

设计数据密集型应用第二部分:分布式系统的机遇与挑战
在《Designing Data-Intensive Applications》的第一部分(参考上文),介绍了数据系统的基础理论与知识,都是基于single node。而在DDIA的第二部分(Distributed Data),则是将视野扩展到了分布式数据系统。数据的分布式主要有以下三个原因:
- Scalability
- Fault tolerance/high availability
- Reduce latency
当负载增加的时候,有两种应对方式,scale up vs scale out,前者指使用更强大但昂贵的设备:更快更多核的CPU、更大的RAM、更大容量更快读写速度的磁盘,这中shared-memory的形式,不仅造价昂贵,而且容错性较差。而后者,是分布式数据系统采用的shared-nothing 架构,通过增加普通机器节点(node)来应对负载的增加,这也是目前主流的应对大容量数据的方式。
如何将数据分布在多个节点上,有两种方式,replication and partition。《Distributed systems for fun and profit 》中这个图形象说明了这两种方式:
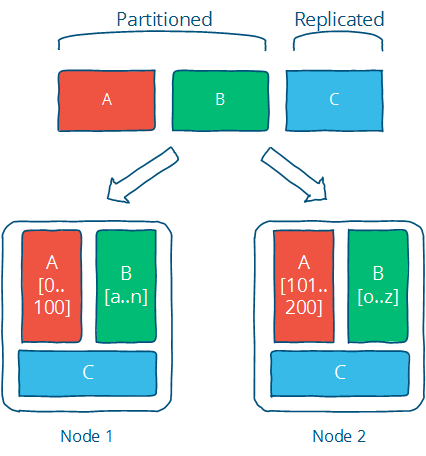
当然,分布式系统并不是银弹,分布式在带来可扩展性、高可用性的同时,也带来了诸多挑战,如分布式事务,共识。
replication
如上图所示,replication(复制集)就是将一份数据(副本)保存在多个节点上,数据的冗余有以下好处
- reduce latency:To keep data geographically close to your users
- increase availability:To allow the system to continue working even if some of its parts have failed
- increase read throughput : To scale out the number of machines that can serve read queries
复制集的最大挑战在于数据的一致性:如何在一定的约束条件下保证复制集中所有副本的数据是一致的。按照在复制集中的不同角色(Leader、Follower),有三种算法 single leader, multi leader, no leader。其中,关于中心化的复制集协议(single leader)我在带着问题学习分布式之中心化复制集一文中已经有较为详细的介绍.
Single leader
中心化复制集协议需要考虑以下问题:
(1)数据在多节节点间的写入是同步还是异步
(2)新增的Follower(secondary)如何快速同步数据
(3)如何处理节点的故障:对于Follower(Secondary)故障,需要catch up; 对于Leader(Primary)故障,需要选举出新的Leader,如何判断Leader故障,如何保证在Leader Failover的过程中不丢失数据,以及避免脑裂(同时存在多个Leader)都是挑战。
很多情况下,数据的异步写入是更好的方式,因为有更好的可用性,并发量更高。但异步写入,需要处理replication lag问题,即Leader与Follower之间的数据延迟,这样用户通过复制集中不同节点读取到的数据可能是不一致的。下面针对几种具体的情况下,来看看如何保证一定程度上的一致。
Reading Your Own Writes
用户能够查询到自己成功更新的内容,但并不关心别的用户能否立即查询。这就需要read-after-write consistency
实现方法:
(1)当读取的是可能被用户修改的内容是,从leader读取,否则可以从follower
(2)记录更新时间,超过一定时间则从follower读
Monotonic reads: (单调读)
only means that if one user makes several reads in sequence, they will not see time go backward
即一个用户如果读到了新版本的数据,那么重复读取的时候,不能读到旧版本的数据
实现办法:
(1)每个用户从固定一个副本读取
Consistent prefix reads
因果关系:比如”问一个问题“与”回答该问题“,一定是前者先发生。但在复制集多个节点间异步通信的时候,第三者(Observer)可能先看到答案,后看到问题,这就违背的因果性。如图所示:
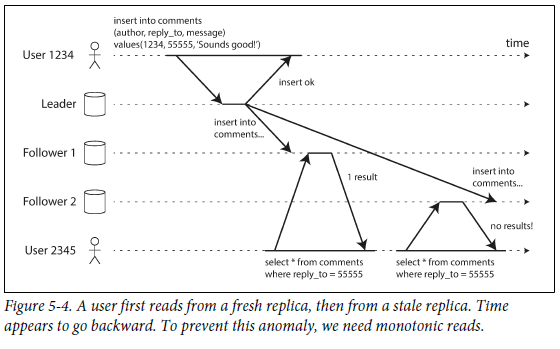
This guarantee says that if a sequence of writes happens in a certain order, then anyone reading those writes will see them appear in the same order.
One solution is to make sure that any writes that are causally related to each other are written to the same partition
如图所示,这个问题在单个复制集(单个partition)中是不会出现的,只有partitioned (sharded)的环境下才会出现。
解决办法:
(1)有因果关系的操作路由到同一个partition
Leaderless Replication
Leaderless Replication,去中心化的副本协议,就是说副本集中没有中心节点,所有节点的地位是平等的,大家都可以接受更新请求,相互通过协商达成数据的一致。在Amazon的Dynamo: Amazon’s Highly Available Key-value Store及其开源实现(Riak, Cassandra, and Voldemort)中就使用了Leaderless replication。
Leaderless的最大优点在于高可用性,不会因为单个(少数)节点的故障导致系统的不可用,高可用性的核心在于Quorum协议:复制集中节点数目为N,当一份数据成功写入到W个节点,每次读取的时候得到R个节点的返回,只要W + R > N,那么R中就一定包含最新的数据。如下图所示:

事实上,每次写入或者读取的时候都是发给所有的节点,但是只用等到W(R)个节点的成功返回即可通知客户端结果。
如上图所示,Node 3(replica 3)由于数据写入时故障,返回了过时的数据,数据系统需要使复制集的数据趋于一致,达到最终一致性。有两种方法
read repair: 读取的时候多读几个replica的数据,修复过时的数据。
Anti-entropy process : 后台进程检查差异
Quorum并不是万能的,在Leaderless中,即使使用了Quorum,还有以下潜在的问题
- 在不同节点的并发写导致的冲突,这是Leaderless最大的挑战
- 在读写并发的情况下,缺乏隔离性,可能读取到旧的数据
- 写失败时(少于w个节点写入成功),不会回滚
Detecting Concurrent Writes
leader less下并发写会可能冲突,在 read-repair 或者 hinted handoff 的时候也可能产生冲突。下面是一个冲突的示例:
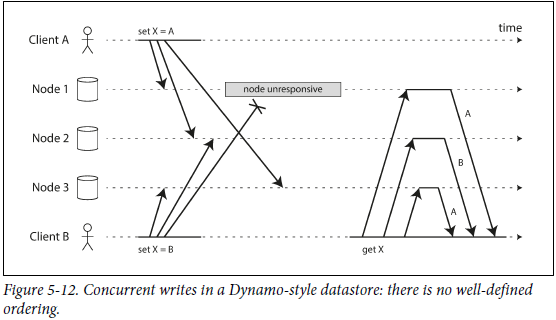
在并发的情况下,如果每个节点收到请求就写数据,那么复制集就无法达成一致,如上图所示,不同节点数据是不一致的。如何解决并发冲突,其中一种方式是 Last write win,cassandra就是这么解决冲突的,作用前提:准确无误判断recent;每一个写操作拷贝到所有的副本。缺点是存在数据丢失的情况:在写入W份告知客户端写入成功的前提下,某些写入会被silently discard
The “happens-before” relationship and concurrency
如何判断两个操作是不是并发:有没有happened before关系
An operation A happens before another operation B if B knows about A, or depends on A, or builds upon A in some way.
In fact, we can simply say that two operations are concurrent if neither happens before the other
如果存在happened before:那么后者覆盖前者是可行的;只有concurrent才会有冲突。
使用version vector来判断多个写操作的依赖关系。
Partition
关于Partitioning(Sharding),我在带着问题学习分布式系统之数据分片一文中也有详细介绍,可供参考。因此在本章节,只补充新知识。
Partitioning的主要原因是伸缩性(scalability)。如何对数据进行划分,如何rebalance数据是Partition需要解决的两个基础问题。
如果某个Partition上的数据或查询比其他Partition多,那么称这个现象为skewed,高负载的Partition为hot spot
Partitioning and Secondary Indexes
partitioning是按照primary index来分片的,那么secondary indexes是如何解决的呢
two main approaches to partitioning a database with secondary indexes: document-based partitioning and term-based partitioning.
Partitioning Secondary Indexes by Document
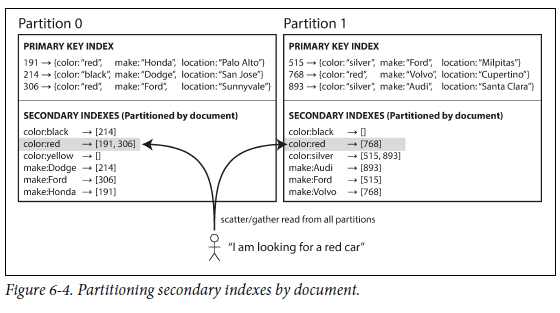
each partition maintains its own secondary indexes, covering only the documents in that partition.
每个分片维护自己的辅助索引,只包含了在该分片上的数据的辅助索引信息。
a document-partitioned index is also known as a local index
因此写数据的时候只用修改本地的辅助索引文件。
用辅助索引查询时,查询语句需要在所有分片上执行,并汇总(scatter-gather).如下图所示,color就是一个辅助索引。
local index非常使用广泛:MongoDB, Riak, Cassandra, Elasticsearch SolrCloud and VoltDB
Partitioning Secondary Indexes by Term
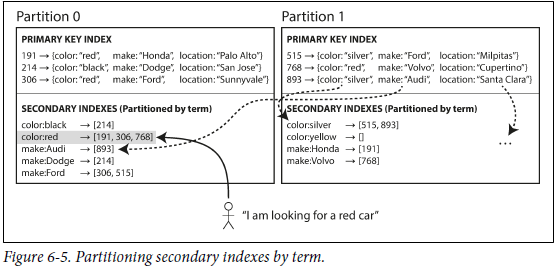
也称之为global index,辅助索引数据也分片。
相比Local index,优点是使用辅助索引读取数据时更高效(无需scatter gather) reads more efficient. 缺点是使得写入操作变慢而且复杂(需要分布式事务来保证)
Rebalancing Partitions
Rebalance的目标是:
-
rebalance之后 各节点间负载均衡
-
rebalance不影响(不中断)读写服务
-
节点间迁移数据不多不少(不要多)
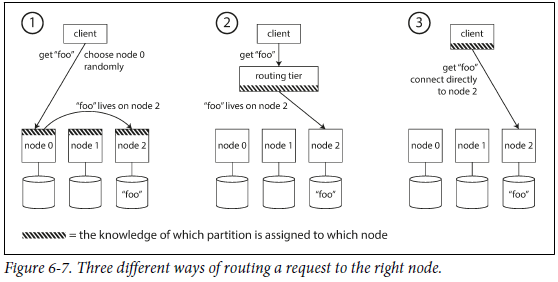
Request Routing
分片环境下,客户端如何得知改与哪个节点通信。
This is an instance of a more general problem called service discovery
方式:
(1)客户端连接任一节点,如果该节点不能处理请求,那么转发到正确的节点
(2)客户端发送请求到路由(routing tier)
This routing tier does not itself handle any requests; it only acts as a partition-aware load balancer.
(3)客户端知道分片信息与节点的映射关系
transaction
事务是在软硬件出现各种异常(fault)的情况下,提升系统可靠性(reliable)的重要手段。
A transaction is a way for an application to group several reads and writes together into a logical unit.
Conceptually, all the reads and writes in a transaction are executed as one operation: either the entire transaction succeeds (commit) or it fails (abort, rollback).
组成一个事务的多个操作要么都成功(commit),要么都不执行(rollback、abort),而不会存在部分执行成功的情况,即 all-or-nothing。
事务简化了应用层对异常的处理,系统是否需要事务,取决于事务带来的安全性保障,以及对应的代价。传统的关系型数据库都会选择支持事务,而在分布式数据库,如Nosql中,则(部分)放弃了对事务的支持,原因在于事务是可伸缩性的对立面,会影响大型系统的性能与可靠性。
当我们谈论事务的时候,一般都是指事务的ACID特性。
一个数据库对ACID的实现(甚至是理解)是不一定等同于其他数据库的,其中,最复杂的是Isolation(隔离性)。
隔离性是指并发的两个事务的执行互不干扰,一个事务不能看到其他事务运行过程的中间状态。当然,并发的读是不会相互干扰的,只有并发的读写、或者并发的写,才会带来race condition。实现隔离性最好的方式是可串行化serializable,达到和顺序执行一样的效果,但这样的方法存在性能问题。因此,数据库提供不同的隔离性级别来兼顾隔离线与并发性能。
关于隔离型这一部分,笔者打算另外写一篇笔记。
The Trouble with Distributed Systems
分布式系统带来了更多的挑战,更多意向不到的错误和异常,除了单点系统的问题,分布式系统还需应对的两个难题是:
- problems with networks
- clocks and timing issues
与单点系统不同的是,分布式系统容易出现partial failure:即部分工作、部分异常。partial failure的最大问题是nondeterministic,不确定性。分布式系统需要在软件层面实现容错(fault tolerance),以应对partial failure。
Unreliable neteork vs Detecting Faults vs timeout
分布式系统使用的网络是不可靠的,数据包可能丢失,可能延迟。而且丢失或者延迟既可能发生在request的路上,也可能发生在response的路上,这都是不确定的。
网络消息其中一个重要的应用就是心跳。
系统需要检测到异常的节点,如load balancer需要监测到不工作的节点,如中心化复制集协议对leader的监测。
在节点crash的时候,如果能准确判断且通知到系统中的其他节点,那最好不过。但是很多时候,无法判断一个节点是否crash,而且,一个节点虽然没有crash但也无法继续工作,这个时候还是得靠心跳超时,之前写过这么一篇文章《Hey,man,are you ok? -- 关于心跳、故障监测、lease机制》来介绍相关问题。
当在网络信息中使用超时时,超时时长是个问题:超时时间太长,那么需要等很长时间;太短,又很容易容易误判。
If the system is already struggling with high load, declaring nodes dead prematurely can make the problem worse. cascading failure
而网络延时在各种环境下变化又很大,拥塞控制导致发送方排队、网络交换机排队、虚拟机管理排队、CPU忙时排队、多租户环境下(超卖)受其他服务影响都有可能影响到网络延时。比较厉害的就是根据网络延时自动调节的超时时间,如Phi Accrual failure detector , TCP的超时重传就使用了类似的思想。
Unreliable Clocks vs Process pause
时间很重要,因为时间意味着:order,duration,points in time。
我们常用的时间,即time-of-day(wall-clock time).:是指根据某种日历返回的时间。在程序中,wall-clock time存在一些问题
- NTP可能导致时间回退
- 通常会忽略闰秒
因此wall-clock time不适合衡量时间差(measuring elapsed time)
因此,操作系统提供了另一种时间Monotonic clocks,如Linux上的clock_gettime(CLOCK_MONOTONIC),Monotonic clocks保证了时间不会jump back。
当分布式系统中各个节点的时钟不一致时,会出现各种问题,如一个常用但容易出问题的场景:用时间(timestamp)来判断多个节点上事件发生的顺序
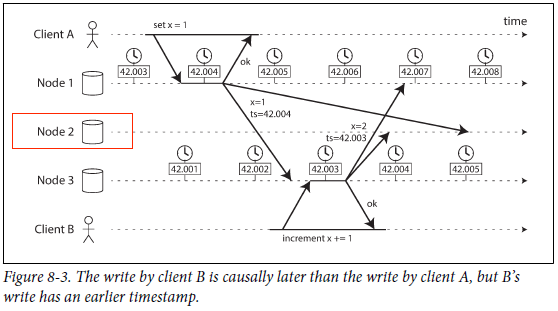
在LeaderLess复制集中,last write win(lww)是解决并发冲突的一个方法,如果这个时候不同节点数据不一致,可能导致数据被 悄无声息 地丢失。
即使使用了NTP,也无法完全保障各节点间数据的一致。一种有意思的想法是使用置信区间:
Clock readings have a confidence interval:
it doesn’t make sense to think of a clock reading as a point in time—it is more like a range of times, within a confidence interval:
很多算法与协议,依赖对本地时间的判断,如Lease,即使各节点的数据一致,在某些情况下也会出问题,那就是Process Pause。
比如,某段代码执行前会去check lease,check的时候满足lease,然后发生了Process Pause,恢复的时候可能已经不再满足lease了。因为不知道哪里可能会pause,也就无从再次检查
什么会导致Process Pause呢,很多:
- gc
- virtual machine can be suspended and resumed
- 多线程
- 磁盘IO: 非预期的disk access,如python import
- swap
- Unix SIGSTOP(Ctrl z)
特点是gc这种stop the world的行为,在有内存管理的编程语言Java、Python中时有发生。
gc导致process Pause,在Hbase中就发生过,如图所示:

分布式锁的实现中,使用了lease,即使在stop-the-world-gc pause,client 1任然认为自己持有lease,而事实上client 1持有的lease已经过期。因此在分布式系统中:
The Truth Is Defined by the Majority。
A node cannot necessarily trust its own judgment of a situation.
解决办法很简单:fencing token

System Model and Reality
当我们提及算法和协议,总是基于一定的系统模型,系统模型是算法工作环境的前提或者假设
system model, which is an abstraction that describes what things an algorithm may assume。
对于时间的假设:
- Synchronous model
- Partially synchronous model: 绝大多数是同步的,bounded;偶尔超出bound问题不大 ,依靠imeout机制
- Asynchronous model
对于Node failure的假设
- Crash-stop faults
- Crash-recovery faults(nodes are assumed to have stable storage)
- Byzantine (arbitrary) faults
如何衡量一个算法设计与实现是否正确呢:在系统模型下,所承诺的属性( properties)都得以满足。比如unique属性,比如事务中的Atomic属性。
属性可以分为两类:
Safety:nothing bad happens,
liveness: something good eventually happens.
分布式算法,在任何系统模型下,都需要满足safety属性
For distributed algorithms, it is common to require that safety properties always hold, in all possible situations of a system model,However, with liveness properties we are allowed to make caveats:
Consistency and Consensus
本章讨论在分布式系统中的容错算法、协议。
构建容错性系统的最好方式是:找出并实现通用的抽象模型(这些抽象解决一类问题),这样应用层代码就无需考虑、处理这些问题,即使发生各种异常。如数据库提供的事务。在分布式系统中:重要的抽象就是共识 consensus: that is, getting all of the nodes to agree on something。
Linearizability & Causality
在CAP理论与MongoDB一致性、可用性的一些思考 一文中介绍过CAP理论,CAP理论是说对于分布式数据存储,最多只能同时满足一致性(C,Consistency)、可用性(A, Availability)、分区容错性(P,Partition Tolerance)中的两者。强一致性能保证对于每一次读操作,要么都能够读到最新写入的数据,要么错误。
linearizability 能实现强一致性,因为
make a system appear as if there were only one copy of the data, and all operations on it are atomic
线性一致性是一个很有用的特性:比如通过lock的形式来选举leader,那么锁必须是线性的linearizable:;比如unqueness约束。
不同的复制集协议能否保持线性呢?对于single leader:如果只从leader读数据,那么基本上是线性的,也有例外,如数据被回滚,这个时候就不能保证线性。对于leaderless,理论上使用Quorum来保证线性,但实际中,也会出现非线性,如下图所示
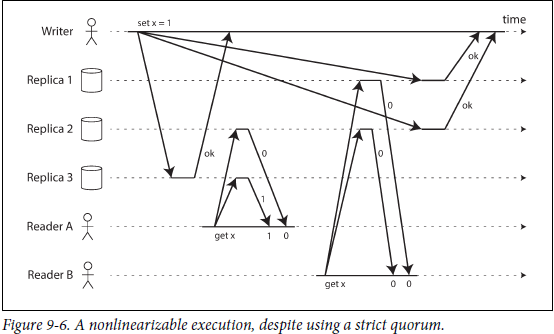
这个图说明了在满足quorum的情况下,也不能保证线性,上图是dirty read的情况,另外如果出现部分节点写失败,读取的时候也不能保证线性。
linearizability其实就是强一致性,虽然linearizability容易理解,易于使用,但分布式系统大多选择不支持linearizability,原因在于线性一致性容错性差,性能也不好。
在分布式一致性语义下,线性就是只有一份数据,且每个操作在某个时间点原子性执行,这就意味着某种顺序
Linearizability是total order,只有一份拷贝,且操作原子性发生,所有操作都有相对顺序。但事实上,很多操作是可以并发执行的,只要相互不影响。
Causality consistenc(因果一致性)是partial order,某些操作间是有顺序的,其他操作则是可以并发的。
In fact, causal consistency is the strongest possible consistency model that does not slow down due to network delays, and remains available in the face of network failures 线性一致性代价大,且很多时候没有必要
consensus & epoch & quorum
上述的因果一致性并不能解决所有问题,比如当两个用户并发登记同一个username,是没有因果的,但并不满足username的uniqueness约束,因此需要共识算法。共识就是几个节点对某件事情达成一致,显然共识能解决uniqueness constraint问题。初次之后,比如single leader的选举,比如 分布式事务的atomic commit,都需要共识。
Two-Phase Commit (2PC)是实现分布式事务的经典手段,通过2PC,也能实现共识。但是2PC的问题在于容错性差,节点故障和网络超时都会导致重试,直到节点或者网络恢复
consensus算法定义:
one or more nodes may propose values, and the consensus algorithm decides on one of those values
公式算法要满足的属性:
Uniform agreement
No two nodes decide differently.
Integrity
No node decides twice.
Validity
If a node decides value v, then v was proposed by some node.
Termination
Every node that does not crash eventually decides some value.
前三是safety属性,最后一个是liveness属性,最后一个也要求了系统要有容错性(2pc就不能满足这个属性)
single leader能保证共识,但single leader的选举依赖于共识算法,常见的容错的共识算法包括(Viewstamped Replication (VSR) , Paxos , Zab)
共识算法依赖leader,但leader不是固定的:the protocols define an epoch number (called the ballot number in Paxos, view number in Viewstamped Replication, and term number in Raft) and guarantee that within each epoch, the leader is unique
因此,single leader只是缓兵之计,不是不需要共识,而是不需要频繁的共识。
不同的数据系统选择不同的形式来满足leader 选举等共识需求,如mongodb,在replica node间使用类似raft的算法来选举leader。而其他系统,如hbase,使用outsourced的服务(如zookeeper)来达成共识、故障检测,把专业的事交给专业的人,大大简化了数据系统的复杂度。
总结
DDIA的第二部分信息量很大,设计到大量的算法和理论,仅仅看这本书是很难搞明白的。于我而言,对LeaderLess replication与consensus这些部分还不是很清楚,比如LeaderLess因果性,vector clock、lamport clock、Paxos & Raft算法,还需要花点时间研究一下。
references
Designing Data-Intensive Applications
Distributed systems for fun and profit

 浙公网安备 33010602011771号
浙公网安备 33010602011771号