笔记06#mysql数据库的使用和接入
Python学习笔记06#mysql数据库的使用和接入
目录速查
一、Mysql基本语句和注意事项
基本语句
1.linux进入mysql
- 以用户名为xxx的权限进入数据库管理系统
mysql -u xxx -p
注意:linux输入的密码不会显示,但实际上已经输进去了
2.创建–create
- 创建名为xxx的数据库
create database xxx character set utf8mb4 collate utf8mb4_unicode_520_ci;
注意:
1.sql语句要以“;”结尾表示一条语句。
2.mysql语法不区分大小写(不包括文件名)
3.如果不对库进行utf-8编码设置,里面的文件都无法显示和输入中文,不如在此直接设置。
- 创建一个表
举例说明:创建了一个名为user的表
CREATE TABLE user (
`id` int NOT NULL AUTO_INCREMENT,
`username` varchar(150) NOT NULL,
`password` varchar(128) NOT NULL,
`realname` varchar(30) NOT NULL,
PRIMARY KEY (id)
)
CHARACTER SET utf8mb4
COLLATE utf8mb4_unicode_520_ci;
- 创建索引
举例说明:给 customer2 这张表的 username 这列添加一个名为 index_username 的索引。
CREATE INDEX index_username ON customer2 (username)
3.切换–use
- 切换到xxx数据库
use xxx
4.显示–show
- 显示所有数据库
show databases; - 显示当前数据库下的所有表
show tables;
5.查询–select(可以理解为查找,也可以理解为取)
- 查询表的所有记录
select * from xxx(显示xxx表的所有记录) - 查询表的指定列
select id,username from user;(显示user表的id和username列) - 带过滤条件的查询
select * from user where username='user1;(where是过滤的标志,后面接过滤条件)
子查询的概念:一个查询的结果是另一个查询的过滤条件,这个查询就是子查询
举例:SELECT 电话号码 FROM 学生表 WHERE 姓名 IN ( SELECT 姓名 FROM 成绩表 WHERE 分数=100 );
- 查询去重
select distinct 课程 from 成绩表 where 分数=100;(distinct是去重标志) - 查询排序
select * from customer1 where id > 10 order by coin;(order by是排序标志,默认按值升序,被排序目标后面加desc按值升序,如:order by coin desc。支持多列排序,如:order by coin, level)
注意,这里存在group by (分组)和order by(排序)的区别。具体概念和区别见group by和order by 的区别
- 查询记录条数
select count(*) from 学生表 where 姓名 like "学生%";(count是SQL函数,用来返回记录数量)
常用的SQL函数还有:sum求和,avg平均,max最大值,min最小值
6.添加–insert into
- 为一个表添加记录,举例:
将这4条记录添加进user表中
INSERT INTO user (username,`password`,realname) VALUES
('byhy2','password2','名字2'),
('byhy3','password3','名字3'),
('byhy4','password4','名字4'),
('byhy5','password5','名字5');
7.更新–update(更新的核心思想是对值的更新,是对列更新)
- 加了过滤条件的更新
update customer1 set coin=100 where username='cus16';(将表custom1中username是cus16的coin值更新为100)
8.删除记录–delete from (删除的核心思想是对记录删除,是对行删除)
- 删除表记录
delete from customer1 where username='cus16';(将表custom1中username是cus16的这条记录删除)
9.彻底删除–drop
- 彻底删除表
drop table xxx; - 彻底删除库
drop database xxx;
二、python访问mysql
ps:这里默认创建连接名为connecton
cursor() 获取游标
游标:游动的标识,沿着游标可以一次取出一行,初始游标位于第一行
用法:cursor =connecton.cursor()
后面的很多命令,如excute()、fetchone()等都属于游标的方法,使用时如cursor.fetchone()
excute(sql)执行一个数据库查询和命令,即sql语句
用法:cursor.excute(sql)
commit()提交,凡是执行更改数据的sql语句,包括插入、更新、删除,后面一定要调用connection的commit方法才能保证执行sql生效
用法:connecton.commit()
close()关闭连接
用法:connection.close()
fetchone() 取得游标所在行,返回的是一个元组,代表获取的一行记录,元组里每个元素代表一个字段
fetchmany(size) 取得游标后(含游标)size行(不是第size行,是共size行),返回的也是一个元组,各行数据是小元组嵌套作为大元组内的元素
fetchall() 取得游标后(含游标)的所有行,返回的也是一个元组,各行数据是小元组嵌套作为大元组内的元素
注意:这些fetch语句每次运行后,游标在sql执行产生的结果集里的位置都会发生变化,比如游标本来在第一行,fetchone后就移动到了第二行;本来在第二行,fetchmany(2)后就移动到了第四行;本来在第四行,fetch后就移动到了结果集的末尾的下一行,再想fetchone的话返回的结果就是none
示例:
import pymysql
connecton =pymysql.connect(
host='192.168.244.128',#ip地址/主机名
port=3306,#端口号
user='user1',#要登入mysql的用户名
password='Mima123$',#密码
db='database1',#数据库名
charset='utf8')#数据库的编码模式
cursor =connecton.cursor()#创建一个游标
sql ='SELECT * FROM `user`'
cursor.execute(sql)#执行sql语句
data1 =cursor.fetchall()#返回结果集所有行
print(data1)
返回结果
((1, 'user1', 'password1', '张三'), (2, 'user2', 'password2', '李四'), (3, 'user3', 'password3', '王五'), (4, 'user4', 'password4', '二狗'))
三、实战例子
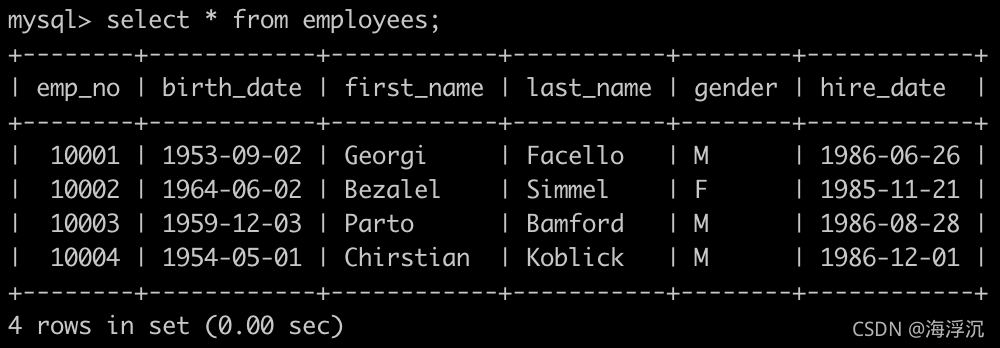
1.有一个员工employees表,查找employees里入职员工时间排名倒数第三的员工所有信息
SELECT * FROM employees WHERE hire_date =(
SELECT DISTINCT hire_date FROM employees ORDER BY hire_date DESC LIMIT 2,1)
思路:根据日期查找,直接排序取第三可能会存在日期重复的员工,所以先把时间倒数第三的这个日期取出来,再取这个日期对应的所有员工信息。
LIMIT 2,1 代表从第2+1条数据开始取,取1条数据; LIMIT n,m代表从第n+1条数据开始取,取m条数据(需要+1的原因是数据序号是从0开始的)
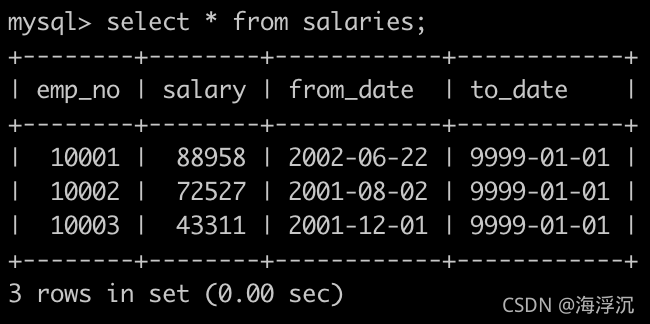
2.查找当前薪水详情以及部门编号dept_no
有一个全部员工的薪水表salaries简况如下:
有一个各个部门的领导表dept_manager简况如下:
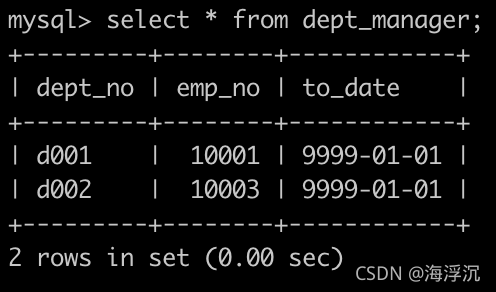
请你查找各个部门当前领导的薪水详情以及其对应部门编号dept_no,输出结果以salaries.emp_no升序排序,并且请注意输出结果里面dept_no列是最后一列
例:
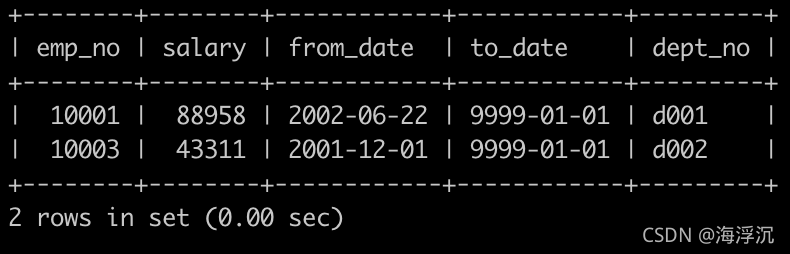
SELECT salaries.*,dept_manager.dept_no FROM salaries
INNER JOIN dept_manager ON salaries.emp_no =dept_manager.emp_no
WHERE dept_manager.to_date='9999-01-01'
AND salaries.to_date ='9999-01-01'
ORDER BY salaries.emp_no ASC
思路:根据emp_no链接两表,条件to_date =‘9999-01-01’,将符合条件的salaries的所有内容和dept_manager的dept_no输出
3.查找所有员工的last_name和first_name以及对应部门编号dept_no
有一个员工表,employees简况如下:
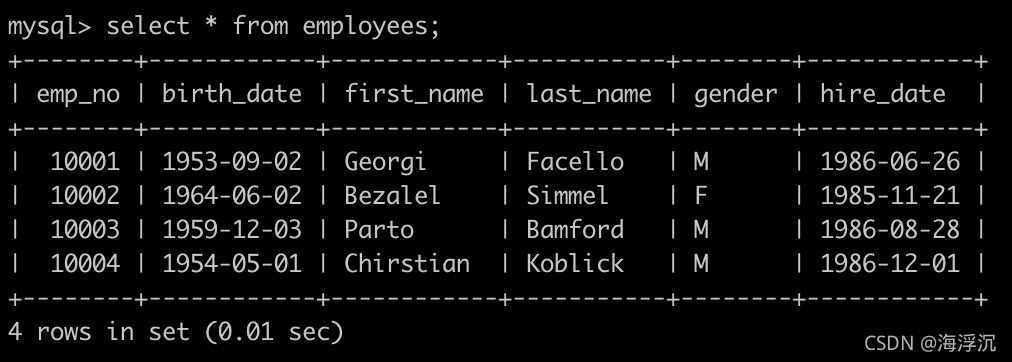
有一个部门表,dept_emp简况如下:
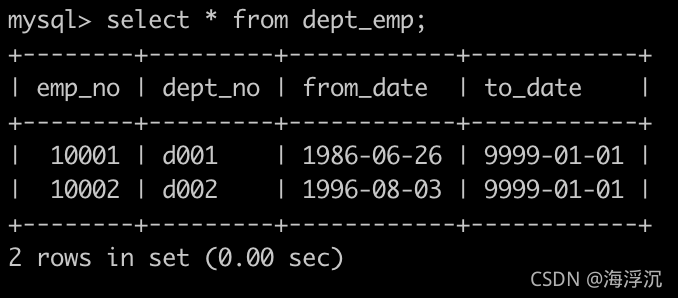
请你查找所有已经分配部门的员工的last_name和first_name以及dept_no,也包括暂时没有分配具体部门的员工,以上例子如下:
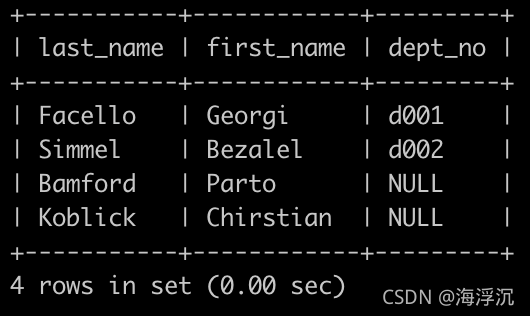
SELECT employees.last_name,employees.first_name,dept_emp.dept_no
FROM employees LEFT JOIN dept_emp
ON employees.emp_no =dept_emp.emp_no
思路:这里的关键是要将连接两表时不符合条件的数据也统计进来,用到了左连接LEFT JOIN,左连接的查询结果不仅包含符合链接条件的行,还包括左表中的所有数据行
4.查找薪水记录超过15次的员工号emp_no以及其对应的记录次数t
有一个薪水表,salaries简况如下: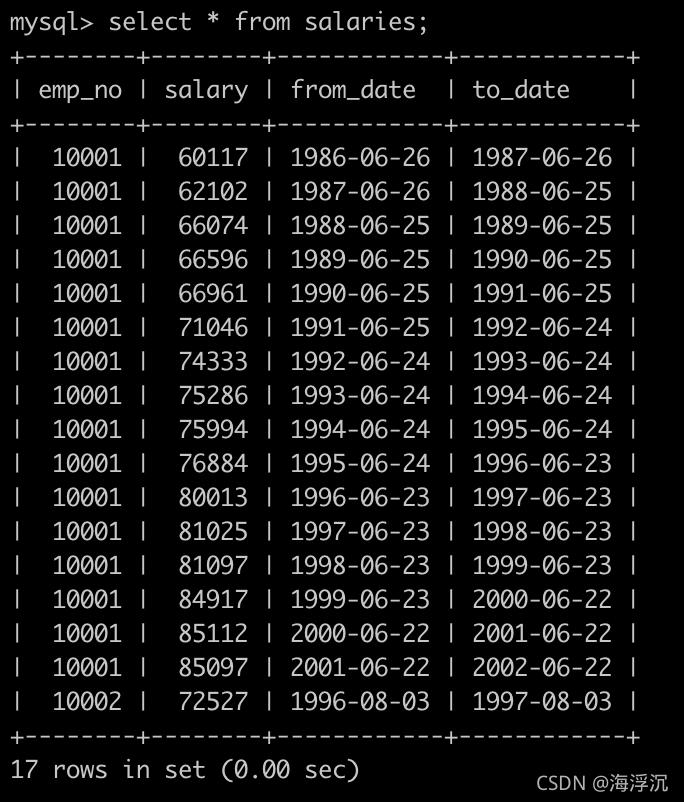
请你查找薪水记录超过15次的员工号emp_no以及其对应的记录次数t,以上例子输出如下:
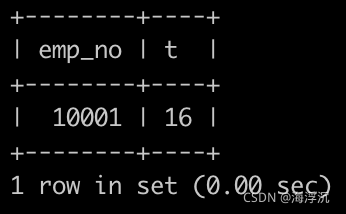
SELECT emp_no,COUNT(emp_no) FROM salaries
GROUP BY emp_no HAVING COUNT(emp_no)>15
思路:这里的关键是统计15次,我们用COUNT来实现。但是要注意的是,COUNT是一个聚合函数,是对结果集进行操作的。而WHERE是用于过程中的,所以WHERE COUNT这种用法是错误的,我们用HAVING来实现条件筛选。另外,表中存在相同员工的多条记录,我们用GROUP BY来实现分组统计,让结果集的员工只出现一次。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号