MySQL数据库基础
-
![]()
数据库xxx语言 CRUD 增删改查! CV程序猿 API程序猿 CRUD程序猿!(业务!)
DDL 定义
DML 操作
DQL 查询
DCL 控制
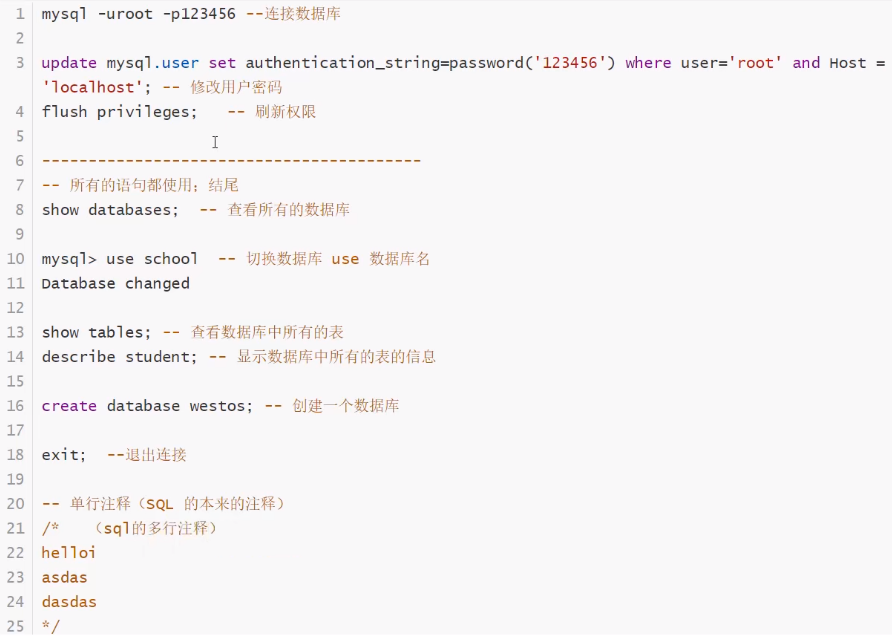
操作数据库(了解)
操作数据库>操作数据库中的表>操作数据库中表的数据
-
创建数据库
![]()
-
删除数据库
![]()
-
使用数据库
![]()
-
查看数据库
![]()




数据库的列类型
-
数值
![]()
-
字符串
![]()
-
char 和varchar的单位是字节 tinytext和text的单位是比特 一字节等于八个比特
-
-
时间日期
java.util.Date
![]()
-
null
![]()




数据库的字段属性(重点)
-
Unsigned
-
无符号的整数
-
声明了该列不能声明为负数
-
-
zerofill
-
0填充
-
不足的位数,使用0来填充,int(3),5---->005
-
-
自增
-
通常理解为自增,自动在上一条记录的基础上 +1(默认)
-
通常用来设计唯一的主键~ index,必须是整数类型
-
可以自定义设计主键自增的起始值和步长
-
-
非空 null not null
-
假设设置为not null,如果不给它赋值,就会报错!
-
null,如果不填写值,默认就是null
-
-
默认
-
设置默认的值!
-
sex,默认值为 男,如果不指定该列的值,则会有默认的值!
-
-
拓展
![]()

创建数据库表(重点)

-
格式:
![]()
-
常用命令:
![]()


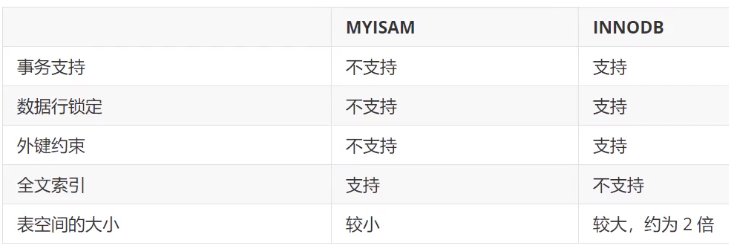
数据表的类型
-
数据库引擎
![]()
-
区别:
![]()
-
常规操作:
![]()
-
-
在物理空间存在的位置
-
所有的数据库文件都存在data目录下,一个文件夹就对应一个数据库
-
本质还是文件的存储!
-
-
MySQL引擎在物理文件上的区别
-
InnoDB 在数据库表中只有一个*.frm文件,以下上级目录下的ibdata1文件
-
MYISAM对应文件
-
*.frm 表结构的定义文件
-
*.MYD 数据文件(data)
-
*.MYI 索引文件(index)
-
-
-
-
设置数据库表的字符集编码
-
charset=utf8
-
不设置的话,会是MySQL默认的字符集编码~(不支持中文!)
-
MySQL的默认编码是Latin1,不支持中文
-
在my.ini中国配置默认的编码
character-set-server=utf8
-


修改删除表
-
修改
![]()
-
删除
![]()
-
所有的创建和删除操作尽量加上判断,以免报错~
-
注意点:
-
`` 所有字段名,使用这个包裹!
-
注释 -- /**/
-
sql关键字大小写敏感,建议写小写
-
所有的符号全部用英文!
-


MySQL数据管理
-
外键(了解)
-
方式一:在创建表的时候,增加约束(麻烦,比较复杂)
![]()
-
删除有关键关系的表的时候,必须要先删除引用别人的表(从表),再删除被引用的表(主表)
-
方式二:创建表成功后,添加外键约束
![]()
-
以上的操作都是物理外键,数据库级别的外键,我们不建议使用!(避免数据库过多造成困扰,这里了解即可~)
-
最佳实践
-
数据库就是单纯的表,只用来存数据,只有行(代表数据)和列(代表字段)
-
我们想使用多张表的数据,想使用外键(程序去实现)
-
-
-
DML语言(全部记)
-
数据库意义:数据存储和数据管理
-
DML语言:数据操作语言
-
insert
-
update
-
delete
-
-
-
添加
-
insert
![]()
![]()
-
-
修改
-
update
![]()
-
where 子句 运算符 id等于耨个值,大于某个值,在某个区间内修改
-
操作会返回布尔值
-
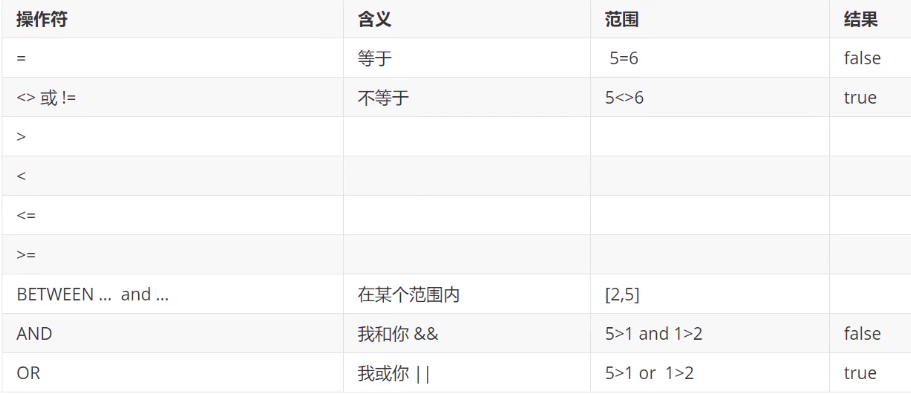
操作符
![]()
-
![]()
-
语法:
![]()
-
【注意】:
![]()
-
-
删除
![]()
-
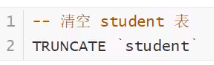
TRUNCATE命令
作用:完全清空一个数据库表,表的结构和索引约束不会变!
![]()
-
delete和TRUNCATE区别
![]()











DQL查询数据(最重点)
-
DQL
(Data Query LANGUAGE:数据查询语言)
-
所有的查询操作都用它 select
-
简单的查询,复杂的查询它都能做~
-
数据库中最核心的语言,最重要的语句
-
使用频率最高的语句
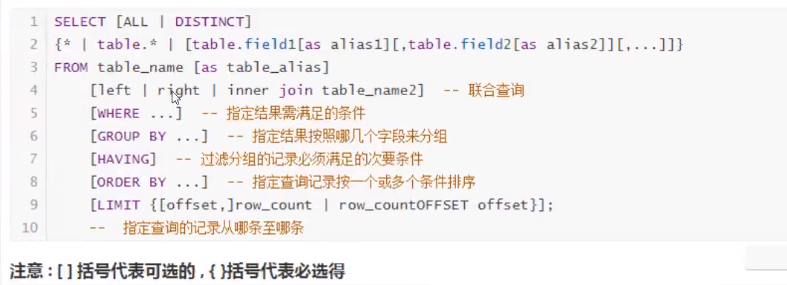
1.select完整的语法
![]()
-
-
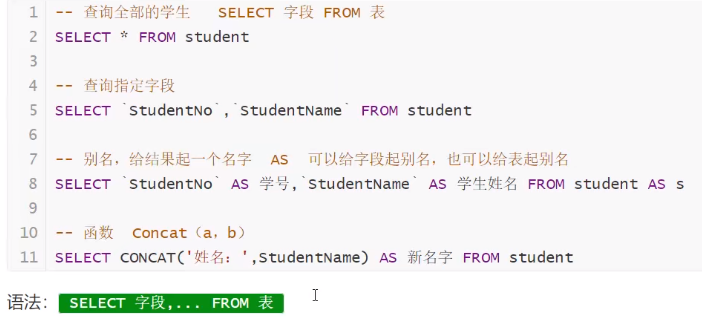
指定查询字段
![]()
-
有的时候,列名字不是那么的见名知意,我们就起别名,用as: 字段名 as 别名 ;表名 as 别名
-
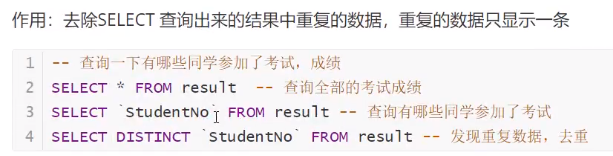
去重 distinct
![]()
-
数据库的列(表达式)
![]()
-
数据库中的表达式:文本值、列、null、函数、计算表达式、系统变量...
-
-
where条件子句
-
作用:检索数据中符合条件的值
-
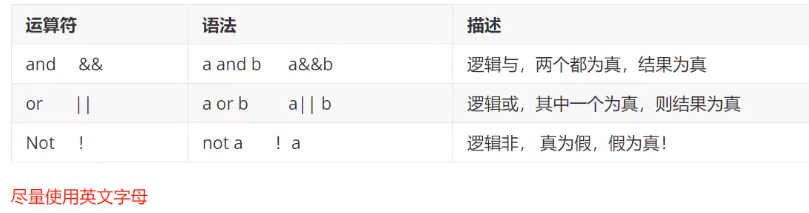
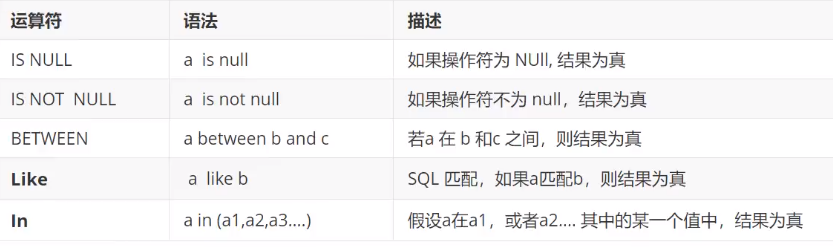
逻辑运算符
![]()
-
案例:
![]()
-
-
模糊查询:比较运算符
![]()
-
案例:
![]()
![]()
-
-
联表查询
-
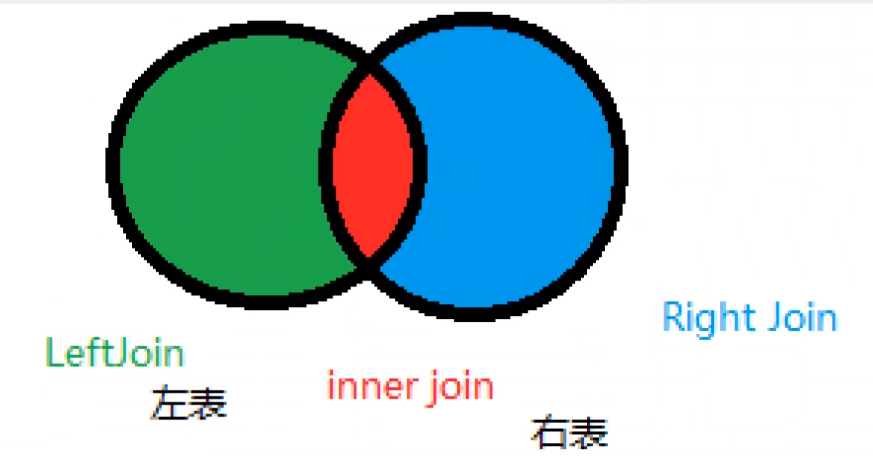
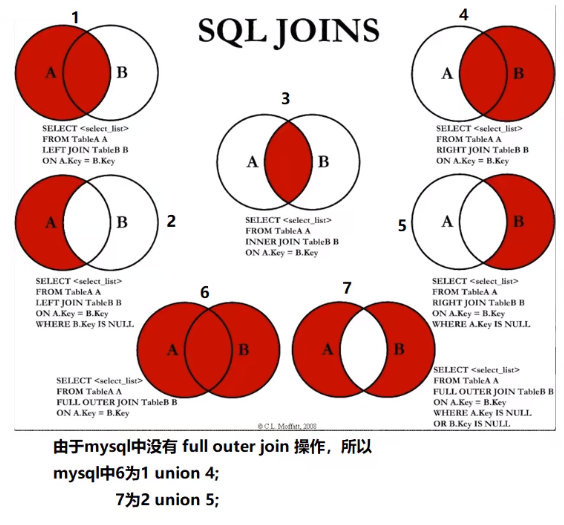
join对比
![]()
![]()
on是先筛选后关联,where是先关联后筛选
![]()
inner join 不会查出多余的字段,也不会查出空串!
-
案例:
![]()
![]()
![]()
![]()
-
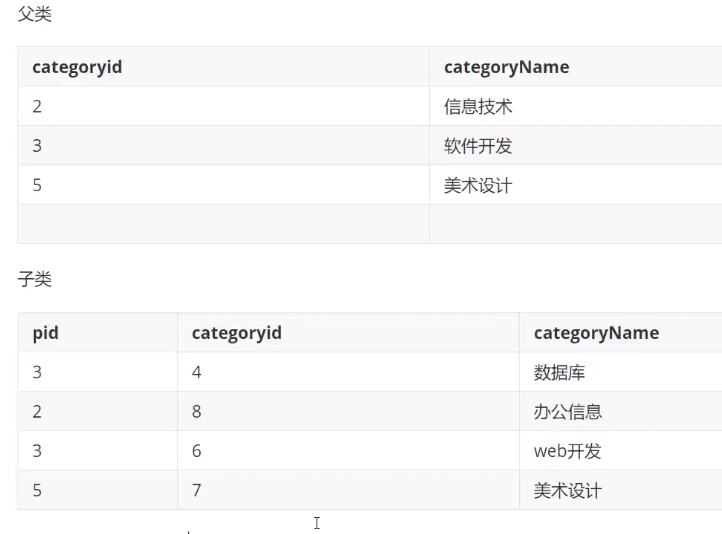
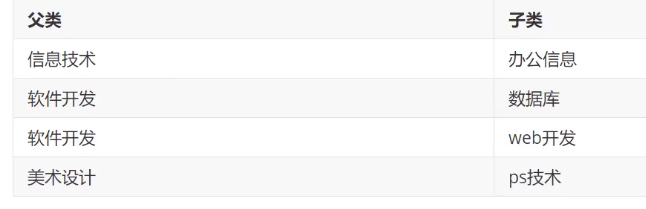
自连接
-
自己的表和自己的表连接,核心:一张表拆为两张一样的表即可
![]()
-
操作:查询父类对应的子类关系
![]()
-
代码实现
![]()
-
-
-
分页和排序
-
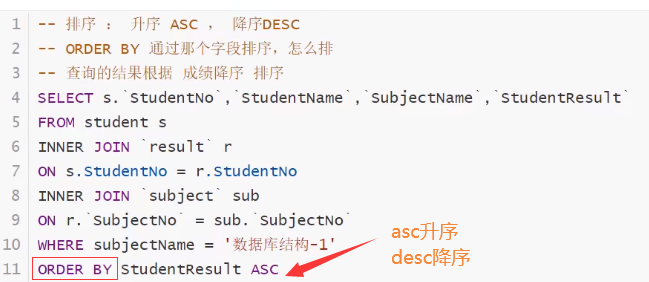
排序
![]()
-
分页
![]()
![]()
-
-
子查询
-
where(这个值是计算出来的)
![]()
-
案例:
![]()
![]()
![]()
![]()
-
-
-
分组和过滤
![]()


















MySQL函数
-
常用函数
![]()
![]()
![]()
-
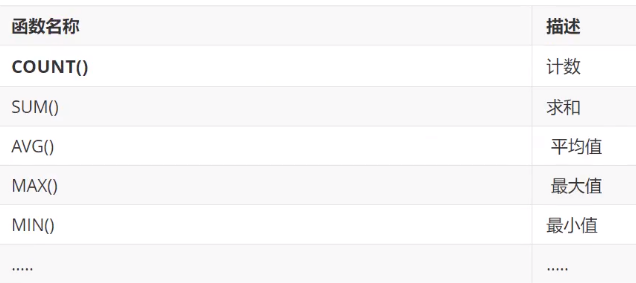
聚合函数(常用)
-
常用聚合函数
![]()
-
案例:
![]()
-
-
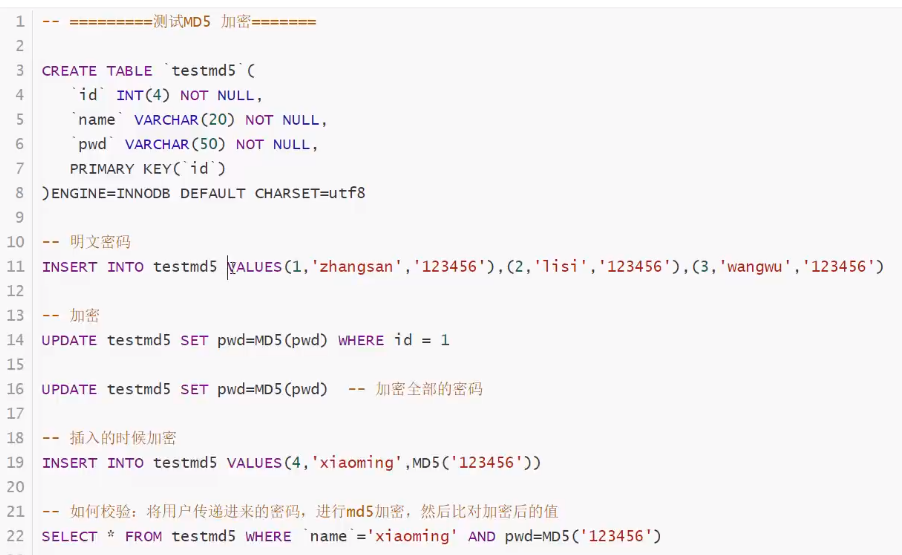
数据库级别的MD5加密(拓展)
-
什么是MD5?
-
主要增强算法复杂度和不可逆性
-
MD5不可逆,具体的值得MD5值是一样的
-
MD5破解网站的原理,背后有一个字典,MD5加密后的值,加密前的值
-
-
案例:
![]()
-




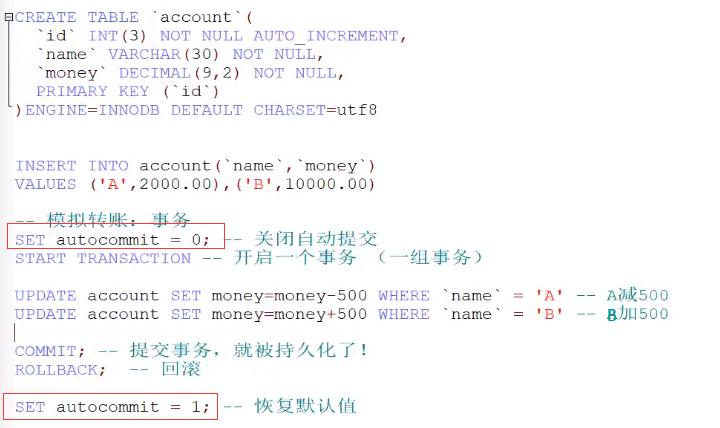
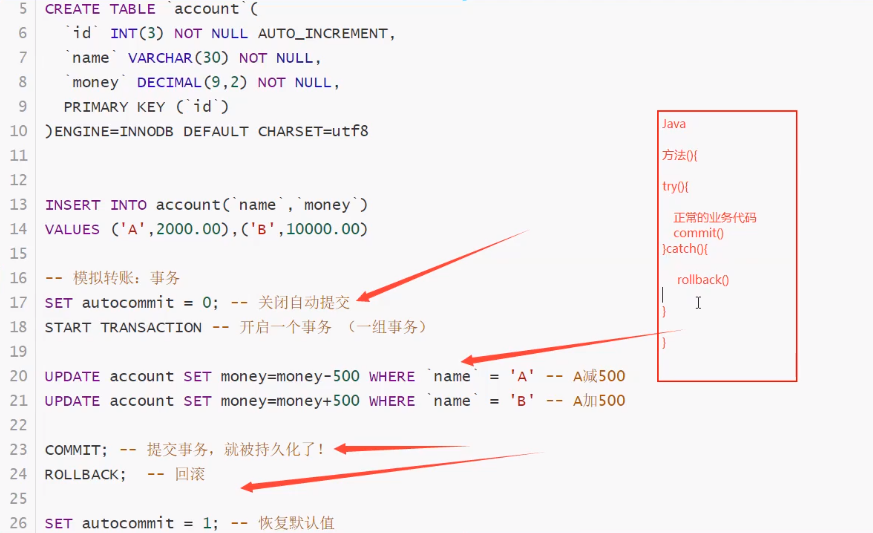
事务
-
什么是事务
要么都成功,要么都失败
![]()
将一组SQL放在一批次中去执行~
-
事务特性:ACID原则,一致性,隔离性,持久性 (脏读,幻读......)
-
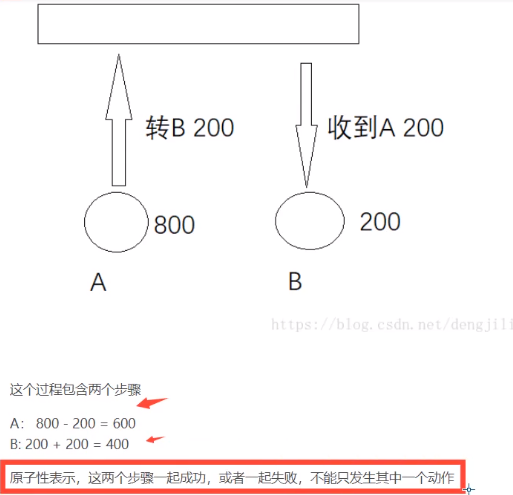
原子性 -- 要么都做,要么都不做!
![]()
-
一致性
![]()
-
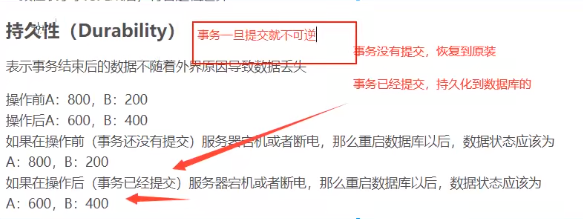
持久性
![]()
-
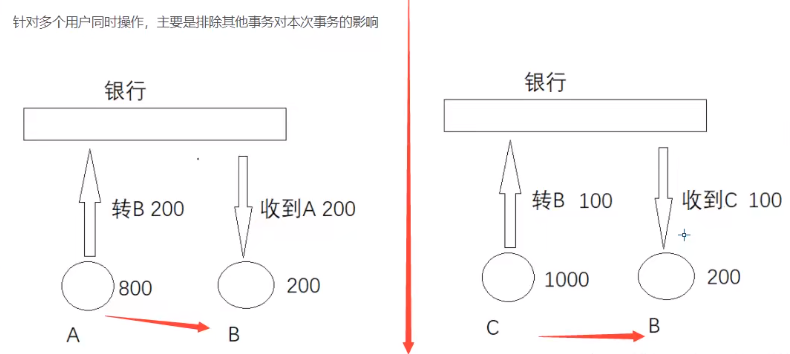
隔离性 -- 互不干扰
![]()
-
-
隔离所导致的问题
-
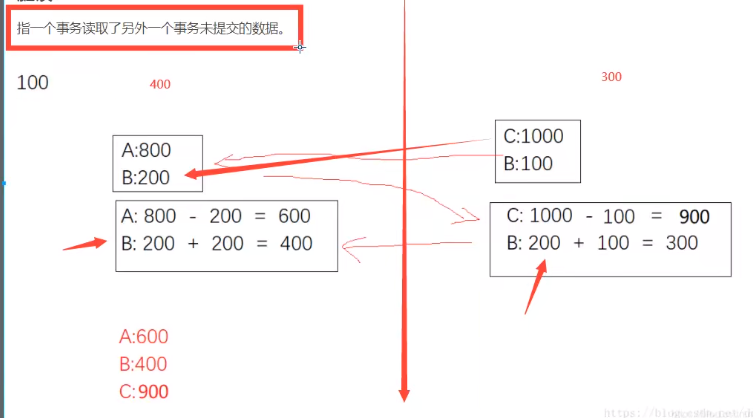
脏读
![]()
-
不可重复读
![]()
-
(虚读)幻读
![]()
-
-
案例:
![]()
![]()
-



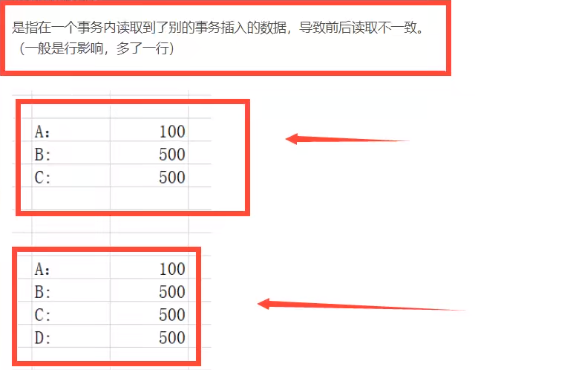
索引
MySQL官方对索引的定义为:索引(Index)是帮助MySQL高效获取数据的数据结构。
提取句子主干,就可以得到索引的额本质:索引是数据结构。
-
索引的分类
在一个表中,主键索引只能有一个,唯一索引可以有多个
![]()
-
基础语法:
![]()
-
-
测试索引
![]()
![]()
-
有索引:
![]()
-
无索引:
![]()
索引在小数据量的时候,用处不大,但是在大数据的时候,区别十分明显~
-
-
索引原则
-
索引不是越多越好
-
不要对经常变动数据加索引
-
小数据量的表不需要加索引
-
索引一般加在常用来查询的字段上!
-
索引的数据类型
-
Hash类型的索引
-
Btree:InnoDB的默认的数据结构~
-
阅读:
![]()
-
-







权限管理和备份
-
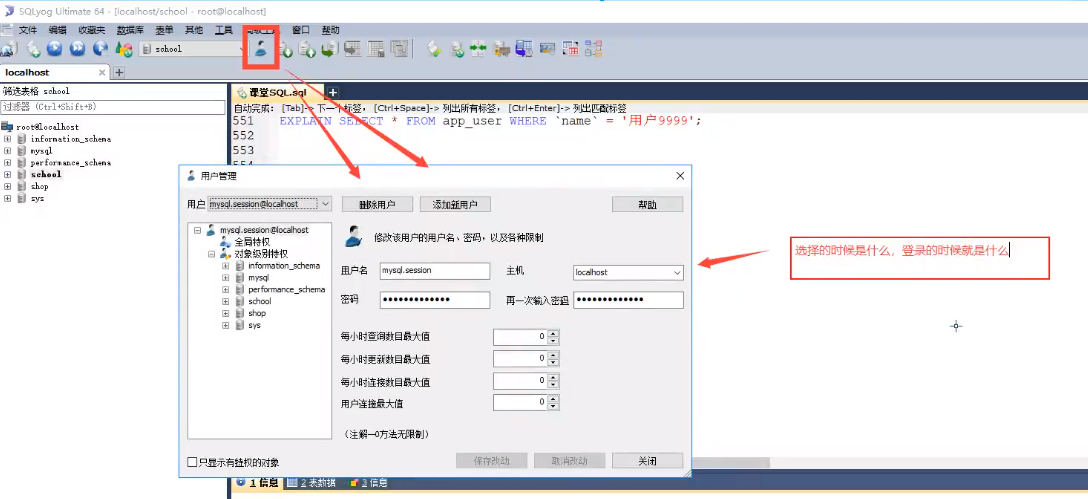
用户管理
-
SQL yog可视化管理
![]()
-
SQL命令操作
-
用户表:mysql.user
-
本质:对这张表进行增删改查
![]()
-
-
-
MySQL备份
-
为什么备份:
-
保证重要的数据不丢失
-
数据转移
-
-
MySQL数据库备份的方式
-
直接拷贝物理文件
-
在sqlyog这种可视化工具中手动导出
-
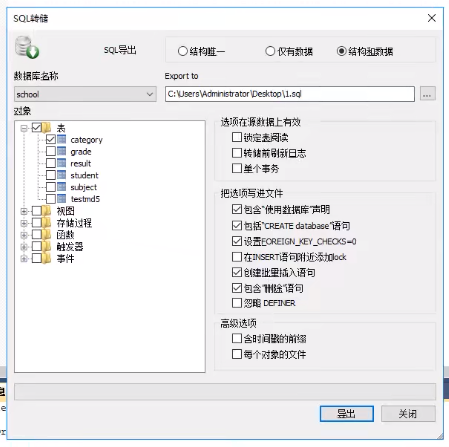
在想要导出的表或者库中,右键,选择备份或导出
![]()
-
-
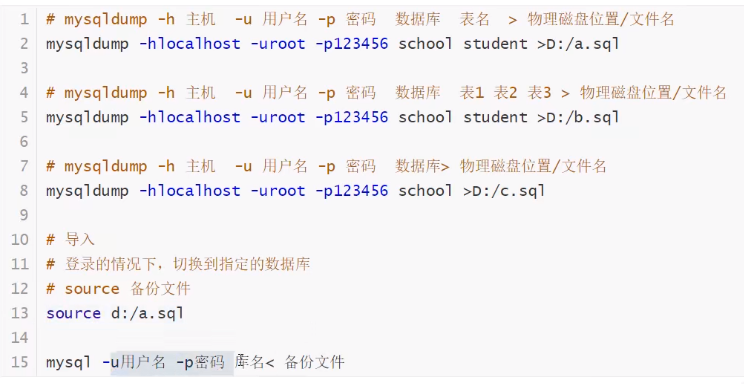
使用命令行导出 mysqldump 命令行使用
![]()
-
-
假设你要备份数据库,防止数据丢失。
把数据库给朋友!sql文件给别人即可!
-

规范数据库设计
-
为什么需要设计
当数据库比较复杂的时候,我么就需要设计了
-
糟糕的数据库设计:
-
数据冗余,浪费空间
-
数据插入和删除都会麻烦、会产生异常【屏蔽使用物理外键】
-
程序的性能差
-
-
良好的数据库设计:
-
节省内存空间
-
保证数据库的完整性
-
方便我们开发系统
-
-
软件开发中,关于数据库的设计
-
分析需求:分析业务和需要处理的数据库的需求
-
概要设计:设计关系图E-R图
-
-
设计数据库的步骤:(个人博客)
-
收集信息,分析需求
-
用户表(用户登录注销,用户的个人信息,写博客,创建分类)
-
分类表(文章的分类,谁创建的)
-
文章表(文章的信息)
-
评论表
-
友链表(友链信息)
-
自定义表(系统信息,某个关键的字,或者一些主字段) key:value
-
说说表(发表心情... id...contennt...create_time)
-
-
标识实体(把需求落到每个地段)
-
标识实体之间的关系
-
写博客:user-->blog
-
创建分类:user-->category
-
关注:user->user
-
友链:links
-
评论:user-user-blog
-
-
-
-
三大范式
-
为什么需要数据规范化?
-
信息重复
-
更新异常
-
插入异常
-
无法正常显示信息
-
-
删除异常
-
丢失有效信息
-
-
-
三大范式
-
第一范式
-
原子性:保证每一列不可再分
-
-
第二范式
-
前提:满足第一范式
-
每张表只描述一件事情
-
-
第三范式
-
前提:满足第一范式和第二范式
-
需要确保数据表中的每一列数据都和主键直接相关,而不能间接相关。
-
-
-
规范性和性能的问题
-
关联查询的表不得超过三张表
![]()
-
-

JDBC(重点)
-
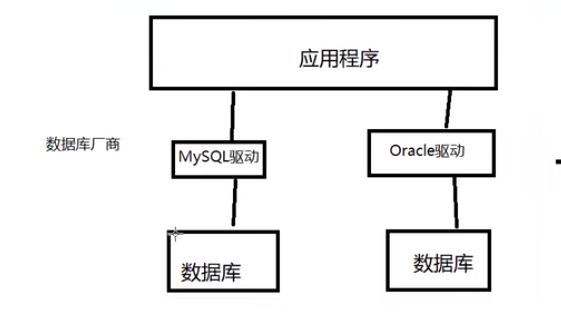
数据库驱动
-
驱动:声卡、显卡、数据库
![]()
-
我们的程序会通过数据库驱动和数据库打交道!
-
-
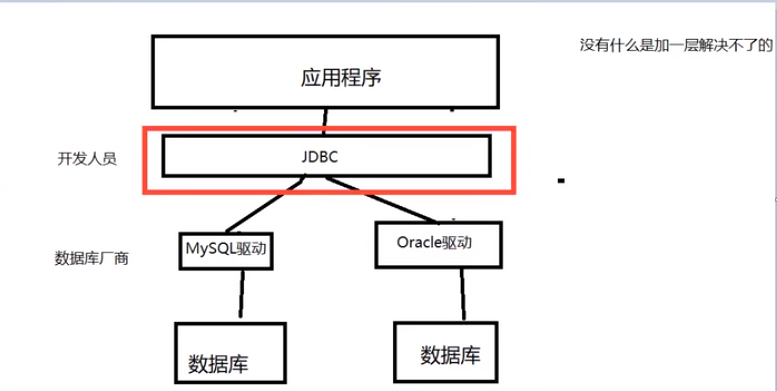
JDBC
-
SUN公司为了简化开发人员的(对数据库的统一)操作,提供了一个(Java操作数据库的)规范,俗称JDBC。
-
这些规范的实现由具体的厂商去做~
-
对于开发人员来说,我们只需要掌握JDBC接口的操作即可!
![]()
-
需要的包:
![]()
-
-
第一个JDBC程序
-
创建一个普通项目
-
导入数据库驱动
![]()
-
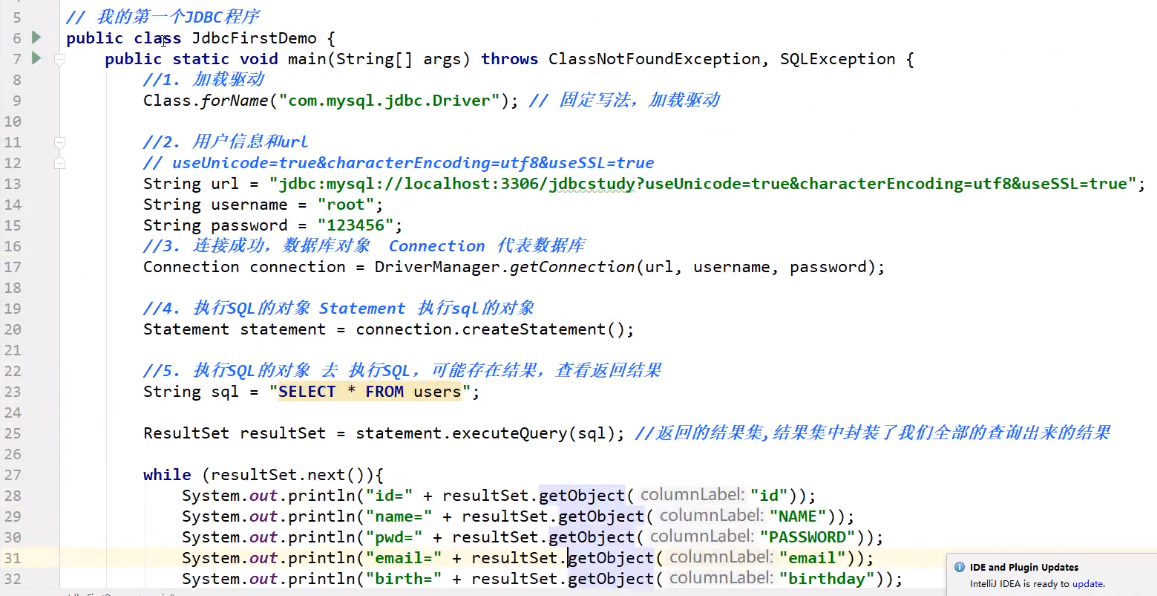
编写测试代码:
口诀:贾琏欲执事(加连预执释) 引入依赖,加载驱动 连接数据库 创建预编译语句 设置参数,执行sql 关闭连接,释放资源
-
程序:
![]()
![]()
-
步骤总结:
![]()
-
DriverManager
![]()
-
URL
![]()
-
Statement执行SQL的对象 PrepareStatement 执行SQL的对象
![]()
-
ResultSet查询的结果集:封装了所有的查询结果
获得指定的数据类型
![]()
-
遍历,指针
![]()
-
释放资源
![]()
-
-
statement对象
![]()
-
CRUD操作-create
![]()
-
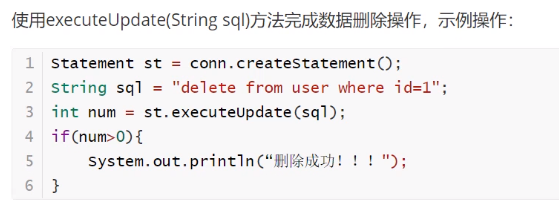
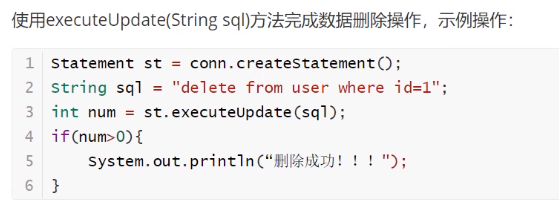
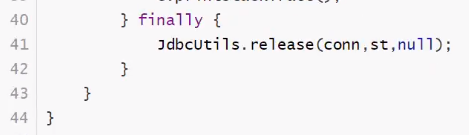
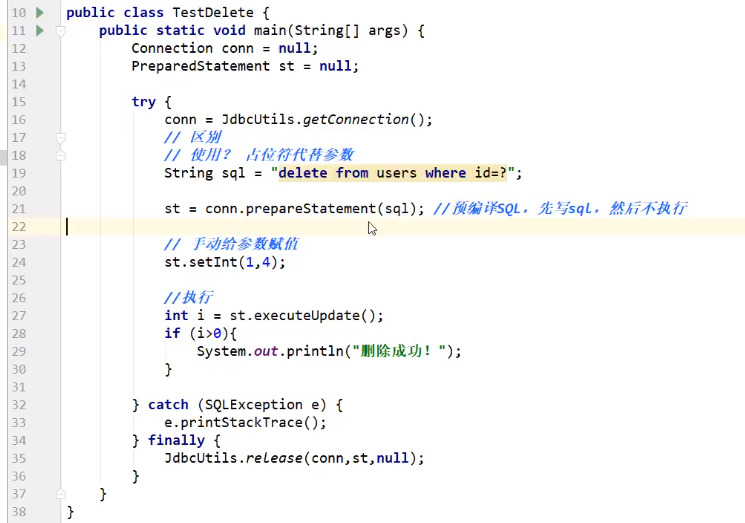
CRUD操作-delete
![]()
-
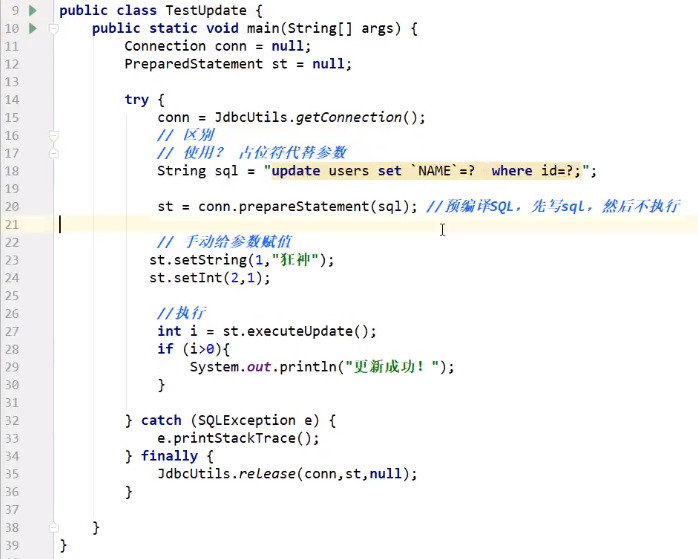
CRUD操作-update
![]()
-
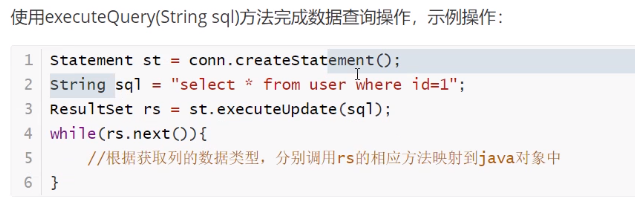
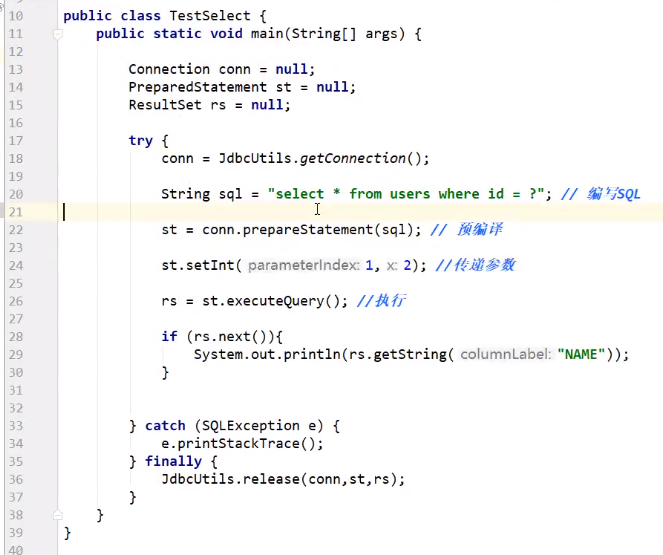
CRUD操作-read
![]()
-
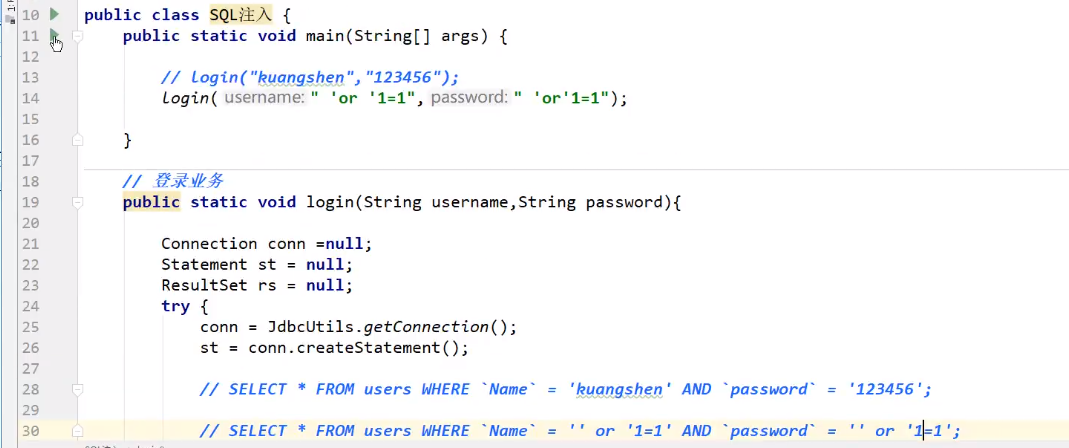
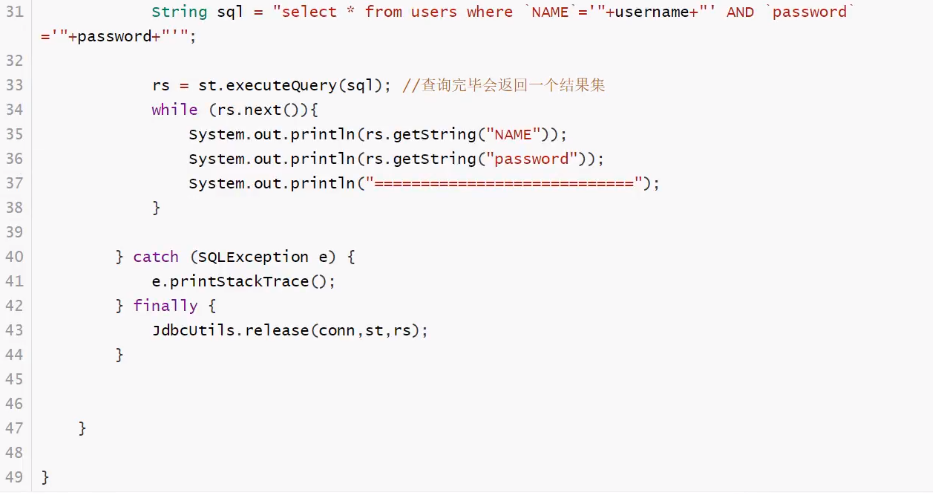
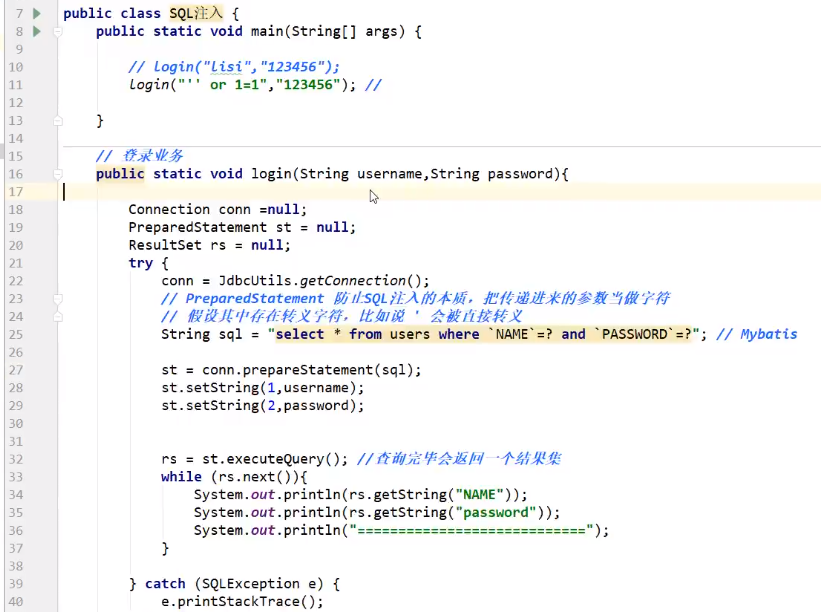
SQL注入的问题
-
sql存在漏洞 ,会被攻击导致数据泄露,SQL会被拼接 or
![]()
![]()
-
-
PreparedStatement对象
PreparedStatement可以防止SQL注入。效果更好!
-
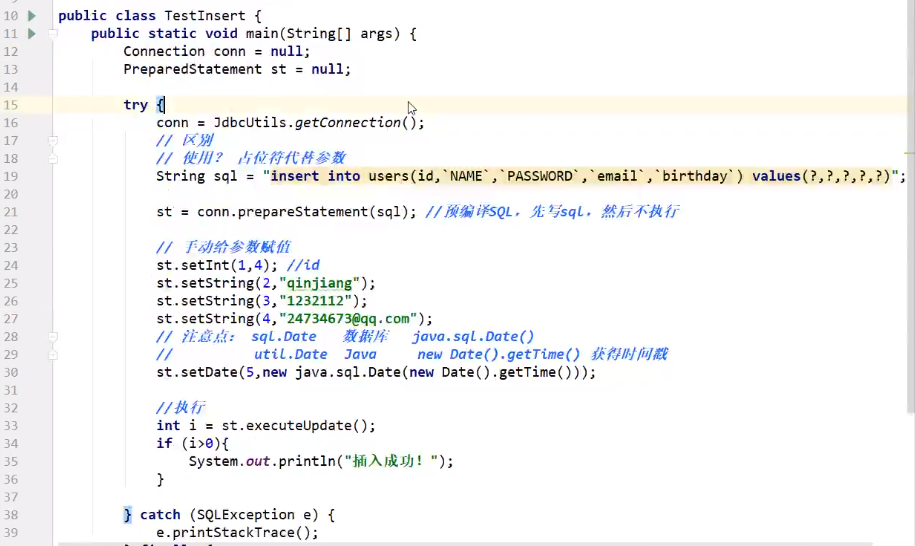
新增
![]()
![]()
-
删除
![]()
-
更新
![]()
-
查询
![]()
-
防止SQL注入
![]()
![]()
-
-
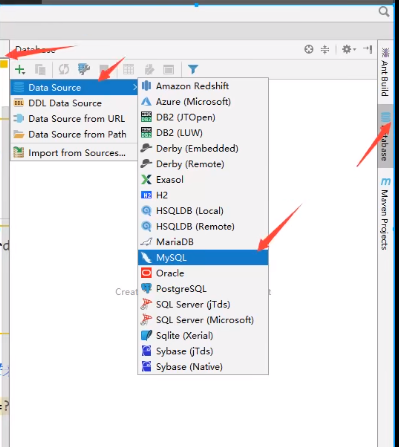
使用IDEA连接数据库
-
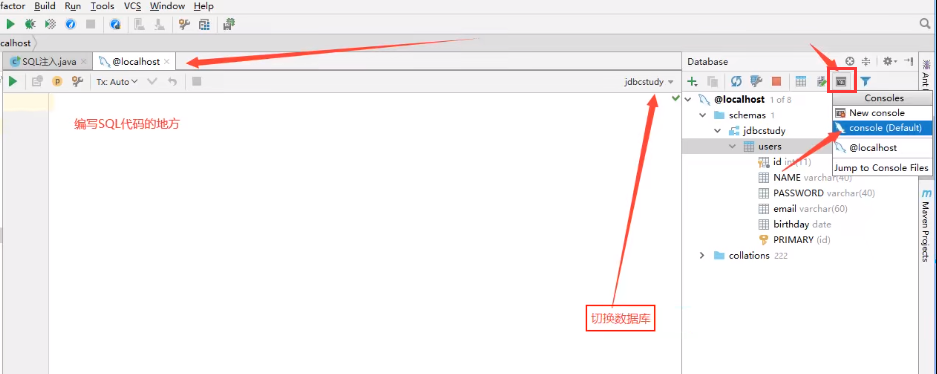
连接数据库
![]()
-
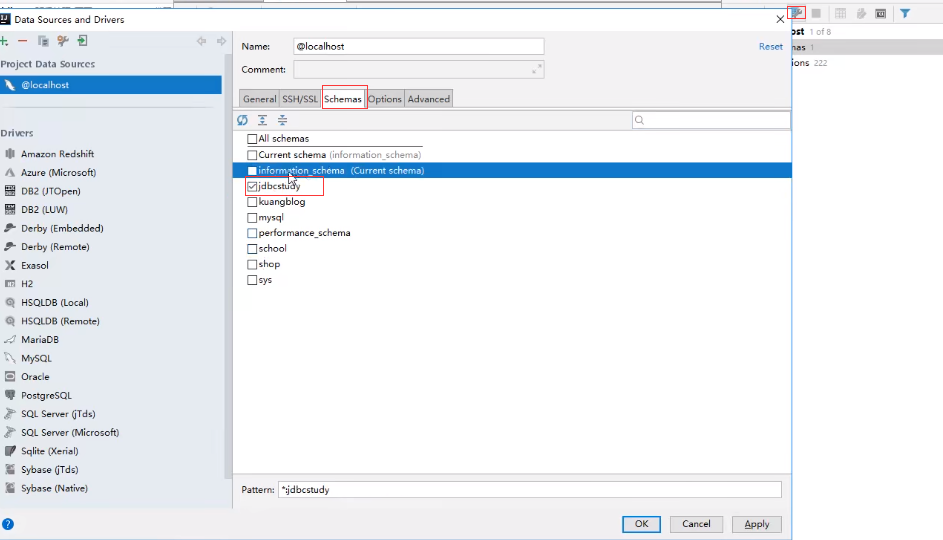
连接成功后,可以添加数据库
![]()
-
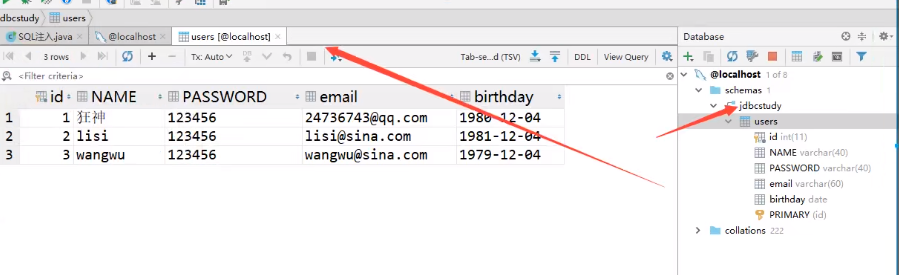
双击数据库
![]()
-
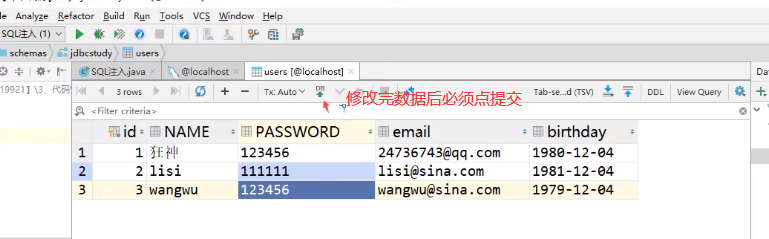
更新数据
![]()
-
编写数据库代码
![]()
-
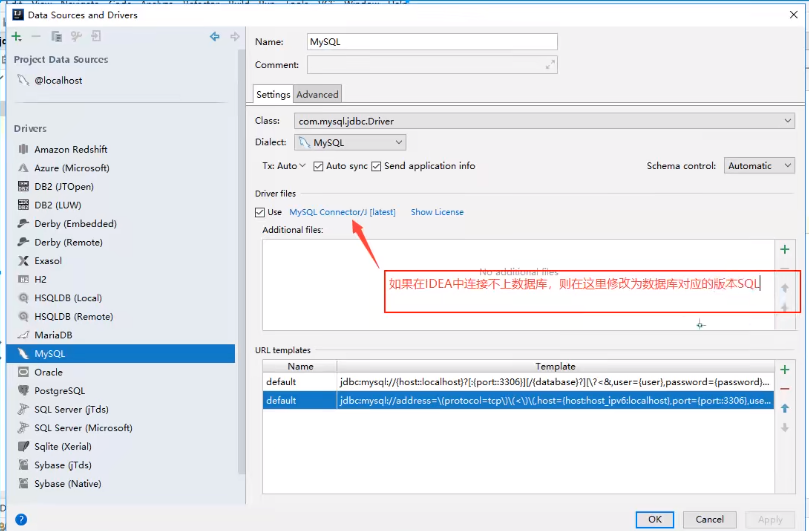
连接失败,查看原因
![]()
-
-
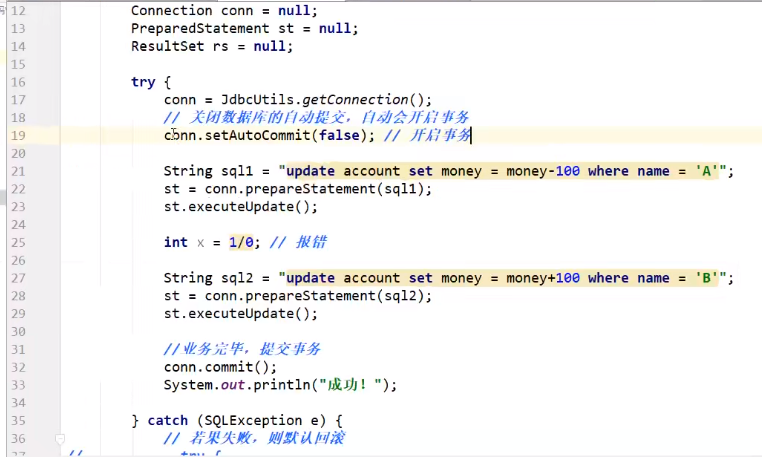
事务
要么都成功,要么都失败!
-
ACID原则
![]()
-
隔离性的问题:
![]()
-
代码实现
![]()
![]()
![]()
-
-
数据库连接池
-
数据库连接 -- 执行完毕 -- 释放
-
连接 -- 释放十分浪费系统资源
-
池化技术:准备一些预先的资源,过来就连接预先准备好的
-
最小连接数
-
最大连接数
-
等待超时
-
-
编写连接池。实现一个接口 DataSource
-
开源数据源实现
-
DBCP
-
C3P0
-
Druid:阿里巴巴
-
-
使用了这写数据库连接池之后,我们在项目中就不需要编写连接数据库的代码了!
-
DBCP
-
需要用到的jar包
![]()
-
-
C3P0
-
需要用到的jar包
![]()
-
-
结论
无论使用什么数据源,本质还是一样的,DataSource接口不会变,方法就不会变。
-
-
-

















参考链接:https://www.bilibili.com/video/BV1NJ411J79W?p=28

 浙公网安备 33010602011771号
浙公网安备 33010602011771号