Reinforcement Tuning for Detecting Stances and Debunking Rumors Jointly with Large Language Models
论文信息
论文标题:Reinforcement Tuning for Detecting Stances and Debunking Rumors Jointly with Large Language Models
论文作者:杨瑞超, 高伟, 马静, 林宏展, 王博
论文来源:ACL 2024
发布时间:2024 年 6 月 4 日
论文地址:link
论文代码:link
摘要
-
核心挑战:联合检测立场(SD)与验证谣言(RV)的多任务模型(JSDRV)面临训练数据难题 —— 需立场的帖子级数据与谣言真实性的声明级数据,两类数据均难获取。
-
解决方案:以大型语言模型(LLMs)作为基础标注器,为 JSDRV 任务提供数据;同时提出新型强化调优框架,提升 LLM 在 SD 和 RV 组件上的联合预测能力。
-
关键设计:设计数据选择策略,筛选 LLM 标注的两级数据;采用混合奖励机制挑选高质量标签,用于 LLM 在两任务上的有效微调。
-
实验结果:JSDRV 提升了 LLM 在联合任务中的性能,不仅优于现有最优方法,还能泛化至适配为任务模型的非 LLM 模型。
1 介绍
1.1 研究动机
1. 社交媒体谣言的社会危害
社交媒体因信息传播迅速的特性,已成为谣言和错误信息滋生的 “温床”—— 由于缺乏系统性的内容审核机制,谣言的泛滥传播已成为全球性社会问题,会深刻影响公众认知、信念乃至正常生活。例如,虚假健康谣言可能导致公众误解医疗常识,政治类谣言可能引发社会信任危机等,这些危害凸显了谣言检测与验证的迫切需求。1
2. 立场与谣言的深度关联
立场(Stance)反映了个体对特定目标的态度、观点和信念,而社交媒体帖子对谣言主张的立场(如支持、否认、质疑),是评估该主张可信度的重要线索。直观来看,通过分析帖子立场,不仅能理解谣言传播的上下文,还能掌握不同用户对谣言的感知方式,为谣言验证提供可解释的依据(如图 1 中,针对 “梅拉尼娅威胁离婚” 的虚假主张,不同帖子的立场可辅助判断该主张的虚假性)。
3. 现有联合任务方法的局限性
当前研究虽已关注 “立场检测(SD)- 谣言验证(RV)” 联合任务,但存在显著瓶颈:
-
标注数据依赖严重:多数方法需要大量 “帖子级立场标签” 和 “主张级真实性标签” 用于训练,而这类标注需人工完成,成本极高、获取难度大。3
-
无监督 / 弱监督方法泛化性差:部分无监督方法仅针对立场检测单任务,且依赖特定手工特征或与社交媒体谣言立场不匹配的预训练数据(如在线辩论数据),导致泛化能力弱;弱监督方法(如基于多实例学习的模型)虽仅用主张真实性标签,但通过 “将主张真实性分散到单个帖子立场” 来推断立场的方式,比 “通过聚合帖子立场推断主张真实性” 更具挑战性,效果有限。4
-
LLM 潜力未被充分挖掘:ChatGPT、Llama 等 LLM 在多种 NLP 任务中表现出接近或超越人类的性能,但在社交媒体场景下的 “立场 - 谣言” 联合任务中,其能力尚未被深入研究 —— 一方面,LLM 的预训练知识和零样本 / 少样本能力可能适配该任务;另一方面,社交媒体帖子中的噪声、不可靠性及缺乏监督信号,可能削弱其预测能力,且如何利用 LLM 生成高质量标注并用于联合任务训练,仍是未解决的问题。
1.2 研究问题
1. 核心问题:低标注成本下的 “立场 - 谣言” 联合任务优化
在仅提供少量人工标注的主张级真实性标签(无帖子立场标签) 的约束下,如何设计框架,充分利用 LLM 的能力,实现 “立场检测” 与 “谣言验证” 的高效联合训练,同时保证模型在两类任务上的性能,且能泛化到非 LLM 模型(如 BERT)?
2. 具体子问题
1)LLM 标注质量与筛选问题
-
- 若直接用 LLM 对大量帖子和主张进行标注,可能因 LLM 输出的不确定性导致标注质量参差不齐,如何设计策略筛选出高质量 LLM 标注实例,避免低质量标注影响模型训练?7
2)任务间协同与优化问题
-
- 立场检测与谣言验证存在相互依赖关系(立场辅助谣言验证,谣言真实性可能反哺立场判断),如何构建端到端的联合优化机制,让 SD 网络与 RV 网络相互促进,而非独立训练?8
3)数据采样效率问题
-
- 社交媒体中单个谣言主张对应的帖子数量可能极多(如部分主张对应数百条帖子),若对所有帖子进行处理,会导致计算成本过高,如何设计高效的采样策略,在平衡 “探索(随机采样)” 与 “利用(按时间顺序采样)” 的同时,减少冗余计算?9
4)奖励机制设计问题
-
- 在强化学习框架中,如何设计合理的奖励函数,既能基于少量人工标注数据评估实例质量,又能引导选择器筛选出对两类任务均有帮助的实例(如对主张真实性预测贡献大的帖子立场)
2 问题定义
2.1 数据集定义
定义谣言数据集为 $C = \{(c_{i}, X_{i})\}_{i=1}^{|C|}$ ,其中每个实例 $(c_{i}, X_{i})$ 由两部分组成:
-
-
源主张(Source Claim): $c_{i}$ ,即待验证的谣言相关核心陈述(如 “梅拉尼娅・特朗普威胁与唐纳德・特朗普离婚并索要 20 亿美元离婚协议”)。
-
对话线程(Conversation Thread): $X_{i} = \{x_{i, 1}, x_{i, 2}, \cdots, x_{i, T}\}$ ,指针对主张 $c_{i}$ 的所有响应帖子集合。帖子需满足两个特征:① 按时间顺序排列;② 可能包含 “@用户” 符号以体现回复结构(即帖子间的交互关系)。
-
2.2 两大核心任务定义
2.2.1 立场检测(Stance Detection, SD)
任务目标
对主张 $c_{i}$ 对应的每个帖子 $x_{i, j} \in X_{i}$ ,判定其对 $c_{i}$ 的立场标签 $y_{i, j}$ 。
数学表达
函数映射关系为: $f: x_{i, 1}x_{i, 2}\cdots x_{i, T} \to y_{i, 1}y_{i, 2}\cdots y_{i, T}$ 。
立场标签体系
立场标签包含 4 类,覆盖社交媒体中用户对谣言主张的典型态度:
-
-
支持(Support, S):帖子认可主张的真实性(如 “这事儿早就该发生了”);
-
否认(Deny, D):帖子质疑或否定主张的真实性(如 “别再胡说八道了,没人信”);
-
质疑(Question, Q):帖子对主张的来源、证据等提出疑问(如 “来源呢?这些邮件公开了吗”);
-
评论(Comment, C):帖子仅对主张进行客观评述,不明确表达支持 / 否认 / 质疑(如 “这是终结的开始🤣”)。
-
2.2.2 谣言验证
任务目标
结合主张 $c_{i}$ 及其对应的所有响应帖子 $X_{i}$ ,将 $c_{i}$ 分类为指定的真实性标签 $Y_{i}$ 。
数学表达
函数映射关系为: $g:(c_{i}, X_{i}) \to Y_{i}$ 。
真实性标签体系
真实性标签包含 4 类,覆盖谣言的不同验证状态:
-
-
非谣言(Non-Rumor, N):主张为真实信息,不属于谣言;
-
真谣言(True Rumor, T):主张经验证为真实,且被广泛传播的谣言(注:此处 “真谣言” 指内容真实的谣言类信息,非矛盾表述,需结合上下文理解为 “真实的待验证主张”);
-
假谣言(False Rumor, F):主张经验证为虚假信息;
-
未验证谣言(Unverified Rumor, U):主张的真实性暂无法通过现有信息确认。
-
2.2.3 与现有研究的场景差异
现有研究对标注数据的依赖分为两类:
-
全监督场景:假设训练集中所有实例的 “帖子立场标签 $y_{i, 1}\cdots y_{i, T}$ ” 和 “主张真实性标签 $Y_{i}$ ” 均已标注(如 Ma et al., 2018;Kochkina et al., 2018 等);
-
弱监督场景:仅假设训练集中所有实例的 “主张真实性标签 $Y_{i}$ ” 已标注,无 “帖子立场标签”(如 Yang et al., 2022)。
本文目标场景更具挑战性:仅提供少量人工标注的主张子集 $C' \subseteq C$ (满足 $|C'| \ll |C|$ ),即仅知晓极小部分主张的真实性标签,无任何帖子立场标签,需在该约束下完成两大任务的联合训练。
3 方法
3.1 框架核心定位与整体逻辑
3.1.1 设计背景
现有 LLM 在 “立场检测(SD)- 谣言验证(RV)” 联合任务中面临两大核心问题:
-
人工标注数据稀缺(尤其是帖子级立场标签),且标注成本高、计算资源有限导致难以充分利用数据;
-
LLM 自动标注质量不可控,直接使用可能引入噪声影响模型性能。基于此,JSDRV 框架以 “少量人工标注的主张级真实性标签” 为种子,通过强化学习实现 “数据标注 - 实例筛选 - 模型微调” 的端到端联合优化,解决上述痛点;
3.1.2 框架三大核心模块
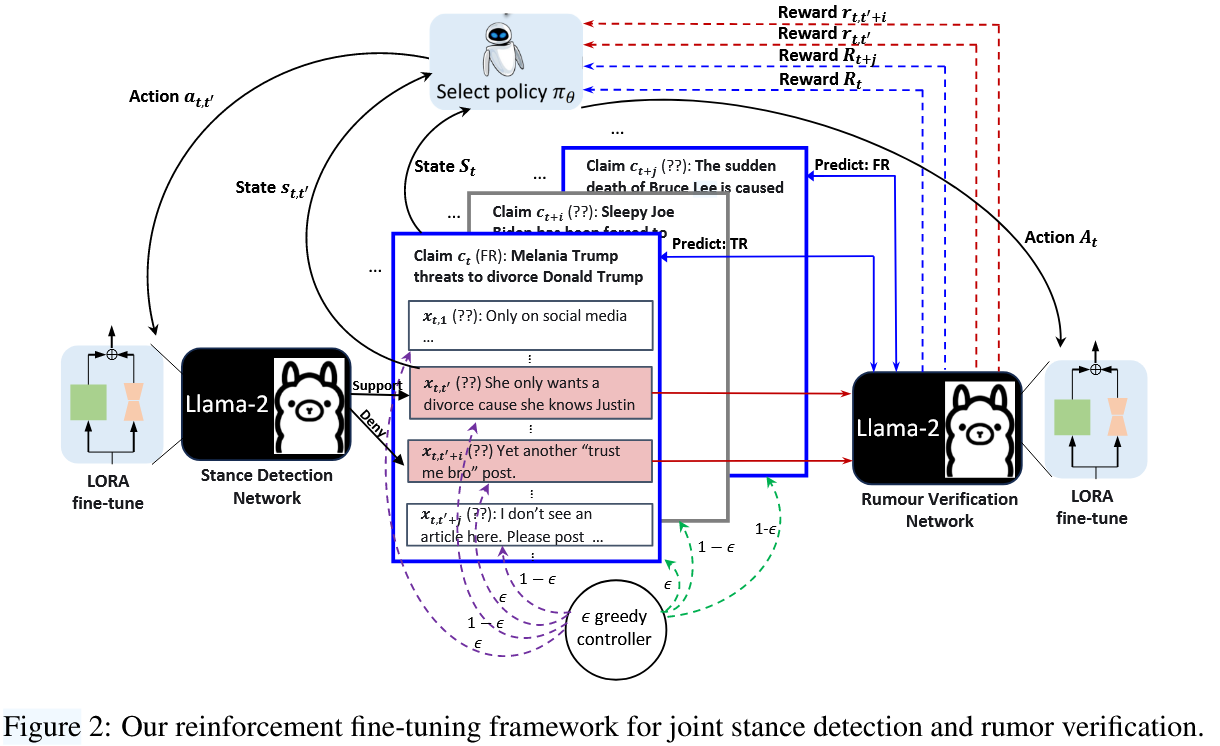
JSDRV 框架包含三个互补模块,整体结构如图 2 所示:
-
LLM 立场检测(SD)网络:对主张对应的帖子进行立场标注,输出 “立场标签 + 解释”;
-
强化选择器(Selector Policy):筛选 SD 网络标注的高质量帖子实例,以及待验证的主张实例,为 RV 网络提供有效输入;
-
LLM 谣言验证(RV)网络:结合筛选后的帖子及立场信息,对主张进行真实性标注,输出 “真实性标签 + 解释”。
3.1.3 基础模型与技术选型
-
核心 LLM:采用开源的 Llama-2 7B 模型 作为 SD 和 RV 网络的基础模型,支持通过 LoRA(Low-Rank Adaptation)等参数高效微调(PEFT)技术降低计算成本;框架具备通用性,可兼容闭源 LLM(如 GPT-3.5/4)及非 LLM 模型(如 BERT)。
-
关键技术:融合零样本 / 少样本提示学习 与 强化学习策略,平衡数据利用率与标注质量。
3.2 LLM 立场检测网络
3.2.1 模块核心目标
针对给定主张 $c_t$ 对应的帖子集合 $X_t$ ,为每个帖子生成高质量的立场标签(支持 S / 否认 D / 质疑 Q / 评论 C)及标注解释,同时通过高效采样降低计算开销,为后续实例筛选提供基础数据。
3.2.2 帖子预选择:ϵ- 贪心控制器
由于帖子集合 $X_t$ 规模可能极大(部分主张对应数百条帖子),需先通过ϵ- 贪心策略预筛选帖子,平衡 “利用(Exploitation)” 与 “探索(Exploration)”:
-
利用逻辑:以概率 $\epsilon$ 按时间顺序选取下一条帖子( $Next(X_t)$ ),优先选择与主张时效性强的内容;
-
探索逻辑:以概率 $1-\epsilon$ 从所有帖子中随机选取( $Uniform(X_t)$ ),避免因时间偏差遗漏关键立场;
-
数学表达:
$\tilde{x}_{t, t'} \sim \begin{cases} Next\left(X_{t}\right) & with\ prob\ \epsilon \\ Uniform\left(X_{t}\right) & with\ prob\ 1-\epsilon \end{cases}$
其中,
-
-
- $\tilde{x}_{t,t'}$ 为第 $t'$ 步采样的帖子,采样过程为 “无放回” 以避免重复。
-
3.2.3 立场提示学习
通过设计结构化 Prompt 引导 LLM 生成立场标签及解释,确保输出格式统一、可解析:
-
Prompt 设计逻辑:明确告知主张内容、帖子内容、立场标签选项(S/D/Q/C)及输出格式(“Stance: [标签], Reason: [解释]”);
-
示例:针对主张 “The University of Ottawa is on lockdown”,Prompt 会要求 LLM 判断帖子 “My Alma Mater. God.” 的立场为 “Comment”,并解释 “用户仅表达个人情感,未针对封锁主张的真实性表态”(如图 4 所示)。

3.2.4 预训练增强(Pretraining)
为提升 LLM 初始标注质量,使用P-stance 数据集(Li et al., 2021b)对 SD 网络进行预训练:
-
-
数据集特性:P-stance 是政治领域的通用立场数据集,含 3 类立场标签(与本文 4 类标签兼容);
-
训练目标:最小化 “负条件语言建模损失”,让 LLM 学习立场分类的基础逻辑,减少零样本场景下的标注误差;
-
3.3 LLM 谣言验证网络(RV)
3.3.1 模块核心目标
结合强化选择器筛选后的 “主张 + 帖子 - 立场对”,为主张生成真实性标签(非谣言 N / 真谣言 T / 假谣言 F / 未验证 U)及解释,核心是利用立场信息提升验证准确性。
3.3.2 主张预选择:ϵ- 贪心策略延伸
与帖子预选择逻辑一致,通过ϵ- 贪心策略筛选主张,平衡 “人工标注主张” 与 “未标注主张” 的采样:
-
-
利用逻辑:以概率 $\epsilon$ 从人工标注主张集合 $C'$ 中随机选取( $Uniform(C')$ ),依托真实标签优化模型;
-
探索逻辑:以概率 $1-\epsilon$ 从未标注主张集合 $C-C'$ 中随机选取( $Uniform(C-C')$ ),提升模型泛化性;
-
数学表达:
-
$\tilde{c}_{t} \sim \begin{cases} Uniform\left(\mathcal{C}'\right) & with\ prob\ \epsilon \\ Uniform\left(\mathcal{C}-\mathcal{C}'\right) & with\ prob\ 1-\epsilon \end{cases}$
其中,$\tilde{c}_t$ 为第 $t$ 步采样的主张。
3.3.3 真实性提示学习
基于 “主张 + 筛选后的帖子立场” 设计 Prompt,引导 LLM 生成真实性标签及解释:
-
Prompt 设计逻辑:明确主张内容、关联帖子的立场分布(如 “支持 x 条 / 否认 y 条”)、真实性标签选项(N/T/F/U)及输出格式(“Veracity: [标签], Reason: [解释]”);
-
示例:针对 “渥太华大学封锁” 的主张,结合支持立场(“BBC 报道确认”)与评论立场(“因议会袭击导致”),LLM 会输出 “Veracity: True Rumor”,解释为 “有权威信源支持且立场内容与主张一致”(如图 5 所示)。

3.3.4 预训练增强(Pretraining)
使用少量人工标注的主张集合 $C'$ 对 RV 网络进行预训练:
-
输入数据:主张文本 + 对应帖子文本(无需立场标签,直接利用原始内容);
-
训练目标:最小化 “预测真实性标签与 ground-truth 的负对数似然损失”,让 LLM 掌握 “主张 - 真实性” 的基础映射关系。
3.4 选择器策略(Selector Policy)
3.4.1 模块核心目标
作为框架的 “数据筛选中枢”,将预选择后的 “帖子 - 立场对” 和 “主张” 转化为 “保留 / 丢弃” 的决策,筛选高质量实例用于 SD 和 RV 网络的微调,核心是通过强化学习优化筛选策略。
3.4.2 两级马尔可夫决策过程(MDP)建模
针对 “主张级” 和 “帖子级” 分别构建 MDP,统一用 $\varsigma$ (状态)、 $\alpha$ (动作)、 $\gamma$ (奖励)、 $\tau$ (时间步)表示,具体定义如下:
| MDP 要素 | 主张级(Claim-level) | 帖子级(Post-level) |
|---|---|---|
| 状态( $\varsigma_\tau$ ) | 包含 “当前主张嵌入 $\tilde{c}_\tau$ 、已选主张上下文 $C_{\tau-1}$ 、主张解释嵌入 $E_\tau$ ”,嵌入由 RoBERTa(Liu et al., 2019)生成。 | 包含 “当前帖子嵌入 $\tilde{x}_{\tau}$ 、已选帖子上下文 $X_{\tau-1}$ 、帖子解释嵌入 $E_\tau$ ”,嵌入同样由 RoBERTa 生成。 |
| 动作( $\alpha_\tau$ ) | 二分类动作:保留(Retain)该主张 / 丢弃(Discard)该主张 | 二分类动作:保留(Retain)该帖子 / 丢弃(Discard)该帖子 |
| 奖励( $\gamma_\tau$ ) | 基于主张真实性预测与标签的一致性(人工标注主张)或立场分布相似度(未标注主张)计算。 | 基于帖子立场对主张验证的贡献度,间接通过主张级奖励反馈。 |
3.4.3 动作生成:策略网络(Policy Network)
策略网络基于状态 $\varsigma_\tau$ 输出 “保留 / 丢弃” 的概率分布,具体流程:
-
输入:状态嵌入 $\varsigma_\tau$ ;
-
网络结构:两层全连接网络,第一层用 ReLU 激活,第二层用 Sigmoid 激活(输出概率);
-
数学表达:
$\pi_{\theta}\left(\alpha_{\tau}, \varsigma_{\tau}\right)=\sigma\left(w_{2} \cdot ReLU\left(w_{1} \cdot \varsigma_{\tau}\right)\right)$
其中 $\theta = \{w_1, w_2\}$ 为网络权重, $\sigma$ 为 Sigmoid 函数;
-
动作采样:根据输出概率随机采样动作 $\alpha_\tau \sim \pi_\theta(\alpha_\tau, \varsigma_\tau)$ 。
3.4.4 奖励设计:混合奖励机制
奖励函数分两类场景,确保筛选的实例对联合任务有正向贡献:
场景 1:人工标注主张( $\tilde{c}_\tau \in C'$ )
-
- 奖励为 “RV 网络预测的真实性分布 $\hat{Y}_{\tilde{c}_\tau}$ 与 ground-truth 分布 $Y_{\tilde{c}_\tau}$ 的余弦相似度期望”,数学表达:
$\gamma_{\tau} = \mathbb{E}\left(cos \left(\hat{Y}_{\tilde{c}_{\tau}}, Y_{\tilde{c}_{\tau}}\right)\right)$
-
-
逻辑:若预测与真实标签一致(余弦相似度高),则该主张及对应帖子对训练有价值,给予正奖励;反之则给予负奖励。
-
场景 2:未标注主张( $\tilde{c}_\tau \notin C'$ )
-
- 奖励为 “当前主张的帖子立场分布均值 $\overline{\hat{y}_{\tilde{c}_\tau, \tilde{x}_{\tau,*}}}$ 与‘同类标注主张的立场分布均值 $\overline{\hat{y}_{c \in C', x_{c,*}}}$ ’的余弦相似度期望”,数学表达:
$\gamma_{\tau} = \mathbb{E}\left(cos \left(\overline{\hat{y}_{\tilde{c}_{\tau}, \tilde{x}_{\tau, *}}}, \overline{\hat{y}_{c \in \mathcal{C}', x_{c, *}}} | \hat{Y}_{\tilde{c}_{\tau}}=Y_{c}\right)\right)$
-
-
逻辑:若当前主张的立场分布与 “预测真实性标签对应的标注主张立场分布” 相似(如均为 “假谣言” 且否认立场占比高),则该主张有价值,给予正奖励。
-
补充: $\mathbb{E}(·)$ 为符号函数,将余弦相似度转化为 - 1(负相似)、0(无相似)、1(正相似),简化奖励计算。
-
3.4.5 策略优化目标
通过离线策略优化方法(Sutton and Barto, 2018)最大化 “主张级 + 帖子级” 的累积期望奖励,优化目标函数:
$\mathcal{R}_{t}= \frac{1}{t} \sum_{i=1}^{t}\left(R_{i} log \left(\pi_{\theta}\left(A_{i}, S_{i}\right)\right) + \frac{1}{t'} \sum_{j=1}^{t'} r_{i, j} log \left(\pi_{\theta}\left(a_{i, j}, s_{i, j}\right)\right)\right)$
-
其中 $R_i$ 为主张级奖励, $r_{i,j}$ 为帖子级奖励,t(主张时间步)、 $t'$ (帖子时间步)分别表示当前迭代步数;
-
优化逻辑:通过对数似然项让策略网络倾向于选择 “高奖励动作”,每次筛选完一个主张及对应帖子后更新策略参数。
3.5 模型训练
3.5.1 核心训练逻辑
采用端到端联合优化,在每个 epoch 中交替训练 “策略网络” 与 “SD/RV 网络”,形成 “筛选 - 微调 - 反馈” 的闭环,具体流程见算法 1。
3.5.2 各模块训练细节
1)策略网络训练
-
优化方法:基于公式 5 的累积奖励目标,使用梯度上升最大化奖励(因目标是 “最大化累积奖励”,与传统损失最小化相反);
-
更新时机:每完成一个主张及对应帖子的筛选后,更新策略网络参数 $\theta$ 。
2)SD 与 RV 网络训练
-
训练数据:策略网络筛选后的 “高质量实例”(人工标注实例 + LLM 标注的保留实例);
-
损失函数:标准的负对数似然损失(Kanamori, 2010),最小化 “LLM 预测标签与真实标签(或筛选后标注)的偏差”;
-
微调技术:使用 LoRA(Hu et al., 2021)进行参数高效微调,仅更新低秩矩阵参数,降低计算成本;
-
更新时机:每个 epoch 中,筛选过程结束后对 SD 和 RV 网络各微调 1 次;支持跳过微调,直接用筛选实例进行少样本上下文学习。
3.5.3 训练终止条件
基于奖励函数自动终止 ϵ- 贪心采样过程:当模型连续 N 步获得奖励 $\gamma_\tau = 1$ (即筛选的实例完全符合预期)时,训练终止;实验中 N 设为 100(通过验证集调优确定)。
4 实验与结果
4.1 Datasets and Setup(数据集与实验设置)
4.1.1 实验数据集选择
1)训练数据集(仅含主张真实性标签)
| 数据集 | 核心特性 | 统计信息(表 4) |
|---|---|---|
| Twitter15(T15) | Ma et al. (2017) 提出,源于 Twitter 平台的谣言数据集 | 总主张 1308 条;含非谣言(28.6%)、假谣言(28.3%)、真谣言(14.5%)、未验证(28.6%);总帖子 68026 条,平均每条主张对应 52 条帖子 |
| Twitter16(T16) | 同属 Twitter 平台谣言数据集,规模小于 Twitter15 | 总主张 818 条;非谣言(25.1%)、假谣言(25.3%)、真谣言(25.1%)、未验证(24.5%);总帖子 40867 条,平均每条主张对应 50 条帖子 |
| PHEME(PH) | 涵盖多事件的谣言数据集,规模最大 | 总主张 6425 条;非谣言(62.6%)、假谣言(9.9%)、真谣言(16.6%)、未验证(10.8%);总帖子 383569 条,平均每条主张对应 6 条帖子 |
2)测试数据集(含立场 + 真实性标签)
| 数据集 | 核心特性 | 统计信息(表 5) |
|---|---|---|
| RumorEval-S | Yang et al. (2022) 提出,含帖子立场标注的谣言数据集 | 总主张 425 条;非谣言(23.53%)、假谣言(17.41%)、真谣言(34.12%)、未验证(24.94%);总帖子 6718 条,立场分布为支持(19.65%)、否认(7.77%)、质疑(7.90%)、评论(64.68%) |
| SemEval-8 | Derczynski et al. (2017) 提出,SemEval 任务数据集,含完整立场与真实性标签 | 总主张 297 条;假谣言(20.8%)、真谣言(46.1%)、未验证(33.0%)(无 “非谣言” 类别);总帖子 4519 条,立场分布为支持(20.1%)、否认(7.6%)、质疑(7.9%)、评论(64.3%) |
4.1.2 实验设置细节
1)数据划分
- 从测试集(RumorEval-S/SemEval-8)中划分 20% 实例作为验证集(Val),用于:① 训练需要立场标签的基线模型;② 调优超参数(如 ϵ 值)。
2)评估指标
-
微平均 F1(MicF):对所有类别样本的精确率(Precision)和召回率(Recall)取平均后计算 F1,侧重样本量多的类别;
-
宏平均 F1(MacF):对每个类别单独计算 F1 后取平均,侧重样本量少的类别(如否认立场);
-
类别级 F1(Class-specific F1):单独报告每个立场 / 真实性类别的 F1 分数,直观反映模型对小众类别的性能。
3)关键参数设置
-
种子主张比例:主实验中使用训练集 50% 的主张作为 “人工标注种子主张”(\(C'\)),后续敏感性分析验证比例对性能的影响;
-
ϵ 值:ϵ- 贪心策略中 \(\epsilon=0.3\)(通过验证集调优确定,平衡探索与利用);
-
LLM 与微调参数:SD/RV 网络使用 Llama-2 7B 模型,LoRA 微调参数为:学习率 1e-4、训练轮次 6、最大序列长度 4096、4-bit 加载;策略网络参数为:学习率 5e-5、Adam 优化器、预热率 0.1、批大小 4、最大轮次 50。
4)基线模型实现
- 公开基线模型直接使用官方代码;无公开代码的模型(如 TD-MIL)则基于论文描述复现,确保实验公平性。
4.2 Baselines(基线模型)
4.2.1 立场检测(SD)基线模型(D.1 节)
| 类别 | 模型名称 | 核心特性 | 依赖标注 |
|---|---|---|---|
| 无监督 | TGA | Allaway and McKeown (2020a),基于主题分组注意力的零样本立场检测模型 | 无标注,依赖预训练主题特征 |
| BerTweet | Nguyen et al. (2020),基于 8.5 亿条推文预训练的语言模型,零样本适配 SD 任务 | 无标注,仅用预训练知识 | |
| Llama 2-ST | Touvron et al. (2023),Llama-2 单任务模型,仅用于立场检测 | 无标注,零样本提示学习 | |
| Llama 2-MT | Touvron et al. (2023),Llama-2 多任务模型,同时处理 SD 与 RV | 无标注,零样本提示学习 | |
| 有监督 | BiGRU | Augenstein et al. (2016),基于双向 GRU 的序列模型 | 需要帖子立场标签(训练于验证集 Val) |
| BrLSTM | Kochkina et al. (2017),基于分支 LSTM 的模型,建模帖子对话结构 | 需要帖子立场标签(训练于 Val) | |
| MT-GRU | Ma et al. (2018),基于 GRU 的多任务模型,联合 SD 与 RV | 需要帖子立场 + 主张真实性标签(训练于 Val) | |
| JointCL | Liang et al. (2022),基于对比学习的零样本立场检测模型 | 需要少量立场标签(训练于 Val) | |
| 弱监督 | SRLF | Yuan et al. (2021),立场感知强化学习框架,仅用主张真实性标签 | 仅需主张真实性标签(训练于 PHEME 等数据集) |
| TD-MIL | Yang et al. (2022),基于自上而下树结构的多实例学习模型,联合 SD 与 RV | 仅需主张真实性标签(当前最优弱监督基线) | |
| 本文变体 | JSDRV-Bert | JSDRV 框架的非 LLM 变体,用 BERT 替换 Llama-2,验证泛化性 | 仅需少量主张真实性标签 |
4.2.2 谣言验证(RV)基线模型(D.2 节)
| 类别 | 模型名称 | 核心特性 | 依赖标注 |
|---|---|---|---|
| 无监督 | BerTweet | 同 SD 基线,微调适配 RV 任务 | 无标注,仅用预训练知识 |
| Llama 2-ST | Llama-2 单任务模型,仅用于 RV | 无标注,零样本提示学习 | |
| Llama 2-MT | 同 SD 基线,多任务处理 SD 与 RV | 无标注,零样本提示学习 | |
| 有监督 | GCAN | Lu and Li (2020),基于图注意力的模型,仅考虑局部结构 | 需要主张真实性标签(训练于 PHEME) |
| TD-RvNN | Ma et al. (2020),基于自上而下树结构的循环神经网络,建模传播结构 | 需要主张真实性标签(训练于 PHEME) | |
| PLAN | Khoo et al. (2020),基于 Transformer 的模型,利用用户交互信息 | 需要主张真实性标签(训练于 PHEME) | |
| DDGCN | Sun et al. (2022),基于双动态图卷积的模型,融合外部知识 | 需要主张真实性标签(训练于 PHEME) | |
| 弱监督 | SRLF | 同 SD 基线,立场感知强化学习框架,适配 RV 任务 | 仅需主张真实性标签(训练于 PHEME) |
| TD-MIL | 同 SD 基线,当前最优弱监督 RV 模型 | 仅需主张真实性标签(训练于 PHEME) | |
| 多任务 | MTL2 | Kochkina et al. (2018),基于任务特定层的序列多任务模型,联合 SD 与 RV | 需要帖子立场 + 主张真实性标签(训练于 Val) |
| MT-GRU | 同 SD 基线,多任务 GRU 模型,联合 SD 与 RV | 需要帖子立场 + 主张真实性标签(训练于 Val) | |
| 本文变体 | JSDRV-Bert | 同 SD 变体,BERT 替换 Llama-2,适配 RV 任务 | 仅需少量主张真实性标签 |
4.3 实验内容、结果与结论
4.3.1 实验 1:立场检测(SD)性能评估(5.2 节)
1)实验内容
2)实验结果(表 1)
| 模型 | RumorEval-S(MicF/MacF) | SemEval-8(MicF/MacF) | 关键类别 F1(示例:否认立场) |
|---|---|---|---|
| 无监督基线 - TGA | 0.324/0.301 | 0.344/0.278 | 0.486(RumorEval-S) |
| 无监督基线 - Llama 2-MT | 0.632/0.500 | 0.766/0.611 | 0.203(RumorEval-S) |
| 有监督基线 - JointCL | 0.639/0.505 | 0.760/0.475 | 0.210(RumorEval-S) |
| 弱监督基线 - TD-MIL | 0.691/0.434 | 0.767/0.426 | 0.179(RumorEval-S) |
| 本文变体 - JSDRV-Bert | 0.683/0.565(PH 训练) | 0.780/0.502(PH 训练) | 0.383(RumorEval-S) |
| 本文模型 - JSDRV | 0.723/0.605(PH 训练) | 0.801/0.522(PH 训练) | 0.476(RumorEval-S) |
3)核心结论
-
无监督模型性能差异显著:TGA 因依赖特定主题预训练(与社交媒体谣言立场不匹配)泛化最差;Llama 2-ST/MT 凭借 LLM 预训练知识,性能远超 TGA 和 BerTweet,证明 LLM 零样本立场检测潜力。
-
有监督模型受限于标注:BiGRU(序列模型)、BrLSTM(结构建模)等有监督模型虽利用立场标签,但对小众类别(如否认立场)敏感 ——BrLSTM 在 RumorEval-S 中否认立场 F1 为 0,而 JSDRV 通过强化筛选缓解该问题。
-
JSDRV 性能最优且泛化性强:
-
JSDRV 在所有数据集上超越无监督、有监督、弱监督基线,如在 RumorEval-S 上,JSDRV(PH 训练)的 MicF(0.723)比弱监督最优 TD-MIL(0.691)高 3.2%,MacF(0.605)高 17.1%;
-
JSDRV-Bert(用 BERT 替换 LLM)虽性能略有下降,但仍优于所有基线,证明框架可泛化到非 LLM 模型;
-
JSDRV(PH 训练)性能最佳,因 PHEME 数据集规模最大(6425 条主张),提供更丰富的训练信号。
-
4.3.2 实验 2:谣言验证(RV)性能评估(5.3 节)
1)实验内容
2)实验结果(表 2)
| 模型 | RumorEval-S(MicF/MacF) | SemEval-8(MicF/MacF) | 关键类别 F1(示例:假谣言) |
|---|---|---|---|
| 无监督基线 - BerTweet | 0.760/0.452 | 0.755/0.427 | 0.293(RumorEval-S) |
| 有监督基线 - PLAN | 0.800/0.743 | 0.794/0.720 | 0.760(RumorEval-S) |
| 弱监督基线 - TD-MIL | 0.809/0.776 | 0.798/0.741 | 0.659(RumorEval-S) |
| 多任务基线 - MT-GRU | 0.768/0.452(Val 训练) | 0.761/0.428(Val 训练) | 0.298(RumorEval-S) |
| 本文变体 - JSDRV-Bert | 0.813/0.780(PH 训练) | 0.796/0.746(PH 训练) | 0.762(RumorEval-S) |
| 本文模型 - JSDRV | 0.842/0.804(PH 训练) | 0.834/0.784(PH 训练) | 0.774(RumorEval-S) |
3)核心结论
-
结构感知模型优于简单模型:有监督基线中,GCAN(仅局部结构)性能最差(RumorEval-S MicF=0.645);TD-RvNN、PLAN、DDGCN(建模传播结构 / 用户交互)性能显著提升,证明结构信息对 RV 的价值。
-
多任务模型依赖标注:MT-GRU、MTL2 需同时使用立场和真实性标签(训练于 Val),但性能仍低于 JSDRV(仅用少量真实性标签)——JSDRV(Val 训练)的 MacF(0.592)比 MT-GRU(0.452)高 14%,证明联合优化机制更高效。
-
JSDRV 全面超越基线:
-
JSDRV 在所有数据集上性能最优,如在 RumorEval-S 上,JSDRV(PH 训练)的 MicF(0.842)比弱监督最优 TD-MIL(0.809)高 3.3%,MacF(0.804)高 2.8%;
-
JSDRV-Bert 仍优于多数基线,进一步验证框架对非 LLM 模型的泛化性;
-
PHEME 数据集训练的 JSDRV 性能最佳,因大样本量提升模型对谣言多样性的适应能力。
-
4.3.3 实验 3:消融实验(Ablation Study)(5.4 节)
1)实验内容
- RSS(强化立场选择器)、RVS(强化真实性选择器)、FTSD(SD 网络微调)、FTRV(RV 网络微调)、PTSD(SD 网络预训练)、PTRV(RV 网络预训练)、epSD(SD 的 ϵ- 贪心)、epRV(RV 的 ϵ- 贪心)。
2)实验结果(表 3)
| 模型配置 | 谣言验证(MicF/MacF) | 立场检测(MicF/MacF) | 性能下降幅度(对比完整 JSDRV) |
|---|---|---|---|
| 完整 JSDRV | 0.842/0.804 | 0.723/0.605 | - |
| - RSS(移除立场选择器) | 0.820/0.783 | 0.700/0.571 | MicF 下降 2.2%(RV)、2.3%(SD) |
| - RVS(移除真实性选择器) | 0.826/0.790 | 0.705/0.573 | MicF 下降 1.6%(RV)、1.8%(SD) |
| - FTSD(移除 SD 微调) | 0.828/0.790 | 0.709/0.578 | MicF 下降 1.4%(RV)、1.4%(SD) |
| - epSD(移除 ϵ- 贪心) | 0.844/0.805 | 0.725/0.606 | 性能略有上升(无负面影响) |
3)核心结论
-
强化选择器是核心组件:移除 RSS 或 RVS 后,RV 和 SD 任务性能下降最显著(如 RV MicF 下降 2.2%),证明 “筛选高质量 LLM 标注实例” 是 JSDRV 性能提升的关键。
-
微调比预训练更重要:移除 FTSD/FTRV(微调)的性能下降幅度(如 SD MicF 下降 1.4%)大于移除 PTSD/PTRV(预训练)(如 SD MicF 下降 0.8%),说明联合微调能更精准地适配任务需求。
-
ϵ- 贪心无负面影响:移除 epSD/epRV 后性能无下降甚至略有提升,证明 ϵ- 贪心策略仅用于 “降低计算成本”(减少冗余采样),不影响核心性能,框架在效率与性能间实现平衡。
5.3.4 实验 4:辅助分析实验(5.5 节)
1)实验内容 1:立场分布可视化(tSNE)
-
用 tSNE 将 “原始帖子” 与 “JSDRV 筛选后的帖子” 的嵌入(RoBERTa [CLS] 向量)可视化,观察立场聚类效果。
-
结果:筛选后的帖子立场聚类更清晰(不同立场的点距离更远),证明 JSDRV 筛选的高质量立场标注能有效区分立场类别,为 RV 提供更可靠的线索。
-
结论:立场选择器能提升立场标注的区分度,间接促进 RV 任务性能。
2)实验内容 2:敏感性分析(E.2 节)
-
种子主张比例影响:在 PHEME 数据集上,测试种子主张比例(0%-100%)对 JSDRV、JSDRV-Bert、TD-MIL 性能的影响(图 7)。
-
结果:① 三者性能均随比例增加而提升;② JSDRV 性能饱和更快(50% 比例时 MicF 达 0.84,后续增长 < 1%),而 TD-MIL 需 100% 比例才达 0.81;③ 相同比例下,JSDRV 性能远超 TD-MIL(如 20% 比例时,JSDRV MicF 比 TD-MIL 高 8%)。
-
结论:JSDRV 对人工标注种子的依赖更低,50% 比例已足够达到饱和性能,降低标注成本。
-
-
ϵ 值影响:测试 ϵ(0-1)对 JSDRV、JSDRV-Bert 性能的影响(图 8)。
-
结果:① ϵ 从 0 增至 0.3 时,性能快速提升;② ϵ≥0.3 后,性能趋于稳定;③ JSDRV 在 ϵ=0.3 时达最优(RV MicF=0.842)。
-
结论:ϵ=0.3 能最优平衡探索与利用,少量采样即可达到与全量采样相当的性能。
-
3)实验内容 3:用户研究(E.3 节)
-
招募 6 名用户,对比 “基线(仅主张 + 帖子)” 与 “JSDRV(主张 + 筛选后立场 - 帖子对 + 解释)” 的用户体验,评估指标:准确率(Acc)、置信度(5 分制)、平均耗时。结果(表 6):
-
指标 基线 JSDRV 提升幅度 谣言判断准确率 0.713 0.990 +27.7% 用户置信度 4.165 1.017 置信度显著更高(分数越低表示越确定) 平均耗时 / 条 25 秒 5 秒 减少 80% -
结论:JSDRV 提供的 “立场 + 解释” 能帮助用户更快速、准确地判断谣言,且提升用户对结果的信任度,证明框架的实用价值。
4.4 实验整体结论
-
性能优势:JSDRV 在 “立场检测 - 谣言验证” 联合任务中全面超越现有无监督、有监督、弱监督基线,且对非 LLM 模型(如 BERT)具有良好泛化性;
-
效率优势:JSDRV 仅需 50% 人工标注种子主张、ϵ=0.3 的采样比例,即可达到饱和性能,大幅降低标注成本与计算开销;
-
实用价值:用户研究证明 JSDRV 能辅助人类高效判断谣言,提供可解释的立场与真实性依据,适配社交媒体谣言治理场景。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号